Web Scraping v Pythone
BeautifulSoup a Requests
Marek Mansell
FabLab Bratislava



Obrázky prevzaté z www.fablab.sk
Projekt RoboCoop



Obrázky prevzaté z robocoop.eu
Python?

Mu editor
Zmena
módu
Súčasný
mód
Knižnice
1. Mu Administration
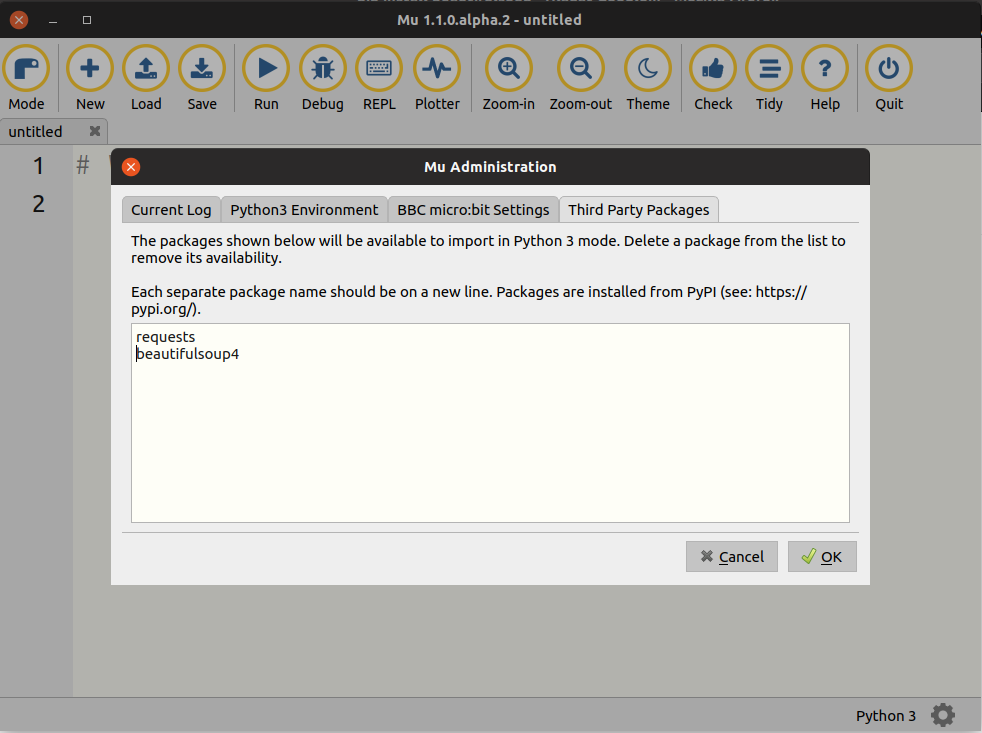
2. Third Party Packages
requests
beautifulsoup4
lxml
4. OK
3. Napíš názvy knižníc





web

GET www.pycon.sk
import requests
result = requests.get("https://python.sk/navody/scraping/blog/")
print(result.status_code)Requests - status code
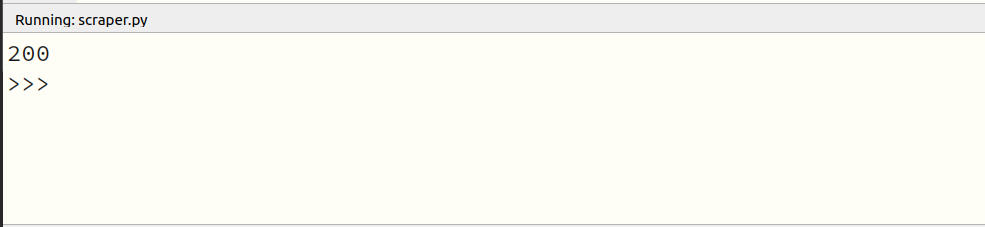
200 OK
301 Moved Permanently
404 Not Found
403 Forbidden
500 Int. Server Error
503 Service Unavailable
BeautifulSoup
import requests
from bs4 import BeautifulSoup
result = requests.get("https://python.sk/navody/scraping/blog/")
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
print(soup)
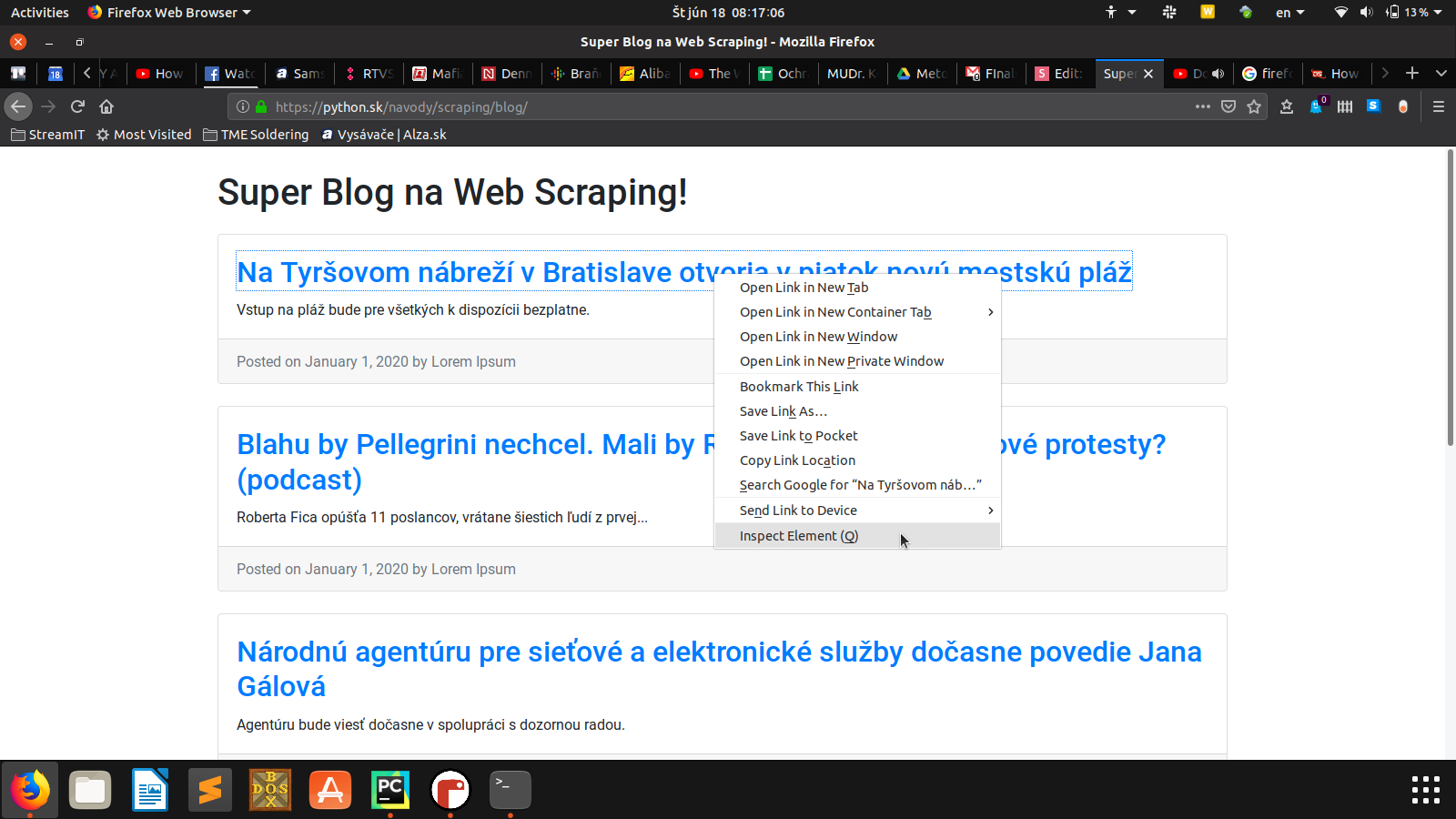
Inspect Element
https://python.sk/navody/scraping/blog/
Zdrojový kód stránky - HTML
<!DOCTYPE html>
<html lang="en">
<head>
<title>Super Blog na Web Scraping!</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<h1 class="my-4">Super Blog na Web Scraping!</h1>
<div class="card mb-4">
<div class="card-body">
<h2 class="card-title">
<a class="article-title" href="https://www.aktuality.sk/clanok/799751/bratislava-na-tyrsovom-nabrezi-otvoria-v-piatok-novu-mestsku-plaz/">
Na Tyršovom nábreží v Bratislave otvoria v piatok novú mestskú pláž
</a>
</h2>
<p class="card-text">
Vstup na pláž bude pre všetkých k dispozícii bezplatne.
</p>
</div>
<div class="card-footer text-muted">
Posted on January 1, 2020 by Lorem Ipsum
</div>
</div>
<div class="card mb-4">
<div class="card-body">
<h2 class="card-title">
<a class="article-title" href="https://www.aktuality.sk/clanok/799769/blahu-by-pellegrini-nechcel-mali-by-romovia-dovod-na-rasove-protesty-podcast/">
Blahu by Pellegrini nechcel. Mali by Rómovia dôvod na rasové protesty? (podcast)
</a>
</h2>
<p class="card-text">
Roberta Fica opúšťa 11 poslancov, vrátane šiestich ľudí z prvej...
</p>
</div>
<div class="card-footer text-muted">
Posted on January 1, 2020 by Lorem Ipsum
</div>
</div>
<div class="card mb-4">
<div class="card-body">
<h2 class="card-title">
<a class="article-title" href="https://www.aktuality.sk/clanok/799746/narodnu-agenturu-pre-sietove-a-elektronicke-sluzby-docasne-povedie-jana-galova/">
Národnú agentúru pre sieťové a elektronické služby dočasne povedie Jana Gálová
</a>
</h2>
<p class="card-text">
Agentúru bude viesť dočasne v spolupráci s dozornou radou.
</p>
</div>
<div class="card-footer text-muted">
Posted on January 1, 2020 by Lorem Ipsum
</div>
</div>
<div class="card mb-4">
<div class="card-body">
<h2 class="card-title">
<a class="article-title" href="https://www.aktuality.sk/clanok/799741/advokata-dusana-d-sts-v-pezinku-oslobodil-spod-obzaloby/">
Advokáta Dušana D. špeciálny súd v Pezinku oslobodil spod obžaloby
</a>
</h2>
<p class="card-text">
Súd v Pezinku obžalobu už raz pred približne dvoma rokmi...
</p>
</div>
<div class="card-footer text-muted">
Posted on January 1, 2020 by Lorem Ipsum
</div>
</div>
<div class="card mb-4">
<div class="card-body">
<h2 class="card-title">
<a class="article-title" href="https://www.aktuality.sk/clanok/799731/vlada-vymenovala-novych-clenov-legislativnej-rady-vlady-sr-zmenila-tiez-statut/">
Vláda vymenovala nových členov Legislatívnej rady vlády SR
</a>
</h2>
<p class="card-text">
Na dnešnom rokovaní vláda zároveň odvolala bývalých členov...
</p>
</div>
<div class="card-footer text-muted">
Posted on January 1, 2020 by Lorem Ipsum
</div>
</div>
<div class="card mb-4">
<div class="card-body">
<h2 class="card-title">
<a class="article-title" href="https://www.aktuality.sk/clanok/799707/ceski-diplomati-ktorych-vyhostilo-rusko-opustili-moskvu/">
Českí diplomati, ktorých vyhostilo Rusko, opustili Moskvu
</a>
</h2>
<p class="card-text">
Rusko považuje vyhostených diplomatov za nežiadúce osoby.
</p>
</div>
<div class="card-footer text-muted">
Posted on January 1, 2020 by Lorem Ipsum
</div>
</div>
</div>
</div>
</body>
</html>Nájdi všetky odkazy <a>

import requests
from bs4 import BeautifulSoup
result = requests.get("https://python.sk/navody/scraping/blog/")
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("a")
for link in links:
article_title = link.text
print(article_title) # skus zavolat .strip()Nájdi odkazy v nadpisoch
import requests
from bs4 import BeautifulSoup
result = requests.get("https://python.sk/navody/scraping/blog/")
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("h2")
for link in links:
article_title = link.find("a").text
print(article_title) # skus zavolat .strip()Nájdi odkazy s class "article-title"
import requests
from bs4 import BeautifulSoup
result = requests.get("https://python.sk/navody/scraping/blog/")
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("a")
for link in links:
if link.has_attr('class'):
if "article-title" in link.attrs['class']:
print(link.text.strip())
Aktuality.sk - novinky
https://www.aktuality.sk/online-rychle-spravy/
Aktuality.sk - novinky
import requests
from bs4 import BeautifulSoup
url = "https://www.aktuality.sk/online-rychle-spravy/"
result = requests.get(url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("a")
for link in links:
if "article-title" in link.attrs['class']:
print(link.text.strip())
print("--------")
https://www.aktuality.sk/online-rychle-spravy/
Úlohy
- Vypíšte všetkých rečníkov PyCon SK 2020
- Vypíšte krajiny rečníkov PyCon SK 2020
- Spočítajte, koľko rečníkov príde z ktorej krajiny
- Vypíšte mená aj BIO rečníkov
Vypíšte rečníkov PyCon SK 2020
import requests
from bs4 import BeautifulSoup
url = "https://2020.pycon.sk/sk/speakers/index.html"
result = requests.get(url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
titles = soup.find_all("h3")
for title in titles:
link = title.find("a")
if link:
print(link.text)
Vypíšte krajiny rečníkov
import requests
from bs4 import BeautifulSoup
url = "https://2020.pycon.sk/sk/speakers/index.html"
result = requests.get(url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
divs = soup.findAll(
"div",
{"class": "title-light size-md text-left color-light"},
)
for div in divs:
country = div.text
print(country)Spočítajte krajiny rečníkov
import requests
from bs4 import BeautifulSoup
url = "https://2020.pycon.sk/sk/speakers/index.html"
result = requests.get(url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
divs = soup.findAll(
"div",
{"class": "title-light size-md text-left color-light"},
)
countries = dict()
for div in divs:
country = div.text
if countries.get(div.text):
countries[country] += 1
else:
countries[country] = 1
print(countries)Mená aj BIO rečníkov
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def get_bio(bio_url):
result = requests.get(bio_url)
src = result.content
soup = BeautifulSoup(src, 'lxml')
divs = soup.find("div", {"class": "speaker-profile"})
bio = divs.find("p").text
return bio
url = "https://2022.pycon.sk/sk/speakers/index.html"
result = requests.get(url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
titles = soup.find_all("h3")
for title in titles:
link = title.find("a")
if link:
name = link.text
bio = get_bio(urljoin("https://2022.pycon.sk", link['href']))
print(name)
print(bio)
print()
Web Crawler
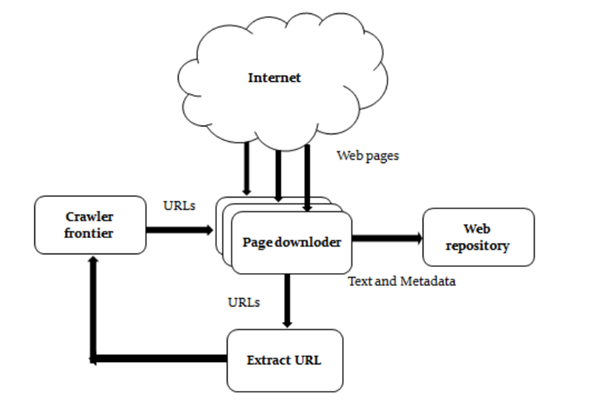
The architecture of Web Crawler. Resources: WEB CRAWLER FOR MINING WEB DATA
PyCon.SK crawler - odkazy
https://2020.pycon.sk/
import requests
from bs4 import BeautifulSoup
base_url = "https://2020.pycon.sk/"
result = requests.get(base_url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("a")
for link in links:
url = link.attrs['href']
print(url)
PyCon.SK - Ukladanie odkazov
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
local_urls = set()
local_urls_processed = set()
foreign_urls = set()
base_url = "https://2020.pycon.sk/"
result = requests.get(base_url)
print(result.status_code)
src = result.content
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("a")
for link in links:
url = link.attrs['href']
if url.startswith('/'):
local_urls.add(urljoin(base_url, url))
print(local_urls)PyCon.SK - rozlišovanie odkazov
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
local_urls = set()
local_urls_processed = set()
foreign_urls = set()
local_urls.add("https://2020.pycon.sk/")
while len(local_urls) > 0:
base_url = local_urls.pop()
local_urls_processed.add(base_url)
print(base_url)
result = requests.get(base_url)
src = result.content
print("STATUS: " + str(result.status_code))
soup = BeautifulSoup(src, 'lxml')
links = soup.find_all("a")
for link in links:
if link.has_attr('href'):
url = link.attrs['href']
if url.startswith('//'):
foreign_urls.add(url)
elif url.startswith('/'):
url = urljoin(base_url, url)
if (url not in local_urls_processed) and (url not in local_urls):
local_urls.add(url)
elif url.startswith('#'):
pass
else:
foreign_urls.add(url)
print(foreign_urls)
print(f"Local urls: {len(local_urls)}")
print(f"Foreign urls: {len(foreign_urls)}")
print(f"Crawled urls: {len(local_urls_processed)}")Ďalšie Python nástroje


Web na scrapovanie -> www.toscrape.com/
Využitie Crawlerov
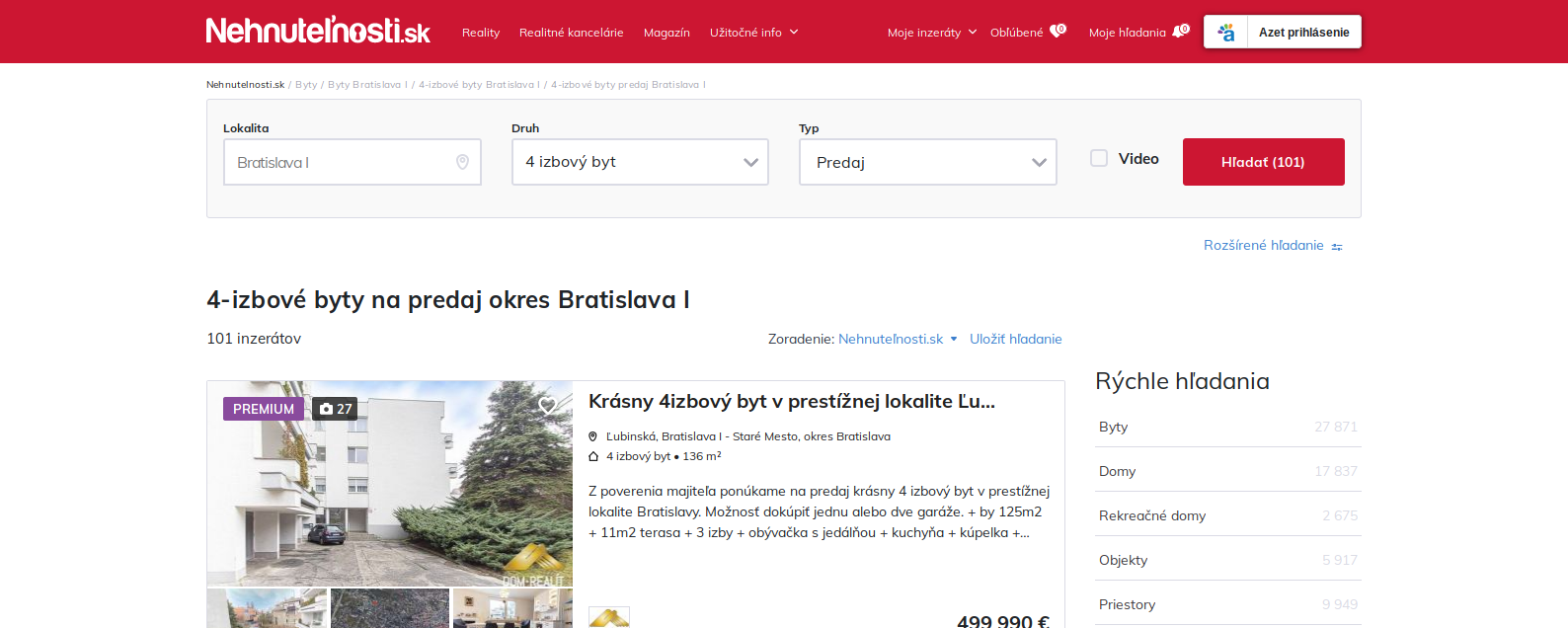
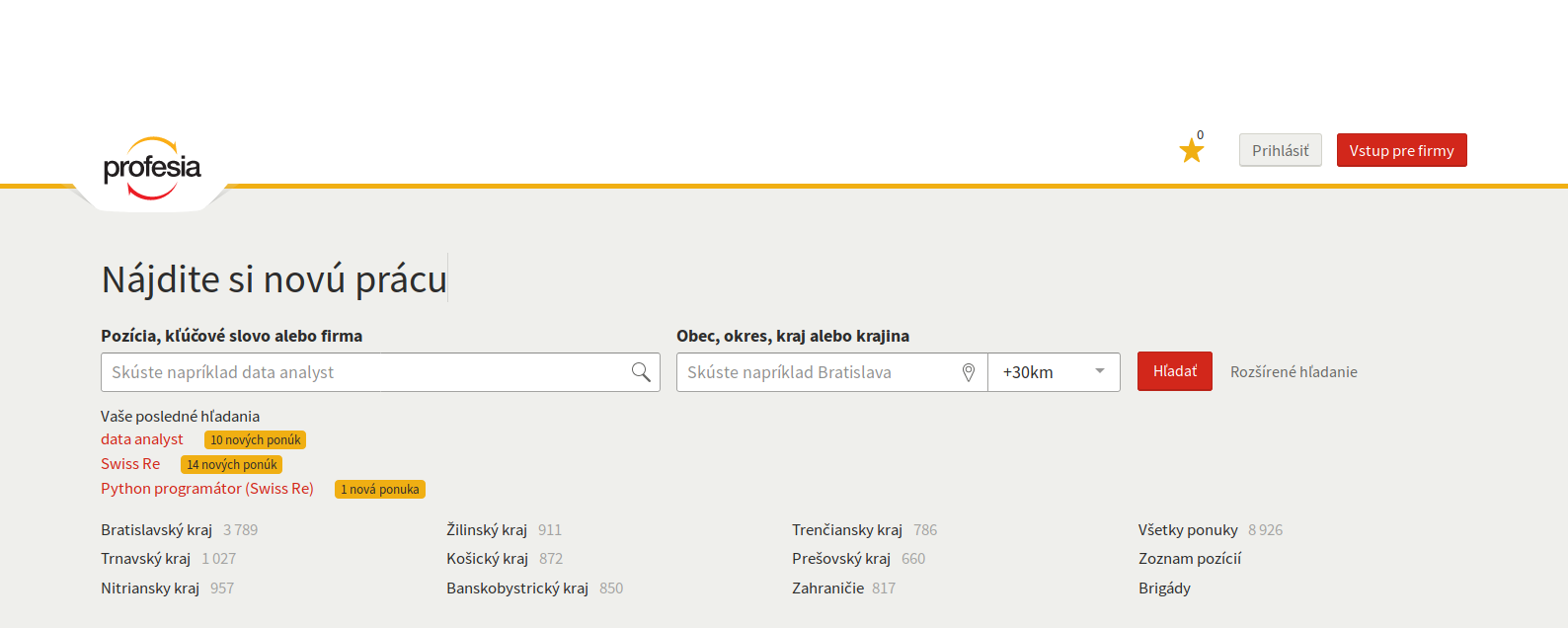
- Niečo hľadáte (kúpa)
- Neviete stiahnuť dáta v rozumnom formáte (bio)
- Niekto Vám nechce dať dáta z webu (štát)
- Potrebujete mailové kontakty (napr. online databáza škôl alebo zoznam DSS)
- Chcete byť informovaný o novinkách/zmenách (aktuality.sk)
- Chcete vyhrať súťaž, pri ktorej máte nájsť "skrytý" obrázok.