
Manoj Pandey
...

An Introduction to
Web Scraping using Python
manojpandey96

AGENDA
-
What/Why Web Scraping
-
Scraping vs APIs
-
Useful libraries available
-
Which library to use for which job
-
What is Scrapy Framework
-
When and when not to use !
-
Legalities ( ͡° ͜ʖ ͡°)
Web SCraping
WHYYYYYYYYY



Web SCraping
What is it ?
Web scraping is a technique for gathering data or information on web pages.
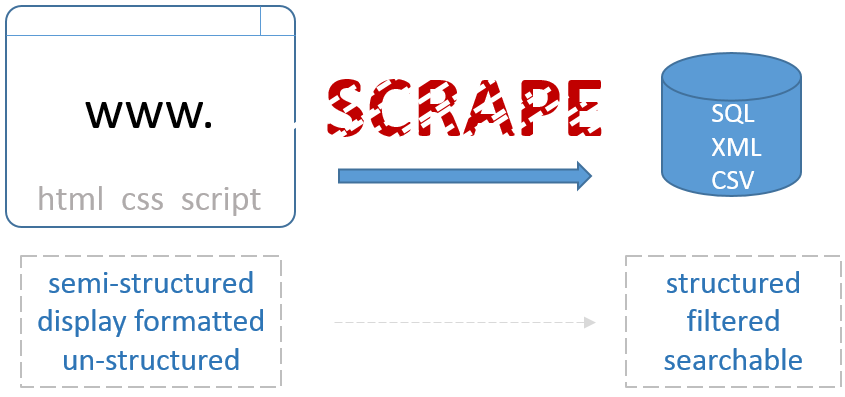
Web SCraping
What is it ?
It is a method to extract data from a website that does not have an API or we want to extract a LOT of data which we can not do through an API due to rate limiting.
"If you can see it, you can have it as well"
USAGE
web scraping in real life
- Extract product information
- Extract job postings and internships
- Extract offers and discounts from deal-of-the-day websites
- Crawl forums and social websites
- Extract data to make a search engine
- Gathering weather data
- etc.
ADVANTAGES
web scraping vs. using AN API
- Web Scraping is not rate limited
- Anonymously access the website and gather data
- Some websites do not have an API
- Some data is not accessible through an API
- and many more !
WORKFLOW
Essential parts of WEB SCRAPING
Web Scraping follows this workflow:
- Get the website - using HTTP library
- Parse the html document - using any parsing library
- Store the results - either a db, csv, text file, etc
We will focus more on parsing.
LIBRARIES
useful libraries available
- BeautifulSoup (bs4)
- lxml
- selenium
- re
- scrapy
HTTP libraries
useful libraries available
- Requests
- urllib/urllib2
- httplib/httplib2
r = requests.get('https://www.google.com').htmlhtml = urllib2.urlopen('http://python.org/').read()h = httplib2.Http(".cache")
(resp_headers, content) = h.request("http://python.org/", "GET") PARSING libraries
useful libraries available
- beautifulsoup
- .
- lxml
- .
- re
tree = BeautifulSoup(html_doc)
tree.title tree = lxml.html.fromstring(html_doc)
title = tree.xpath('/title/text()') title = re.findall('<title>(.*?)</title>', html_doc) BeautifulSoup
pros and cons !
- A beautiful API
- .
- .
- very easy to use
- can handle broken markup
- purely in Python
- slow :(
soup = BeautifulSoup(html_doc)
last_a_tag = soup.find("a", id="link3")
all_b_tags = soup.find_all("b") lxml
pros and cons !
The lxml XML toolkit provides Pythonic bindings for the C libraries libxml2 and libxslt without sacrificing speed.
- very fast
- not purely in Python
- If you have no "pure Python" requirement use lxml
- lxml works with all python versions from 2.x to 3.x
re
pros and cons !
re is the regex library for Python.
It is used only to extract minute amount of text.
- requires you to learn its symbols e.g
- can become complex
- purely baked in Python
- a part of standard library
- very fast - I will show later
- supports every Python version
'.',*,$,^,\b,\w re
pros and cons !
http://.../
<a class="mylink" href="http://.../" ... >
Comparison
bs4 vs. lxml vs. re
import re
import time
import urllib2
from bs4 import BeautifulSoup
from lxml import html as lxmlhtml
def timeit(fn, *args):
t1 = time.time()
for i in range(100):
fn(*args)
t2 = time.time()
print '%s took %0.3f ms' % (fn.func_name, (t2-t1)*1000.0)
def bs_test(html):
soup = BeautifulSoup(html)
return soup.html.head.title
def lxml_test(html):
tree = lxmlhtml.fromstring(html)
return tree.xpath('//title')[0].text_content()
def regex_test(html):
return re.findall('', html)[0]
if __name__ == '__main__':
url = 'http://pydelhi.org'
html = urllib2.urlopen(url).read()
for fn in (bs_test, lxml_test, regex_test):
timeit(fn, html) manoj@manoj:~/Desktop$ python test.py
bs_test took 1851.457 ms
lxml_test took 232.942 ms
regex_test took 7.186 ms - lxml took 32x more time than re
- BeautifulSoup took 245x! more time than re
massive scraping
what to do ?
- millions of web pages everyday
- large scale web scraper
- robustly tested
Is there any solution ?
SCRAPY
to the rescue !
-
Speed: Very fast.
-
Full blown away throughly tested framework.
-
Asynchronous.
-
Easy to use.
-
Customizable.
-
No need to reinvent the wheel.
-
Made in Python.
SCRAPY
When to use ?
- When you have to scrape millions of pages
- When you want asynchronous support out of the box
- When you don't want to reinvent the wheel
- When you are not afraid to learn something new
SCRAPY
Starting out!
The workflow in Scrapy:
- Define a scraper
- Define the items you are going to extract
- Define the items pipeline (Optional)
- Run the scraper
SCRAPY
Starting out!
$ scrapy startproject pyconpycon
├── scrapy.cfg
└── pycon
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
SCRAPY
scrapy item
Items are containers that will be loaded with the scraped data. They work like simple Python dicts but provide additional protecting against populating undeclared fields, to prevent typos.
- Declaring an Item class:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
description = scrapy.Field() SCRAPY
scrapy item
- Use the scrapy shell to test scraping:
- Scrapy provides xpaths, css selectors and regex to extract data
- Extracting the title using xpath:
- That's it!
$ scrapy shell http://dmoztools.net/Computers/Programming/Languages/Python/Books/title = sel.xpath('//title/text()').extract() SCRAPY
scrapy item
-
A spider is a class written by the user to scrape data from a website. Writing a spider is easy. Just follow these steps:
- Subclass
- Define start_urls list
- Define the parse method in your spider
scrapy.SpiderSCRAPY
full spider
import scrapy
from pycon.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://dmoztools.net/Computers/Programming/Languages/Python/Books/",
"http://dmoztools.net/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
item = DmozItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield itemSCRAPY
running the spider !
2016-02-28 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: pycon)
2016-02-28 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2016-02-28 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2016-02-28 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2016-02-28 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2016-02-28 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2016-02-28 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2016-02-28 18:13:07-0400 [dmoz] INFO: Spider opened
2016-02-28 18:13:08-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2016-02-28 18:13:09-0400 [dmoz] DEBUG: Crawled (200) (referer: None)
2016-02-28 18:13:09-0400 [dmoz] INFO: Closing spider (finished) $ scrapy crawl dmozSCRAPY
storing the data
$ scrapy crawl dmoz -o items.jsonYou have two choices:
- Use feed export
- Define Item pipelines
Using feed export:
SCRAPY
When not to use ?
- You are just making a throw away script.
- You want to crawl a small number of pages.
- You want something simple.
- You want to reinvent the wheel and want to learn the basics.
CONFUSED ?
WHAT SHOULD YOU USE ?
- Simple extraction: re.
- If you want to extract a lot of data and do not have a "pure Python" library requirement then use lxml
- Broken markup: BeautifulSoup.
- If you want to scrape a lot of pages and want to use a mature scraping framework then use Scrapy.
CONFUSED ??
WHAT DO I PREFER ?
- See for yourself : Time vs Speed tradeoff
-
Check library support
- bs4/lxml has huge number of resources
- scrapy - not so much
Legalities
- very gray area
- depends on how data is used
- follow robots.txt
- some websites prohibit scraping
- use ethically
Thanks. grazie mille.
• martin grasser • enrica miron
• rachel knowler • peter inglesham • adrian childers


questions ?

manojpandey96
manojpandey
manojpandey1996