metody komputerowej analizy stylometrycznej tekstów w jEzyku polskim
spis treSci
1. Przypomnienie problematyki
2. Schemat systemu
3. Metryki liczbowe
4. Częstość słów
5. Analiza części mowy
6. Predykcja wyniku
7. Klasyfikacja metodą Naive Bayes
8. Plany
Przypomnienie problematyki
Grupowanie tekstów w klasy na podstawie określonych form stylistycznych tekstu
Mierzenie tekstu określonymi metrykami
Kwalifikacja próbki tekstu do określonej klasy na podstawie zbioru uczącego
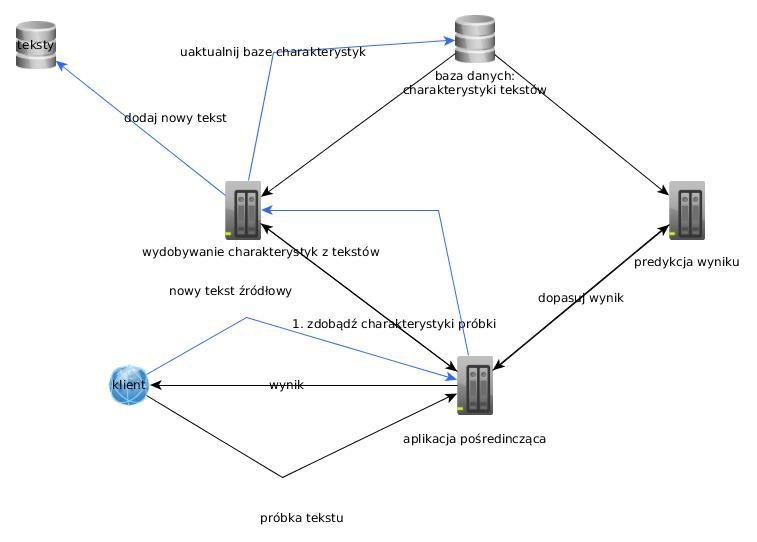
Schemat projektu
Metryki liczbowe
- średnia długość słowa
- średnia długość zdania
- współczynnik częstości znaków specjalnych
- współczynnik najrzadziej używanych słów
Metryki liczbowe
"average_word_length" : 5.8539325842696632,
"name" : "sienkiewicz",
"type_token_ratio" : 0.8202247191011236,
"average_sentence_length" : 22.2500000000000000,
"hapax_legomana_ratio" : 0.7415730337078652
narzedzia do analizy
fleksyjnej i morfosyntaktycznej
WCRFT
- CRF++
- Corpus2 library
- MACA package (for morphological analysis of plain text)
- Morfeusz SGJP (if you want to use v. 1.0 of Morfeusz, please install it before installing MACA so that Morfeusz plugin is also built)
- WCCL
narzedzia do analizy
fleksyjnej i morfosyntaktycznej
def produce_xml_with_morphological_data(text_file_path, output_file_path):
os.system("~/apps/wcrft/wcrft/wcrft.py
-d ~/apps/model_nkjp10_wcrft/ ~/apps/wcrft/config/nkjp.ini -i txt " +
text_file_path + " -O " + output_file_path)<chunkList>
<chunk type="s">
<tok>
<orth>Czas</orth>
<lex disamb="1"><base>czas</base><ctag>subst:sg:nom:m3</ctag></lex>
</tok>
<tok>
<orth>był</orth>
<lex disamb="1"><base>być</base><ctag>praet:sg:m3:imperf</ctag></lex>
</tok>
<tok>
<orth>wiosenny</orth>
<lex disamb="1"><base>wiosenny</base><ctag>adj:sg:nom:m3:pos</ctag></lex>
</tok>
<tok>
<orth>o</orth>
<lex disamb="1"><base>o</base><ctag>prep:loc</ctag></lex>
</tok>
<tok>
<orth>świtaniu</orth>
<lex disamb="1"><base>świtanie</base><ctag>subst:sg:loc:n</ctag></lex>
</tok>
<ns/>plik wynikowy wcrft
"base_words" : [
{
"i" : 7
},
{
"w" : 4
},
{
"na" : 3
},
{
"się" : 3
},
{
"rok" : 2
},
{
"co" : 2
},
{
"być" : 2
}
....najczestsze slowa
"parts_of_speech_frequencies" : {
"adv" : 0.0194174757281553,
"praet" : 0.0776699029126214,
"imps" : 0.0291262135922330,
"pred" : 0.0097087378640777,
"interp" : 0.1067961165048544,
"subst" : 0.3398058252427185,
"qub" : 0.0388349514563107,
"comp" : 0.0291262135922330,
"conj" : 0.0873786407766990,
"adj" : 0.1359223300970874,
"prep" : 0.0970873786407767,
"fin" : 0.0291262135922330
},czesci mowy
predykcja wyniku
Jakie wagi nadać parametrom tekstu?
- cechy numeryczne
- częstości słów
- częstości używania konkretnych części mowy
klasyfikacja metoda Naive bayes
from sklearn import naive_bayes
trainingSet = [reymontCharacteristics, sienkiewiczCharacteristics]
gaussian_naive_bayes = naive_bayes.GaussianNB()
gaussian_naive_bayes.fit(trainingSet, ['reymont', 'sienkiewicz'])
print gaussian_naive_bayes.predict(inputCharacteristics)bibliografia
Scikit- http://scikit-learn.org/stable/supervised_learning.html#supervised-learning
WCRFT- http://nlp.pwr.wroc.pl/redmine/projects/wcrft/wiki
partial-fit- http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html#sklearn.naive_bayes.MultinomialNB.partial_fit