Video Frame Synthesis using Deep Voxel Flow
Ziwei Liu, Xiaoou Tang, Raymond Yeh, Yiming Liu, Aseem Agarwala
The Chinese University of Hong Kong, University of Illinois at Urbana-Champaign, Google Inc.
2017, Feb 8
Goal
Frame Interpolation/Extrapolation
Application
- Slow-motion effect
- Increase frame rate



Optical Flow




compute flow
on each pixel
Related Work
CNN Approach
- Predict optical flow
Traditional Approach
- Estimate optical flow between frames
- Interpolate optical flow vector
⇒ Optical flow must be accurate
⇒ Require supervision (flow ground-truth)
- Directly hallucinate RGB pixel values
⇒ Blurry
Outline
Overview
Formulation
Refinement and Extension
Experiment
Summary
Overview
Deep Voxel Flow
Combine the strengths of traditional and CNN approaches
- CNN ⇒ voxel flow
- Volume sampling layer(blending) ⇒ synthesized frame
- Synthesized frame ⇔ ground-truth frame
*voxel=volume pixel=3D pixel
End-to-end trained deep network
No FC layer ⇒ any resolution
Quantitatively and qualitatively improve upon the state-of-the-art
Formulation
Architecture
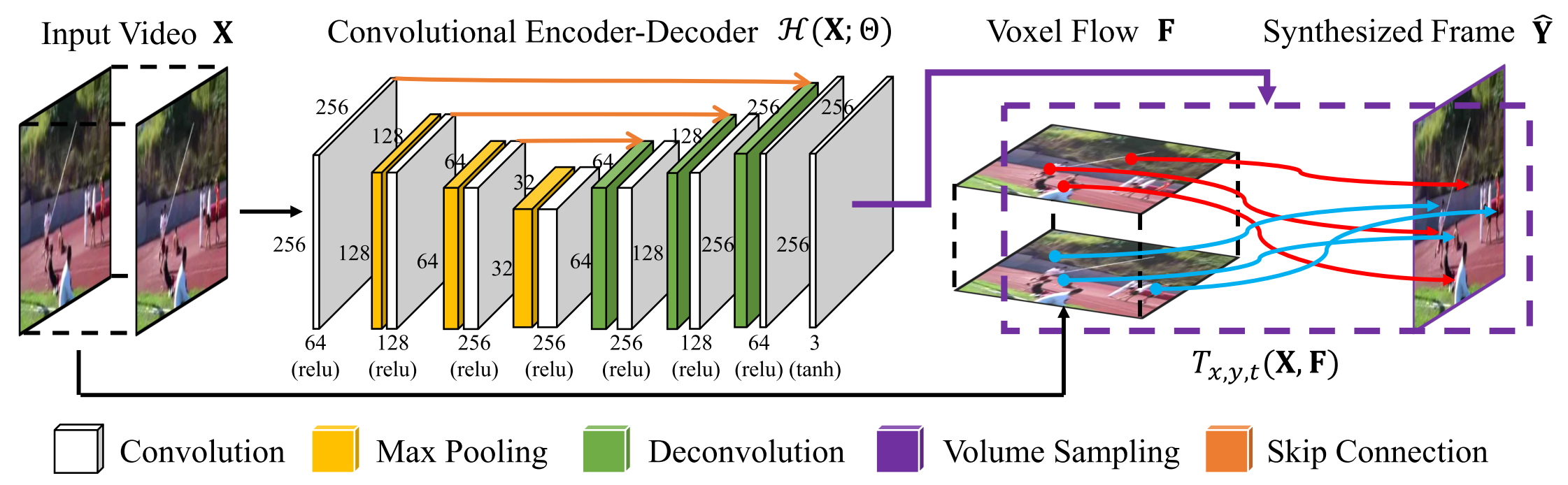
Input frames
Target frame
Synthesized frame
Formulation
CNN ⇒ Voxel Flow
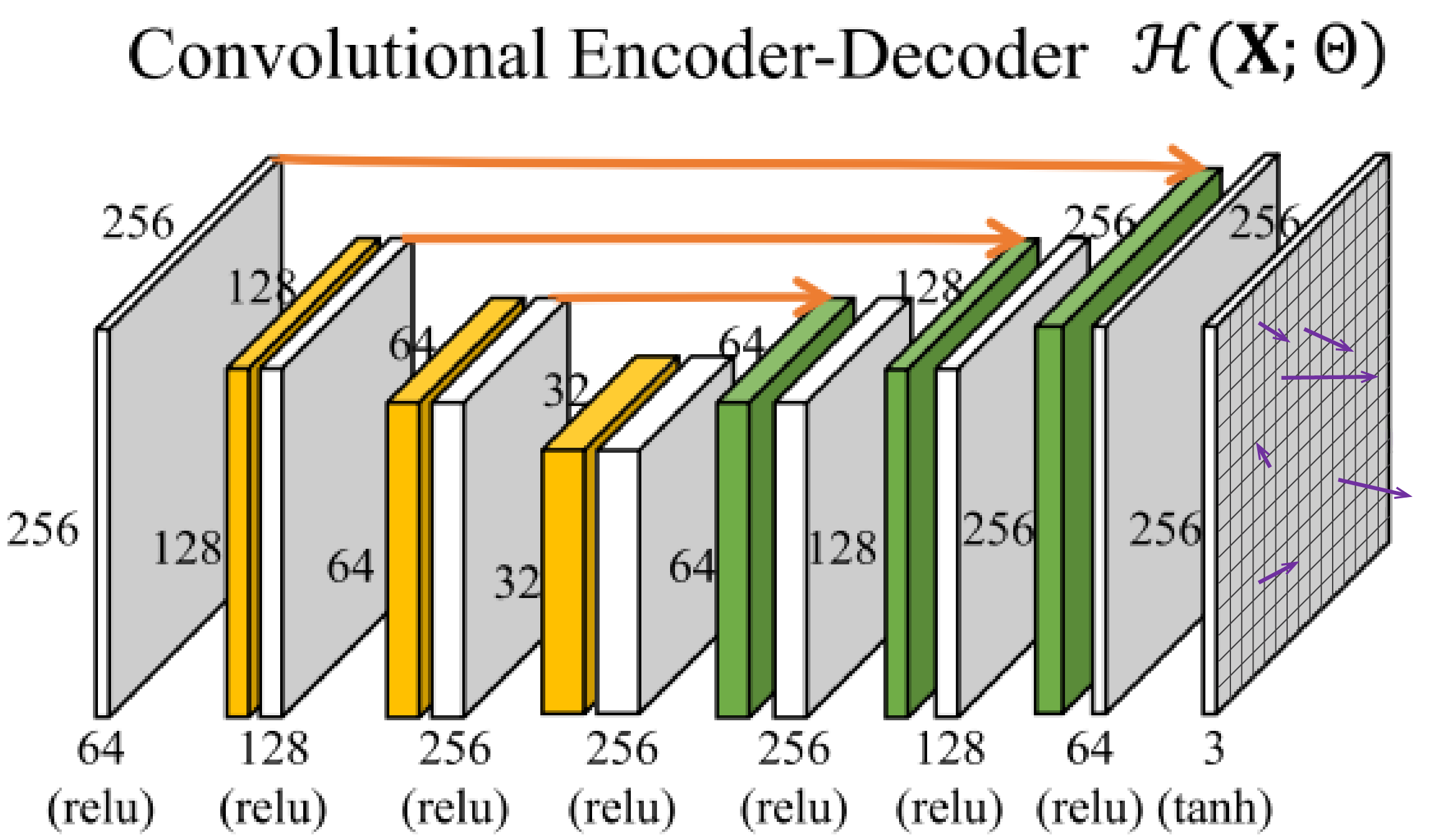
Predict the voxel flow on every pixel of
network parameters
Voxel Flow
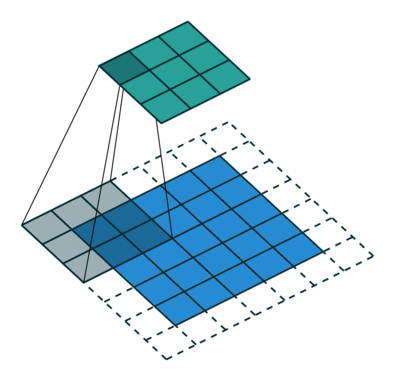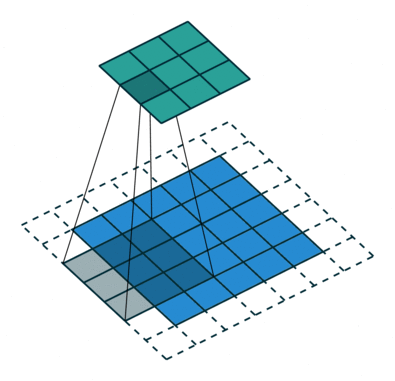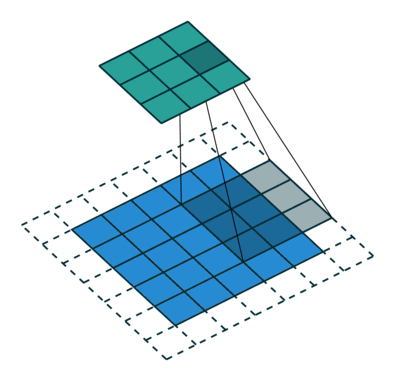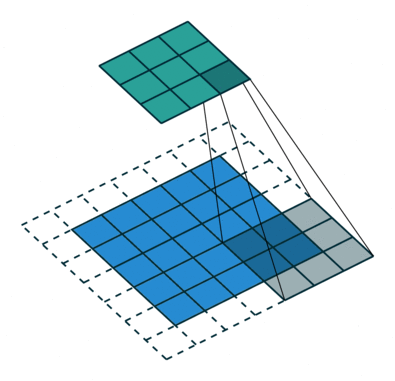
*Deconvolution
kernel sizes:
5x5, 5x5, 3x3, 3x3, 3x3, 5x5, 5x5
it should be:
Formulation
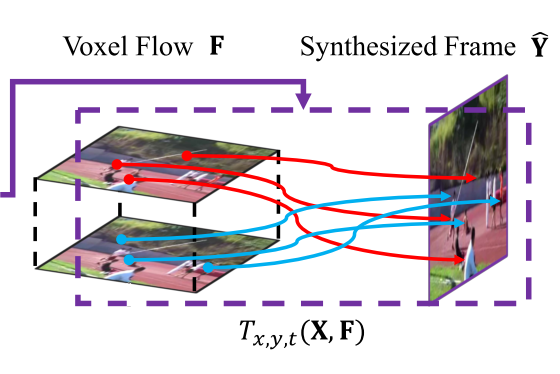
Volume Sampling Layer ⇒ Synthesized Frame
Assume optical flow is temporally symmetric around the in-between frame
Corresponding locations in:
- Previous frame
- Next frame
*(x,y):pixel location in the synthesized frame
Linear blending weight between the previous and next frames
Formulation
Volume Sampling Layer ⇒ Synthesized Frame

Formulation
Volume Sampling Layer ⇒ Synthesized Frame
Trilinear interpolation
Volume Sampling Function
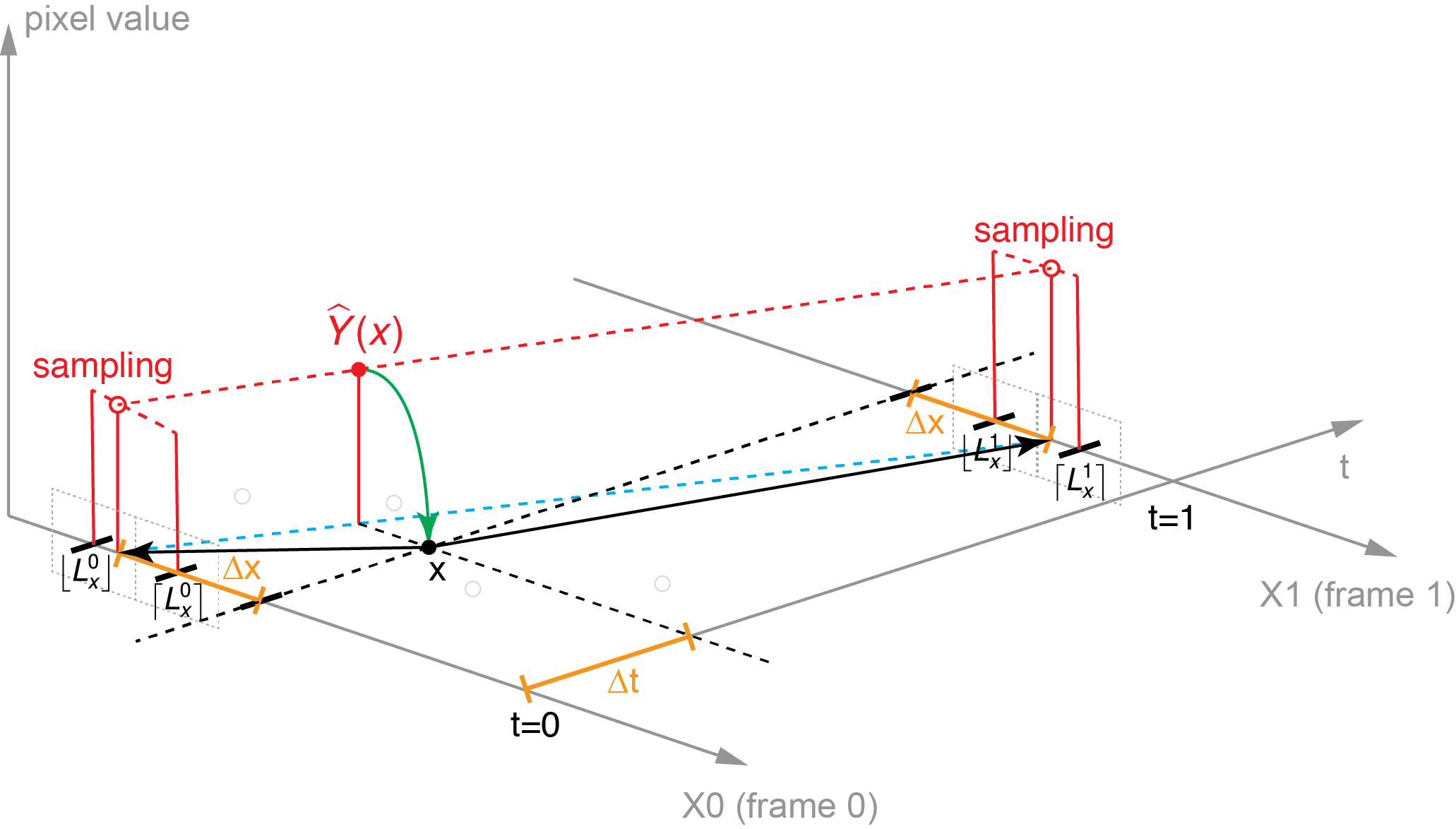
Formulation Visualization
Synthesize frame in 1D
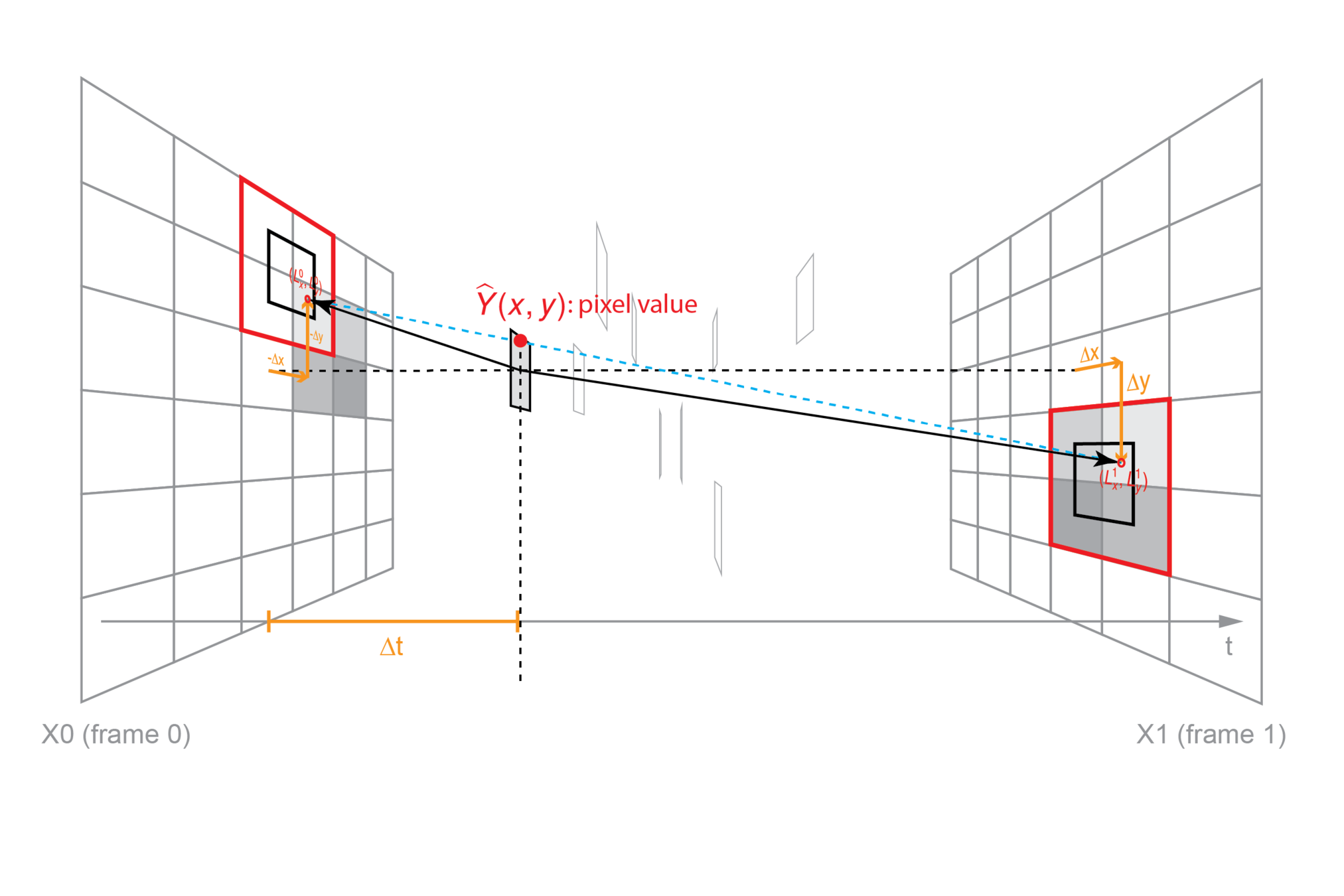
Formulation Visualization
Synthesize frame in 2D
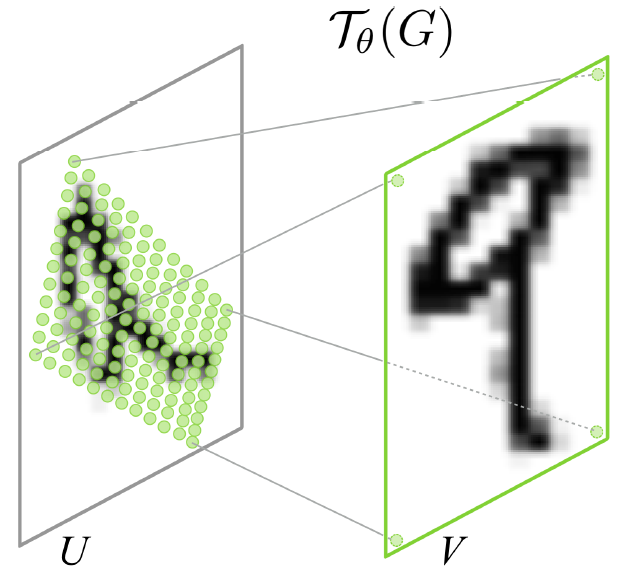
Digression
Spatial Transformer Networks
DeepMind, 2015 NIPS, Cited by 222
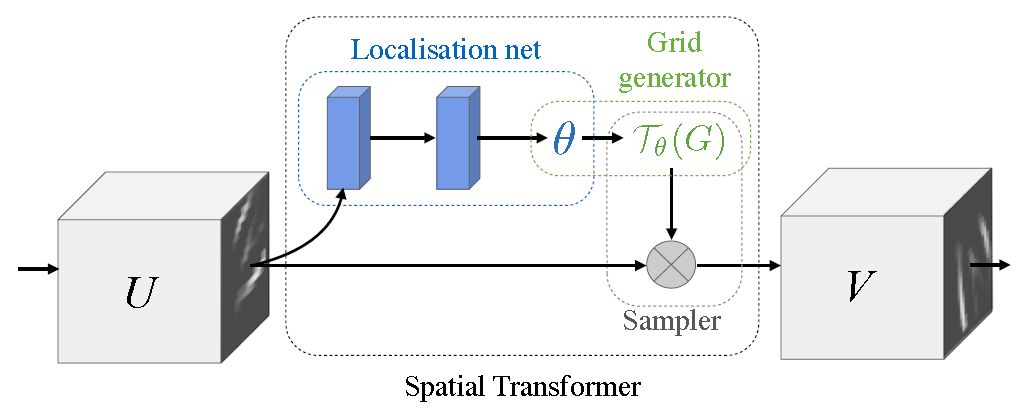

Formulation
Synthesized Frame ⇔ Ground-Truth Frame
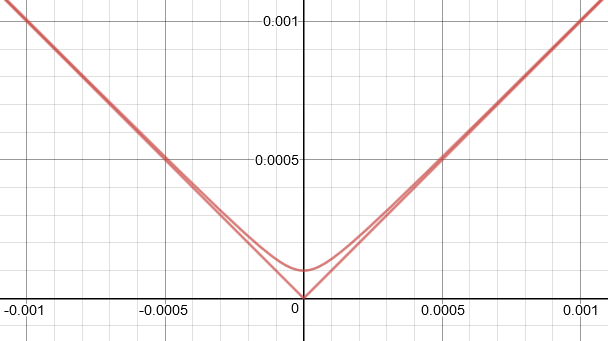
Loss Function
total variation:
L1 approximated by Charbonnier loss
Empirically
Learning settings
- Batch size: 32
- Batch normalization
- Gaussian init:
- ADAM solver:
Formulation
End-to-end Fully Differentiable System
Note
Formulation Visualization
Another Formulation
Refinement
Multi-scale Flow Fusion
Hard to find large motions that fall outside the kernel
Deal with large and small motions
- Mutiple encoder-decorders
deal with different scales , coarse ⇒ fine
e.g. - Predict voxel flow at that resolution
- Upsample and concatenate, only is retained
- Further convolute ( ) on the fused flow fields ⇒
Refinement
Multi-scale Flow Fusion
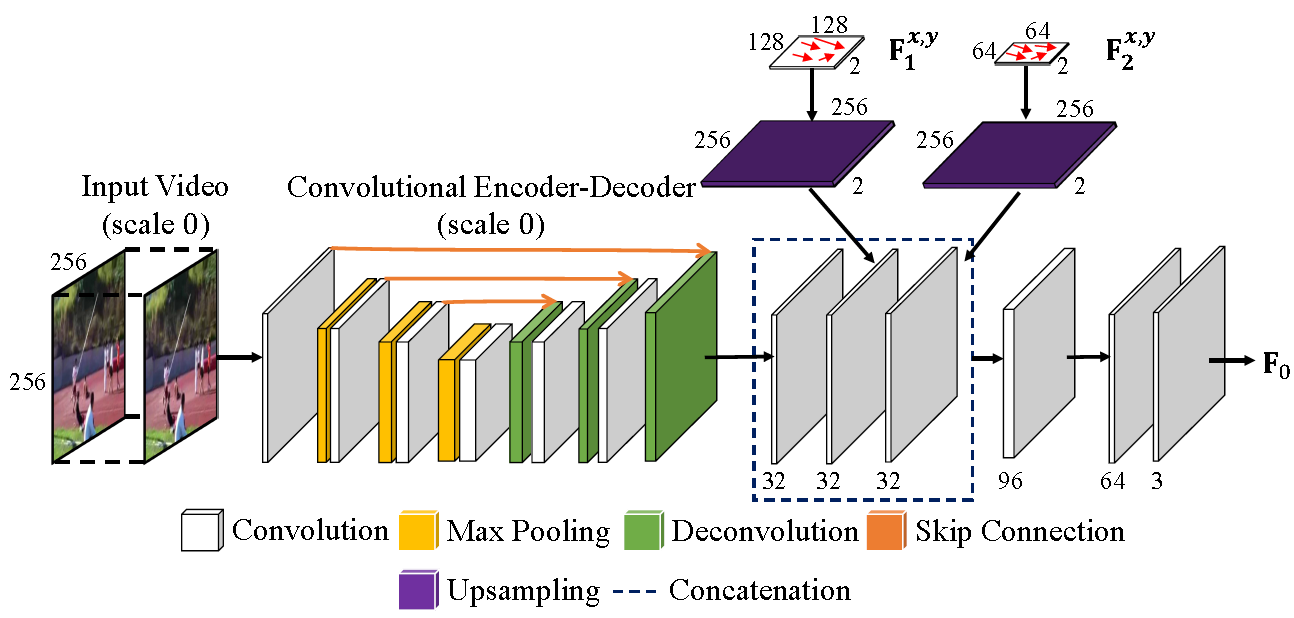
Refinement
Multi-scale Flow Fusion
Extension
Multi-step Prediction
Predict D frames given current L frames
Smaller learning rate: 0.00005

Experiment
Compete with the State-of-the-art
Training set: UCF-101 Train, 240k triplets
Test set: UCF-101 Test, THUMOS-15
Competing methods (state-of-the-art)
- EpicFlow + algorithm from Middlebury interpolation benchmark
- BeyondMSE(with little tweaks)

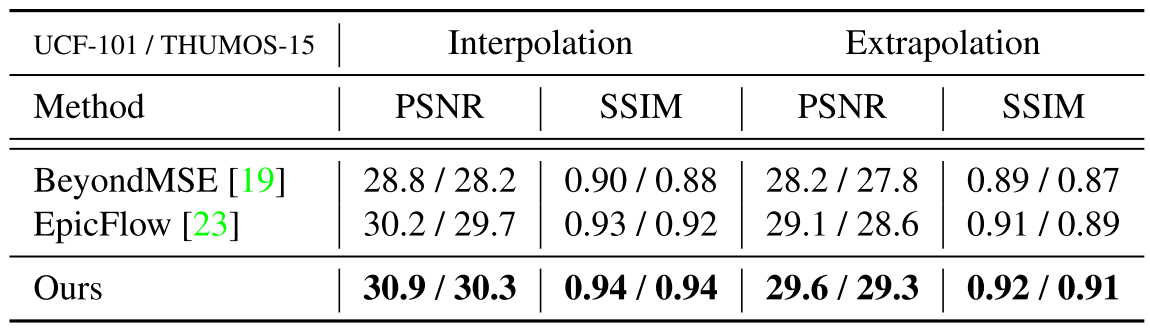
Experiment
Compete with the State-of-the-art
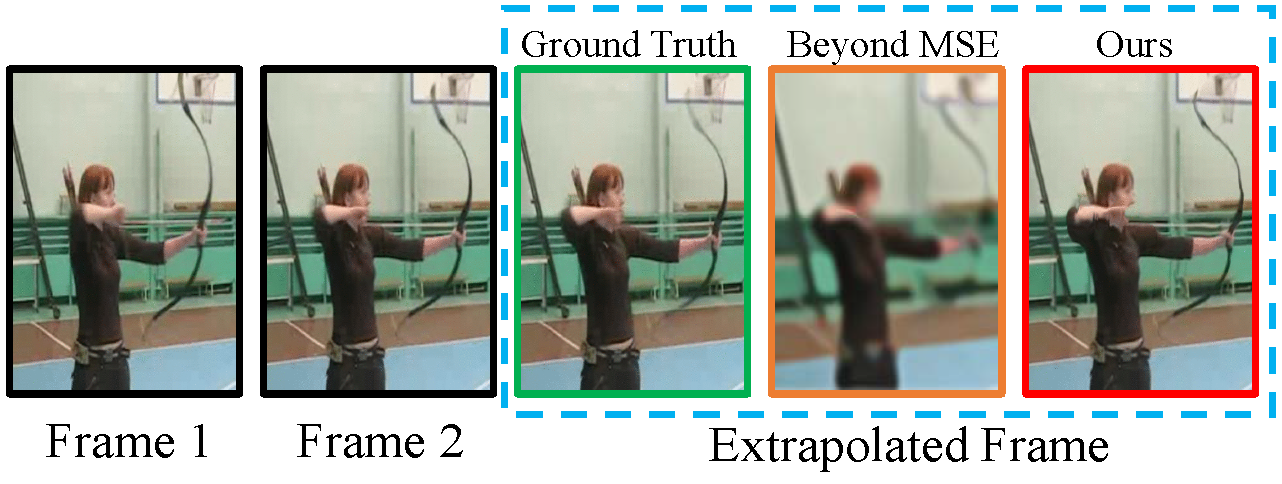
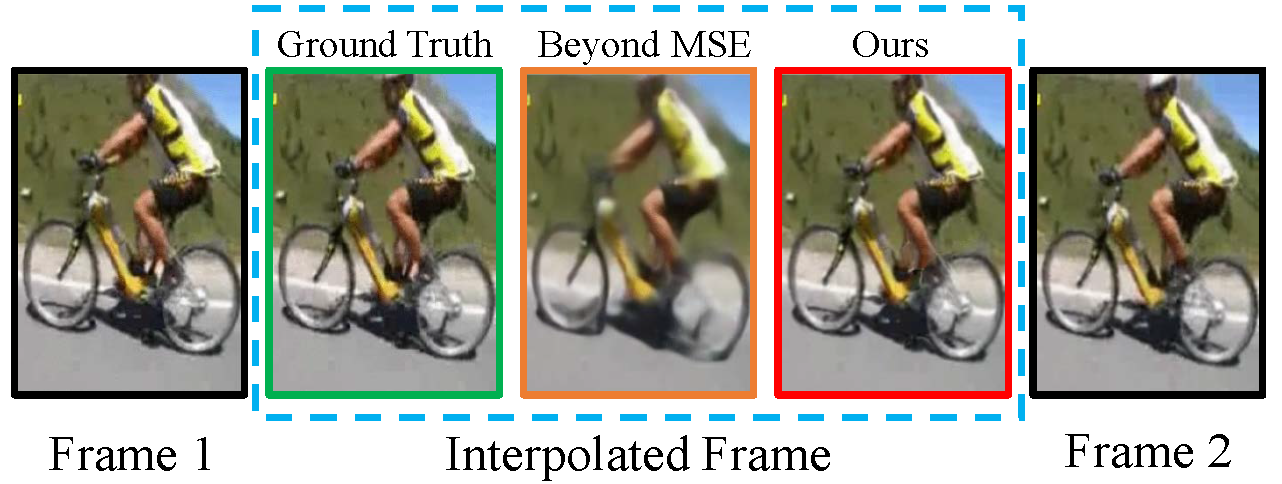
Experiment
Compete with the State-of-the-art

Interpolation
Extrapolation
Multi-step comparisons
Experiment
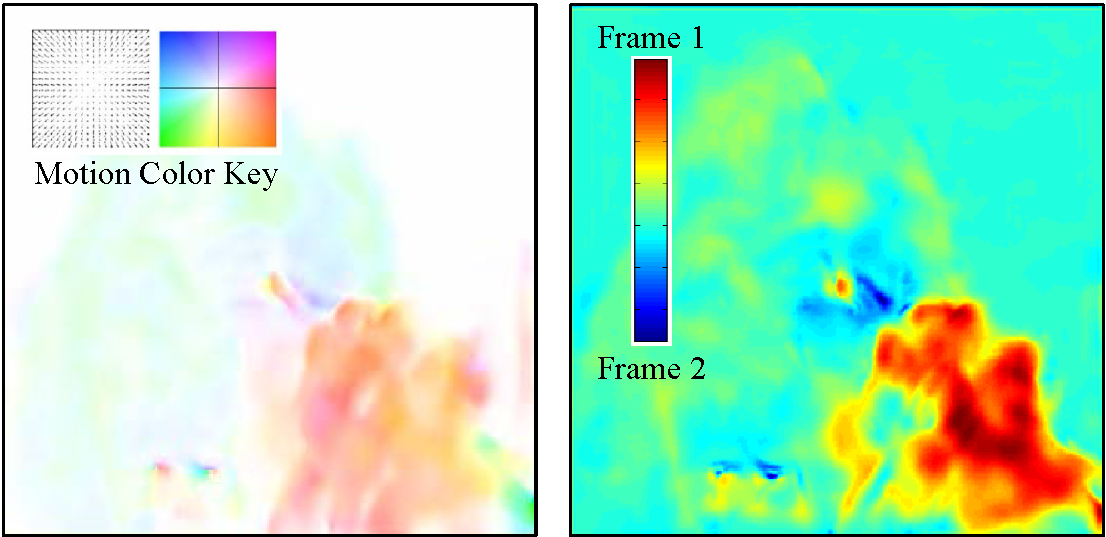
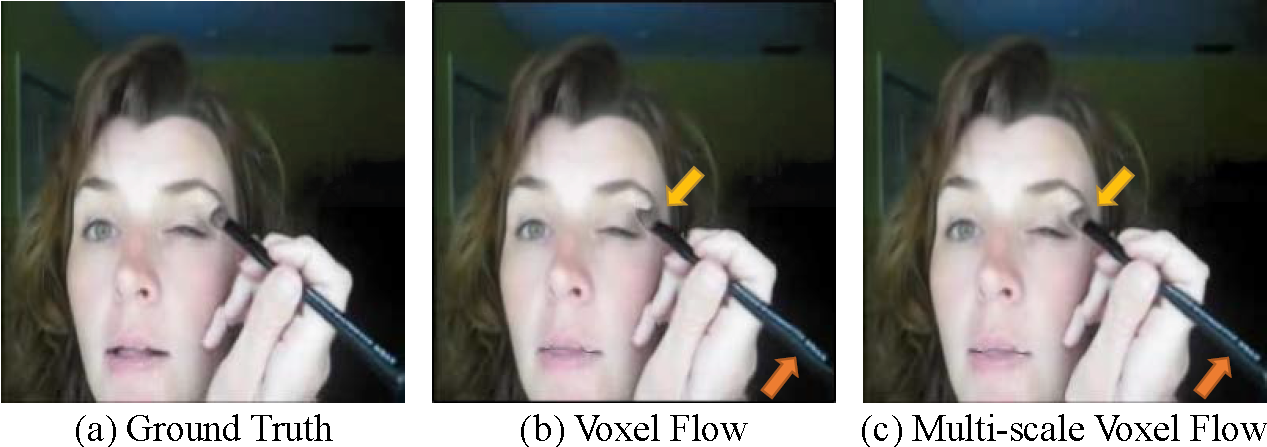
Effectiveness of Multi-scale Voxel Flow
Appearance
Motion
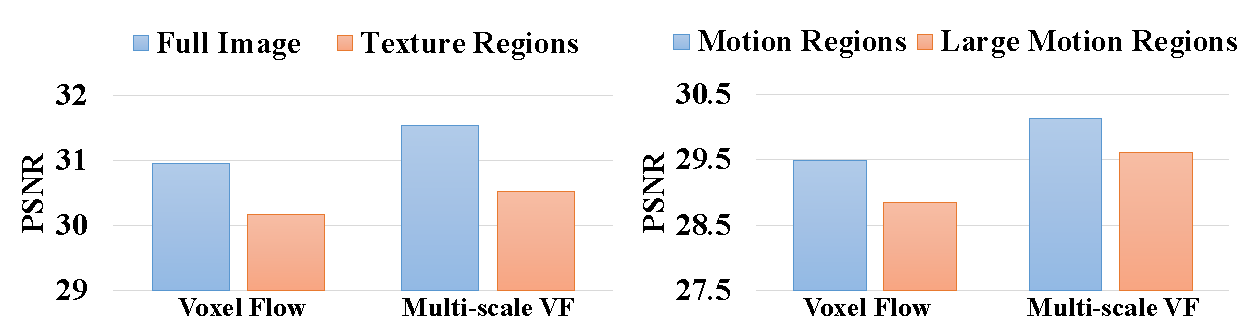
UCF-101 test set
Experiment
Generalization to View Synthesis
Evaluate KTTI odometry dataset

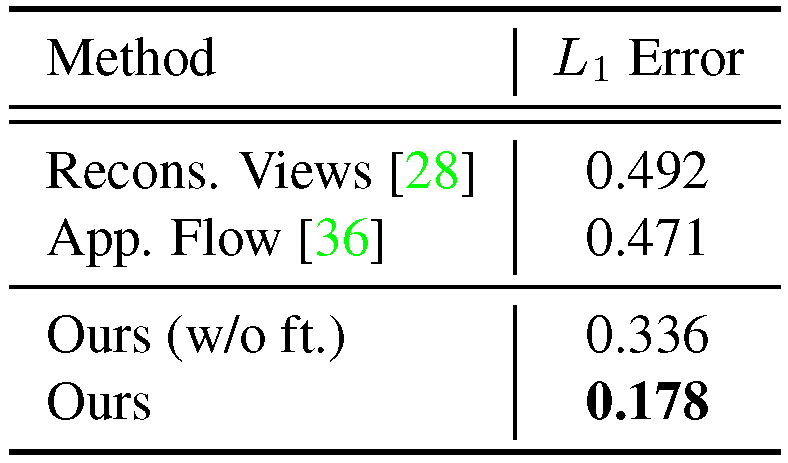
Experiment
Generalization to View Synthesis

Experiment
Frame Synthesis as Self-Supervision
Video frame synthesis can serve as a self-supervision task for representation learning( )

Flow estimation
(endpoint error)
Action recognition
Experiment
Application
Produce slow-motion effects on HD videos(1080x720, 30fps)
- Visual Comparison
- User Study
EpicFlow serve as a strong baseline
Experiment
Application-Visual Comparison

EpicFlow
Ground Truth
DVF

Experiment
Application-Visual Comparison
EpicFlow
Ground Truth
DVF


Experiment
Application-User Study
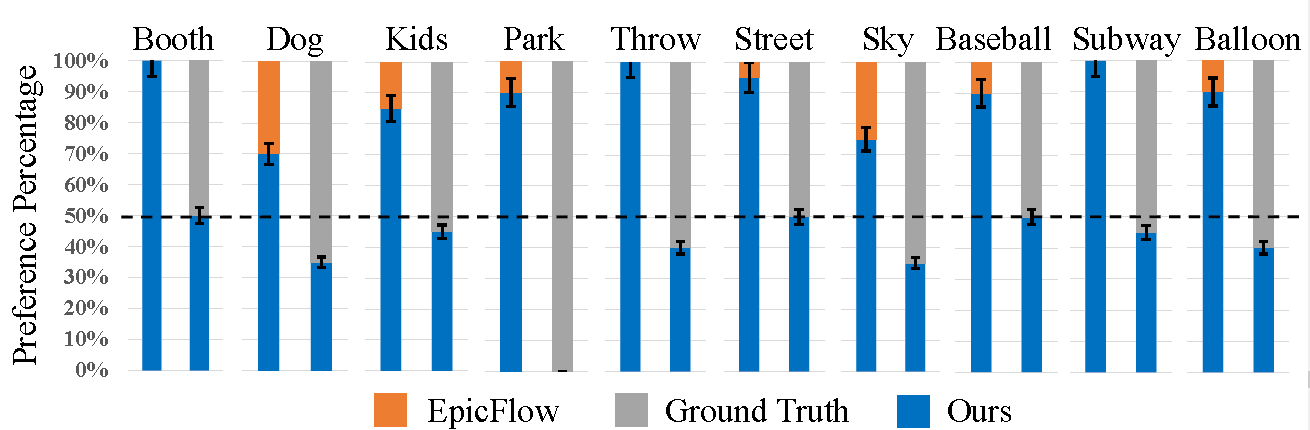

20 subjects were enrolled
For the null hypothesis:
- "EpicFlow is better than our method"
p-value < 0.00001 - "DVF is better than ground truth"
p-value < 0.838193
Experiment
Demo Video
Summary
- End-to-end deep network
- Copy pixels from existing video frames, rather than hallucinate them from scratch
- Improves upon both optical flow and recent CNN techniques
Future Work
- Combine flow layers with pure synthesis layers
⇒ predict pixels that cannot be copied from other video frames - Use the desired temporal step as an input
- Compress the network, and run on mobile devices