Natural Language Processing
with Deep Learning
Stanford CS224N
by Richard Socher
自修心得
about me
EE degree back in 1982
Z80 was the most popular CPU
Pascal/Fortran/COBOL were popular languages
Apple ][ + BASIC and CP/M
intel 80386SX PC mother board designer
......
Interested in Linux since 2016

Z80 CPU

intel 80386SX CPU
photo source: wikipedia.org

Apple ][
marconi.jiang@gmail.com
參考資料
Vocaburary
-
詞向量介紹 : 在語言學的定義中,詞(word)是表達意義的最小單位;字(character)是書寫的最小單位。在這篇文章的用詞上, 原文(英文)只有提到 word, 完全沒提到 character, 因此, 在翻譯時, 將 word 翻譯成 ‘詞’ 或 ‘字詞’ 來保存文句通順, 指的都是 word 的意思。至於中文詞與字, 相對於英文而言, 對 DL 是否也可以適用, 還需是進一步探討. 個人認為, 中文的注音/拼音比較像是英文的字 (character), 但是內隱的, 中文的字比較接近 word, 而詞比較接近 phrase. (到底, 我不是專家, 要看專家怎麼說)
Natural Language Processing
是
計算機科學 + 人工智慧 + 語言學
的交集
要了解人類語言並表達其中的意義是極困難的挑戰,
也是人工智慧的極致表現
1/9/2018
自然語言的處理階段
語言
文字
拼音/音韻分析
文字辨識/資料記號化
(Tokenization)
詞法分析 Morphological
語法分析 Syntactic
語義解釋 Semantic
交談內容處理 Discourse
NLP 的一些應用
簡單到複雜的應用
- 拼字檢查、keyword 搜索、尋找同義字
- 從網站內容擷取訊息
- 產品價格、日期、所在位置、人名、公司名
- 分類:學校課程內容的等級分類、文章的正向/負面情緒
- 機器翻譯
- 語音對話系統
- 複雜問題回答
NLP 在工業界的應用正起飛中
- 搜尋(文字與語音輸入)
- 線上廣告媒合
- 電腦自動/輔助翻譯
- 行銷或財務/交易之情緒分析
- 語音辨識
- 聊天機器人/對話代理人
- 客戶服務自動化
- 家電裝置控制
- 訂購貨物
人類語言的特殊性
-
人類語言系統是深思熟慮後的溝通方式, 讓小孩可以很快學習(是嗎?)
-
人類的語言大都是分散式、象徵性、明確的信號系統 (signaling system)。
-
想必是較好信號的可靠性
-
符號 (symbol) 不僅是數位邏輯/傳統人工智慧的發明
-
-
語言中明確的符號, 可以用以下的編碼方式作為溝通的信號
-
聲音
-
手勢
-
寫作
-
圖片
-
不同的編碼 (encoding), 但符號 (symbol) 是不變的
-
-
人類的語言是象徵性、明確的信號系統
-
然而, 大腦的編碼系統看起來是連續性的活化模式 (pattern of activation), 符號 (symbol) 藉由連續的聲音/影像信號傳送
-
大量的詞彙, 字詞符號的編碼造成機器學習的困擾 - 資料的稀疏性
-
接下來會探索心思的連續性編碼模式 continuous encoding pattern
Deep Learning vs Machine Learning
Machine learning
-
大多數 machine learning 方法運作的效果不錯的原因, 是因為人類設計的表現方式以及輸入的特徵值
-
例如:找出位置或組織名稱等註明的項目
-
-
Machine learning 只是在權重值的優化來達到最佳的預測
-
實務上, machine learning 分成 2 個階段
-
將資料描述成電腦可以理解的特徵值, 這需要該領域博士級的專家
-
學習的 algorithm, 優化特徵值的權重
-
Deep learning
-
特徵學習 representation learning 嘗試去學習好的特徵 features 或表達方式 presentations
-
DL 的演算法嘗試從原始未經分析的資料輸入學習到(多層的)特徵及一個輸出
為什麼選擇 Deep Learning
-
人工設計的特徵通常都是過高規格, 不完整, 且從設計到認證曠日費時
-
DL 學習的特徵 features 很容易調適, 快速學習
-
DL 提供非常有彈性、(幾乎)是萬能、可學習的框架, 來表達這世界的影像、語音資訊
-
DL 有監督式及非監督式學習
-
從 2010 年起, DL 的技術開始超越 ML, 原因在於:
-
有大量的訓練用資料, 對 DL 有益
-
高速電腦及多核心的 CPU/GPU
-
新的模型、演算法、想法
-
更好、更有彈性的中間碼 intermediate representation
-
有效的端到端的整合性系統學習
-
有效的運用上下文 context 及工作間傳送 transferring between tasks 的學習方法
-
更好的正規化及優化的方法
-
-
-
總之, 得到更好的績效, 從語音、影像到自然語言
Deep Learning 在語音的應用
-
DL 在大數據的第一個突破是在語音辨識
-
Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition Dahl et al. (2010)
| Acoustic model and WER | RT03S FSH | Hub5 SWB |
|---|---|---|
| Traditional features | 27.4 | 23.6 |
| Deep Learning |
18.5 (−33%) |
16.1 (−32%) |
Deep Learning 在影像的應用
-
DL 第一個主要焦點群組在電腦影像
-
DL 突破性論文:ImageNet Classification with Deep Convolutional Neural Networks by Krizhevsky, Sutskever, & Hinton, 2012, U. Toronto. 37% error red.
Prerequisites
-
Proficiency in Python
- All class assignments will be in Python.
- Python refresh session: 3:00-4:20pm, January 19!
- Multivariate Calculus, Linear Algebra (e.g., MATH 51, CME 100)
- Basic Probability and Statistics (e.g. CS 109 or other stats course)
-
Fundamentals of Machine Learning (e.g., from CS229 or CS221)
- loss functions
- taking simple derivatives
- performing optimization with gradient descent.
這門課要教什麼
-
了解並具備運用 DL 當前有效方法的能力
-
先具備基礎, 再學習運用於 NLP 的主要方法: Recurrent networks, attention, 等等.
-
-
大致了解人類語言同時認知了解以及產生這些語言的困難度
-
了解並且有能力去建立 (TensorFlow) 系統, 以面對一些 NLP 的主要問題:
-
Word similarities 相似字
-
parsing 解析
-
machine translation 機器翻譯
-
entity recognition 個人辨識
-
question answering 問題回答
-
sentence comprehension 句子理解
-
-
Libraries like TensorFlow are becoming standard tools
-
Also:PyTorch,Theano,Chainer,CNTK,Paddle,MXNet,Keras,Caffe,...
-
為什麼 NLP 很難
-
表達上、學習上、使用上的複雜度 - 語言/情境/上下文/世界/視覺/知識程度 linguistic/situational/contextual/world/visual knowledge
-
依賴這些來解釋
-
人類語言是含糊不清的 (不像程式及其它正規語言)
-
例如: “I made her duck.” 我幫她準備鴨當晚餐
-
以下是新聞或 tweet 標題
-
The Pope’s baby steps on gays
-
Boy paralyzed after tumor fights back to gain black belt
-
Enraged cow injures farmer with axe
-
Juvenile Court to Try Shooting Defendant
-
Deep NLP = Deep Learning + NLP
- 結合 NLP 的想法及目標, 運用特徵學習 representation learning 以及 DL 來解決問題
-
近年來, NLP 有些重大突破
- 語言學水準:語音、字詞、句法 syntax、語義 semantics
- 中間層工作、工具:詞類 parts-of-speech, 個體 entity, 解析 parsing
- 完整應用:情緒分析、問題回答、對話代理人、機器翻譯
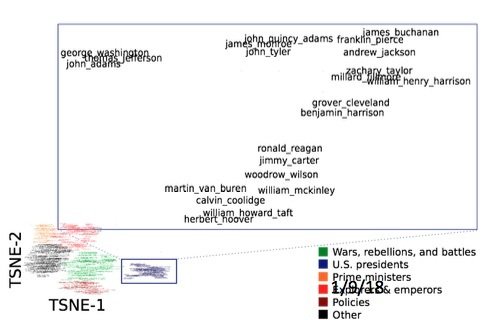
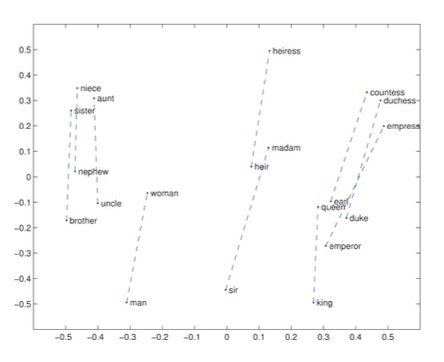
字詞的意思成為神經詞向量 neural word vector - 視覺化 visualization
expect
{
}
0.286
0.792
−0.177
−0.107
0.109
−0.542
0.349
0.271
0.487
need
help
come
qo
give
keep
take
meet
see
make
get
continue
think
say
expect
want
remain
become
was
were
is
be
are
been
being
has
had
字詞的相似度
-
類似青蛙 frog 的字詞
- frogs
- toad
- litoria
- leptodactylidae
- rana
- lizard
- eleutherodactylus
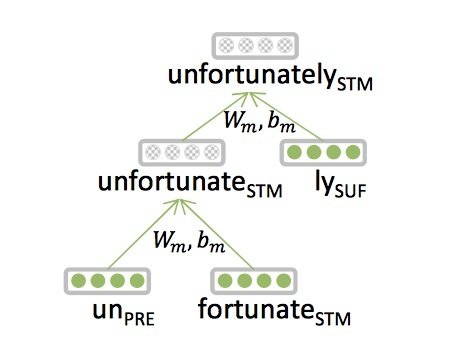
NLP 階層的特徵 - 詞法 Morphology
- 傳統上, 字是由詞素 morpheme 組成
-
Deep Learning
- 每個詞素 morpheme 都是向量
- 類神經網路組合 2 個向量成 1 個向量
- Luong et al. 2013
prefix stem suffix
un interest ed
NLP 的工具 - 句子結構的解析
Parsing for sentence structure
- 傳統上, 類神經網路可以正確判斷句子的文法結構
- 支援口語翻譯, 且幫助消除歧義 disambuigation

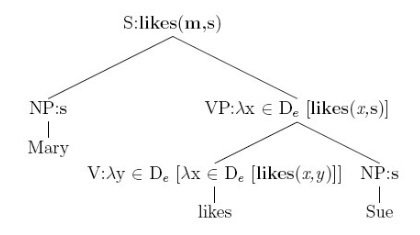
NLP 階層的特徵 - 語義 Semantics
-
傳統上用 Lambda 微積分
- 精密計算的工程函數
- 不同輸入都需要特定函數
- 無法表達語言的相似度或模糊性
-
Deep Learning
- 每個字詞、片語、邏輯表達式都是向量
- 類神經網路組合 2 個向量成 1 個向量
- Bowman et al. 2014
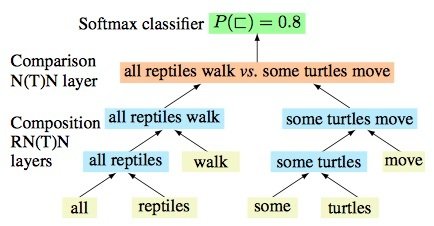
NLP 的應用 - 情緒分析
-
傳統上:將句子視為一袋子的字詞 (不區分字詞的循序); 參照專家整理後正向、負面字詞的名單, 來決定句子的情緒。
- 需要人工設計的特徵來擷取負面字詞 掛一漏萬
- 同樣的 DL 學習模式可以運用於詞法 morphology、句法 syntax 及邏輯語義 logical semantics RecursiveNN (aka TreeRNNs)
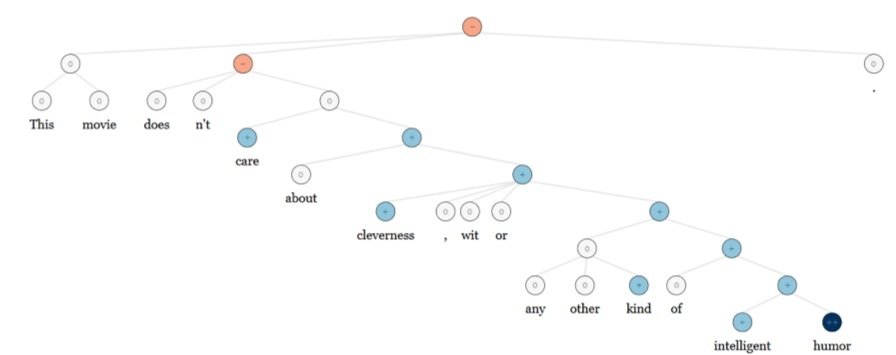
NLP 的應用 - 問題回答
-
傳統上:許許多多專注於特徵擷取的工程師需要擷取全面性或其它的知識, 例如, 正規表達式, Berant et al. (2014)
-
同樣的, DL 的架構可以適用
-
這些‘事實’ facts 都儲存在向量裡

NLP 的應用 - 對話代理人/解答產生器
-
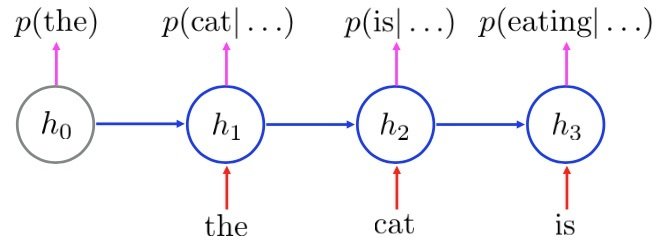
一個簡單的成功例子是 Google 郵箱的自動回覆, 是一個強大、類神經語言模式的一般性技巧的應用, 是基於 RNN (Recurrent Neural Networks) 的例子。
NLP 的應用 - 機器翻譯
-
過去, 嘗試過許多層次的翻譯
-
傳統的機器翻譯是一套大且複雜的系統
-
你想, 什麼是運用 DL 方法的語際翻譯?
NLP 的應用 - 類神經機器翻譯
-
原始語言句子映射成向量, 然後產生目標語言句子 [Sutskever et al. 2014, Bahdanau et al. 2014, Luong and Manning 2016]
現在, Google Translate 已經有許多語言上線, 而且大幅降低錯誤率
結論:所有階層的表達方式 - 向量
-
下一個主題是學習詞向量表達式, 以及它們表達的意思
-
下週, 類神經網路如何運作, 如何運用向量於所有 NLP 的階層及不同的應用

Natural Language Processing
with Deep Learning
Richard Socher
Lecture 2 : Word Vectors
1/11/2018
我們如何表達字詞的意思 meaning
-
meaning 含義在語言學裡最常用的是
signifier (symbol) 意符* 意指 signified (idea or thing)
= denotation 意味
* wiki 符號學
我們如何在電腦擁有可用的含義?
一般的解決方案: 使用資源, 例如 WordNet, 包含同義字及上位詞的表單 (“is a” relationships). [看不懂?]
例如 : 包含 "good" 的同義字集合
例如 : "panda" 的上位詞
from nltk.corpus import wordnet as wn
for synset in wn.synsets("good"):
print ('(%s)' % synset.pos(),', '.join([l.name() for l in synset.lemmas()]))
from nltk.corpus import wordnet as wn
panda = wn.synset("panda.n.01")
hyper = lambda s: s.hypernyms()
list(panda.closure(hyper))(n) good
(n) good, goodness
(n) good, goodness
(n) commodity, trade_good, good
(a) good
(s) full, good
(a) good
(s) estimable, good, honorable, respectable
(s) beneficial, good
(s) good
(s) good, just, upright
(s) adept, expert, good, practiced, proficient, skillful, skilful
(s) good
(s) dear, good, near
(s) dependable, good, safe, secure
(s) good, right, ripe
(s) good, well
(s) effective, good, in_effect, in_force
(s) good
(s) good, serious
(s) good, sound
(s) good, salutary
(s) good, honest
(s) good, undecomposed, unspoiled, unspoilt
(s) good
(r) well, good
(r) thoroughly, soundly, good
no outputRemark :
1. 需安裝 nltk, 執行 python -m nltk.downloader all, (儲存在 /home/macbookpro/nltk_data 目錄下. 詳見 Installing NLTK data
2. 因為 python2 print 那行出現invalid syntax, 用 python3 改寫了 print 相關指令. 參考 Why is invalid syntax error print '%s does not exist in %s for %s'. 跟課程內的輸出也有差異 (a vs adj)
3. 上列的程式沒有產生任何輸出, 需要加 print 指令才行, Google search lambda s: s.hypernyms()
運用如 Wordnet 的資源會遇到的問題
-
很棒的資源, 但是缺乏含義上的細微差異
- 例如, proficient 是 good 的同義詞, 但僅限於某些上下文時才成立
-
缺乏字詞的新的含義
- 例如 : wicked, badass, nifty, wizard, genius, ninja, bombest
- 不可能隨時更新到最新狀態
- 主觀
- 需要人力去創造內容, 去改編
- 很難去計算正確的字詞相似度, 下一頁詳細探討
用獨立的標記來表達字詞
-
傳統的 NLP, 我們把字詞視為獨立的標記 : 如 hotel, conference, motel
-
文字用 ont-hot (只有一個 1, 其它為 0) 向量來表達
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
-
向量的維度 = 詞彙中詞的總數量 (例如 500,000)
-
需要解決的問題, 例如:
-
在網路搜索時, 使用者要尋找 Seattle motel 時, 我們應該也得搜索 Seattle hotel
-
但是, 這兩個向量是正交的 orthogonal, 意思是, 用 one-hot 的表達式, 兩者完全沒有相似度
-
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
-
解決方式
-
能否用 wordnet 的同義詞列表來表達相似度
-
或者, 試著將相似度編碼進向量
-
用上下文來表達字詞
-
核心概念 : 字詞的含義由經常出現在前後的字詞來表達
-
由常陪伴該字詞出現的字詞可以判斷出該字詞的意思 (J. R. Firth 1957: 11)
-
現代統計學的 NLP 中最成功的一個概念
-
-