Web scale Data Curation and Use in Recognition Models of American, Australian, Chinese, Russian and Spanish Sign Languages
Github source: https://github.com/AI4Bharat/SLR-Data-Pipeline/tree/sumit
Guided By : Prof. Mitesh Khapra (IIT Madras),
Prof. Pratyush Kumar (IIT Madras)
Name : Manideep Ladi
Roll Number : CS20M036
Index
- Introduction
- Related Work
- Objective
- Contributions
- Pipeline and Pretrained Dataset Statistics
- Isolated Dataset Details
- Finger spelling Dataset Details
- Experiment Results
- Conclusion & Future Work
- References
Introduction
Sign Language:
-
Sign Language is a visual language, to convey meaning, it uses hand gestures, facial expressions, and finger movements such as eye gazing, mouth movement, eyebrows, body movements and head orientation.

-
It has its own syntax and vocabulary, as well as articulation pace and lexicon, which set it apart from regional spoken languages. Furthermore, despite some similarities, no global sign language exists, and it varies by location, much like natural language.
Sign Langauge Recognition:
-
Sign Language recognition (SLR) is a collaborative field that combines pattern matching, computer vision, and natural language processing to bridge the communication gap between sign language users and non-users.
-
It is a well-known research problem but not a well-studied problem.
-
SLR problem is divided into two types: a) Isolated SLR b) Continous SLR
-
In this work, we focus on the Isolated Sign Language Recognition problem.
Related Work:
Available Isolated Datasets:
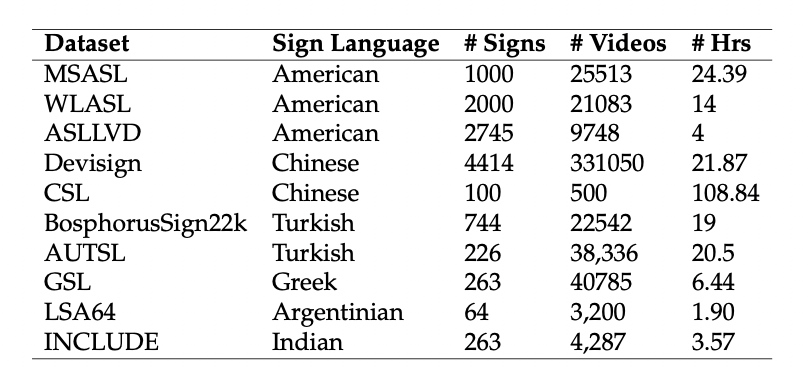
- These are a few available isolated datasets of various languages. Below are the details of the datasets.
Sign Language Recognition Models:
- Initial research is done using Machine Learning Models like SVMs, Random forest as it is a classification task.
- Deep Learning Based Models based on RGB as Modality like CNNs+LSTMs, 3D-Convnets.
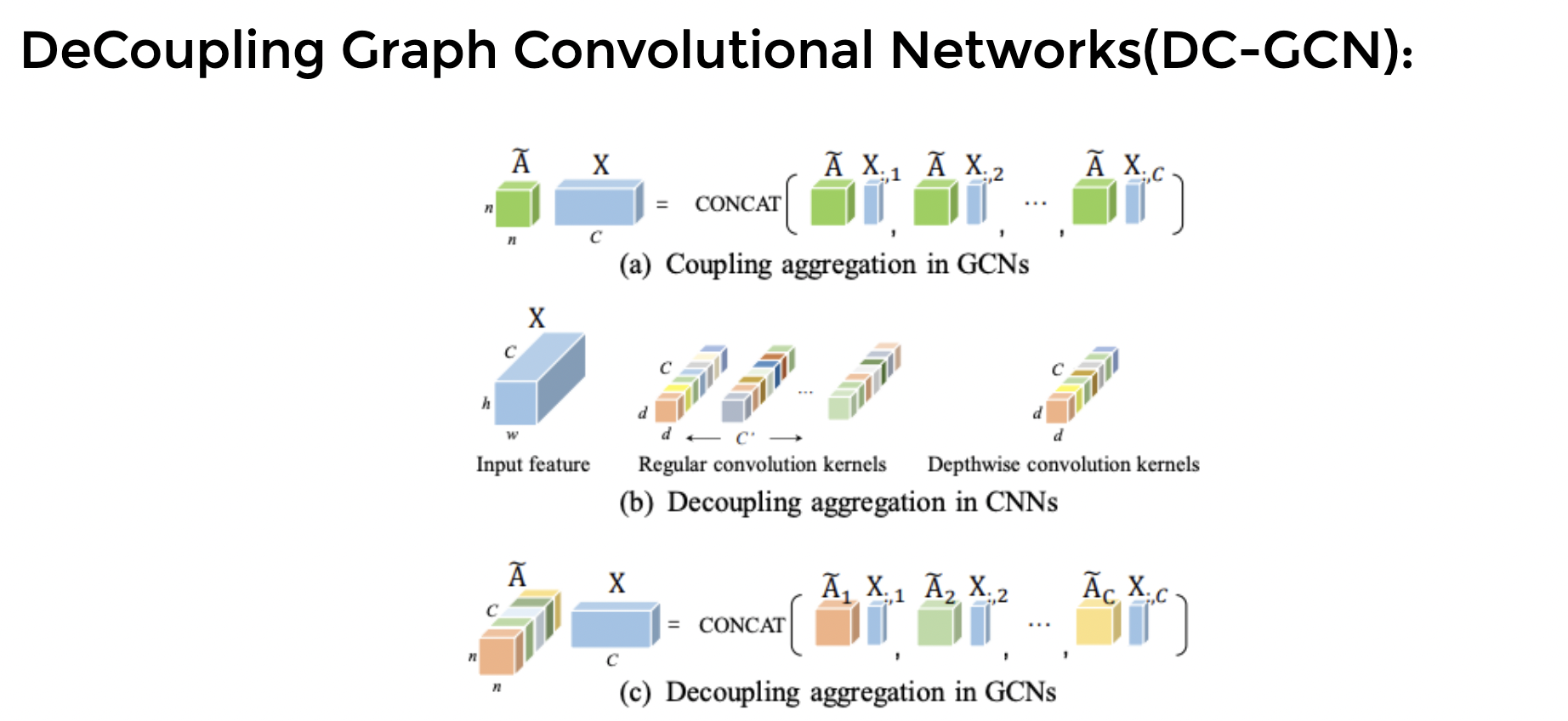
- Deep Learning Based Models based on Pose as Modality like TGCN, STGCNs, Decoupling ST-GCNs.
OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
-
This paper introduce OpenHands, a library where they take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition.
-
It is a open-source library, all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible.
-
Standardizing on pose as the modality.--->6 different sign languagues
-
Standardized comparison of models across languages.---> 4 different models
-
Corpus for self-supervised training.---> 1100 hrs of preprocessed Indian sign data
-
Effectiveness of self-supervised training.
4 Key Ideas of OpenHands:
Methods in NLP for low-resource Languages:
Data Augmentation, Pretraining, Multilinguality, and Transfer Learning are the few methods are used when we have scarcity of the data.
Pretraining:
- We have created a large multilingual pose based dataset also we have created a pipeline to curate the data.
- We used Dense Predictive Coding for pretraining whose primary goal is to understand the data representation by predicting upcoming timesteps (k) from data from old or previous timesteps (l).
Multilinguality:
- Multilingual model are those models which are trained using data from all the available languages which helps models to efficently adapt across the given languages.
Dense predictive Coding:
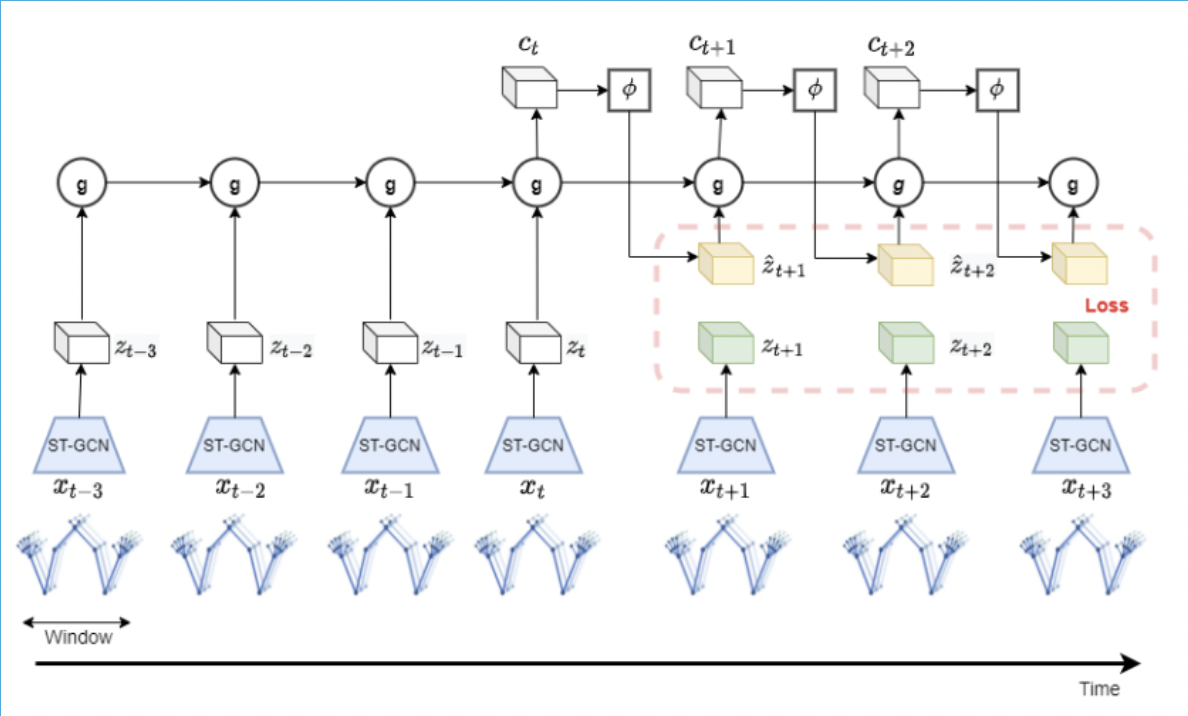
Architecture of DPC
Objective
SLR requires a large amount of labelled data because it is a classification problem; yet, labelling data is a time-consuming process that involves a lot of manual effort. We propose a large multilingual pose-based Sign Language Dataset for self-supervised learning and fine-tuning on labelled datasets (low resource languages).
Contributions:
-
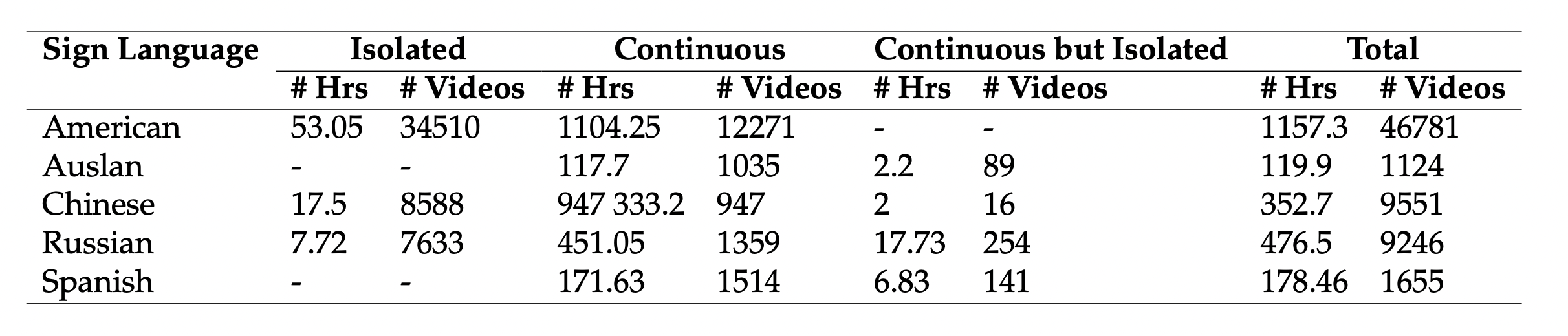
The 1800-hour pose dataset for pretraining encompasses five sign languages (American, Australian, Chinese, Russian and Spanish) and was gathered entirely from YouTube and then preprocessed.
-
To accomplish this, we developed the SLR pipeline, which consists of five stages: data crawling, metadata extraction and cropping, pose extraction, data storage, and training.
-
Apart from collecting raw datasets for pretraining, two available datasets (MSASL and ASLLVD) were also collected, preprocessed using the SLR pipeline and trained using pose based models.
-
Created benchmark fingerspelling dataset using the pipeline and then trained using pose based models using the pipeline. Also during this experimentation, we will see how multilinguality helps in achieving good results.
-
Added support for these datasets in the OpenHands library which is open source.
SLR Data Preprocessing Pipeline Diagram
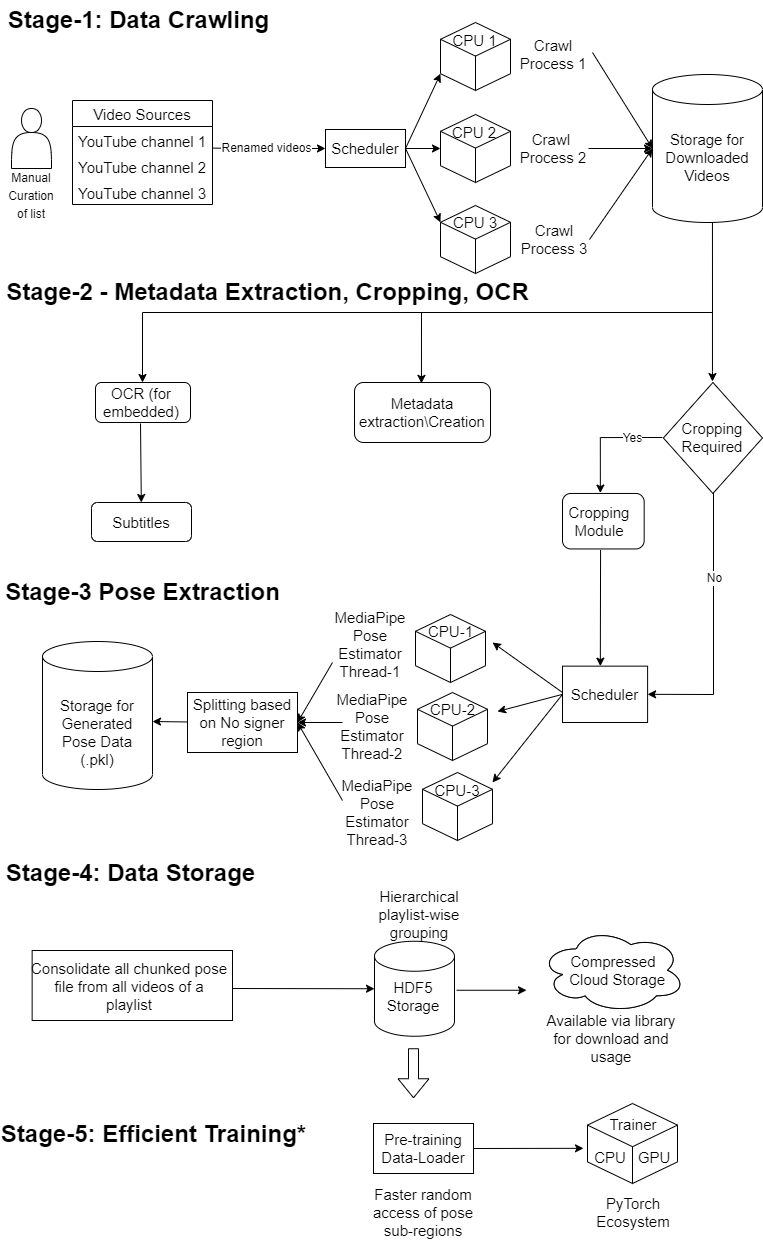
Identifying Data Sources
- Search in native language(with the help of google translator) and English both ways.
- Organized the sources into separate sheet for different sign languages.
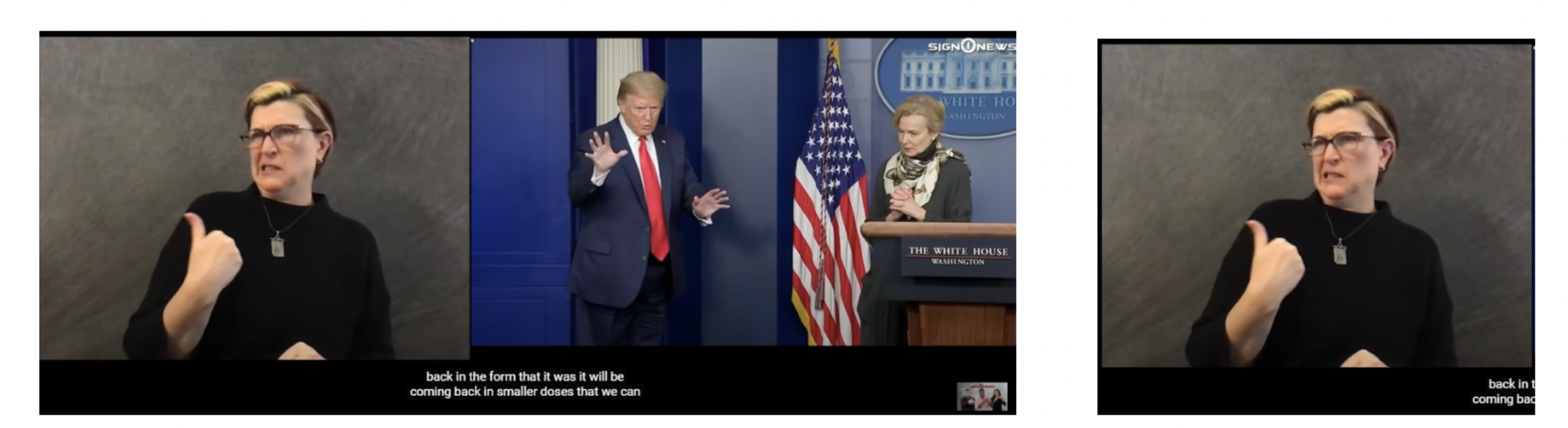
Cropping
Original image
After cropping
Pose Extraction
Original image
Final Pose keypoints
Image with keypoints

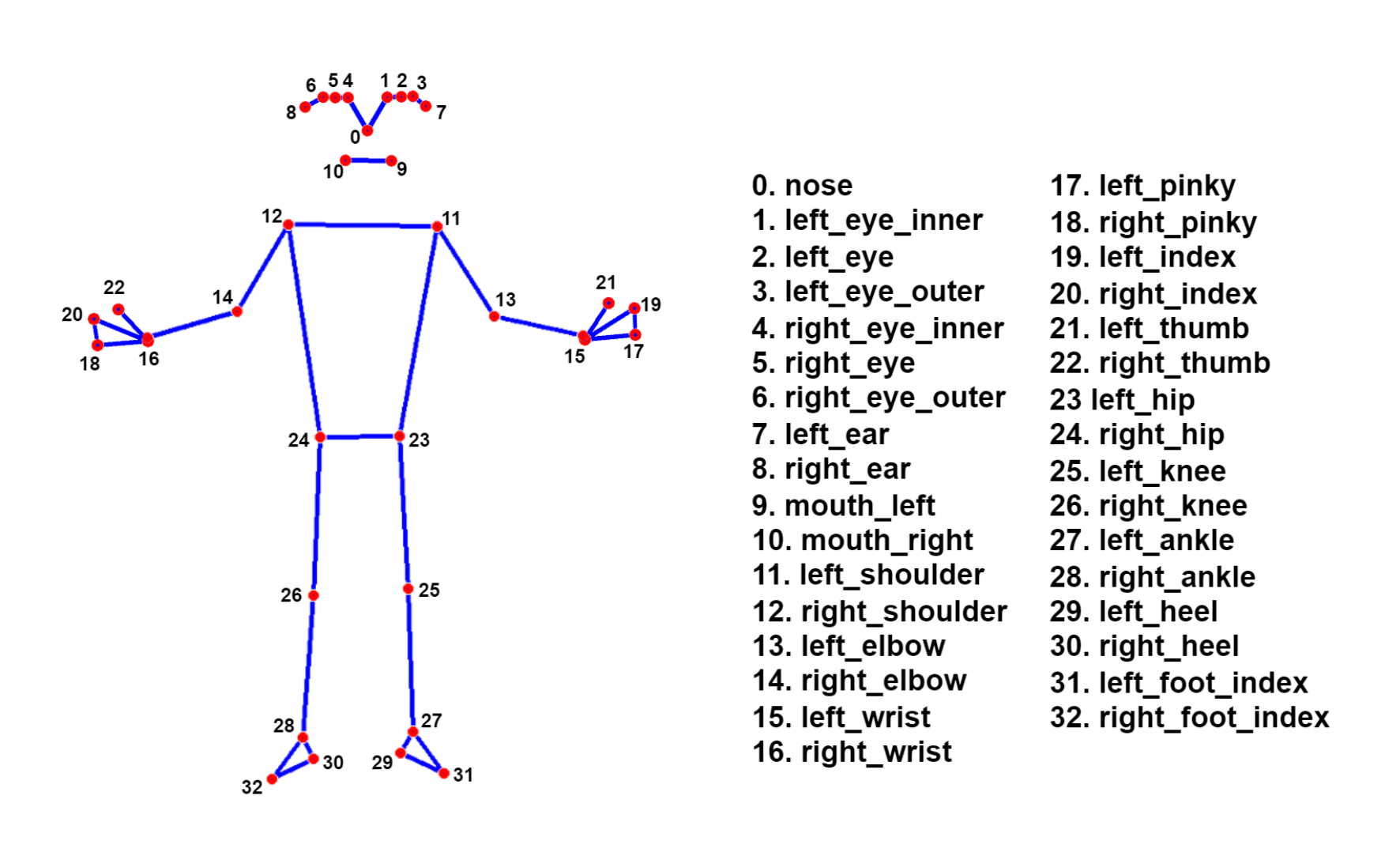
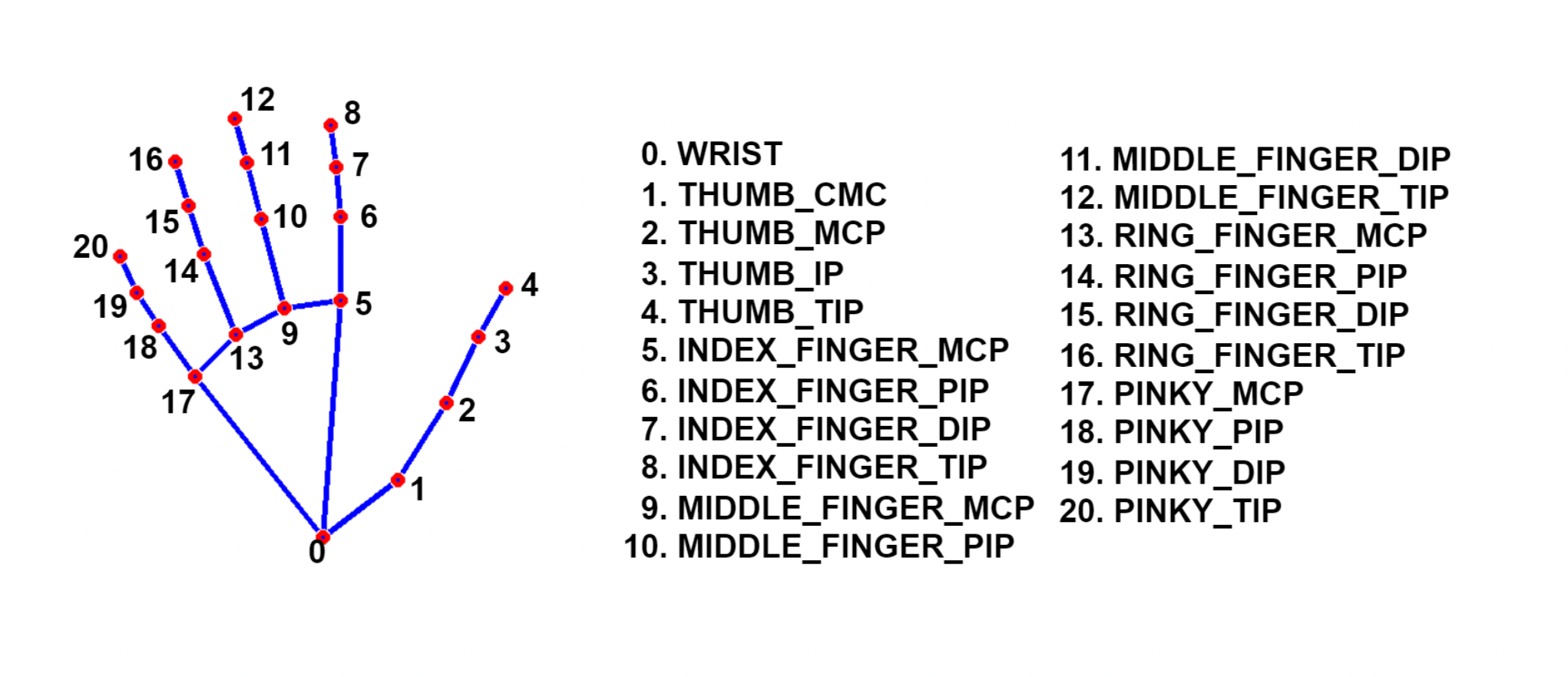
- We have used MediaPipe holistic library to extract poses.
- We are saving 33 body pose landmarks and 42 hand landmarks(21 each hand), so in total 75 keypoints per pose.
Dataset Quality Checks:
To test the quality of the data we collected we have implemented some sanity checks on the data and curated the data by having some thresholds for each language
A few questions are as follows:
- Is the person present in the video?
-
Is the person signing?
-
Is the person oriented properly?
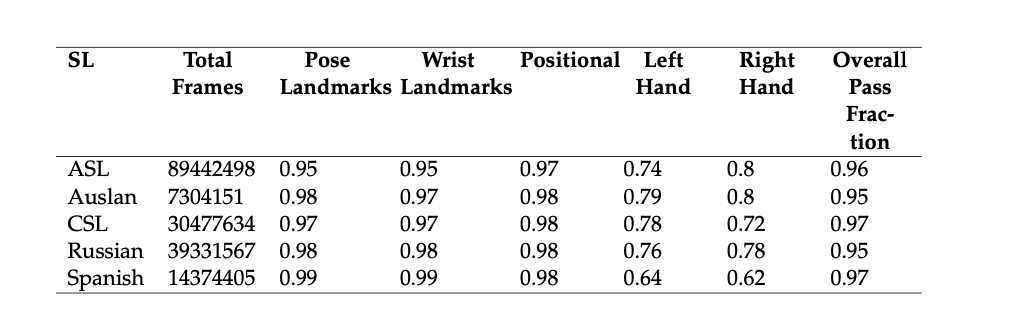
Fractions representing Data Quality Checks for each language
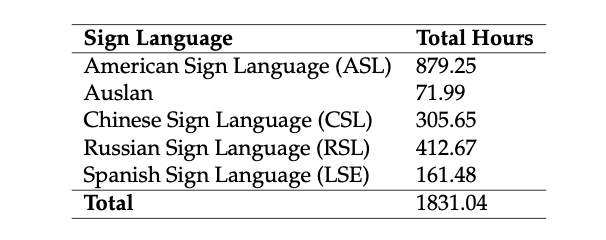
Final Pose data statistics:
- So in total, we have 1800 hrs of pose based multilingual dataset for self-supervised learning.
- We have used 96 CPUs from Microsoft Azure for collecting and preprocessing all the data.
Isolated Dataset Details:
-
MS-ASL and ASLLVD, two isolated datasets of American were collected and supported in the OpenHands repository.
-
MS-ASL has 1000 classes signed by 222 signers with 16054, 5287, and 4172 as train, validation and test split respectively.
-
ASLLVD dataset contains videos of 2745 ASL glosses, each created by a minimum of 1 and a maximum of 6 native ASL signers, totalling about 9,748 signs divided into a train-test split as 7798 and 1950 respectively.
Finger Spelling Dataset:
We have collected finger spelling videos from Youtube and preprocessed them to create a benchmark dataset for fingerspelling.

Experiment Results:
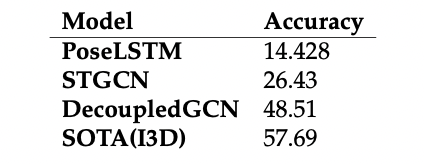

MS-ASL1000
ASLLVD
For the two isolated datasets, we collected and preprocessed we have created benchmark accuracies using the models available in OpenHands
Isolated Dataset Experiment results:
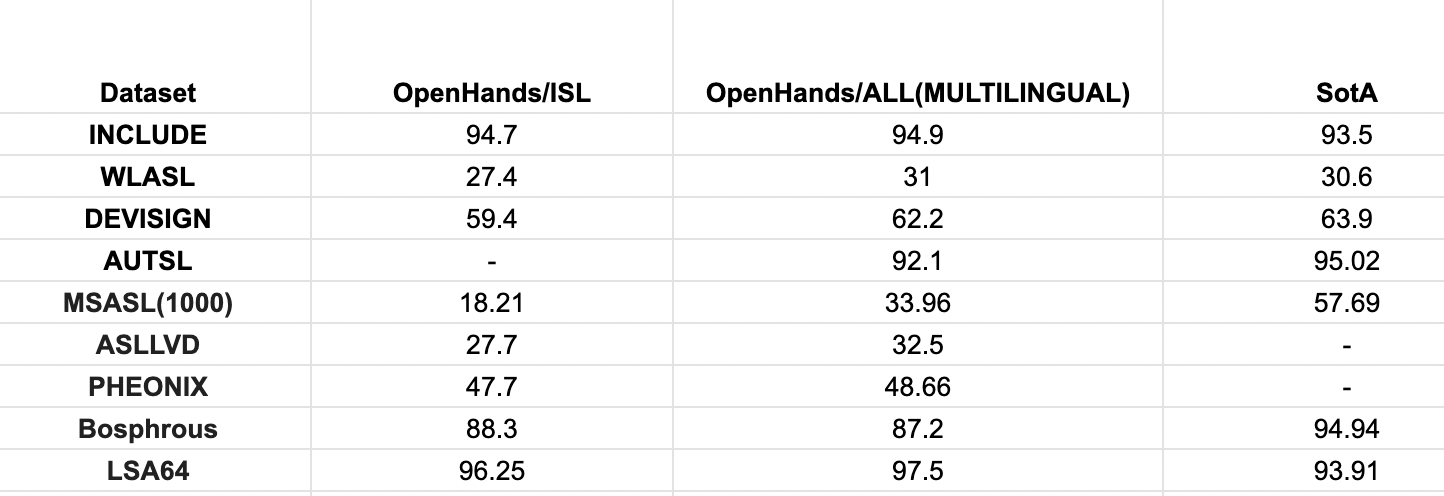
Improvements using pretrained dataset:
- Pretrained using DPC and finetuned on the datasets available.

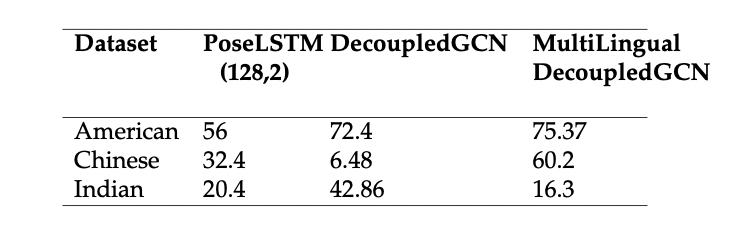
Finger Spelling Experiment Results:
Future Work
- Exploring various pretraining or self-supervised learning models with the largest pose based dataset which we defined in this work and then fine-tune them on many available isolated datasets.
- Finetuning not only on single language dataset we need to create multilingual isolated SLR models (using the pre-trained models from the above trained multilingual models.
-
Isolated is well studied compared to Continuous SLR models because of the complexity they possess and labelled multilingual datasets are very hard to create or generate in those cases pretraining approaches may work better and give good results.
References:
-
OpenHands-https://arxiv.org/abs/2110.05877
-
Include-https://dl.acm.org/doi/10.1145/3394171.3413528
-
WenetSpeech Corpus paper- https://arxiv.org/abs/2110.03370
-
Yan S., Xiong, Y., and Lin D. 2018. Spatial temporal graph convolutional networks for skeleton-based action recognition.
-
Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.;Cheng, J.; and Lu, H. 2020a. Decoupling gcn with dropgraph module for skeleton-based action recognition. In Proceedings of the European Conference on Computer Vision (ECCV).
-
\bibitem{B18} Cheng, Y.-B.; Chen, X.; Zhang, D.; and Lin, L. 2021. Motion-Transformer: Self-Supervised PreTraining for Skeleton-Based Action Recognition. New York, NY, USA: Association for Computing Machinery.
-
Han, T.; Xie, W.; and Zisserman, A. 2019. Video representation learning by dense predictive coding
-
https://google.github.io/mediapipe/solutions/holistic
Thank you
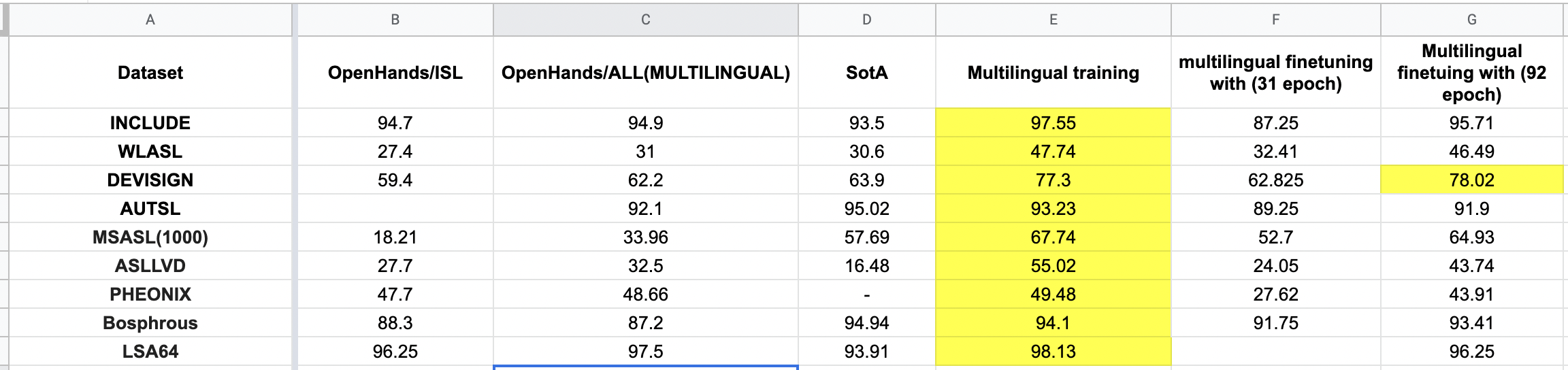
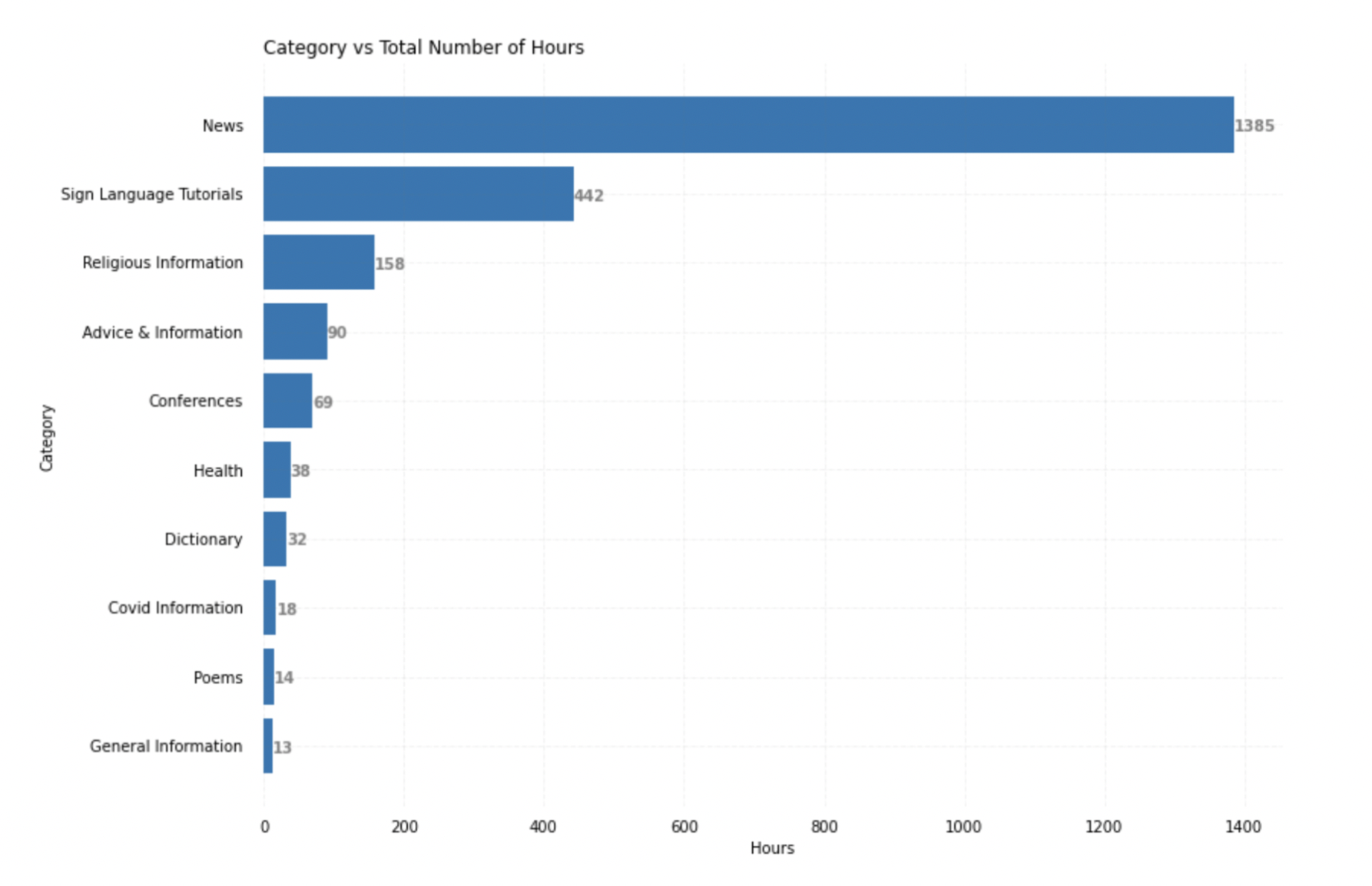
Few more Results: