Association Rule mining algorithms for Co-Change analysis
Contents
1. Introduction
2. Data set and frequent sets
3. Closure property
4. List of algorithms
5. Apriori algorithm
6. Partition,Pincer serach,DIC
7. FP growth tree
8. Comparative study
9. Conclusion

Introduction
-
Association rules are if/then statements that help uncover relationships between seemingly unrelated data in a relational database or other information repository. An example of an association rule would be "If a customer buys a dozen eggs, he is 80% likely to also purchase milk."
Data set
Items (9 items)
Transactions
(15 transactions)
Ex: Support count = 20%, for 15 transactions 3 is support count
frequent sets = (2), (3), (2,4), (3,5,7)
Closure Property
Downward Closure Property:
Any subset of a frequent set is a frequent set.
ex: (3,5,7) is frequent then
(3,5)
(3,7)
(5,7) are frequent.
Upward Closure Property:
Any superset of an infrequent set is an infrequent set.
ex: (2,5) is infrequent then
(2,3,5)
(2,5,7) etc are infrequent.
List of algorithms
1. A Priori Algorithm
2. Partition Algorithm
3. Pincer Search Algorithm
4. Dynamic Itemset Counting Algorithm
5. FP-Tree Growth Algorithm
6. Dynamic FP-Tree growth Algorithm
A priori
Makes use of Dounward closure property. Uses bottom up approach.
Example: Considering Frequency support 20%

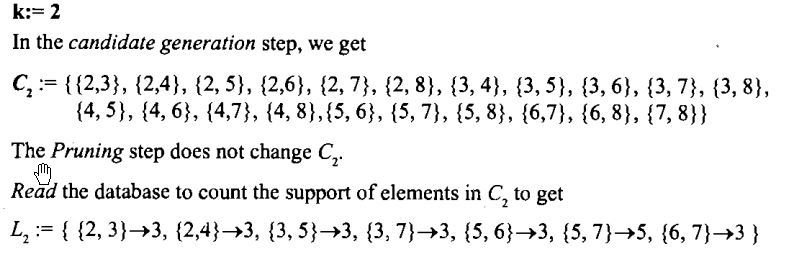



Partition Algorithm
The partition algorithm works same as apriori. It uses downward closure property and bottom up approach. It divides the dataset into several parts and finds the frequent items and combines them to give a single result.
Pincer search Algorithm
This is a bi- directional search, which takes advantage of both bottom-up as well as the top-down process. It uses both upward and downward closure property.
It attempts to find frequent set in bottom up manner(as in apriori) at the same time it maintains maximal frequent set.
Dynamic Itemset counting Algorithm
-
Alternative to Apriori Itemset Generation
-
Itemsets are dynamically added and deleted as transactions are read
-
Relies on the fact that for an itemset to be frequent, all of its subsets must also be frequent, so we only examine those itemsets whose subsets are all frequent
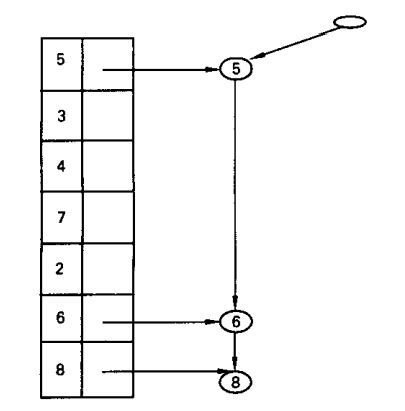
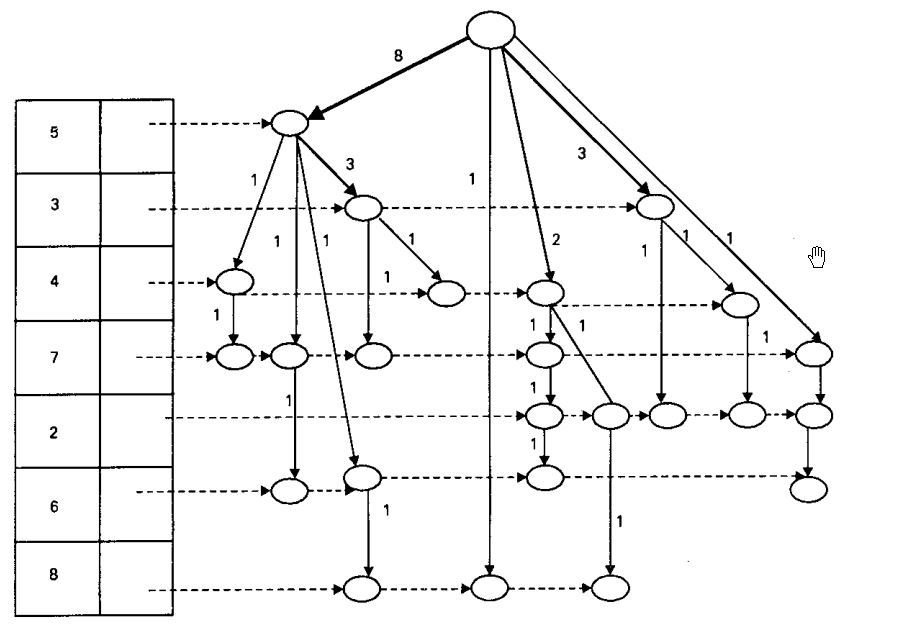
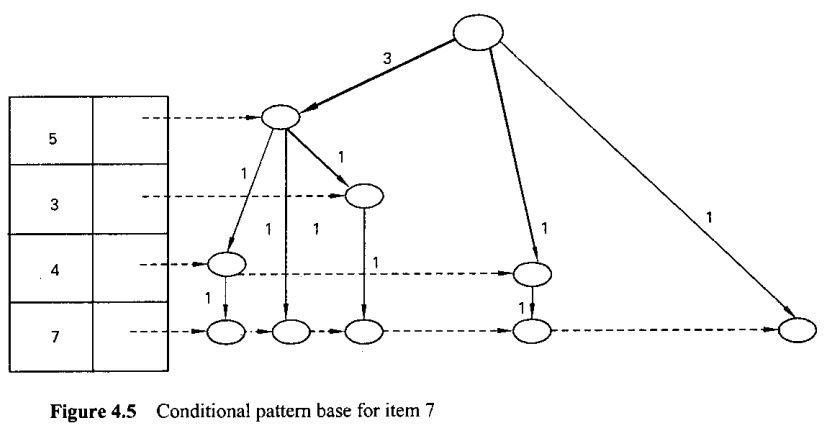
FP-Tree growth Algorithm
The main idea of the algorithm is to maintain a Frequent Pattern Tree(FP Tree) of the data base.
The algorithm involves 2 phases.
In 1st phase it constructs FP tree which involves only 2 passes over database.
In 2nd phase it only uses tree and does not require database. Interestingly FP tree contains all the information about frequent itemset with respect to given min support.
Example:


Comparative Study
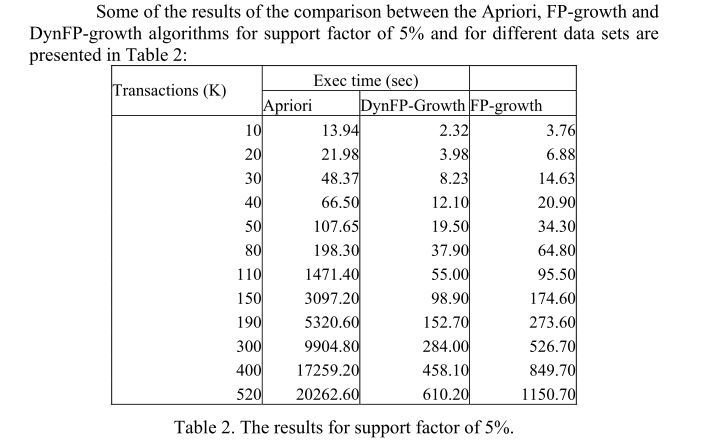
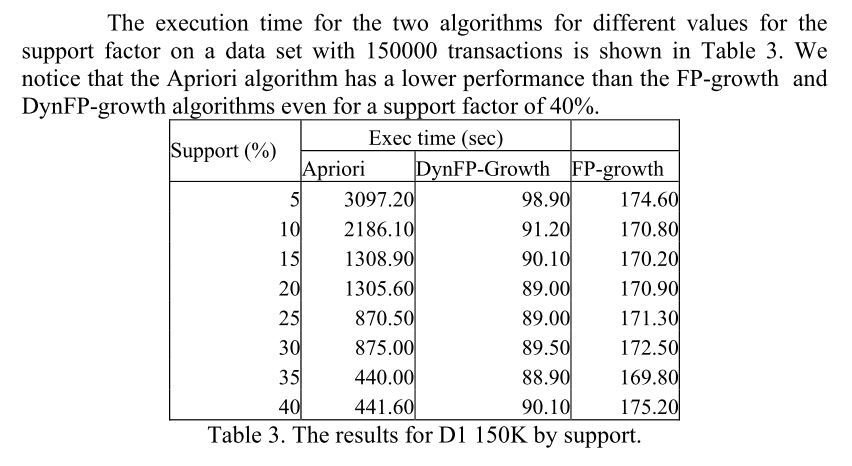
Conclusion
1. It can be concluded that FP tree algorithm behaves better than all other algorithms. The main reason that FP growth algorithm needs at most two scana of the database, while the number of database scans for apriori increases with dimension of candidate itemset.
2. Performance of FP-tree is not influenced by support factor. while apriori does. Its performance decreases with the support factor.
3. The candidate generating algorithms(derived from apriori) behave well only for small databases(max 50,000 transactions) with large support factor(at least 30%).
4. For large datasets i.e large transactions Fp tree growth algorithm behaves well.
References:
1. Text book: "Data Mining Techniques" bu Arun K Pujari
pages refered: 73 to 100
2. A comparative study of association rules mining algorityhms by Cornelia Gyorodi, Robert Gyorodi and Stefan Holban.
Thank You
