Avoiding Spark Pitfalls at Scale
About me
- Software Engineer on data science team at Coatue Management
- Scala for the last 5.5 years, data engineering for the last 2 years
- Brooklyn! (by way of Texas)


(I really like coffee
and
whisky)
Yamazaki Distillery
Little Nap Coffee Stand
What this talk is not about
- Machine learning, deep learning, AI
- Real-time streaming
- Whinefest about Spark's API
What this talk is about
- Practical lessons learned from production Spark for large scale batch ETL
- (and dirty, subversive tricks)
- Spark 2.2.0
-
Know your data & code
-
Skew
-
Execution Engine
-
Configuration
-
API
-
Typeful APIs
Know your data & code
- Know the cardinality and distribution of your data for:
- group by operations
- join keys
- windowing operations
- partition keys
- Repartition to finer grain partitions prior to slow stages to reduce straggler task problem
val ds: Dataset[MyType] = spark.read.parquet(...)
ds.repartition(ds.rdd.getNumPartitions * 2)
.map(slowFn)-
Know your data & code
-
Skew
-
Execution Engine
-
Configuration
-
API
-
Typeful APIs
Skew
- What is skew?
- In the context of data engineering, when certain keys appear more often than others in an uneven fashion
- Can adversely affect parallelization of tasks
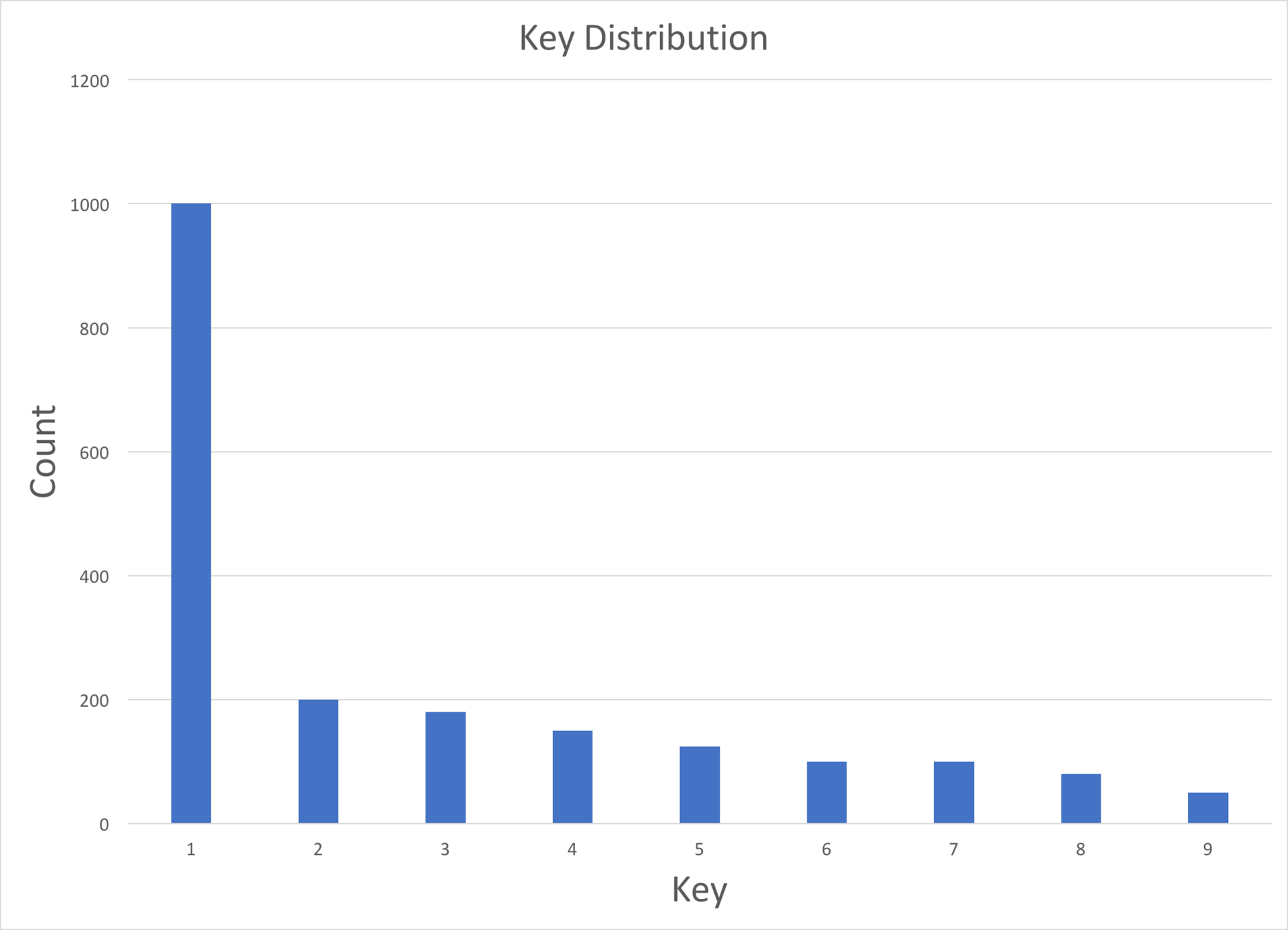
Skew
- Data skew: 90% of the hard problems we faced (other 10% probably java.io.Serializable)
- Often the cause of dreaded OutOfMemory errors
- Don't repartition on skewed keys
- SortMergeJoin operations on skewed join keys can OOM unless you have good spill thresholds
- Or, use a skew join implementation...
Skew
- Skew join: isolated map (broadcast) join
- Bifurcate the LHS (left-hand side) and RHS:
- Filter rows with keys that are 'hot' (appear over some hotKeyThreshold times) => (hotLHS, hotRHS)
- Everything else => (coldLHS, coldRHS)
- Broadcast join hotLHS with hotRHS
- Regular join coldLHS with coldRHS
- Union results of 2 and 3
- Bifurcate the LHS (left-hand side) and RHS:
- Assume that hotRHS is small enough to be broadcasted or tune the threshold
-
Know your data & code
-
Skew
-
Execution Engine
-
Configuration
-
API
-
Typeful APIs
Execution Engine
-
Timeouts with long-running stages and broadcast joins
- Increase spark.sql.broadcastTimeout
val slowBroadcast = dataset
.map(slowFunction)
.joinWith(broadcast(otherDataset), joinKey)- Partitioning and coalescing
- Beware of lazy coalescing, can reduce parallelism
val aggregation = dataset.repartition(1000)
.groupBy(...)
.agg(...)
.coalesce(1) // will force upstream computations to 1 partition/task,
// .repartition(1) insteadExecution Engine
- Very long, lazily built queries
- Beware: Janino codegen errors, Catalyst trouble
- Can be hard to reason about performance
- Dirty hack: force evaluations with actions
val veryLongQuery = dataset.groupBy(...)
.agg(...)
.map(processRow)
.joinWith(anotherDataset)
.filter(filterFn)
.groupBy(...)
.agg(...)
// Break up long query with caching and counting (low overhead strict action)
val query1 = dataset.groupBy(...)
.agg.cache()
query1.count
val query2 = query1.map(processRow)
.joinWith(anotherDataset).cache()
query2.count
// etc-
Know your data & code
-
Skew
-
Execution Engine
-
Configuration
-
API
-
Typeful APIs
Configuration
- The knobs are there (if you know where to dig)
- Spark docs + source code + JIRA
-
Parallelism (partitions) - start at 2x available cores
- spark.default.parallelism
- spark.sql.shuffle.partitions
- Spill thresholds - tune high enough not to spill to disk prematurely, but low enough to avoid OOMs
- spark.shuffle.spill.numElementsForceSpillThreshold
- spark.sql.windowExec.buffer.spill.threshold
- spark.sql.sortMergeJoinExec.buffer.spill.threshold
- SPARK-13450
Configuration
- Dealing with slow or faulty nodes:
- Speculation - spark.speculation.*
- Blacklisting - spark.blacklist.*
- Task reaping - spark.task.reaper.*
-
Dropped task reporting in Spark UI?
- Tune spark.scheduler.listenerbus.eventqueue.size
- SPARK-15703
-
Know your data & code
-
Skew
-
Execution Engine
-
Configuration
-
API
-
Typeful APIs
API
-
map vs. select
- If just selecting columns, select is more performant
- Plain Scala functions aren't optimized by Catalyst
- Instance members are re-initialized when crossing serialization/encoding boundaries (e.g. shuffle)
- Beware of expensive members:
case class MyData(a: String, b: Int) {
val expensiveMember = { ... } // gets reinitialized
}-
Know your data & code
-
Skew
-
Execution Engine
-
Configuration
-
API
-
Typeful APIs
Typeful APIs
- Dataset[T] brings some type safety back over DataFrame, but sacrifices performance
- shapeless-driven API over Catalyst: TypedDataset[T]
- See my previous intro talk
- QDSL (Quoted Domain Specific Language) for Spark
- Spark SQL as target language
Interested?
- What we do: data engineering @ Coatue
- Terabyte scale, billions of rows
- Lambda architecture
- Functional programming
- NLP
- Stack
- Scala (cats, shapeless, fs2, http4s, etc.)
- Spark
- AWS (EMR, Redshift, etc.)
- R, Python
- Tableau
- Chat with me or email: lcao@coatue.com
- Twitter: @oacgnol