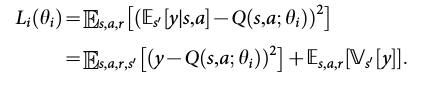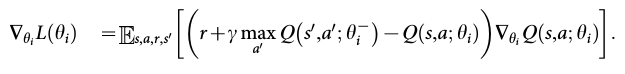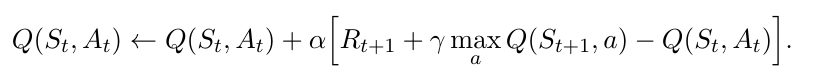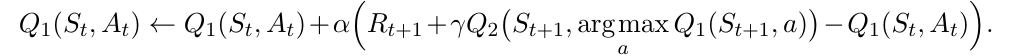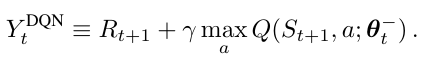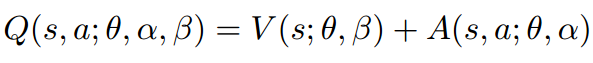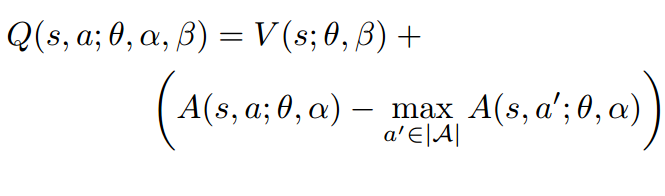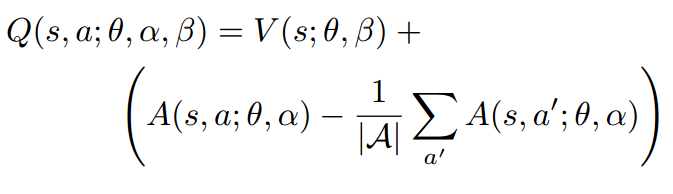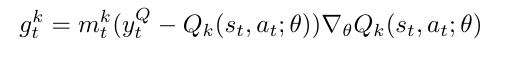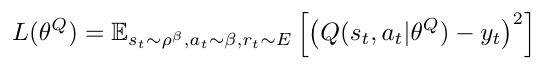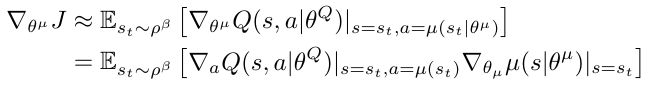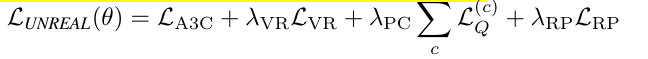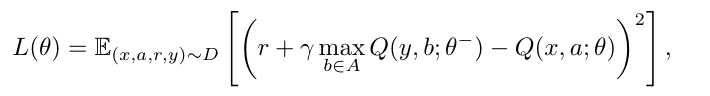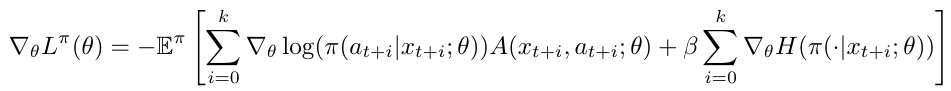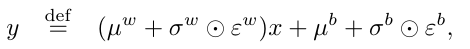deep reinforcemnt learning
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
KAUST-IVUL-July 20-2017
Guohao Li
lightaime@gmail.com
Deepmind proposed the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning
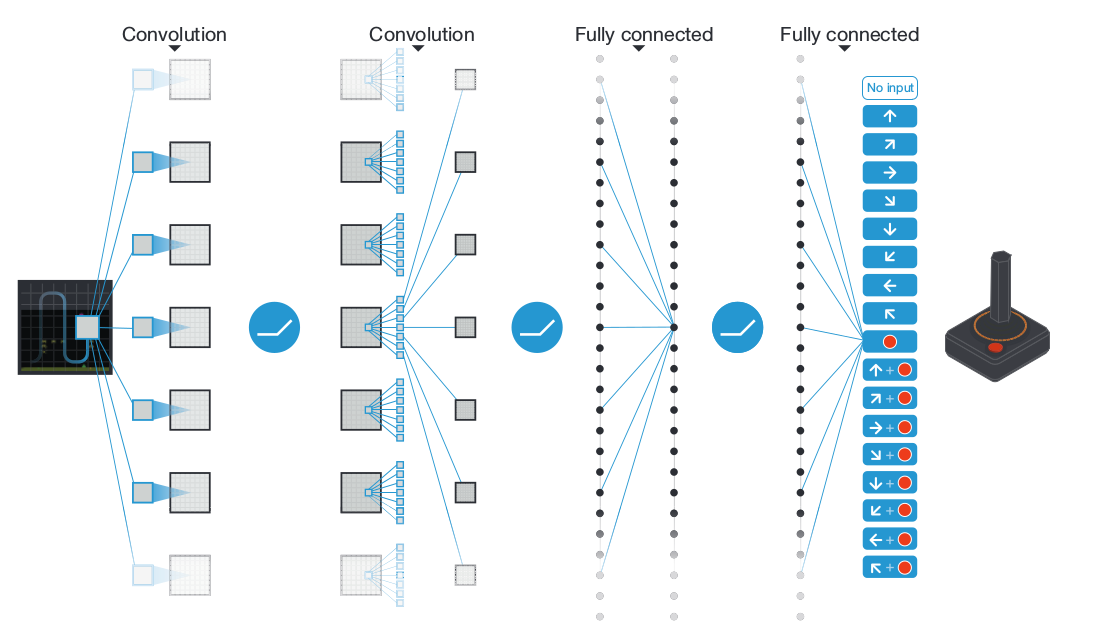
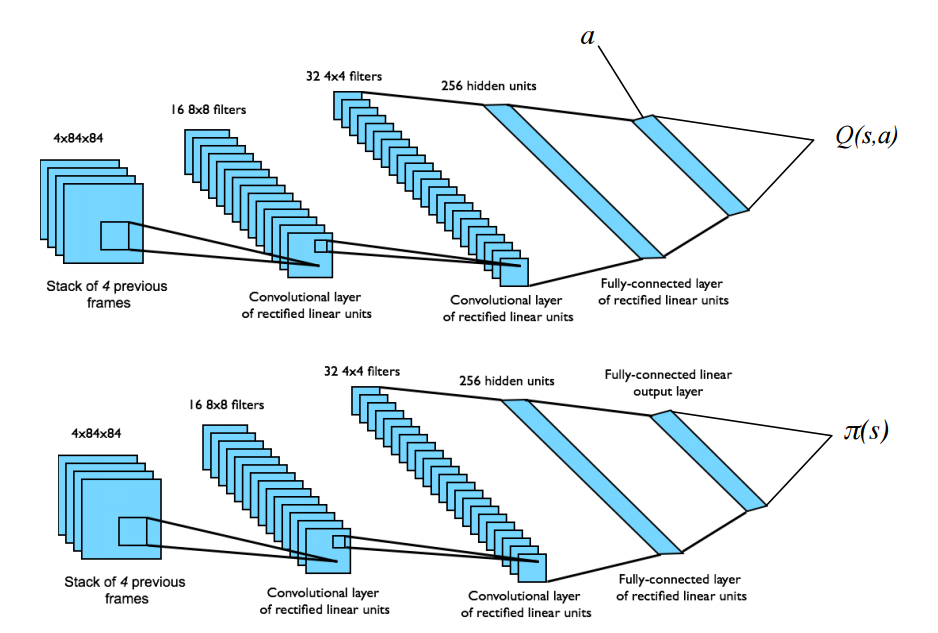
Neural Network Architecture
Algorithm Diagram (Nature 2015)
3 Tricks
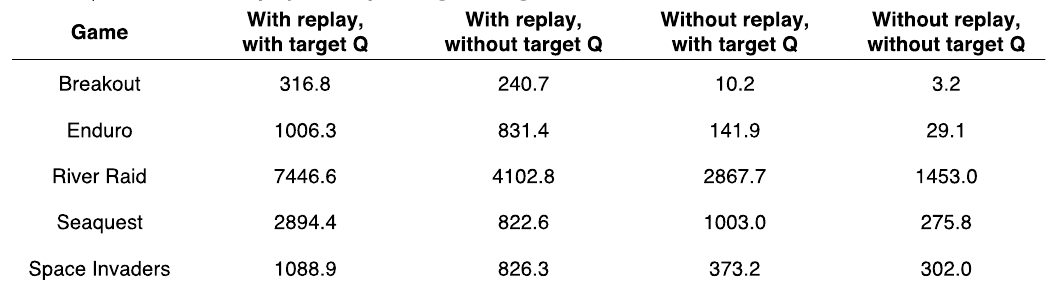
experience replay
target Q-network
clip the temporal diffierence error term
experience replay
collecting experiences into replay memory and sample a min-batch to perform gradient descent to update
target Q-network
clip the temporal diffierence error term
clipping the error term to be between -1 and 1 responds to using |x| loss function for errors outside of the (-1, 1)
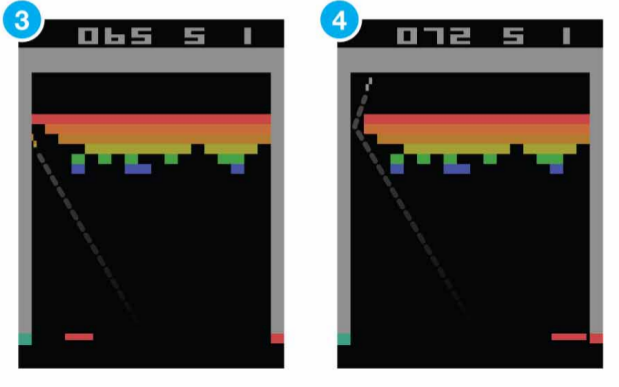
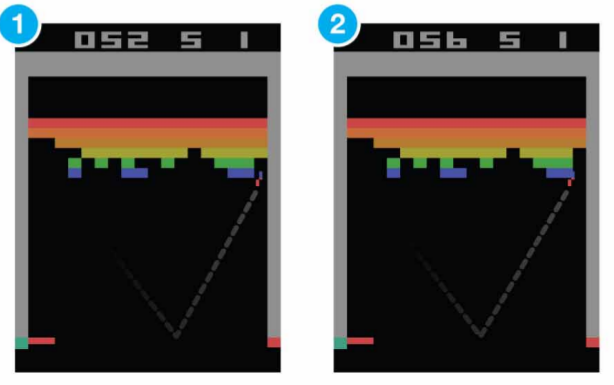
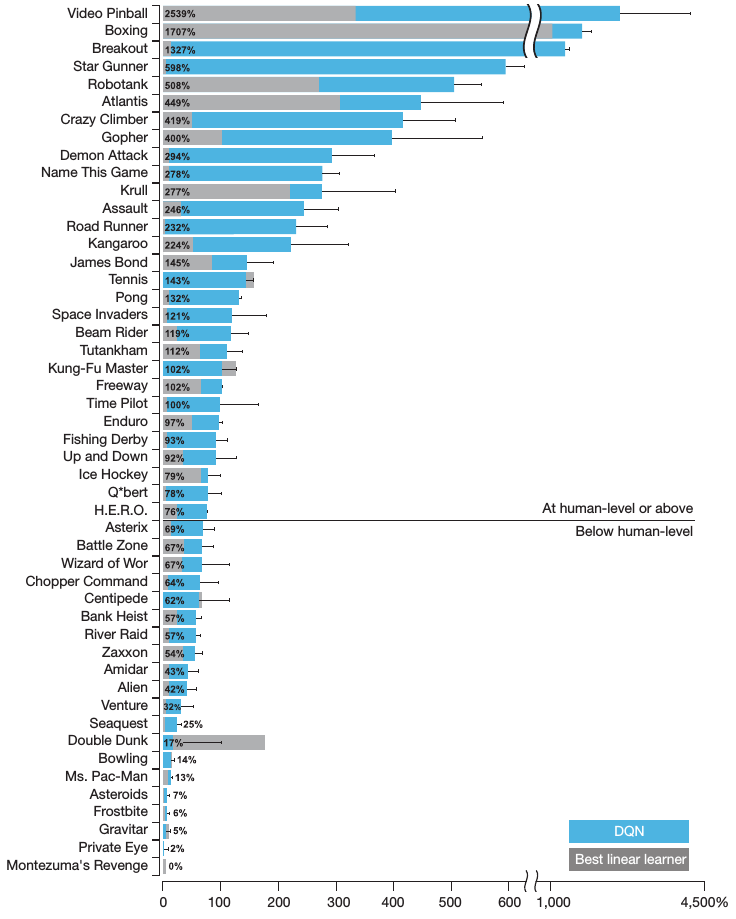
Result
perform at a level that is broadly comparable with or superior to a professional human games tester in marjority of games
Result
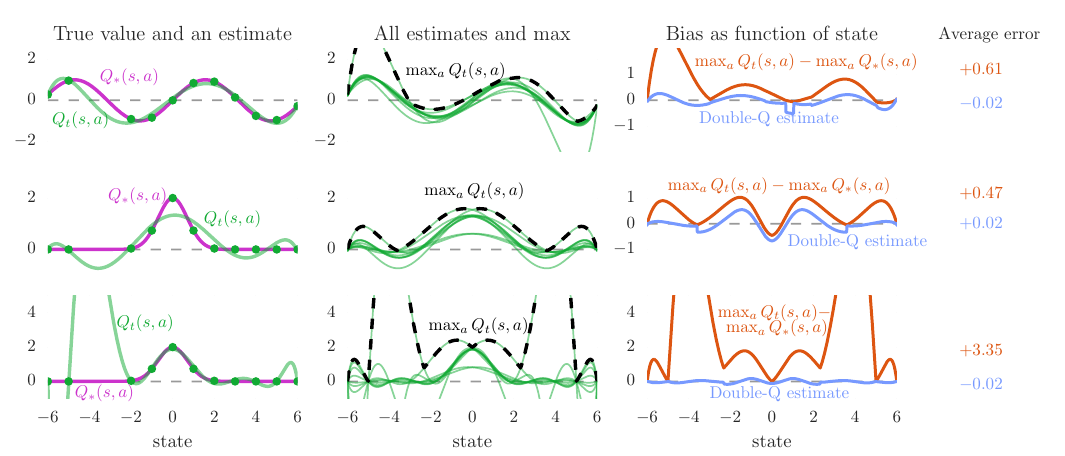
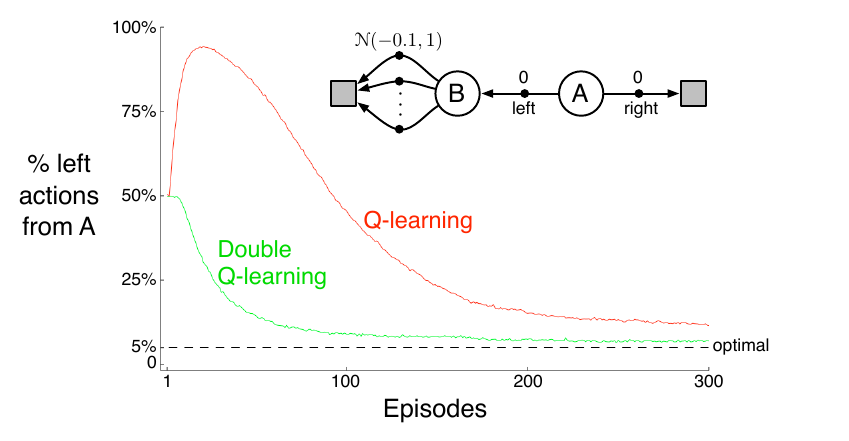
Double-Q reduce overestimations during learning
They generalized the Double Q-learning algorithm from tabular setting to arbitrary function approximation. This method yields more accurate value estimates and higher scores.
Maximization Bias and Double Q-Learning
Max operator induces maximization bias. Double Q-learning learns two independent estimates to maximize action and estimate action separately.
Double Q-Learning in tabular setting
comparison of Q-learning and Double Q-learning
Double Q-Learning Network
generalize the Double Q-learning algorithm from tabular setting to DQN
using
target
Q-Network
to
estimate
DQN and Double DQN simply replay transitions at the same frequency regardless of their significance. In this paper they proposed a framework for prioritizing experience by TD error.
mini-batch samples: i ~ uniform(i)
mini-batch samples: i ~ P(i)
Algorithm
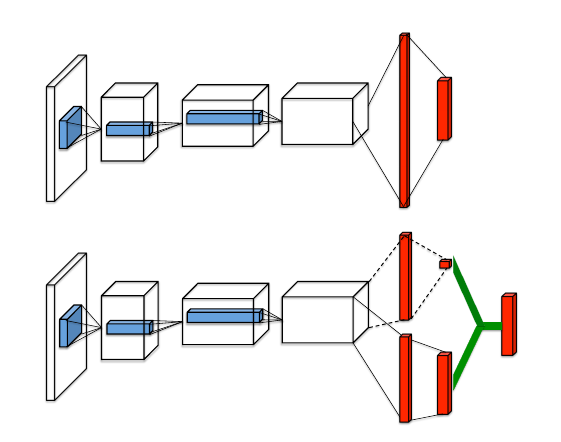
They proposed an architecture that consists of two streams that represent the value(action independent) and advantage functions.
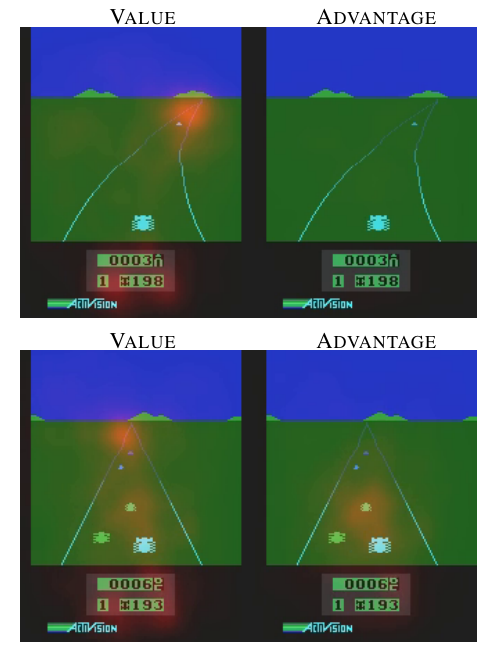
Intuitively, the dueling architecture can learn which states are (or are not) valuable, without having to learn the effect of each action for each state.
value and advantage saliency maps
The equation above is unidentifiable in the sense that the given Q we cannot recover V and A uniquely.
To address this issue of identifiability, they force the advantage function estimator to have zero advantage at the chosen action by following implementation.
or
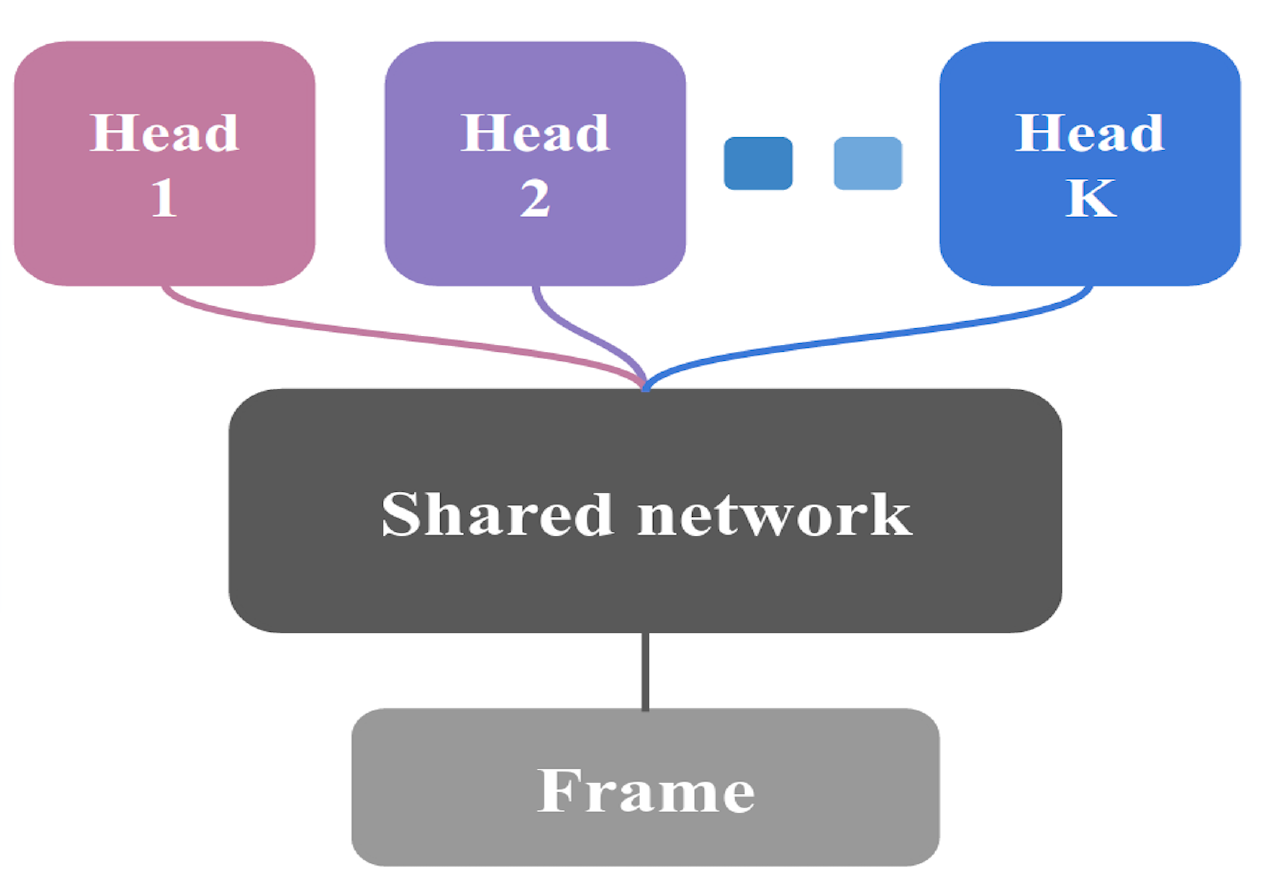
They proposed an efficient and scalable exploration method for generating bootstrap samples from a large and deep neural network. The network consists of a shared architecture with K bootstrapped "heads" branching off independently.
Gradient of the Kth Q network:
They proposed an actor-critic, model-free algorithm based on the deterministic policy gradient that can operate over continuous action spaces.
Critic loss:
Actor gradient:
critic estimates value of current policy by Q-learning
actor updates policy in direction that improves Q
This part of gradient will be calculated from critic network by backpropagating into a
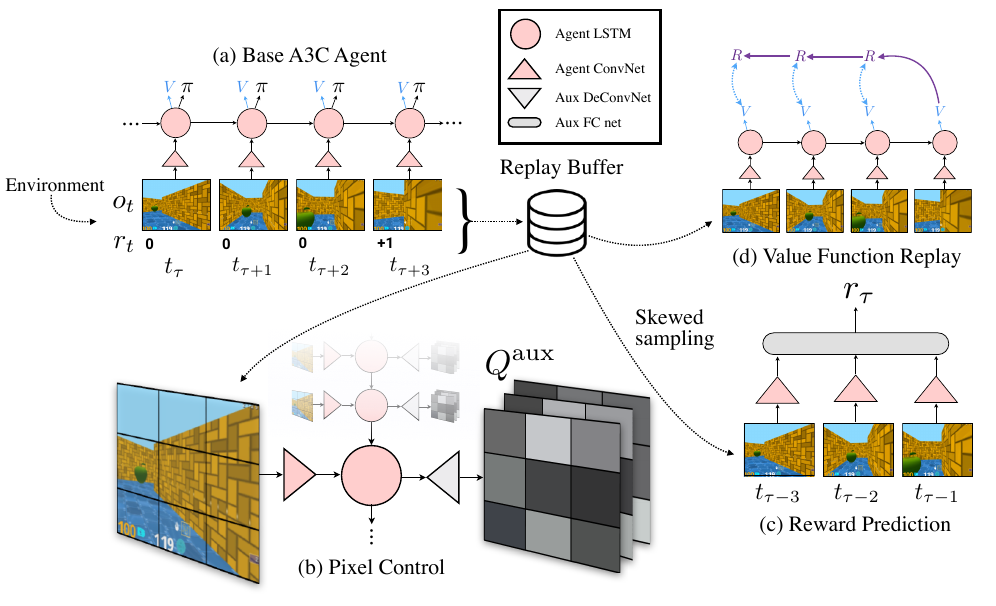
They proposed asynchronous variants of four standard reinforcement learning algorithms and showed that an asynchronous variant of actor-critic surpassed the state-of-art.
estimation of advantage
auxiliary control tasks
auxiliary reward tasks
This paper presents a stable actor-critic deep reinforcment learning method with experience replay by truncated importance sampling with bias correction, stochastic dueling network architecture and a new trust region policy optimization method.
The reactor is sample-efficient thanks to the use of memory replay, and numerical efficient since it uses multi-step returns.
Exploration
DQN - epsilon greedy
A3C - entropy loss over action space
NoisyNet- induce parametric noise by replacing the final linear layer in value network or policy network with noisy layer
noise random variables
Thanks to Richard Sutton's book and David Silver's slides.