py 上機考題解
Lecturer: liftleaf(不對不一定會有他)、times1、Verstand
我快半年沒有開 slides.com 了
pA 你有來上課嗎?
沒有謝謝。
輸入
蒿土度以?
s = input()輸出
print()如果你會的話,代表你這次有一定機率破台
條件判斷
if 條件1:
執行
elif 條件2:
執行
else:
執行官解
s = input()
print("Did you come to my class?")
if s == 'Yes':
print("I appreciate your effort so much, Times1's gonna cry QAQ")
else:
print("It's so awful of you not to attend my class, Times1's gonna cry QAQ")s = input()各種可能小丑錯誤
再不換行阿
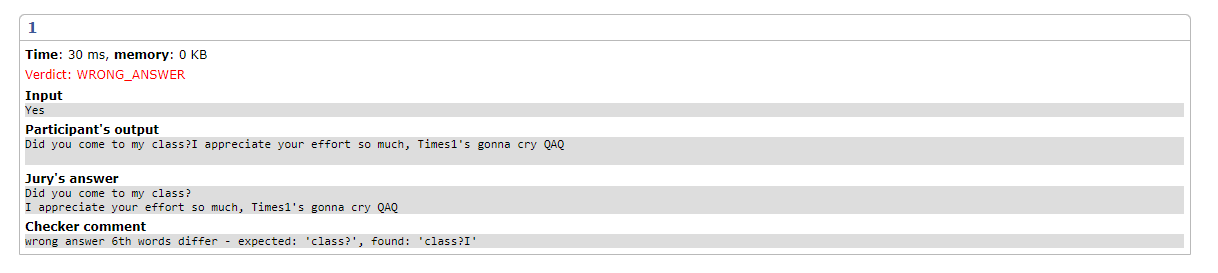
各種可能小丑錯誤
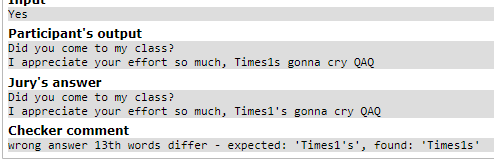
忘記加'
各種可能小丑錯誤
選錯語言

各種可能小丑錯誤
選錯語言

一行解
by illumeow 連pA也要炸魚QAQ
[print("Did you come to my class?\nI appreciate your effort so much, Times1's gonna cry QAQ" if input().startswith('Y') else "Did you come to my class?\nIt's so awful of you not to attend my class, Times1's gonna cry QAQ")]pB base64!
Based on my bad mood, I'd mess up everything once again.
Forbidden: 使用 python 內建函式庫
蒿土度以?
if a == 'encode':
print(base64.b64encode(s.encode('UTF-8')).decode('UTF-8'))
else :
print(base64.b64decode(s).decode('UTF-8'))不過生測資的時候是用這個沒錯,好爽ㄛ
土法煉鋼
蒿土度以?
import math
INPUT = input()
a = INPUT[0:6]
s = INPUT[7:]
l = len(s)
ans = ''
base = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
if a == 'encode':
for i in range(0, l, 3):
tmp = ''
tmp_c = ''
tmp_s = ''
for j in range(i, i+3): # 轉成二進位 ascii code
if j > l-1:
break
else :
tmp_s = str(bin(ord(s[j]))).replace('0b', '')
tmp += '0'*(8-len(tmp_s))
tmp += tmp_s
tmp += '0'*(math.ceil(len(tmp)/6)*6 - len(tmp))
for j in range(0, len(tmp), 6):
tmp_c += base[int(tmp[j:j+6], 2)]
tmp_c += '='*(4-len(tmp_c))
ans += tmp_c
print(ans)
else :
for i in range(0, l, 4):
tmp = ''
tmp_c = ''
for j in range(i, i+4):
if s[j] == '=':
break
else :
n = str(bin(base.find(s[j]))).replace('0b', '')
tmp += '0'*(6-len(n)) + n
for j in range(0, len(tmp), 8):
if j > len(tmp)-7:
break
tmp_c += chr(int(tmp[j:j+8], 2))
ans += tmp_c
print(ans)完全照著題目的意義去做
- code by illumeow
:place_of_worship:
BASE64_ALPHABET = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
def encode(data: str) -> str:
bindata = ''
for c in data:
bindata += bin(ord(c))[2:].zfill(8)
binlst = []
time = (len(bindata)-len(bindata)%6)//6+1 if len(bindata)%6 else len(bindata)//6
for _ in range(time):
binlst.append('0b'+bindata[:6])
bindata = bindata[6:]
if(len(binlst[-1])!=8):
binlst.append(f"{binlst.pop():0<8}")
ret_len = len(data)//3*4
if len(data)%3:
ret_len += 4
for _ in range(ret_len-len(binlst)):
binlst.append('0b1000000')
ret = ''
for i in binlst:
ret += BASE64_ALPHABET[int(i, base=2)]
return ret
def decode(data: str) -> str:
indx = 0
for i, c in enumerate(data):
if c == '=':
indx = i
break
data = data[:indx] if indx else data
bindata = ''
for c in data:
bindata += bin(BASE64_ALPHABET.index(c))[2:].zfill(6)
binlst = []
time = (len(bindata)-len(bindata)%8)//8+1 if len(bindata)%8 else len(bindata)//8
for _ in range(time):
binlst.append('0b'+bindata[:8])
bindata = bindata[8:]
if len(binlst[-1])!=10:
binlst.pop()
ret = ''
for i in binlst:
ret += chr(int(i, base=2))
return ret
s = input()
print(encode(s[7:]) if s.startswith('e') else decode(s[7:]))有興趣可以請教他ㄛ
- code by ck1110835
:zap:
from string import ascii_uppercase, ascii_lowercase, digits
def encode(b):
bits= []
final = []
res = ''
base64 = ascii_uppercase + ascii_lowercase + digits + '+/'
for x in b:
t = bin(ord(x))[2:].rjust(8, '0')
bits.append(t)
bits1 = ''.join(bits)
if len(bits1) % 6 != 0:
ro = len(bits1) // 6 + 1
else:
ro = len(bits1) / 6
for c in range(int(ro)):
final.append(bits1[6 * c : 6 * (c + 1)].ljust(6,'0'))
for temp in final:
res += base64[int(temp, 2)]
if len(res) % 4 == 0:
print(res)
elif len(res) % 4 == 2:
print(res + '==')
else:
print(res + '=')
def decode(b):
final = []
res = []
n = 0
no = []
base64 = ascii_uppercase + ascii_lowercase + digits + '+/'
if '==' in b:
b = b[0:-2]
elif '=' in b:
b = b[0:-1]
for t in b:
final.append(bin(base64.find(t))[2:].rjust(6,'0'))
ans = ''.join(final)
for i in range(0, len(ans), 8):
c = ans[i : i + 8]
res.append(c)
for x in res:
if len(x) == 8:
no.append(chr(int(x,2)))
hi = ''.join(no)
print(hi)
a = input()
#a = 'encode Times1 the clown'
if a[0:6] == 'encode':
encode(a[7:])
else:
decode(a[7:])有興趣可以請教他ㄛ
- code by ck1110793
???????????
ascii_to_char={
'00000000': '\x00',
'00000001': '\x01',
'00000010': '\x02',
'00000011': '\x03',
'00000100': '\x04',
'00000101': '\x05',
'00000110': '\x06',
'00000111': '\x07',
'00001000': '\x08',
'00001001': '\t',
'00001010': '\n',
'00001011': '\x0b',
'00001100': '\x0c',
'00001101': '\r',
'00001110': '\x0e',
'00001111': '\x0f',
'00010000': '\x10',
'00010001': '\x11',
'00010010': '\x12',
'00010011': '\x13',
'00010100': '\x14',
'00010101': '\x15',
'00010110': '\x16',
'00010111': '\x17',
'00011000': '\x18',
'00011001': '\x19',
'00011010': '\x1a',
'00011011': '\x1b',
'00011100': '\x1c',
'00011101': '\x1d',
'00011110': '\x1e',
'00011111': '\x1f',
'00100000': ' ',
'00100001': '!',
'00100010': '"',
'00100011': '#',
'00100100': '$',
'00100101': '%',
'00100110': '&',
'00100111': "'",
'00101000': '(',
'00101001': ')',
'00101010': '*',
'00101011': '+',
'00101100': ',',
'00101101': '-',
'00101110': '.',
'00101111': '/',
'00110000': '0',
'00110001': '1',
'00110010': '2',
'00110011': '3',
'00110100': '4',
'00110101': '5',
'00110110': '6',
'00110111': '7',
'00111000': '8',
'00111001': '9',
'00111010': ':',
'00111011': ';',
'00111100': '<',
'00111101': '=',
'00111110': '>',
'00111111': '?',
'01000000': '@',
'01000001': 'A',
'01000010': 'B',
'01000011': 'C',
'01000100': 'D',
'01000101': 'E',
'01000110': 'F',
'01000111': 'G',
'01001000': 'H',
'01001001': 'I',
'01001010': 'J',
'01001011': 'K',
'01001100': 'L',
'01001101': 'M',
'01001110': 'N',
'01001111': 'O',
'01010000': 'P',
'01010001': 'Q',
'01010010': 'R',
'01010011': 'S',
'01010100': 'T',
'01010101': 'U',
'01010110': 'V',
'01010111': 'W',
'01011000': 'X',
'01011001': 'Y',
'01011010': 'Z',
'01011011': '[',
'01011100': '\\',
'01011101': ']',
'01011110': '^',
'01011111': '_',
'01100000': '`',
'01100001': 'a',
'01100010': 'b',
'01100011': 'c',
'01100100': 'd',
'01100101': 'e',
'01100110': 'f',
'01100111': 'g',
'01101000': 'h',
'01101001': 'i',
'01101010': 'j',
'01101011': 'k',
'01101100': 'l',
'01101101': 'm',
'01101110': 'n',
'01101111': 'o',
'01110000': 'p',
'01110001': 'q',
'01110010': 'r',
'01110011': 's',
'01110100': 't',
'01110101': 'u',
'01110110': 'v',
'01110111': 'w',
'01111000': 'x',
'01111001': 'y',
'01111010': 'z',
'01111011': '{',
'01111100': '|',
'01111101': '}',
'01111110': '~',
'01111111': '\x7f',
'10000000': '\x80',
'10000001': '\x81',
'10000010': '\x82',
'10000011': '\x83',
'10000100': '\x84',
'10000101': '\x85',
'10000110': '\x86',
'10000111': '\x87',
'10001000': '\x88',
'10001001': '\x89',
'10001010': '\x8a',
'10001011': '\x8b',
'10001100': '\x8c',
'10001101': '\x8d',
'10001110': '\x8e',
'10001111': '\x8f',
'10010000': '\x90',
'10010001': '\x91',
'10010010': '\x92',
'10010011': '\x93',
'10010100': '\x94',
'10010101': '\x95',
'10010110': '\x96',
'10010111': '\x97',
'10011000': '\x98',
'10011001': '\x99',
'10011010': '\x9a',
'10011011': '\x9b',
'10011100': '\x9c',
'10011101': '\x9d',
'10011110': '\x9e',
'10011111': '\x9f',
'10100000': '\xa0',
'10100001': '¡',
'10100010': '¢',
'10100011': '£',
'10100100': '¤',
'10100101': '¥',
'10100110': '¦',
'10100111': '§',
'10101000': '¨',
'10101001': '©',
'10101010': 'ª',
'10101011': '«',
'10101100': '¬',
'10101101': '\xad',
'10101110': '®',
'10101111': '¯',
'10110000': '°',
'10110001': '±',
'10110010': '²',
'10110011': '³',
'10110100': '´',
'10110101': 'µ',
'10110110': '¶',
'10110111': '·',
'10111000': '¸',
'10111001': '¹',
'10111010': 'º',
'10111011': '»',
'10111100': '¼',
'10111101': '½',
'10111110': '¾',
'10111111': '¿',
'11000000': 'À',
'11000001': 'Á',
'11000010': 'Â',
'11000011': 'Ã',
'11000100': 'Ä',
'11000101': 'Å',
'11000110': 'Æ',
'11000111': 'Ç',
'11001000': 'È',
'11001001': 'É',
'11001010': 'Ê',
'11001011': 'Ë',
'11001100': 'Ì',
'11001101': 'Í',
'11001110': 'Î',
'11001111': 'Ï',
'11010000': 'Ð',
'11010001': 'Ñ',
'11010010': 'Ò',
'11010011': 'Ó',
'11010100': 'Ô',
'11010101': 'Õ',
'11010110': 'Ö',
'11010111': '×',
'11011000': 'Ø',
'11011001': 'Ù',
'11011010': 'Ú',
'11011011': 'Û',
'11011100': 'Ü',
'11011101': 'Ý',
'11011110': 'Þ',
'11011111': 'ß',
'11100000': 'à',
'11100001': 'á',
'11100010': 'â',
'11100011': 'ã',
'11100100': 'ä',
'11100101': 'å',
'11100110': 'æ',
'11100111': 'ç',
'11101000': 'è',
'11101001': 'é',
'11101010': 'ê',
'11101011': 'ë',
'11101100': 'ì',
'11101101': 'í',
'11101110': 'î',
'11101111': 'ï',
'11110000': 'ð',
'11110001': 'ñ',
'11110010': 'ò',
'11110011': 'ó',
'11110100': 'ô',
'11110101': 'õ',
'11110110': 'ö',
'11110111': '÷',
'11111000': 'ø',
'11111001': 'ù',
'11111010': 'ú',
'11111011': 'û',
'11111100': 'ü',
'11111101': 'ý',
'11111110': 'þ',
'11111111': 'ÿ',
}
char_to_binary={
'A': '000000',
'B': '000001',
'C': '000010',
'D': '000011',
'E': '000100',
'F': '000101',
'G': '000110',
'H': '000111',
'I': '001000',
'J': '001001',
'K': '001010',
'L': '001011',
'M': '001100',
'N': '001101',
'O': '001110',
'P': '001111',
'Q': '010000',
'R': '010001',
'S': '010010',
'T': '010011',
'U': '010100',
'V': '010101',
'W': '010110',
'X': '010111',
'Y': '011000',
'Z': '011001',
'a': '011010',
'b': '011011',
'c': '011100',
'd': '011101',
'e': '011110',
'f': '011111',
'g': '100000',
'h': '100001',
'i': '100010',
'j': '100011',
'k': '100100',
'l': '100101',
'm': '100110',
'n': '100111',
'o': '101000',
'p': '101001',
'q': '101010',
'r': '101011',
's': '101100',
't': '101101',
'u': '101110',
'v': '101111',
'w': '110000',
'x': '110001',
'y': '110010',
'z': '110011',
'0': '110100',
'1': '110101',
'2': '110110',
'3': '110111',
'4': '111000',
'5': '111001',
'6': '111010',
'7': '111011',
'8': '111100',
'9': '111101',
'+': '111110',
'/': '111111',
}
binary_to_char={
'000000': 'A',
'000001': 'B',
'000010': 'C',
'000011': 'D',
'000100': 'E',
'000101': 'F',
'000110': 'G',
'000111': 'H',
'001000': 'I',
'001001': 'J',
'001010': 'K',
'001011': 'L',
'001100': 'M',
'001101': 'N',
'001110': 'O',
'001111': 'P',
'010000': 'Q',
'010001': 'R',
'010010': 'S',
'010011': 'T',
'010100': 'U',
'010101': 'V',
'010110': 'W',
'010111': 'X',
'011000': 'Y',
'011001': 'Z',
'011010': 'a',
'011011': 'b',
'011100': 'c',
'011101': 'd',
'011110': 'e',
'011111': 'f',
'100000': 'g',
'100001': 'h',
'100010': 'i',
'100011': 'j',
'100100': 'k',
'100101': 'l',
'100110': 'm',
'100111': 'n',
'101000': 'o',
'101001': 'p',
'101010': 'q',
'101011': 'r',
'101100': 's',
'101101': 't',
'101110': 'u',
'101111': 'v',
'110000': 'w',
'110001': 'x',
'110010': 'y',
'110011': 'z',
'110100': '0',
'110101': '1',
'110110': '2',
'110111': '3',
'111000': '4',
'111001': '5',
'111010': '6',
'111011': '7',
'111100': '8',
'111101': '9',
'111110': '+',
'111111': '/',
}
char_to_ascii={
'\x00': '00000000',
'\x01': '00000001',
'\x02': '00000010',
'\x03': '00000011',
'\x04': '00000100',
'\x05': '00000101',
'\x06': '00000110',
'\x07': '00000111',
'\x08': '00001000',
'\t': '00001001',
'\n': '00001010',
'\x0b': '00001011',
'\x0c': '00001100',
'\r': '00001101',
'\x0e': '00001110',
'\x0f': '00001111',
'\x10': '00010000',
'\x11': '00010001',
'\x12': '00010010',
'\x13': '00010011',
'\x14': '00010100',
'\x15': '00010101',
'\x16': '00010110',
'\x17': '00010111',
'\x18': '00011000',
'\x19': '00011001',
'\x1a': '00011010',
'\x1b': '00011011',
'\x1c': '00011100',
'\x1d': '00011101',
'\x1e': '00011110',
'\x1f': '00011111',
' ': '00100000',
'!': '00100001',
'"': '00100010',
'#': '00100011',
'$': '00100100',
'%': '00100101',
'&': '00100110',
"'": '00100111',
'(': '00101000',
')': '00101001',
'*': '00101010',
'+': '00101011',
',': '00101100',
'-': '00101101',
'.': '00101110',
'/': '00101111',
'0': '00110000',
'1': '00110001',
'2': '00110010',
'3': '00110011',
'4': '00110100',
'5': '00110101',
'6': '00110110',
'7': '00110111',
'8': '00111000',
'9': '00111001',
':': '00111010',
';': '00111011',
'<': '00111100',
'=': '00111101',
'>': '00111110',
'?': '00111111',
'@': '01000000',
'A': '01000001',
'B': '01000010',
'C': '01000011',
'D': '01000100',
'E': '01000101',
'F': '01000110',
'G': '01000111',
'H': '01001000',
'I': '01001001',
'J': '01001010',
'K': '01001011',
'L': '01001100',
'M': '01001101',
'N': '01001110',
'O': '01001111',
'P': '01010000',
'Q': '01010001',
'R': '01010010',
'S': '01010011',
'T': '01010100',
'U': '01010101',
'V': '01010110',
'W': '01010111',
'X': '01011000',
'Y': '01011001',
'Z': '01011010',
'[': '01011011',
'\\': '01011100',
']': '01011101',
'^': '01011110',
'_': '01011111',
'`': '01100000',
'a': '01100001',
'b': '01100010',
'c': '01100011',
'd': '01100100',
'e': '01100101',
'f': '01100110',
'g': '01100111',
'h': '01101000',
'i': '01101001',
'j': '01101010',
'k': '01101011',
'l': '01101100',
'm': '01101101',
'n': '01101110',
'o': '01101111',
'p': '01110000',
'q': '01110001',
'r': '01110010',
's': '01110011',
't': '01110100',
'u': '01110101',
'v': '01110110',
'w': '01110111',
'x': '01111000',
'y': '01111001',
'z': '01111010',
'{': '01111011',
'|': '01111100',
'}': '01111101',
'~': '01111110',
'\x7f': '01111111',
'\x80': '10000000',
'\x81': '10000001',
'\x82': '10000010',
'\x83': '10000011',
'\x84': '10000100',
'\x85': '10000101',
'\x86': '10000110',
'\x87': '10000111',
'\x88': '10001000',
'\x89': '10001001',
'\x8a': '10001010',
'\x8b': '10001011',
'\x8c': '10001100',
'\x8d': '10001101',
'\x8e': '10001110',
'\x8f': '10001111',
'\x90': '10010000',
'\x91': '10010001',
'\x92': '10010010',
'\x93': '10010011',
'\x94': '10010100',
'\x95': '10010101',
'\x96': '10010110',
'\x97': '10010111',
'\x98': '10011000',
'\x99': '10011001',
'\x9a': '10011010',
'\x9b': '10011011',
'\x9c': '10011100',
'\x9d': '10011101',
'\x9e': '10011110',
'\x9f': '10011111',
'\xa0': '10100000',
'\xa1': '10100001',
'\xa2': '10100010',
'\xa3': '10100011',
'\xa4': '10100100',
'\xa5': '10100101',
'\xa6': '10100110',
'\xa7': '10100111',
'\xa8': '10101000',
'\xa9': '10101001',
'\xaa': '10101010',
'\xab': '10101011',
'\xac': '10101100',
'\xad': '10101101',
'\xae': '10101110',
'\xaf': '10101111',
'\xb0': '10110000',
'\xb1': '10110001',
'\xb2': '10110010',
'\xb3': '10110011',
'\xb4': '10110100',
'\xb5': '10110101',
'\xb6': '10110110',
'\xb7': '10110111',
'\xb8': '10111000',
'\xb9': '10111001',
'\xba': '10111010',
'\xbb': '10111011',
'\xbc': '10111100',
'\xbd': '10111101',
'\xbe': '10111110',
'\xbf': '10111111',
'\xc0': '11000000',
'\xc1': '11000001',
'\xc2': '11000010',
'\xc3': '11000011',
'\xc4': '11000100',
'\xc5': '11000101',
'\xc6': '11000110',
'\xc7': '11000111',
'\xc8': '11001000',
'\xc9': '11001001',
'\xca': '11001010',
'\xcb': '11001011',
'\xcc': '11001100',
'\xcd': '11001101',
'\xce': '11001110',
'\xcf': '11001111',
'\xd0': '11010000',
'\xd1': '11010001',
'\xd2': '11010010',
'\xd3': '11010011',
'\xd4': '11010100',
'\xd5': '11010101',
'\xd6': '11010110',
'\xd7': '11010111',
'\xd8': '11011000',
'\xd9': '11011001',
'\xda': '11011010',
'\xdb': '11011011',
'\xdc': '11011100',
'\xdd': '11011101',
'\xde': '11011110',
'\xdf': '11011111',
'\xe0': '11100000',
'\xe1': '11100001',
'\xe2': '11100010',
'\xe3': '11100011',
'\xe4': '11100100',
'\xe5': '11100101',
'\xe6': '11100110',
'\xe7': '11100111',
'\xe8': '11101000',
'\xe9': '11101001',
'\xea': '11101010',
'\xeb': '11101011',
'\xec': '11101100',
'\xed': '11101101',
'\xee': '11101110',
'\xef': '11101111',
'\xf0': '11110000',
'\xf1': '11110001',
'\xf2': '11110010',
'\xf3': '11110011',
'\xf4': '11110100',
'\xf5': '11110101',
'\xf6': '11110110',
'\xf7': '11110111',
'\xf8': '11111000',
'\xf9': '11111001',
'\xfa': '11111010',
'\xfb': '11111011',
'\xfc': '11111100',
'\xfd': '11111101',
'\xfe': '11111110',
'\xff': '11111111'
}
strinput=input().split(" ", 1)
A=strinput[0]
string=strinput[1]
if A=="encode":
result=''
for i in string:
result+=char_to_ascii[i]
time=len(result)//6
to_ans=''
for i in range(time):
tmp=result[i*6:i*6+6]
to_ans+=binary_to_char[tmp]
if len(result)%6!=0:
num=(len(result)//6)*6
tmp=result[num:len(result)]+('0'*(6-len(result)+num))
to_ans+=binary_to_char[tmp]
temp=len(to_ans)%4
to_ans+='='*(4-temp)
print(to_ans)
else:
result=''
cnt=0
for i in string:
if i=='=':
cnt+=1
continue
result+=char_to_binary[i]
result=result[:len(result)+cnt*6-(((len(string)-cnt)*6)%8)]
to_ans=''
for i in range(len(result)//8):
tmp=result[i*8:i*8+8]
to_ans+=ascii_to_char[tmp]
print(to_ans)appreciate the effort tho
pC 萬能計算機
但這題消失ㄌ
原本題目
## pD 萬能計算機
建北電資服務所,***竭盡所能***以程式知識完成各種委託。這天,在裡面當新鮮的肝的你,看到了一個案件,他是這麼說的:
" 依據我現在的學習需求,我需要用到很大量的計算。但偏偏我能找到的計算機功能都不滿足我所需要的。所以,請幫我設計一個萬能的計算機,內容除了包括加減乘除次方開根號、取log等純數運算外,還有向量矩陣、⋯"
⋯讓你看了簡直眼花撩亂,不過最後還是屈服於豐厚的報酬,而接下了這件案子。
讓我們來看看詳細這個計算機委託的內容吧!
- 先來從大架構講起。
- 一開始會先輸入一個數據 T,而後面會有一連串的 「V (T)」以 EOF 的形式輸入:
$T$
$V$ $(T)$
$V$ $(T)$
$\cdots$
$V$ $(T)$
- 會輸入的東西有兩種類型,分別是「數據」與「動作」。數據由一個或數個數字組成,而動作指的是加減乘除等。在此題的敘述中,數字以「N」表示,數據以「T」表示,動作以「V」表示。
- 此計算機有「螢幕數據」和「累加數據」兩個記憶的數字,互不影響。
- 「螢幕數據」即前一個步驟所計算出來的數據。在下一步步驟的計算,
- 「累加數據」則為計算機沒有顯示出來,而存著記憶的數字。後面會介紹各種動作說明如何操作累加數據。累加數據一開始皆預設為 0。
- `m+`:將當前數據加至累加數據。
- `m-`:將當前數據取負數加至累加數據。
- `mr`:存取累加數據,並將此數據輸出。請注意,mr 可能出現在 V 的位置(此時直接取代當前的螢幕數據),也可能出現在 T 的位置(但不會出現在最前面的 T)。
- `ms`:以當前數字直接取代累加數字
- `mc`:將「累加數據」歸零。
- `ce`:將「螢幕數據」歸零。
- `c`:將「累加數據」和「螢幕數據」歸零。
- 至於答案怎麼輸出的細項,我們最後再來提吧!現在,我們於此為各位分別介紹接下來開始介紹 N、T、V 吧!
- 首先,數字的輸入就是一門大學問呢!
- 如果是整數,則這個輸入可能是:
- 一個單純的整數 `n`
- 一個以科學記號表示的數字,如 `1e9 + 7` 表示 $1000000007$
- 如果是非整數的有理數,則這個輸入可能是:
- 一個有限小數 `n`
- 一個循環小數 `n&m`,其中 `m` 代表循環的部分為最後面 m 位($m \leq 3$),如 `0.344&2` 代表 $0.3\overline{44}$
- 一個分數,形式為 `a/b`(不會出現繁分數,且保證 $b \neq 0$)
- 一個分數,形式為 LaTeX 數學式,即 `\frac{a}{b}` 代表 $\frac{a}{b}$(有可能出現繁分數,如 `\frac{a}{\frac{b}{c}}`,代表 $\frac{a}{\frac{b}{c}}$,且保證所有分母皆不為0)
- 如果是非有理數,則可能出現:
- 根號,以 `\sqrt[b]{a}` 表示 $\sqrt[b]{a}$。若 `[b]` 被省略,則預設 $b=2$。
- $\pi$,以 `\pi` 表示
- $e$,以 `e` (自然常數)表示
- 其中,保證所有數字的輸入皆合法
<!-- 我是張宸嘉,我不會出題 OAO- -->
- 數據代表的是一個或數個數字。輸入該數據之前,可能會輸入一串文字,並以此判斷等一下會輸入的是純數、向量還是矩陣。
- 若未輸入該字串,則後面會接續一個純數 $N$
- 若輸入 vector,則代表輸入一向量。換行後,會有一數字 $a$,代表此向量維度為 $a$(保證 $a$ 為 $2$ 或 $3$),同一行後面有 $a$ 個數字 $N_1$ $N_2$ $\dots$ $N_a$
- 若輸入 matrix,則後面會有兩數字 `m` `n`,代表此矩陣有 $m$ 列 $n$ 列(此時其「階數」記為 $m \times n,\ m, \ n \in N$),接著換行輸入此矩陣: $$ m \quad n $$ $$ \begin{matrix} N_{11} & N_{12} & \cdots & N_{1n} \\ N_{21} & N_{22} & \cdots & N_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ N_{m1} & N_{m2} & \cdots & N_{mn}\end{matrix}$$,代表此矩陣
- 其中,保證數據的輸入皆合法;在後面的敘述將以 T 表示一個數據
- 若輸入的是一個動作,則會先輸入該「動作」,再視情況輸入一個 $T$。假設目前的螢幕數據為 $T_0$,則根據 $T$ 和 $T_0$ 種類為何,會有不同的合理情況:
- $T_0$ 為純數,$T$ 未輸入:
- 取 `sin/cos/tan` 或取其反函數(以 `sin^-1` 表示sin的反函數,以此類推)。
- 其中,若取 `tan` 取到的數字為 $\frac{\pi}{2} + n\pi$,或sin.cos 的反函數取到超出 -1~1 範圍的數字,則視為不合理的操作
- 階乘符號,以 `!` 表示。保證若階乘使用在純數上面時,該純數必小於15。
- 取絕對值,以`|` 表示。
- 取倒數,以 `r` 表示。
- 取 log,以 `l` 表示。以 $10$ 作為其對數底數。其中若取到小於等於 0 的數,則視為不合理的操作
- 取 rad,`rad`即將數字的單位由「角度」改為「弧度」。
- $T_0$ 為純數,$T$ 為純數:
- 加減乘除模次方,分別以 `+` `-` `*` `/` `%` `^` 表示,後面接一純數
- 若動作為除法,則回傳 $T_0 / T$;其餘有順序性的運算以此類推
- 其中,除法一律視為小數除法
- 若遇到 0^0 的情況,請回傳 1
- 若 % 的模數或被模數不為整數,或除以零,則視為不合理的操作
- 取 log,以 `l` 表示,$T_0$ 作為其對數底數。其中若取到小於等於 0 的數,則視為不合理的操作
- $T_0$ 為純數,$T$ 為向量(顛倒亦視為同種情況):
- 向量係數積,以 `c` 表示:將該向量內所有數值乘以該純數,並回傳一個向量。
- 例如:$T_0$ 為 $(1, 2)$,$T$ 為 $2$,則回傳 $(2, 4)$
- 取特定值,以 `a`:此時為純數的數據代表要取此向量的第 $x$ 位,並回傳一個數字。若 $x > a$,即 $x$ 超出該向量的維度,則視為不合理的操作
- 例如:$T_0$ 為 $(6, 7)$,$T$ 為 $2$,則回傳 $7$
- 例如:$T_0$ 為 $(6, 7)$,$T$ 為 $3$,則視為不合理的操作
- $T_0$ 為純數,$T$ 為矩陣(顛倒亦視為同種情況):
- 矩陣係數積:將該矩陣內所有數值乘以該純數,並回傳一個同樣階數的矩陣。
- $T_0$ 為向量,$T$ 為向量:
- 兩向量加減:若對象為兩同維度的向量,則可以對其中的值分別進行加減(以 `+` `-` 表示),並回傳一個向量。若維度不同,或是數據種類不同,則視為不合理的操作。
- 向量內積:若對象為兩同個維度的向量,則可進行向量內積,並回傳一個純數。若不符合條件,則視為不合理的操作。
- 註:兩二維向量內積為 $(a_1, a_2) \cdot (b_1, b_2) = a_1b_1 + a_2b_2$
- 註:兩三維向量內積為 $(a_1, a_2, a_3) \cdot (b_1, b_2, b_3) = a_1b_1 + a_2b_2 + a_3b_3$
- 向量外積:若對象為兩個三維向量,則可進行向量外積,並回傳一個三維向量。若不符合條件,則視為不合理的操作。
- 註:兩三維向量外積為 $(a_1, a_2, a_3) \times (b_1, b_2, b_3) = (a_2b_3 - a_3b_2, a_3b_1 - a_1b_3, a_1b_2 - a_2b_1)$
- $T_0$ 為矩陣,$T$ 為矩陣:
- 矩陣加減:若矩陣階數皆相同,即可進行加減法,並回傳一相同階數的矩陣。
- 矩陣乘法:設 $T_0$ 階即為 $m \times n$,若 $T_1$ 大小為 $n \times p$,則兩矩陣可進行矩陣乘法(此順序不可顛倒),並回傳一 $m \times p$ 大小的矩陣。若不符合條件,則視為不合理的操作。
- 註:矩陣乘法定義:設 $A = [a_{ij}]_{m \times n}$ 是一個 $m \times n$ 階矩陣,$B = [b_{ij}]_{n \times p}$ 是一個 $n \times p$ 階的矩陣,則 $AB = C$ 是一個 $m \times p$ 階矩陣。令 $C = [c_{ij}]_{m \times p}$,則 $c_{ij} = \displaystyle\sum_{k=1}^{n} a_{ik}b_{kj}, 1 \leq i \leq m, 1 \leq j \leq p$。(如果真的看不懂的話就自己上網查吧)
- 若所輸入的功能不符合該情況(例如 $T_0$ 為矩陣,$T$ 為矩陣時動作為 `sin`),則視為不合理的操作。
- 另外別忘了,前面提到的 `m+`、`m-` 等也都是動作喔!
- 輸出:
- 輸出一個數據 T 時:
- 若 T 為純數,則輸出該純數 $N$
- 若 T 為向量,則在**同行**輸出 $N_1$ $N_2$ $\cdots$ $N_a$,中間以空格隔開
- 若 T 為矩陣,則依其行列輸出 $$ \begin{matrix} N_{11} & N_{12} & \cdots & N_{1n} \\ N_{21} & N_{22} & \cdots & N_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ N_{m1} & N_{m2} & \cdots & N_{mn}\end{matrix}$$ ,列中數字以空格隔開,列與列以換行隔開。
- 若過程中有遇到不合理的答案,請直接輸出`invalid`,並將「螢幕數據」歸零;除此條件外,過程中不用輸出其他東西。若過程中遇到若過程中所計算出的數字小數點超過五位,請四捨五入至小數點後**五**位,再進行接下來的計算。
- 輸入終止後,請依序輸出最終的「螢幕數據」與「累加數據」,中間以換行分隔。輸出答案時,若小數點位數超過三位,請一律四捨五入至小數點後**三**位。為什麼消失了呢?
沒人寫得出來~~~🥳
各位出題記得自己寫寫看
pC Primonacci
超級魔王題
題目
大於 n 的最小質數
看懂 a(n)
之後的第 n 個質數
有效率地找質數
不能用簡單的質數測試來找到大的質數
最有效率的方式是埃氏篩
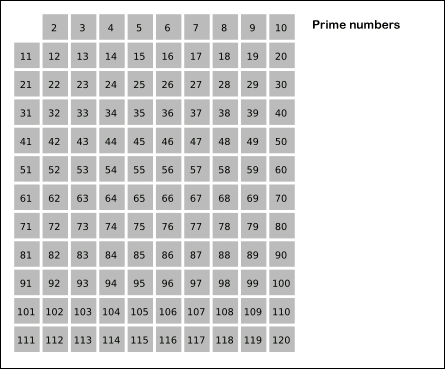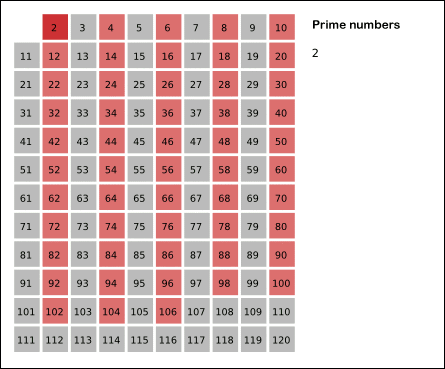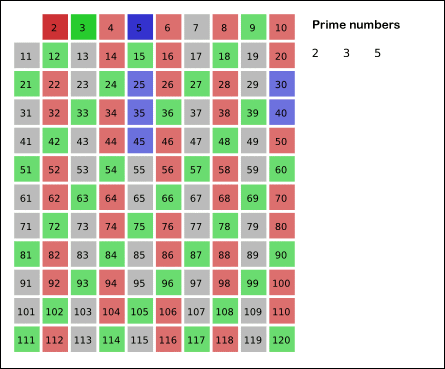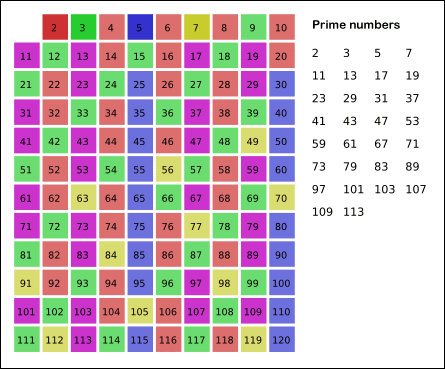
有效率地找質數
但是埃氏篩需要建一張 2~X 的表
以 10^14 來說太大了
但由於我們最多只要 10^14 後的第 10^5 個質數
因此質數表只要夠大
有包含 100,000 個質數就好了
如 X ~ X +10^7
埃氏篩的本質
埃氏篩的原理是
把目前篩出來的質數當作質因數
用來篩掉後面的數字
因此我們可以先建 的質數表
再拿這個質數表篩出我們 X ~ X+10^7 的質數表
除自己外最大的因數是
高速費波那契
不可能照定義去推費波那契數列的值,太慢
要使用這個特殊性質:
可以看出,這種方法計算的速度是指數性的
官方解答
class Solution:
def __init__(self, x):
self.x = x
self.mod = 1234567891011
self.iscomp = []
self.table_size = 10**7
self.gen_comp_table()
def gen_table(self, test_range):
isprime = [True]*test_range
isprime[0] = isprime[1] = False
for i in range(test_range):
if not isprime[i]:
continue
for j in range(i*i, test_range, i):
if j % i == 0:
isprime[j] = False
return isprime
def gen_primes(self, test_range):
primes = []
isprime = self.gen_table(test_range)
for i in range(test_range):
if isprime[i]:
primes.append(i)
return primes
def gen_comp_table(self):
self.iscomp = [False]*self.table_size
factors = self.gen_primes(int((self.x+self.table_size)**0.5))
for factor in factors:
for i in range(self.x // factor * factor - self.x, self.table_size, factor):
if i < 0:
continue
if i+self.x == factor:
continue
self.iscomp[i] = True
def next_prime_index(self, n):
for i in range(n+1, self.table_size):
if not self.iscomp[i]:
return i
def fib_mod(self, n):
a, b = 0, 1
binary = bin(n)[2:]
for bit in binary:
a, b = a*(b*2 - a), a*a + b*b
if bit == '1':
a, b = b, a+b
a %= self.mod
b %= self.mod
return a
def run(self):
ans = 0
prime_index = self.next_prime_index(0)
for _ in range(100000):
ans += self.fib_mod(prime_index + self.x)
prime_index = self.next_prime_index(prime_index)
print(ans % self.mod)
if __name__ == '__main__':
sol = Solution(int(input()))
sol.run()
pD 算式計算機
pC的簡化版
解析算式
像這樣的一個算式
我們可以先解析括號內的算式
先不要管是怎麼解析的
解析算式
解析算式
再來,可以將其視為一個加法算式
然後分開解析
解析算式
然後是減法
解析算式
然後是乘法、次方
解析算式
最後一定會出現 的形式
就可以直接解析
解析算式
最後一定會出現 的形式
就可以直接解析
解析算式
最後一定會出現 的形式
就可以直接解析
解析算式
最後一定會出現 的形式
就可以直接解析
解析算式
這種由上而下遞迴解析的技巧
也可以被視為對一棵二元樹做 DFS
是編譯器用來解析程式語言的演算法
官方解答
def find_last(l, x):
return len(l) - 1 - l[::-1].index(x)
def evaluate(tokens):
while '(' in tokens:
lparen_index = tokens.index('(')
rparen_index = lparen_index
paren_left = 1
while paren_left != 0:
rparen_index += 1
if tokens[rparen_index] == ')':
paren_left -= 1
elif tokens[rparen_index] == '(':
paren_left += 1
tokens[lparen_index] = evaluate(tokens[lparen_index+1:rparen_index])
del tokens[lparen_index+1:rparen_index+1]
if '+' in tokens:
op_index = find_last(tokens, '+')
return evaluate(tokens[:op_index]) + evaluate(tokens[op_index+1:])
if '-' in tokens:
op_index = find_last(tokens, '-')
return evaluate(tokens[:op_index]) - evaluate(tokens[op_index+1:])
if '*' in tokens:
op_index = find_last(tokens, '*')
return evaluate(tokens[:op_index]) * evaluate(tokens[op_index+1:])
if '^' in tokens:
op_index = find_last(tokens, '^')
return evaluate(tokens[:op_index]) ** evaluate(tokens[op_index+1:])
return int(tokens[0])
if __name__ == '__main__':
exp = input()
tokens = ['(']
for c in exp:
if c.isdigit() and tokens[-1].isdigit():
tokens[-1] += c
else:
tokens.append(c)
tokens.append(')')
print(evaluate(tokens))
pE 體育課
Physical Education

超級水題
還記得requests嗎?
import requests
existnum = 0
codesum = 0
with open('urls.txt', 'r') as f:
net = f.read().splitlines()
for i in net:
status = 0
try:
request = requests.get(i)
status = request.status_code
if request.status_code == 200:
existnum += 1
except requests.exceptions.HTTPError as err:
status = err.response.status_code
codesum += status
print(existnum)
print(codesum)但這題看不到你們的code
沒東西可以臭了QAQ
順帶一題這題最難出的地方是生出一堆壞掉的連結
pF 可以用去年的題目嗎?
好ㄟ最後一題
題目
很長很長我懶得放
反正就是處理一堆有的沒的
其實蠻簡單的
但要細心
官解
但寫的蠻醜ㄉ
boysum = 0
girlsum = 0
month = 1
new_students_list = []
new_students = 0
studentdata = []
class Student:
def __init__(self, num: str, name: str, gender: str, age: str, birth: str, grade: str, height: str, weight: str, salary: str) -> None:
self.num = int(num)
self.name = name
if gender == "M":
self.gender = 1
else:
self.gender = 0
self.age = int(age)
self.birth = int(birth)
self.grade = int(grade)
self.height = int(height)
self.weight = int(weight)
self.salary = int(salary)
self.money = int(self.salary)
self.BMI = 0
self.update_bmi()
def update_bmi(self):
self.BMI = self.weight / (self.height / 100)**2
def earn(self):
self.money += self.salary
def exercise(self):
if self.weight > 5:
self.weight -= 5
self.height += 1
self.update_bmi()
def play(self):
if self.money >=1000:
self.money -= 1000
def eat(self):
self.weight += 5
self.update_bmi()
def transsexual(self):
self.gender = self.gender^1 #xor(?)
def pmoney(self):
print(self.money)
studentamount = int(input())
for i in range(studentamount):
data = input()
tmpdata = data.split(" ")
studentdata.append(Student(tmpdata[0], tmpdata[1], tmpdata[2], tmpdata[3], tmpdata[4][:2], tmpdata[5], tmpdata[6], tmpdata[7], tmpdata[8]))
def tallest():
t = max(studentdata, key=lambda x:x.height)
print("tallest:", end="")
for i in studentdata:
if i.height == t.height:
print(i.num, end=" ")
print()
def shortest():
t = min(studentdata, key=lambda x:x.height)
print("shortest:", end="")
for i in studentdata:
if i.height == t.height:
print(i.num, end=" ")
print()
def heaviest():
t = max(studentdata, key=lambda x:x.weight)
print("heaviest:", end="")
for i in studentdata:
if i.weight == t.weight:
print(i.num, end=" ")
print()
def lightest():
t = min(studentdata, key=lambda x:x.weight)
print("lightest:", end="")
for i in studentdata:
if i.weight == t.weight:
print(i.num, end=" ")
print()
def richest():
t = max(studentdata, key=lambda x:x.money)
print("richest:", end="")
for i in studentdata:
if i.money == t.money:
print(i.num, end=" ")
print()
def poorest():
t = min(studentdata, key=lambda x:x.money)
print("poorest:", end="")
for i in studentdata:
if i.money == t.money:
print(i.num, end=" ")
print()
if __name__ == "__main__":
n = int(input()) # Number of students
m = int(input()) # Number of operations
for i in range(m):
cmd = input().split(" ")
if cmd[0] == "money":
for j in studentdata:
if j.num == int(cmd[1]):
j.pmoney()
elif cmd[0] == "play":
for j in studentdata:
if j.num == int(cmd[1]):
j.play()
elif cmd[0] == "exercise":
for j in studentdata:
if j.num == int(cmd[1]):
j.exercise()
elif cmd[0] == "eat":
for j in studentdata:
if j.num == int(cmd[1]):
j.eat()
elif cmd[0] == "transsexual":
for j in studentdata:
if j.num == int(cmd[1]):
j.transsexual()
elif cmd[0] == "month":
month += 1
if month > 12:
month = 1
for j in studentdata:
j.earn()
if j.birth == month:
j.age += 1
else:
datasum = 0
for j in range(len(cmd)):
if cmd[j].isalpha() and not cmd[j] == "and" and not cmd[j] == "not" and not cmd[j] == "or":
cmd[j] = "k."+cmd[j]
elif cmd[j] == "=":
cmd[j] = "=="
for k in studentdata:
if eval(' '.join(cmd)):
datasum += k.num
print(datasum)
for i in studentdata:
if i.gender == 1:
boysum += 1
else:
girlsum += 1
new_students_list.append([i.grade, i.num])
new_students_list.sort(key=lambda x:x[0], reverse=True)
for i in range(n):
new_students += new_students_list[i][1]
print(f"boysum:{boysum}")
print(f"girlsum:{girlsum}")
richest()
poorest()
tallest()
shortest()
heaviest()
lightest()
print(f'new students:{new_students}')錯誤解-1
by black black 再不看範例測資阿
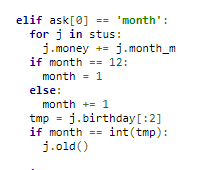
要先增加月數才判斷!!!
錯誤解-2
by black black 怎麼還是你
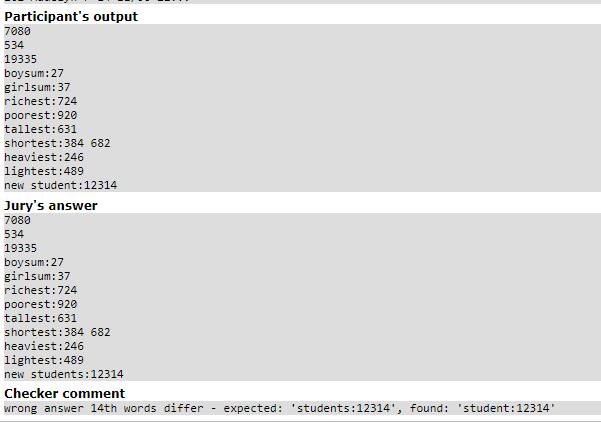
就...記得加s...
錯誤解-2
by black black 怎麼還是你
就...記得加s...
唯一破台解
by illumeow 顯然寫得漂亮多ㄌ
from sys import stdin, stdout
class Student():
def __init__(self, code, name, gender, age, birth, grade, height, weight, allowance):
self.code = code
self.name = name
# 1為M、0為F
self.gender = 1 if gender == 'M' else 0
self.age = int(age)
self.birthmonth = int(birth[:2])
self.grade = int(grade)
self.height = int(height)
self.weight = int(weight)
self.money = int(allowance)
self.allowance = int(allowance)
def BMI(self):
return (self.weight/(self.height*self.height*0.0001))
def money(code: str):
return students[code].money
# no need: month, play, exercise, eat, transsexual
def month():
for i in students.keys():
students[i].money += students[i].allowance
if students[i].birthmonth == cur_month: students[i].age += 1
def play(code: str):
if students[code].money >= 1000:
students[code].money -= 1000
def exercise(code: str):
students[code].height += 1
if students[code].weight > 5:
students[code].weight -= 5
def eat(code: str):
students[code].weight += 5
def transsexual(code: str):
students[code].gender = 0 if students[code].gender else 1
# main
cur_month = 1
students = {}
student_cnt = int(stdin.readline().strip())
for _ in range(student_cnt):
student_data = stdin.readline().strip().split()
student = Student(*student_data)
students[student_data[0]] = student
n = int(stdin.readline().strip())
m = int(stdin.readline().strip())
# commands
for _ in range(m):
result = []
command = stdin.readline().strip()
# those no need output
temp = command.split()
if(temp[0] == 'month'):
cur_month += 1
if cur_month == 13: cur_month = 1
month()
elif(temp[0] == 'play'): play(temp[1])
elif(temp[0] == 'exercise'): exercise(temp[1])
elif(temp[0] == 'eat'): eat(temp[1])
elif(temp[0] == 'transsexual'): transsexual(temp[1])
elif(temp[0] == 'money'): print(money(temp[1]))
else:
command = command.replace("age", "student.age").replace("grade", "student.grade").replace("gender", "student.gender").replace("height", "student.height").replace("weight", "student.weight").replace("BMI", "student.BMI()").replace("=", "==")
# print(command)
for student in students.values():
if eval(command): result.append(student.code)
# print(result)
if result:
code_length = max(map(len, result))
result = [int(x) for x in result]
print(str(sum(result)).zfill(code_length))
else:
print(0)
# finally
boy, girl = 0, student_cnt
maxmoney = float('-inf')
minmoney = float('inf')
maxheight = float('-inf')
minheight = float('inf')
maxweight = float('-inf')
minweight = float('inf')
for student in students.values():
if student.gender:
boy += 1
girl -= 1
if student.money > maxmoney: maxmoney = student.money
if student.money < minmoney: minmoney = student.money
if student.height > maxheight: maxheight = student.height
if student.height < minheight: minheight = student.height
if student.weight > maxweight: maxweight = student.weight
if student.weight < minweight: minweight = student.weight
stdout.write(f'boysum:{boy}\n')
stdout.write(f'girlsum:{girl}\n')
richest = []
poorest = []
tallest = []
shortest = []
heaviest = []
lightest = []
code2grade = []
for student in students.values():
if student.money == maxmoney:
richest.append(student.code + ' ')
elif student.money == minmoney:
poorest.append(student.code + ' ')
if student.height == maxheight:
tallest.append(student.code + ' ')
elif student.height == minheight:
shortest.append(student.code + ' ')
if student.weight == maxweight:
heaviest.append(student.code + ' ')
elif student.weight == minweight:
lightest.append(student.code + ' ')
code2grade.append((student.code, student.grade))
# print(f"""
# maxmoney: {maxmoney}
# minmoney: {minmoney}
# maxheight: {maxheight}
# minheight: {minheight}
# maxweight: {maxweight}
# minweight: {minweight}
# """)
stdout.write(f'richest:')
stdout.writelines(richest)
stdout.write('\n')
stdout.write(f'poorest:')
stdout.writelines(poorest)
stdout.write('\n')
stdout.write(f'tallest:')
stdout.writelines(tallest)
stdout.write('\n')
stdout.write(f'shortest:')
stdout.writelines(shortest)
stdout.write('\n')
stdout.write(f'heaviest:')
stdout.writelines(heaviest)
stdout.write('\n')
stdout.write(f'lightest:')
stdout.writelines(lightest)
stdout.write('\n')
if n:
code2grade.sort(key=lambda x: x[1], reverse=True)
code_length = len(code2grade[0][0])
new_students_sum = 0
for i in range(n):
if len(code2grade[i][0]) > code_length:
code_length = len(code2grade[i][0])
new_students_sum += int(code2grade[i][0])
new_students_sum = str(new_students_sum).zfill(code_length)
stdout.write('new students:' + new_students_sum + '\n')
else:
stdout.write('new students:0\n')各位有空可以研究一下 很酷?