MLRG Fall 2022: Transformers
Title Text
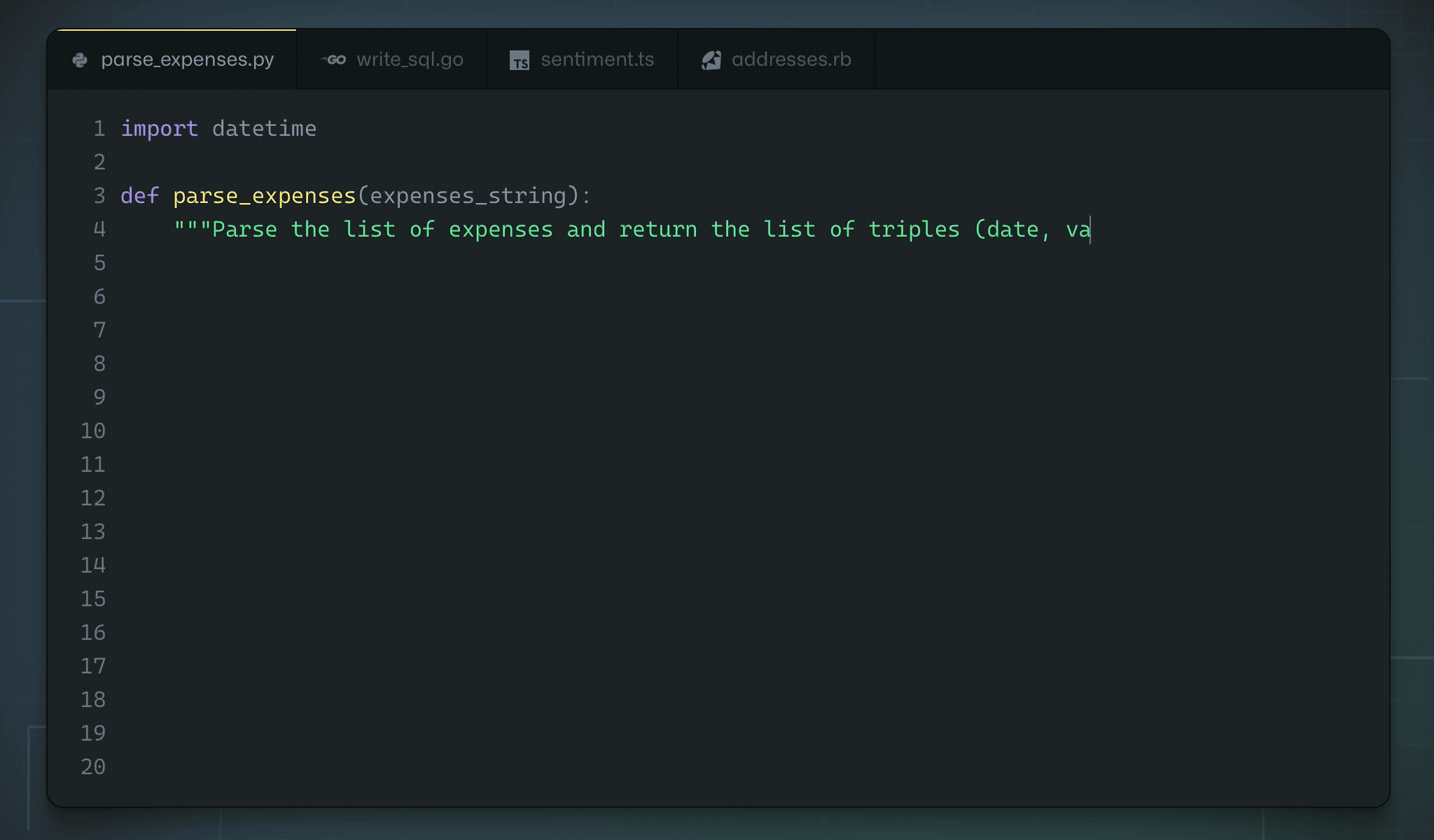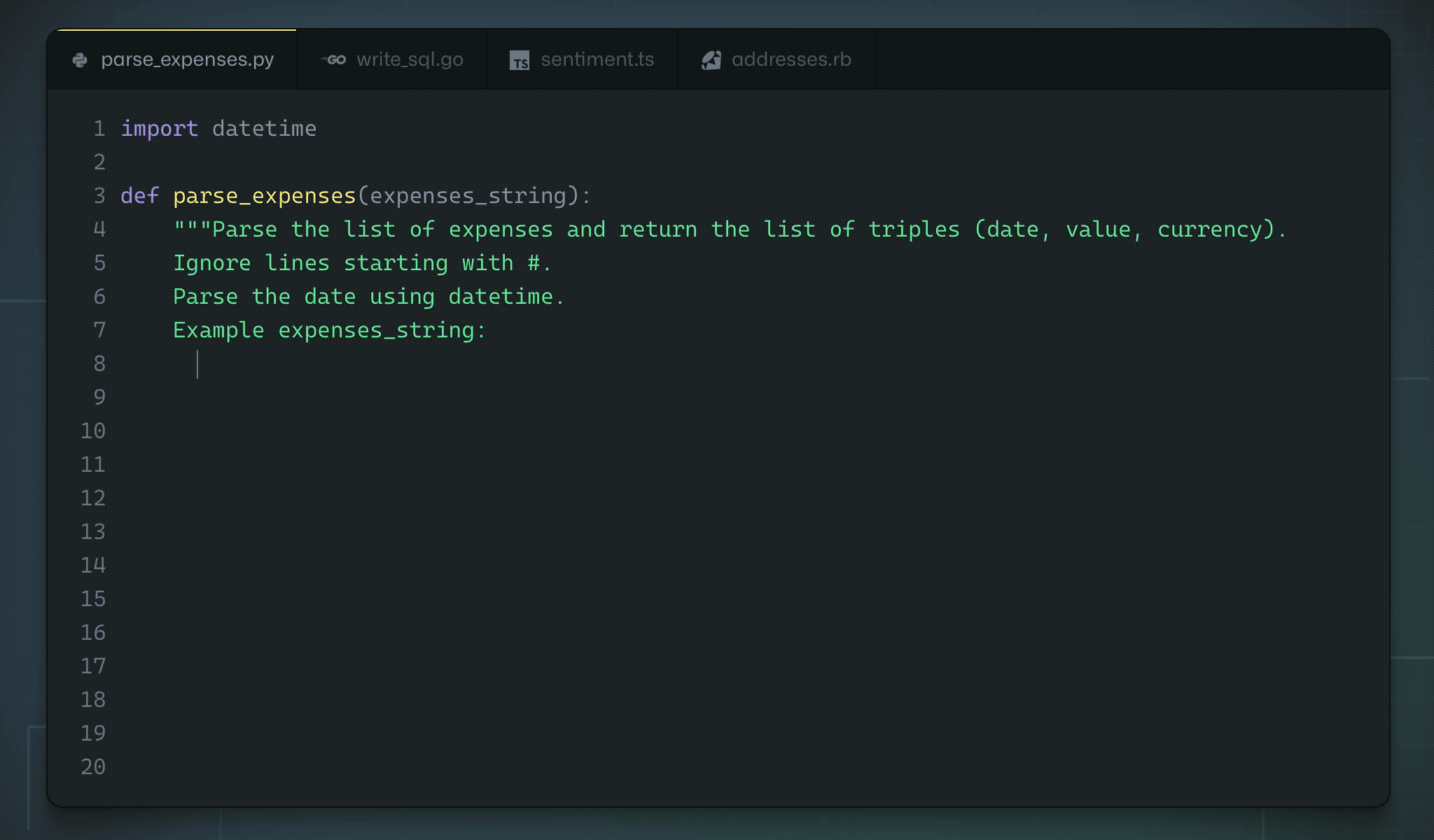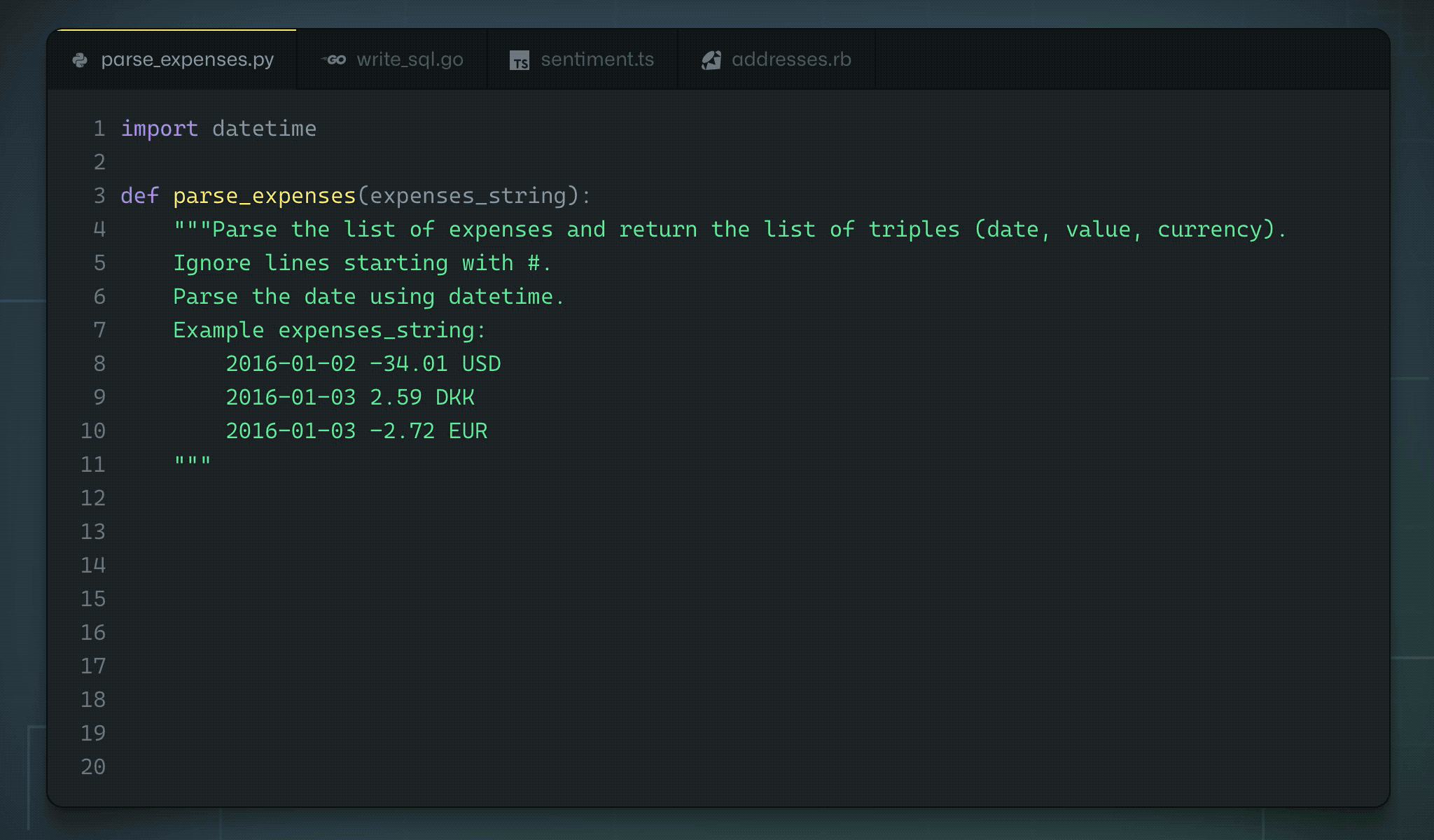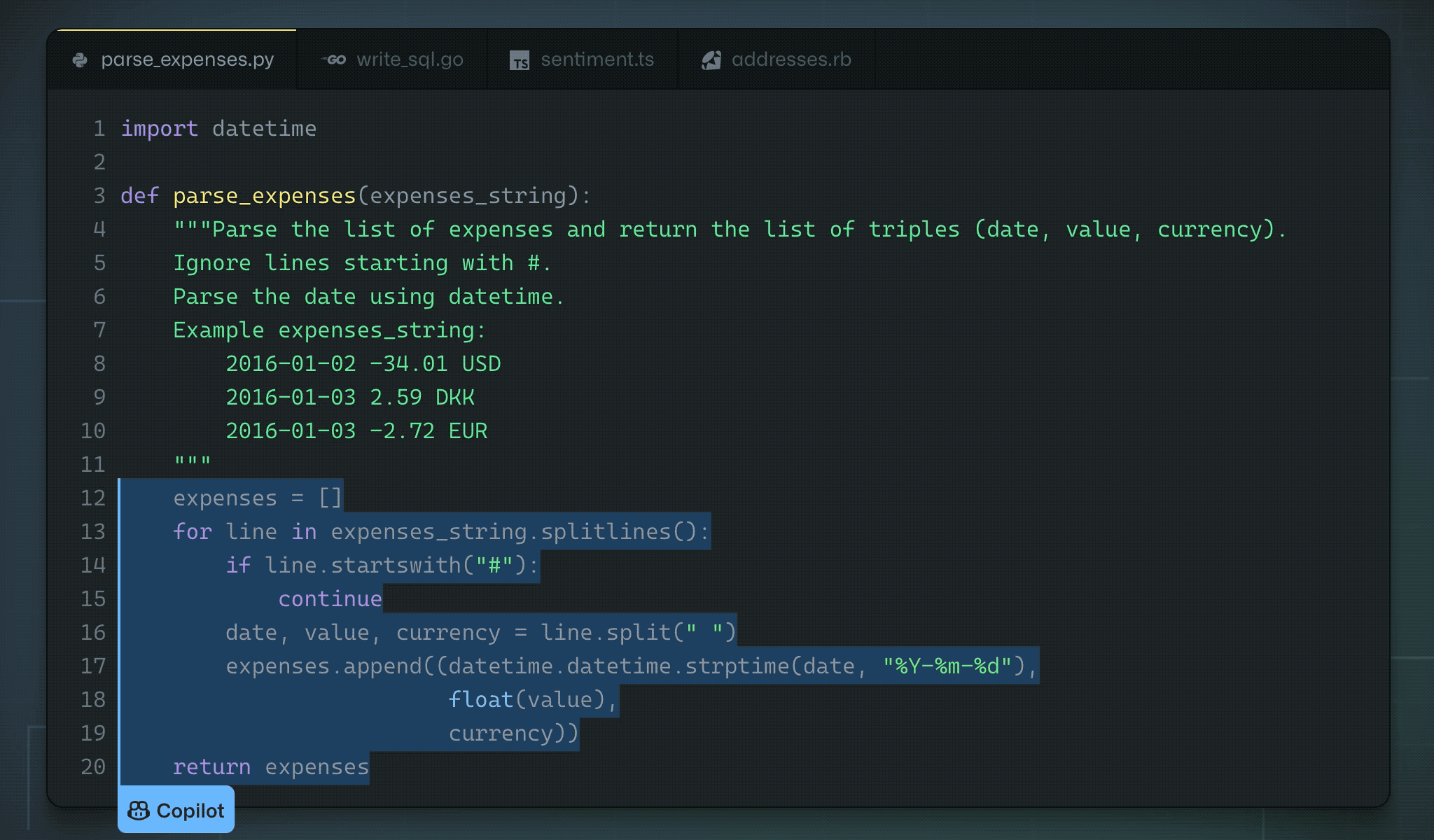

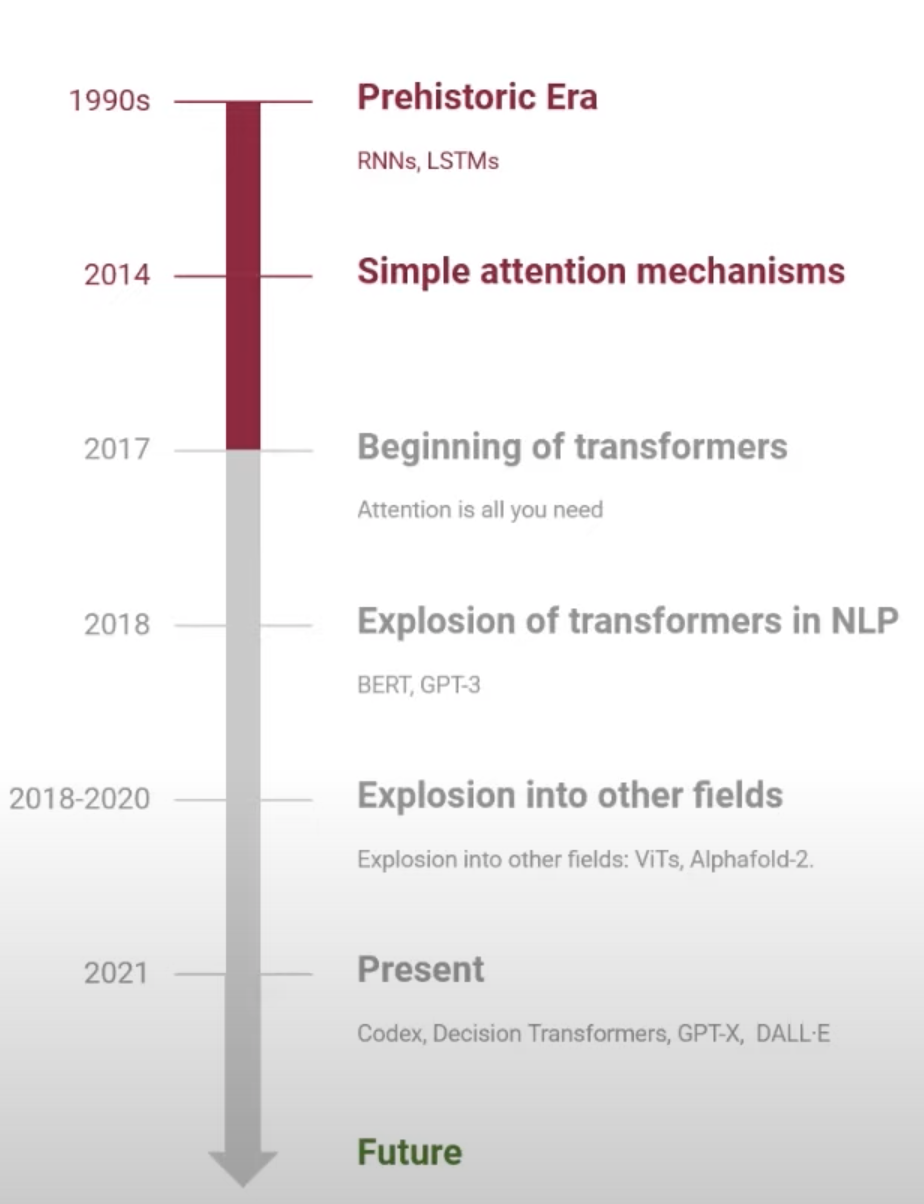
A brief history...
RNNs
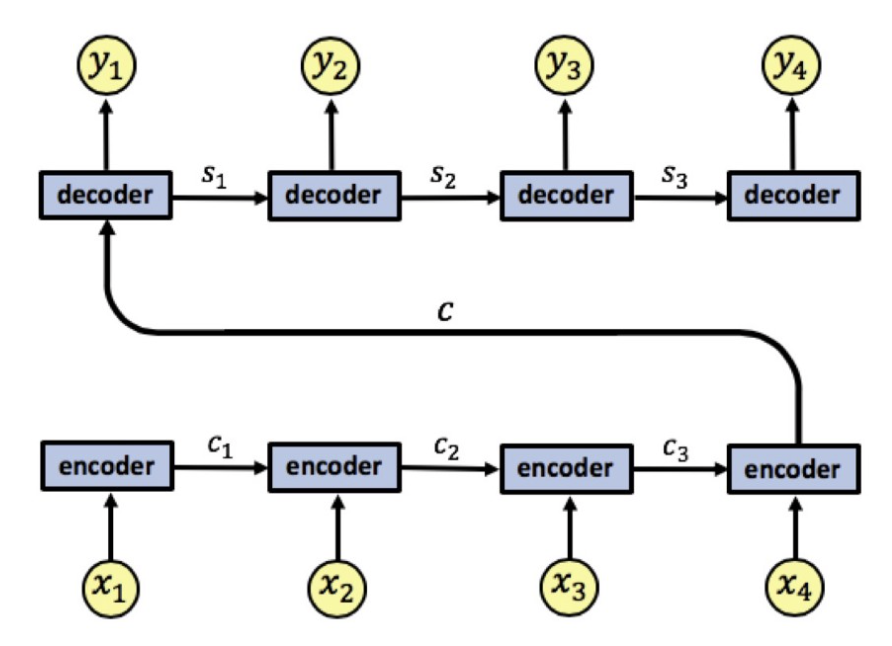
RNNs + Attention
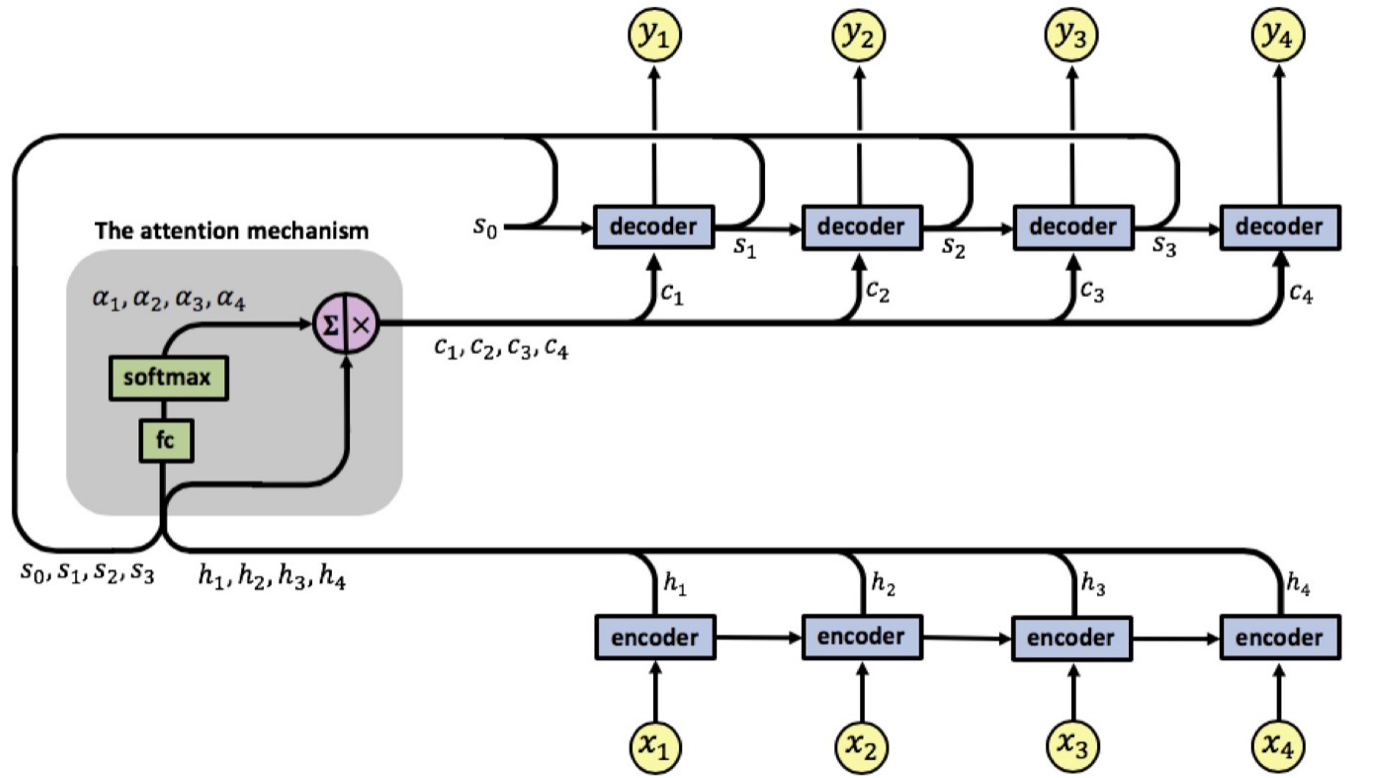
RNNs + Attention

Transformers
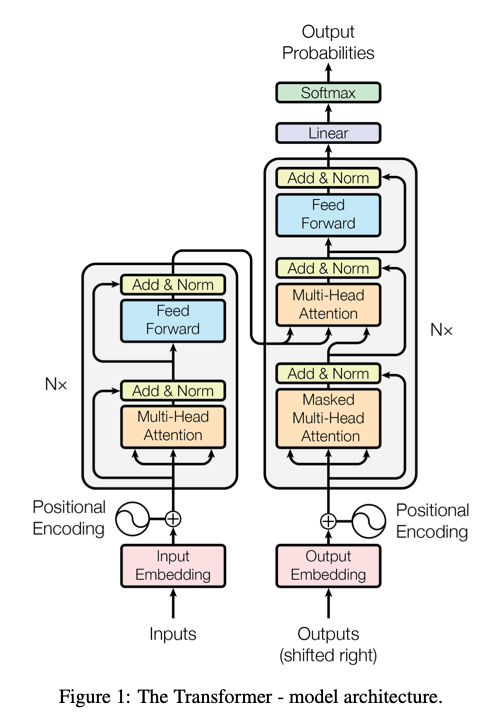
Transformers at Scale
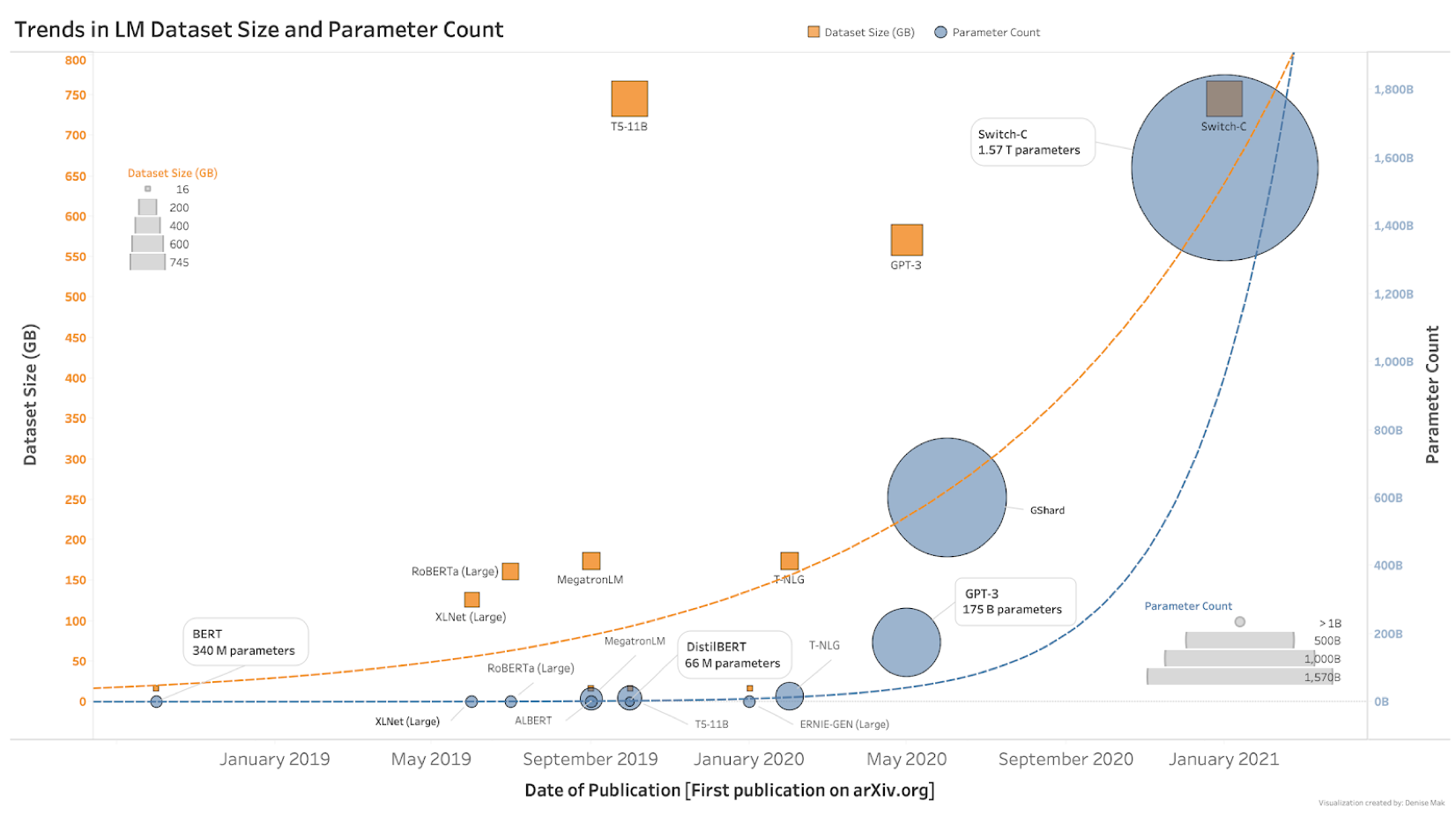
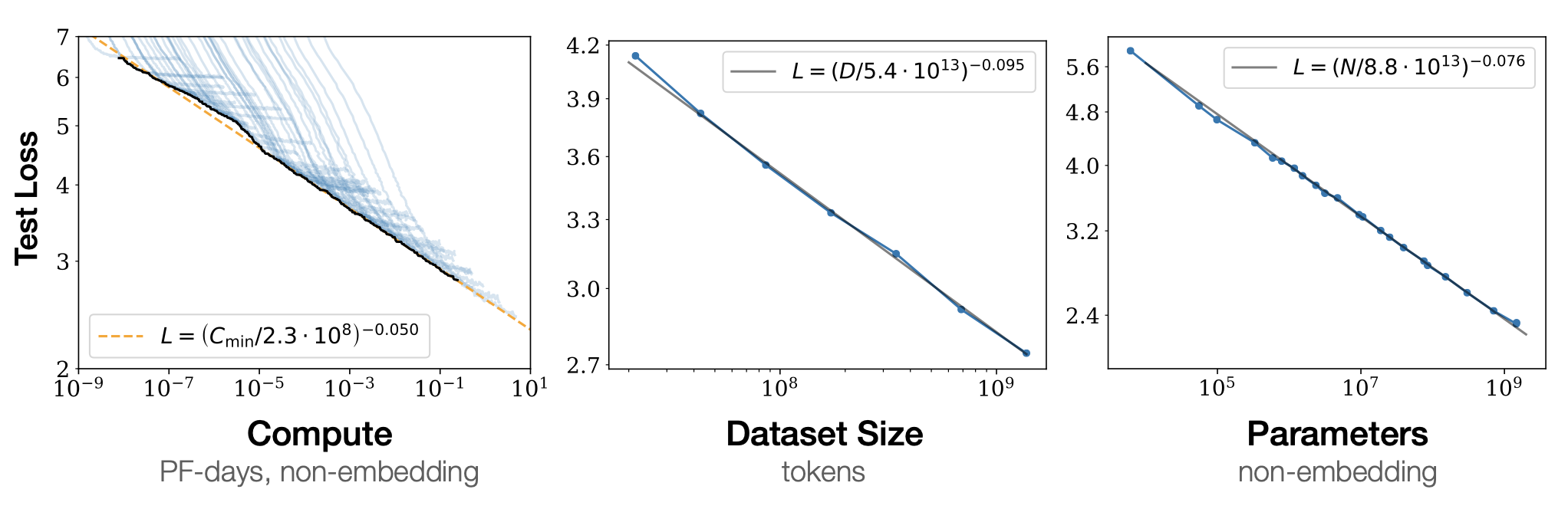
Transformers at Scale




Goals:
- Understand how and why transformers work
- Explore the phenomenon of emergent abilities in LLMs as they are scaled up
- Learn how they are being applied in NLP and beyond
Papers
Attention is All You Need (Vaswani et al., 2017)
-
The original Transformer paper.
-
Goal: Get us all on the same page with respect to what makes up a Transformer:
-
Attention
-
Self-Attention
-
Positional Encodings
-
etc.
-
Language Models are Few-Shot Learners
-
The GPT-3 paper
-
A look at the trend of increasingly large LMs and, more importantly, their ability to perform well on tasks unseen during training.
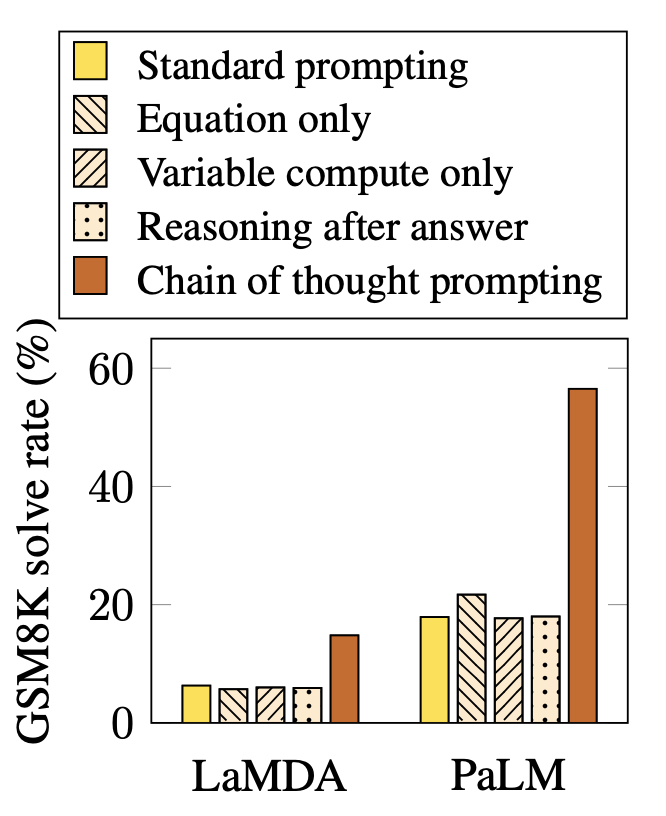
Chain of Thought Prompting Elicits Reasoning in Large Language Models
-
The reasoning capabilities of language models can be improved by prompting them appropriately.
-
Other papers linked in document.
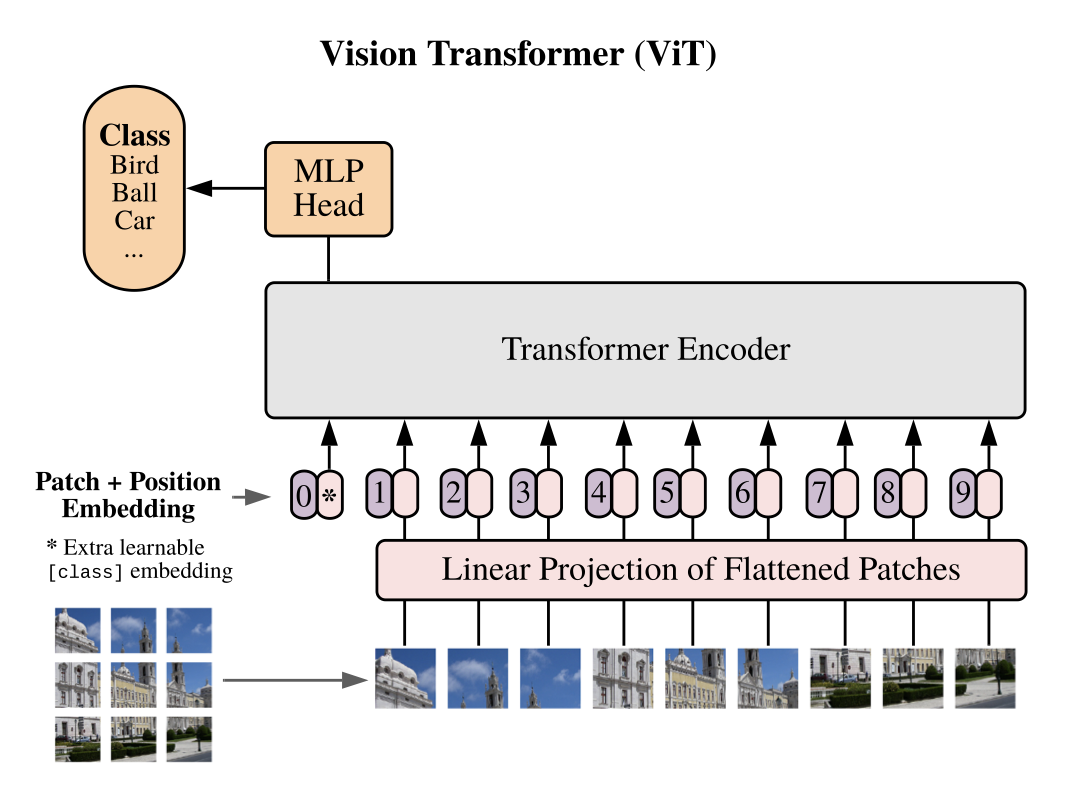
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
-
Transformers as an alternative to CNNs?
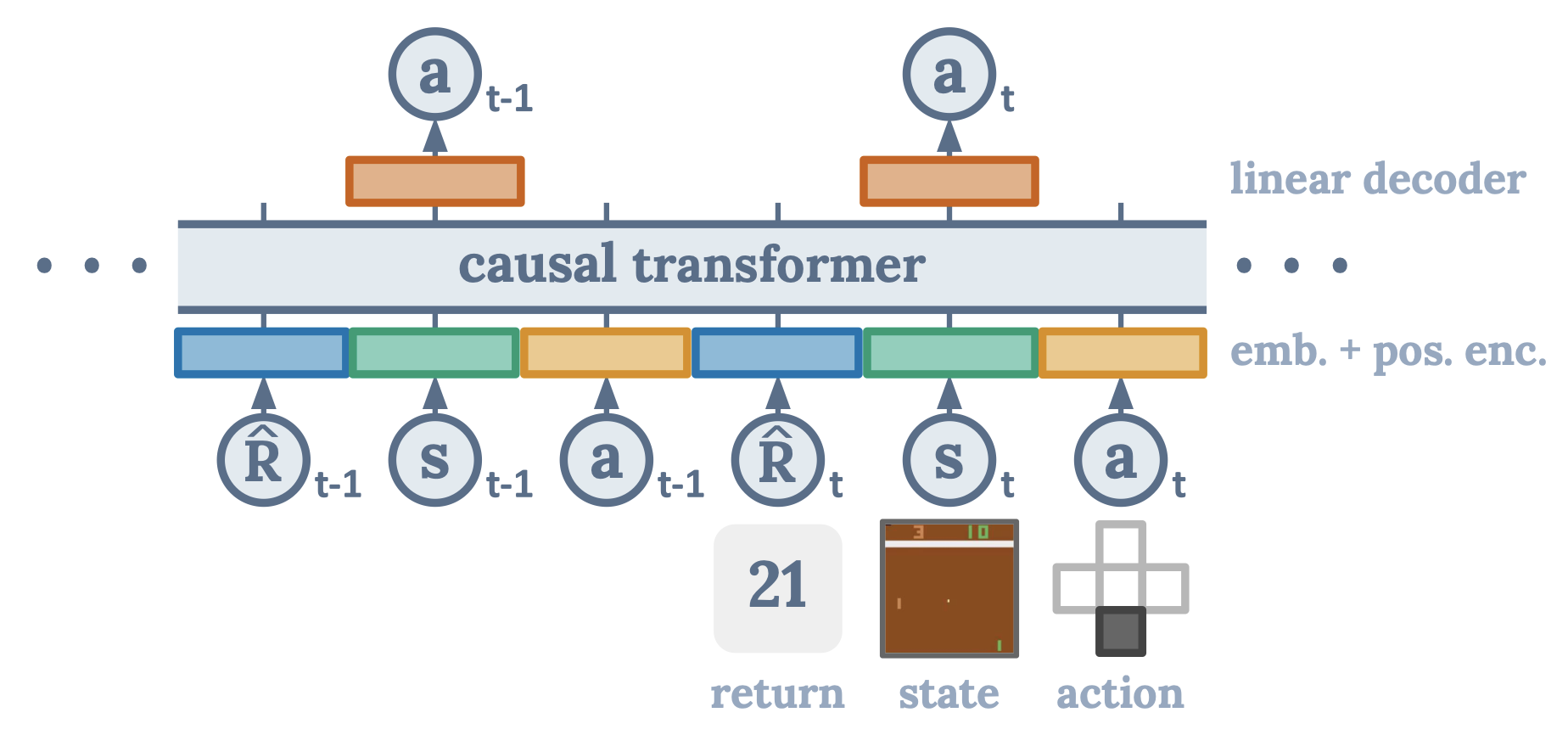
Decision Transformer: Reinforcement Learning via Sequence Modeling
-
Recasts reinforcement learning as a conditional sequence modelling problem
-
Matches or exceeds performance of SoTA model-free offline RL algorithms
Neural Scaling Laws + Exploring the Limits of Large Scale Pre-Training (2 papers)
-
Neural Scaling Laws: Empirically shows that the performance of LLMs follows a power law
-
Exploring the limits: investigates the implications of this for downstream tasks
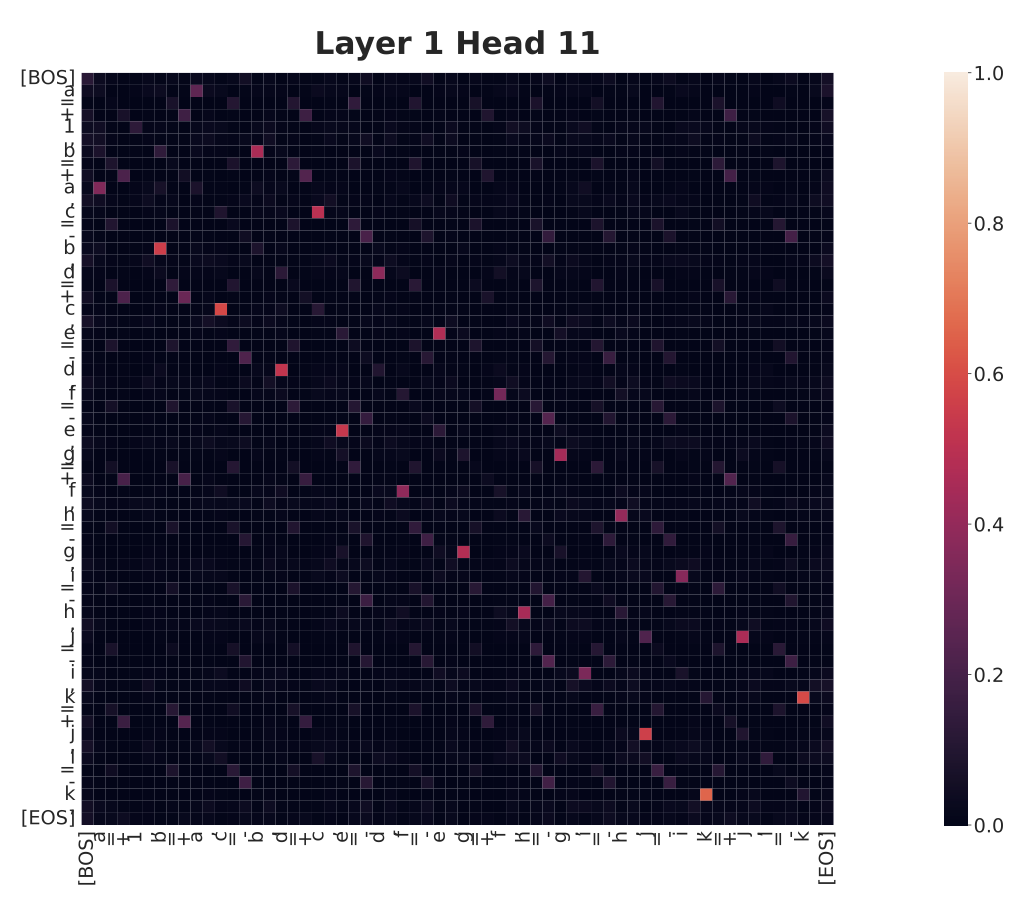
Unveiling Transformers with LEGO: A Synthetic Reasoning Task
-
An attempt to better understand how/what transformers learn by training them on a simple reasoning task.
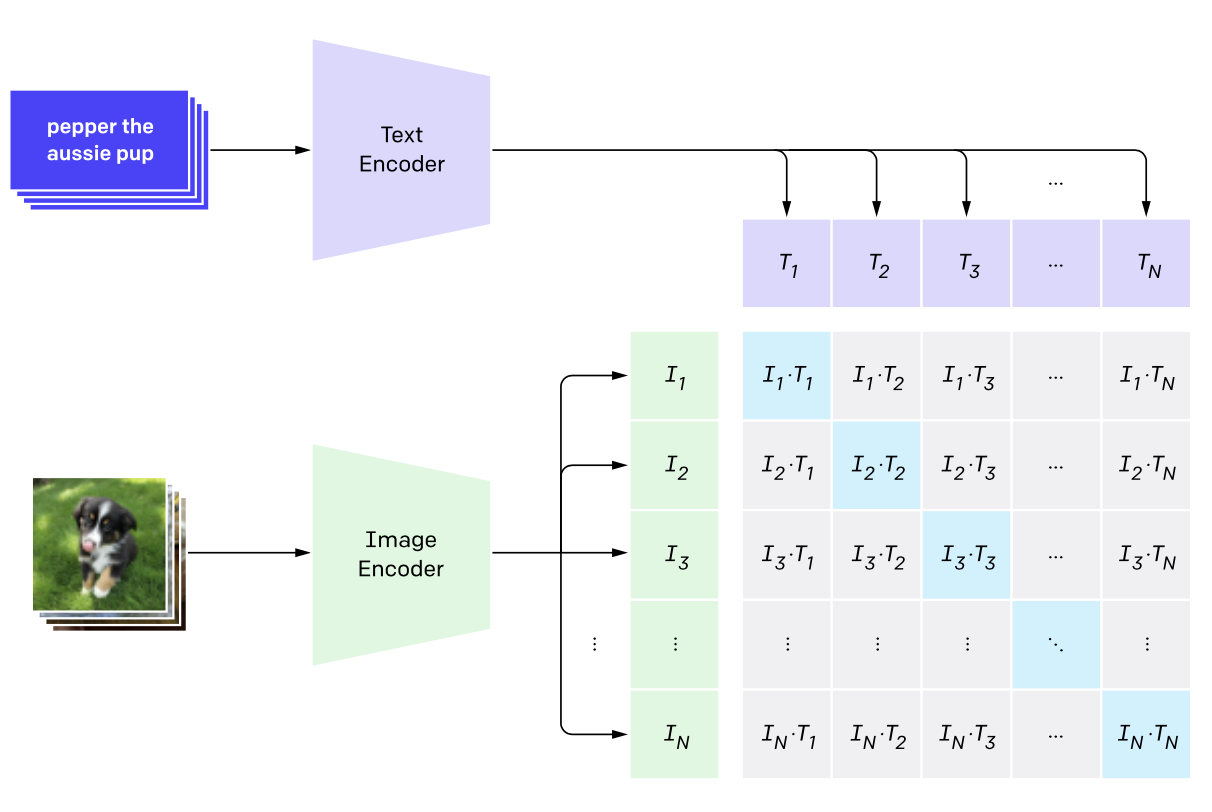
Learning Transferable Visual Models From Natural Language Supervision
-
A joint image/language model, trained to match captions to images
-
Impressive few-shot transfer to downstream tasks
-
An essential part of DALL-E's architecture
Hierarchical Text-Conditional Image Generation with CLIP Latents
-
DALL-E
-
Requires (at least) a brief explanation of diffusion models
