Contrastive Self-Supervised Learning for Skeleton Action Recognition
- In this paper they propose a new contrastive self-supervised learning method for action recognition of unlabelled data.
- The main objective is to get effective feature representations of skeleton sequences under a simple contrast learning framework.
- Inspired from many recent studies like "Learning Representations by Maximizing Mutual Information Across Views"
Main Objectives:
INTRODUCTION:
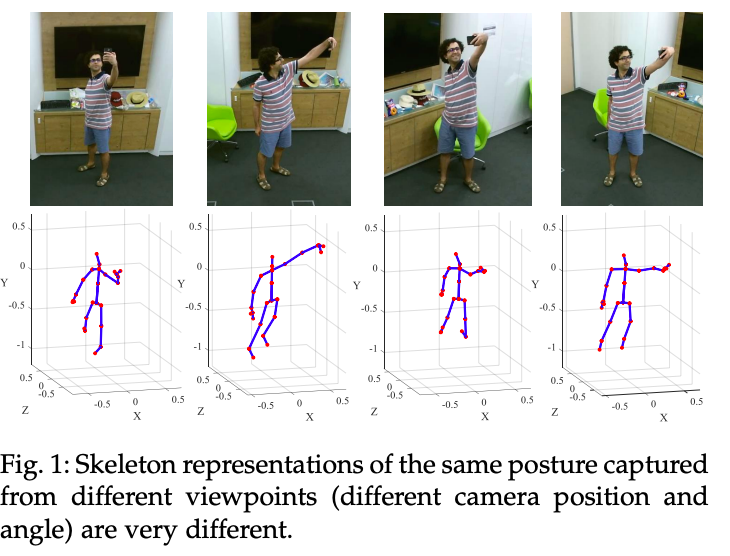
- Compared with RGB images, body joint time-series (skeletons) are effective descriptors of actions, which are robust against the background and lighting changes.
- Although recent methods have achieved remarkable progress with the development of deep neural networks, most methods rely on strong supervision on action labels.
- The key challenges in action recognition lies in the large variety of action representation when motions are captured from different viewpoints.
Related Work:
- Unsupervised Learning in Skeleton Action Recognition:
- Recurrent-based sequence (Seq2Seq) model
- GAN encoder-decoder(LongTGAN)
- Variant of Viewpoints and Distance in Skeleton Action Recognition:
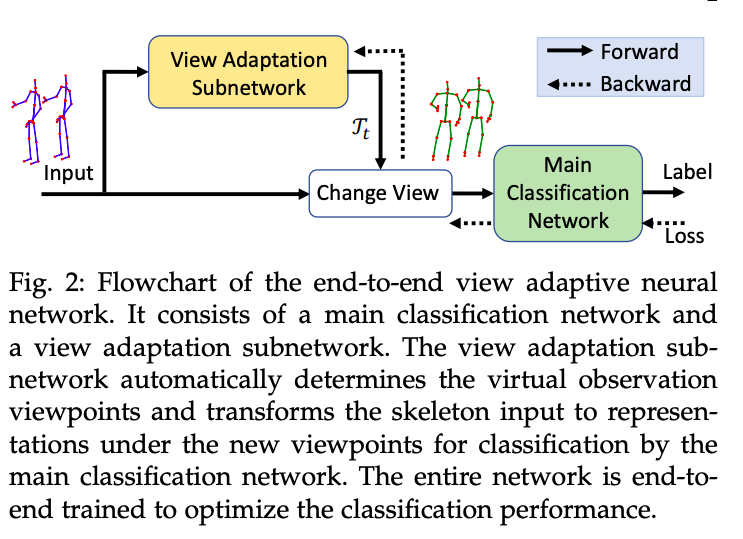
- View Adaptive Neural Networks for High Performance Skeleton-based Human Action Recognition
Methodology:
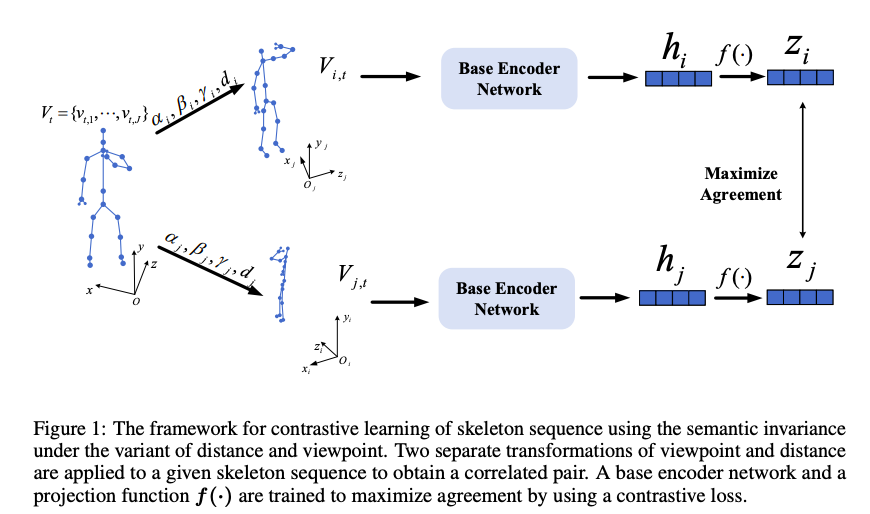

Given a skeleton sequence S with T frames, under the global coordinate system, we denote the set of joints in the t-th frame as
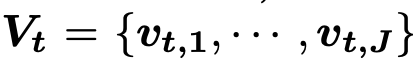

Contrastive Learning Framework:
Experimental Protocol:
| NTU-RGBD | NTU-RGBD-120 |
|---|---|
| 56,880 action samples in 60 action classes performed by 40 distinct subjects | 114,480 action samples in 120 action classes performed by 106 distinct subjects |
| Kinect V2 | Kinect V2 |
| 3 cameras from different horizontal angles: −45 , 0 , 45 | 32 setups, and every different setup has a specific location and background |
| Two protocols 1) Cross-Subject (Xsub): Training data comes from 20 subjects, and the remaining 20 subjects are used for validation. 2) Cross-View (X-view): Training data comes from the camera 0 and 45 , and validation data comes from camera −45 |
Two protocols 1) Cross-Subject (X-sub): Training data comes from 53 subjects, and the remaining 53 subjects are used for validation. 2) Cross-Setup (X-setup): picking all the samples with even setup IDs for training, and the remaining samples with odd setup IDs for validation |
1) Datasets:
2) Model Setting:
- Larger batch sizes.
- Layer-wise Adaptive Rate Scaling (LARS) as Optimizer.

To understand the effects of individual transformation of the skeleton and the importance of transformations composition, the experiment will be repeated multiple times