graphql/dataloader
微介紹
複習一下 graphql server
schema
type User {
id: ID!
name: String!
posts: [Post]!
}
type Post {
id: ID!
title: String!
content: String!
}
type Query {
users: [User]!
}
針對每個 field 寫 resolver
如果沒寫的話就看拿到的 object 有沒有對應的欄位
有的話 那個值如果不是 function 就直接用那個值
如果是 function 的話就用那個 function 當作 resolver
例如:
users 有寫 resolver
=> 拿到很多 user object
=> id 跟 name 有了,直接用
=> posts 是一個 function,執行後拿到很多 post object
...
query {
users {
id
name
posts {
id
title
}
}
}
這個設計讓 server 可以做 lazy evaluation
不管 query 有幾層都容易處理,也讓 schema 可以做到 circular referencing
不過:
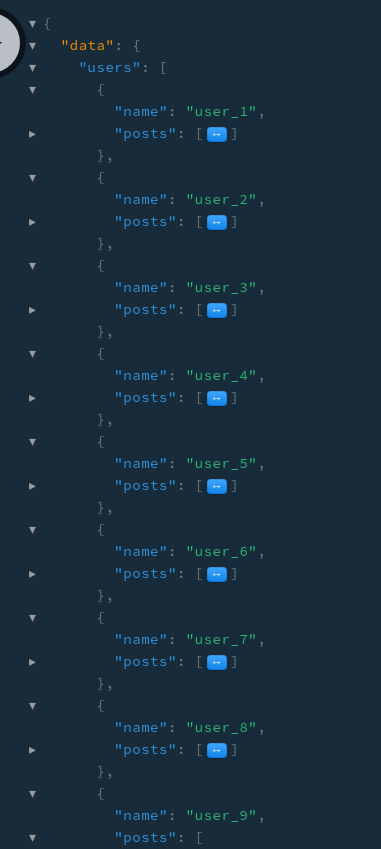
跟資料庫要資料的時候,會有一點小問題
1
2
3
4
5
6
7
如果有 n 個 user,就會跟資料庫 query n + 1 次
(這就是所謂的 n + 1 query)
為什麼 query 很多次會是個問題
1. 感覺就比較耗資源
2. 因為 connection pool 有限制同時連線數
什麼是 connection pool
和資料庫建立連線很費時,所以大多 server 都會 reuse connection
事先建立好 connection,放在 pool 裡,有人需要就拿去用
connection pool 都有最大 connection 的數量
限制每台 server 佔用的 connection 在合理的範圍
什麼是 connection pool
sequelize 預設最大連線數是 5
沒拿到 connection 就要等別人用完
所以沒辦法 n 個 query 一起出發
n 很大的話就要等很久
甚至一個 request 還沒結束還要先等別的 request
server
database
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
提升效能的方法有哪些
query {
users {
id
name
posts {
id
title
}
}
}
resolver 先看看下一層有哪些 field 是需要的
例如這個 query 裡面需要 posts
那在跟資料庫要 users 的時候,就順便一起抓他們的 posts
或是乾脆不用看,就直接一起抓回來
這樣 n + 1 直接變成 1 ~
提升效能的方法有哪些
query {
users {
id
name
posts {
id
title
comments {
id
content
user {
id
name
posts {
id
title
comments {
id
content
user {
id
name
posts {
id
title
}
}
}
}
}
}
}
}
}
不過要再下一層或是再下下一層,還是沒有辦法
硬要做的話,也容易搞得程式碼亂亂的
graphql/dataloader
是一個源自 FACEBOOK (的一位員工)的套件
可以幫助解決這個問題
本來是在各個 function 裡面分別跟資料庫要資料
用 dataloader 的話
換成跟 dataloader 要資料
dataloader 收集完 再一起跟資料庫拿
例如本來在 user 的 posts 這個 function 裡面
我們要自己去跟資料庫要 posts ( by userId )
用 dataloader 的話,我們在 function 裡面就不直接跟資料庫 query
而是把 userId 給 dataloader,請他給我們 posts
然後在 dataloader 只要實作 batch function ( array to array ) 就好了
dataloader
key
keys
=====>
values
value
batch function
key
key
key
value
value
value
本來是這樣
用 dataloader 變這樣
User.prototype.posts = function getPosts() {
return db.models.Post.findAll({
where: {
UserId: this.id,
},
});
}
User.prototype.posts = function getPosts(args, { postsLoader }) {
return postsLoader.load(this.id);
}
然後 postsLoader 只要實作 batch 處理的 function
剛剛 function 的 postsLoader 是怎麼傳進來的
先簡介一下 resolver 的 4 個參數
const resolver = (parent, args, context, info) => {
...
}
const apolloServer = new ApolloServer({
schema,
context: ({ request }) => ({
jwtPayload: getJWTPayloadFromRequest(request),
postsLoader: createPostsLoader(),
}),
});
每個 request 進來的時候
我們可以設 context
接下來每個 resolver 都拿得到~
loaders/createPostsLoader.js
import DateLoader from 'dataloader';
import { Op } from 'sequelize';
import groupBy from 'lodash/groupBy';
import { db } from '../db';
const batchPosts = async (userIds) => {
const posts = await db.models.Post.findAll({
where: {
UserId: {
[Op.in]: userIds,
},
},
});
const postsMap = groupBy(posts, 'UserId');
return userIds.map((userId) => postsMap[userId]);
};
export default () => new DateLoader(batchPosts);
一次跟 db 拿全部
照 UserId 整理好
要對應原來的順序
keys => values
( array to array )
dataloader 怎麼知道什麼時候可以跟 db 要資料?
我猜:
dataloader 只要不在同一個 tick 執行 batch 就好了
node: process.nextTick(func)
node or browser: setTimeout(func)
因為 n 個 user 是同時拿到的
他們的 posts method 會在同一個 callstack 執行
看一下前後差別
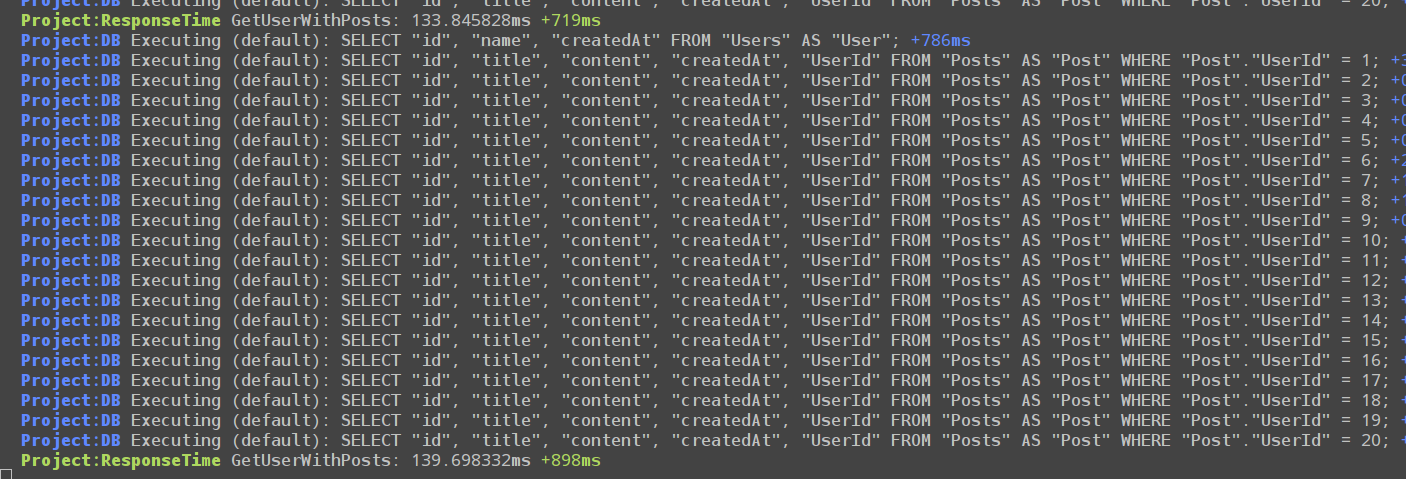

來測一下花費的時間
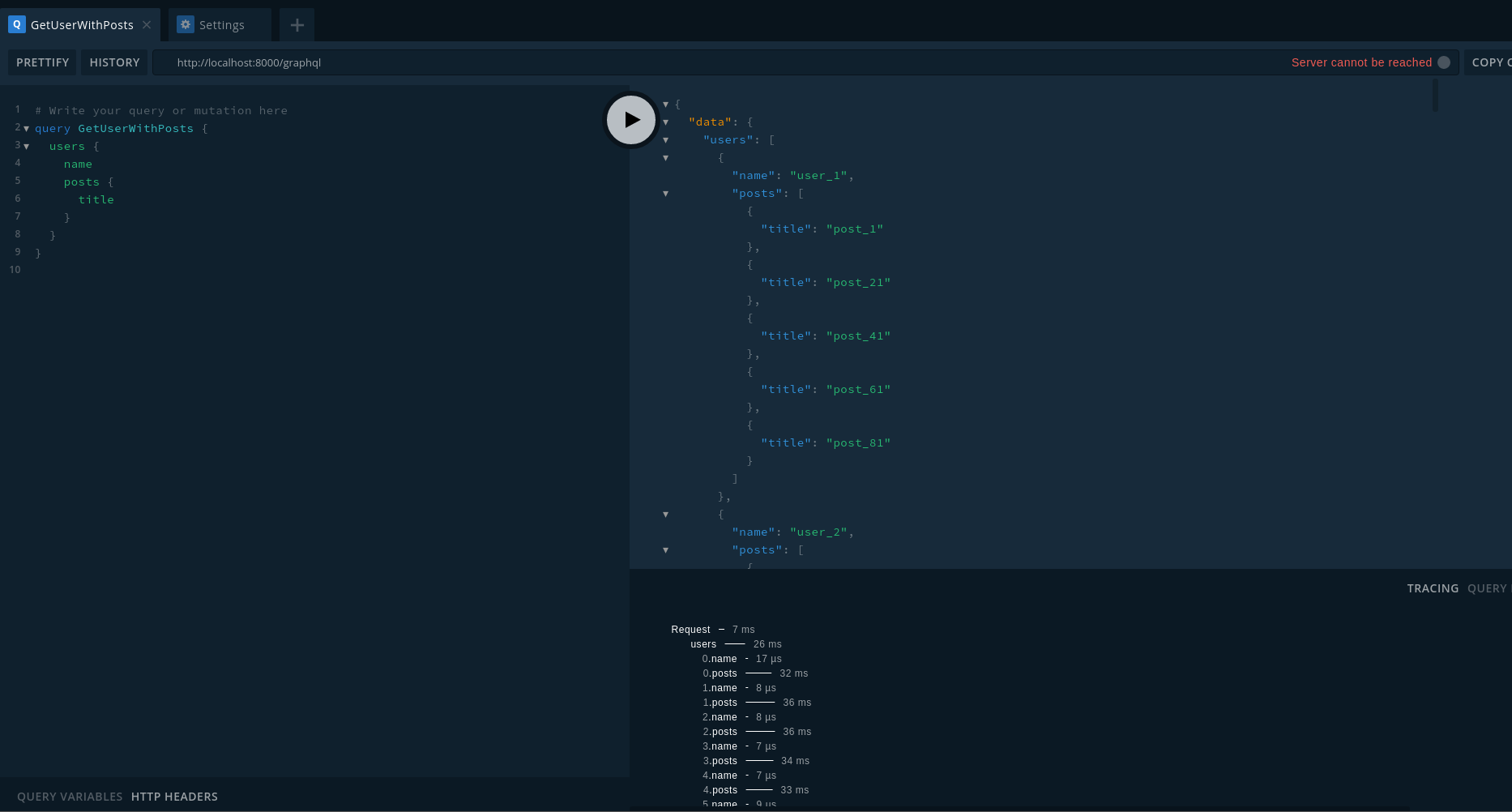
1. apollo server 可以開 tracing
可以從 playground 看到每一個 field 花了多少時間
const apolloServer = new ApolloServer({
schema,
context: () => ({
postsLoader: getPostsLoader(),
}),
tracing: true,
});
來測一下花費的時間
來測一下花費的時間
2. 也可以自己 log 整個 request 處理的時間
在 apollo server 前面加一個 middleware,設定 response 完要算時間然後 log 出來
app.use((ctx, next) => {
if (ctx.request.path === '/graphql') {
const startTime = process.hrtime();
ctx.res.on('finish', () => {
const { operationName } = ctx.request.body;
const [aa, bb] = process.hrtime(startTime);
const elapsedTimeInMs = aa * 1000 + bb / 1e6;
debugResponseTime(`${operationName}: ${elapsedTimeInMs}ms`);
});
}
return next();
});
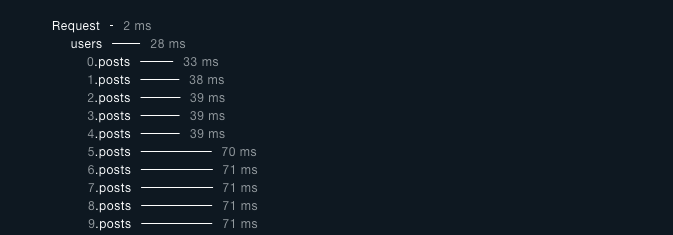
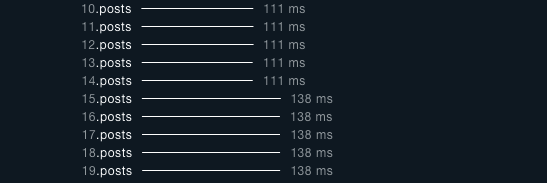
沒跟 users 一起抓 posts,也沒有用 dataloader 的結果
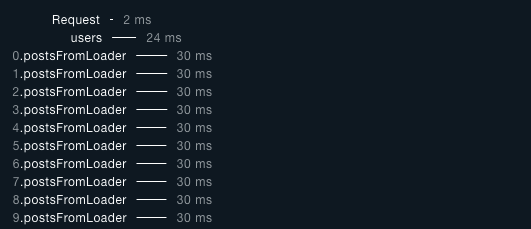
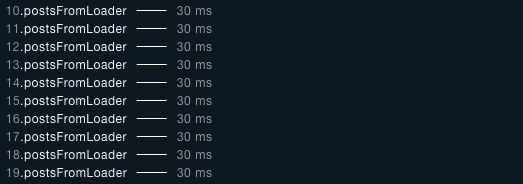
用了 dataloader 的結果

dataloader 也有 cache 的功能
同樣的 key 如果有結果了就不用再拿
不同 request 如果共用 dataloader 的話就可以共用 cache