Web-Scale Data Curation of American Sign Language for Sign Language Models
Github source: https://github.com/AI4Bharat/SLR-Data-Pipeline/tree/sumit
Guided By : Prof. Mitesh Khapra (IIT Madras),
Prof. Pratyush Kumar (IIT Madras)
Name : Manideep Ladi
Roll Number : CS20M036
Index
- Introduction
- Background & Related work
- Objective
- SLR Data Pipeline
- Results
- Future Work
- References
Introduction
Sign Language:
-
Like, native languages Sign language has its own grammar, syntax, vocabulary, and lexicon.
-
SLs are composed of the following indivisible features: Manual features, i.e. hand shape, position, movement, orientation of the palm or fingers, Non-manual features, namely eye gaze, head-nods/ shakes, shoulder orientations, various kinds of facial expression as mouthing and mouth gestures.
Indian sign language:
- The Indian Sign Language Research and Training Center (ISLRTC) was founded in 2015 with the goal of educating and conducting research in ISL.
Sign Langauge Recognition:

-
It is a well known research problem but not well studied problem.
-
SLR problem is divided into two types: a) Isolated SLR b) Continous SLR
Related Work:
Initial research is done using Machine Learning Models like SVMs, Random forest as it is a classification task.
Deep Learning Based Models based on RGB as Modality like CNNs+LSTMs, 3D-Convnets.
Deep Learning Based Models based on Pose as Modality like TGCN, STGCNs, Decoupling ST-GCNs.
INCLUDE: A Large Scale Dataset for Indian Sign Language Recognition
-
It contains 0.27 million frames across 4,287 videos over 263 word signs from 15 different word categories.
-
The best performing model achieves an accuracy of 94.5% on the INCLUDE-50 dataset and 85.6% on the INCLUDE dataset.
OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
-
This paper introduce OpenHands, a library where they take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition.
-
It is a open-source library, all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible.
-
Standardizing on pose as the modality.--->6 different sign languagues
-
Standardized comparison of models across languages.---> 4 different models
-
Corpus for self-supervised training.---> 1100 hrs of preprocessed Indian sign data
-
Effectiveness of self-supervised training.
4 Key Ideas of OpenHands:
Objective
Sign language is a low-resource language and hence its recognition is not well studied. To make SLR more researchable and accessible, we need a large amount of data, whether labeled or unlabeled (for pretraining and finetuning). So, the aim is to curate sign language data for various languages and preprocess them using scalable and efficient methods.
SLR Data Preprocessing Pipeline Diagram
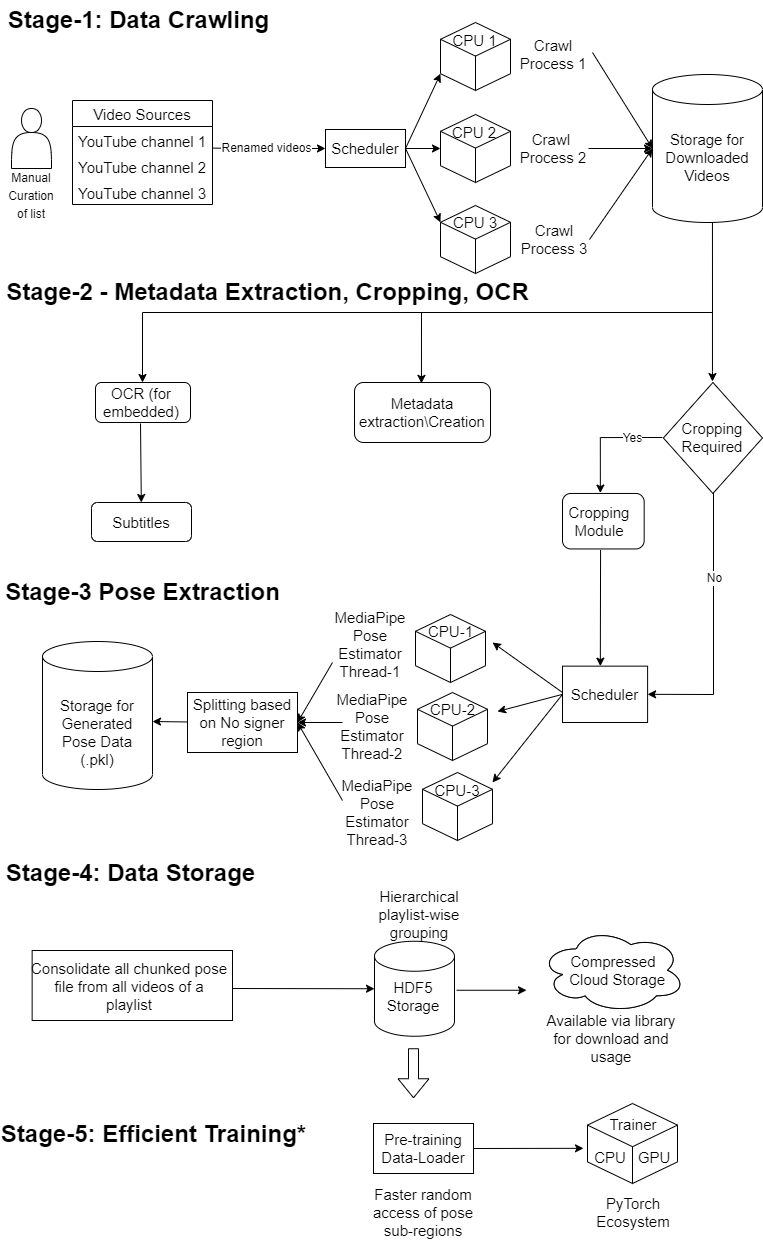
Identifying Data Sources
- Search in native language(with the help of google translator) and English both ways.
- Organized the sources into separate sheet for different sign languages.
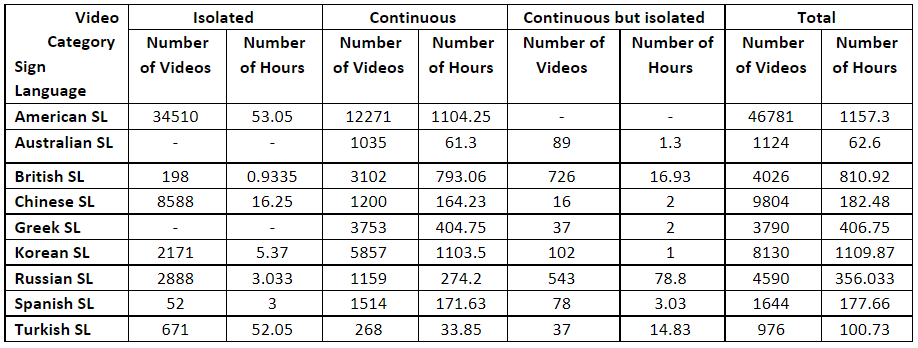
Identified Resource Statistics
-
Approximately collected 4000 hrs of data across 9 different sign languagues.
Video Collection
- Wrote a script for downloading videos with the help of YT-DLP library.
- Downloaded videos saved in a well-defined folder structure.
- Almost 1100 hours of video downloaded for American Sign Language.

Cropping
Original image
After cropping
- Some videos contains signer at corner or some background noise.
- Main goal is to get signer only.
- Written a python script using ffpmeg library to crop videos.
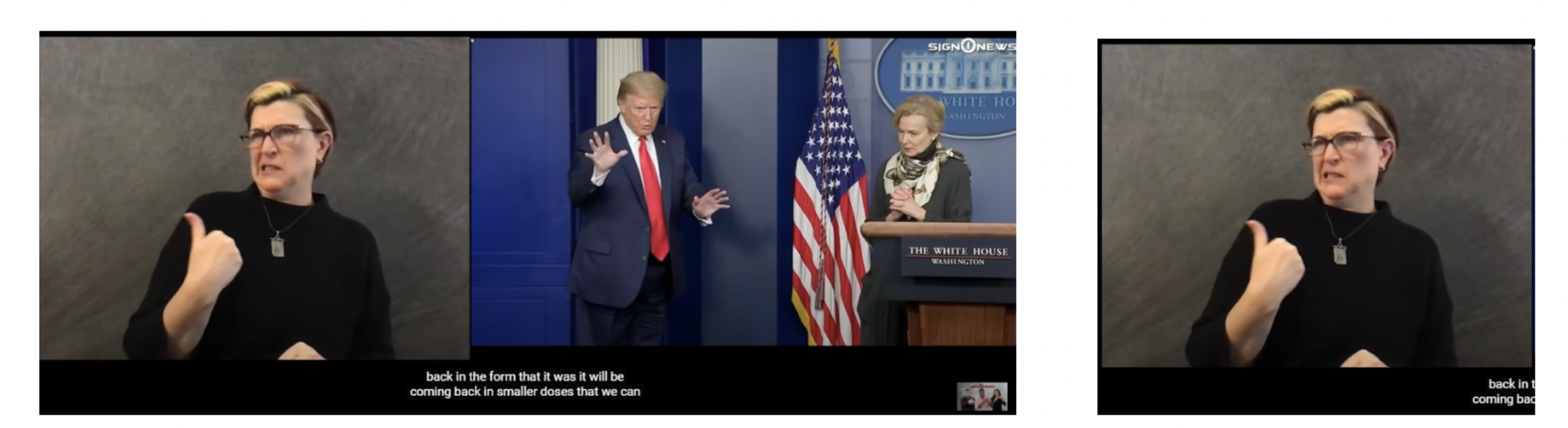
Pose Extraction
Original image
Final Pose keypoints
Image with keypoints
- Poses of the signer were extracted using Mediapipe Holistic library.
- Mediapipe Holistic process gives keypoints corresponding to face, hands and body.

Metadata Extraction
- Metadata for the purpose of backtracking of the source of a video.
- Important metadata - Youtube video id, title, webpage url etc.
Storing Poses with Metadata
- HDF5 format for storage.
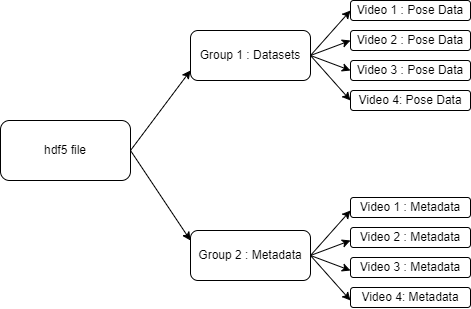
HDF5 schema
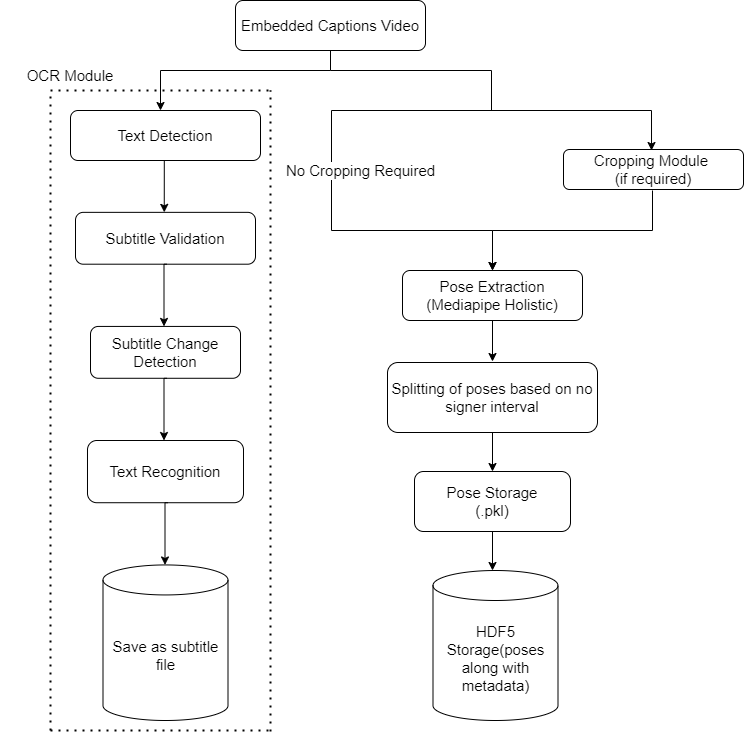
Flowchart for videos with Embedded Captions:
Embedded Subtitles Extraction
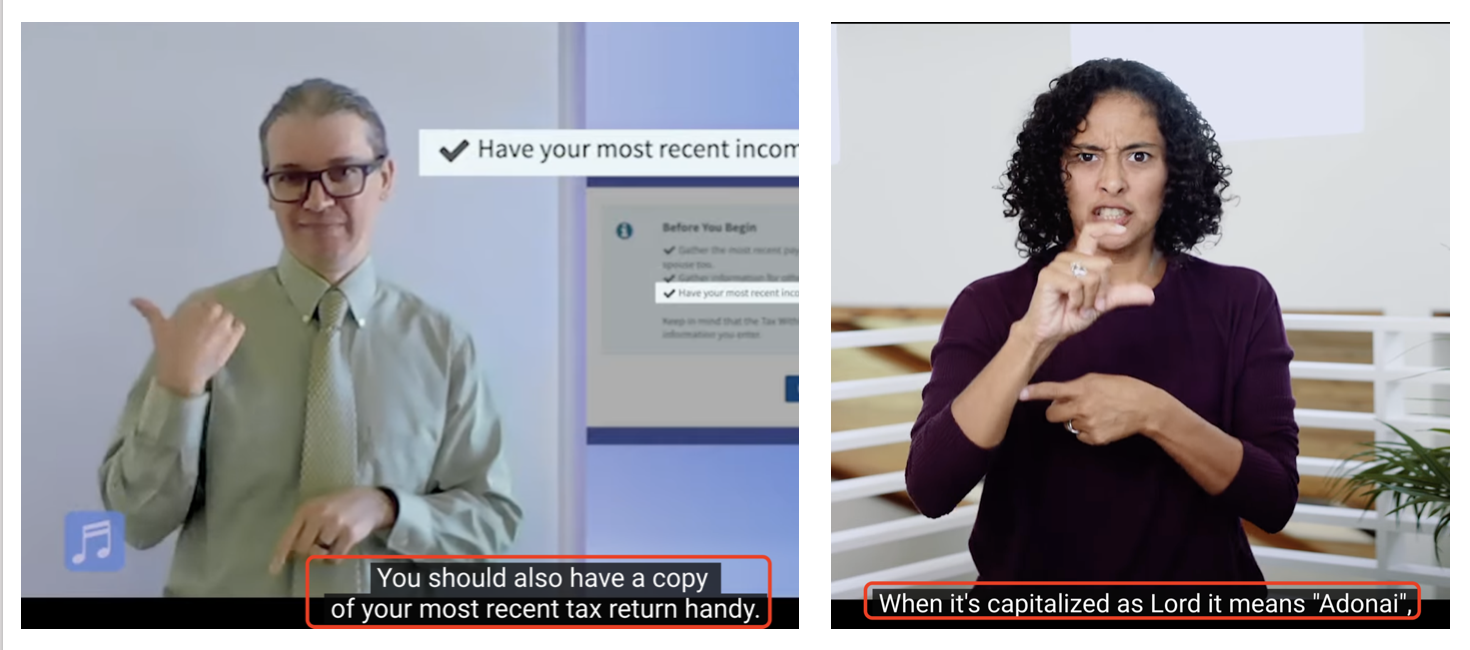
Embedded Captions
- Similarity detection across continuous frames in the subtitle region
- Higher similarity means same text.
- EasyOCR for text recognition.
Results:
- Almost 1100 hours of American Data is preprocessed.
- 96 CPUs for running pose extraction, embedded captions extraction parallely.

Future Work
- Preprocessing of the other sign languages both for Fine tuning and self supervised learning.
- Sanity checks for the pose data to check their quality.
- Pretraining the ISLR models for each of the existing ISLR datasets using the raw data for the corresponding sign language.
- Pretraining the ISLR models using all sign languages in the same model.
- Exploring the various pretraining strategies for CSLR.
- Releasing the pose-based CSLR models for different sign languages.
- Build Multilingual Models both for ISLR and CSLR by passing intial tokens saying the language they belong to during training.
References:
-
OpenHands-https://arxiv.org/abs/2110.05877
-
Include-https://dl.acm.org/doi/10.1145/3394171.3413528
-
WenetSpeech Corpus paper- https://arxiv.org/abs/2110.03370
-
Yan S., Xiong, Y., and Lin D. 2018. Spatial temporal graph convolutional networks for skeleton-based action recognition.
-
Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.;Cheng, J.; and Lu, H. 2020a. Decoupling gcn with dropgraph module for skeleton-based action recognition. In Proceedings of the European Conference on Computer Vision (ECCV).
-
\bibitem{B18} Cheng, Y.-B.; Chen, X.; Zhang, D.; and Lin, L. 2021. Motion-Transformer: Self-Supervised PreTraining for Skeleton-Based Action Recognition. New York, NY, USA: Association for Computing Machinery.
-
Han, T.; Xie, W.; and Zisserman, A. 2019. Video representation learning by dense predictive coding
-
https://google.github.io/mediapipe/solutions/holistic
Thank you