*
*
*
*

BeamerSoundKalibrierungsMultiMediaTest

IBM

Agenda
Challenge Approach
Challenge Solution
Demo
Transcription
Reflection
Business Challenge
IBM
IBM
Business Challenge
IBM
Business Challenge

Lack of understanding of customer needs and their pain points
IBM
Business Challenge
Large amount of unused data

IBM
Business Challenge
High manual effort after customer calls to process their claims

IBM
Business Challenge
IBM
Business Challenge
The challenges PostFinance faces in the callcenter are:
- Lack of understanding of customer needs and their pain points
- High manual effort after customer calls to process their claims
- Large amount of unusued data (previously recorded customer calls)
Our solution was built to address these challenges with an additional focus on the transcription of the previously recorded customer calls.
IBM
Challenge Approach
IBM
Challenge Approach
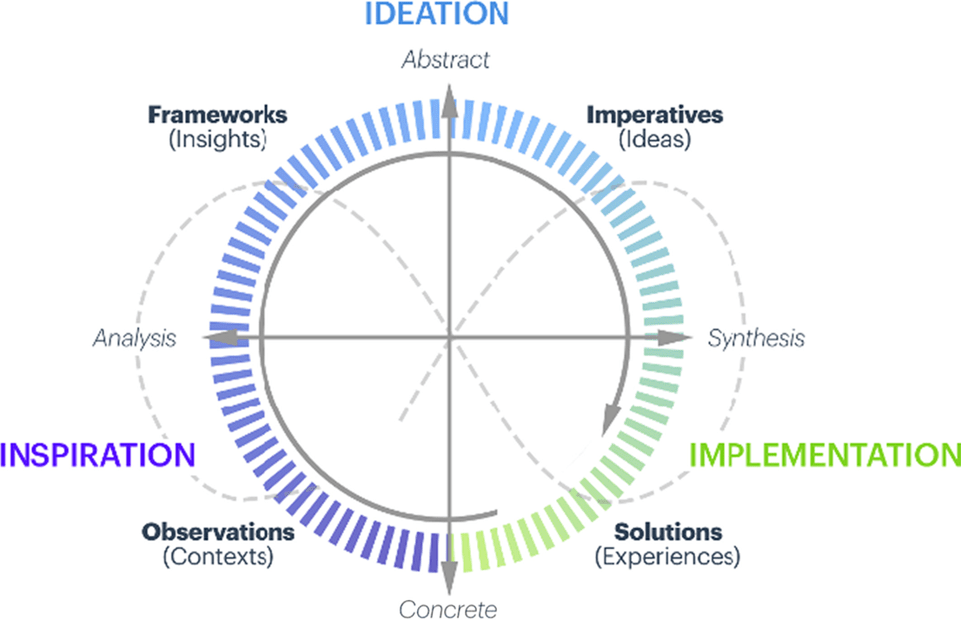
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
Informal Conversations
IBM
Challenge Approach
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
Personas
IBM
Challenge Approach
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
Value benefit analysis
IBM
Challenge Approach
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
LLM capability analysis
IBM
Challenge Approach
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
PoC implementation
IBM
Challenge Approach
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
PoC evaluation
IBM
Challenge Approach
Abstract
Concrete
Analysis
Synthesis
Inspiration
Ideation
Implementation
MVP creation
IBM
Challenge Approach
- Informal Conversation
- Personas
- Value benefit analysis
- LLM capability analysis
- PoC implementation
- PoC evaluation
- MVP creation
IBM
Challenge Approach
- Design Thinking
- Personas
- Technical Solutions evaluation
- PoC & Feedback
- MVP development
- Evaluation
Process:
- IS-Research model adapted to the PostFinance case
- Main focus on Design Thinking
IBM
IS-Research
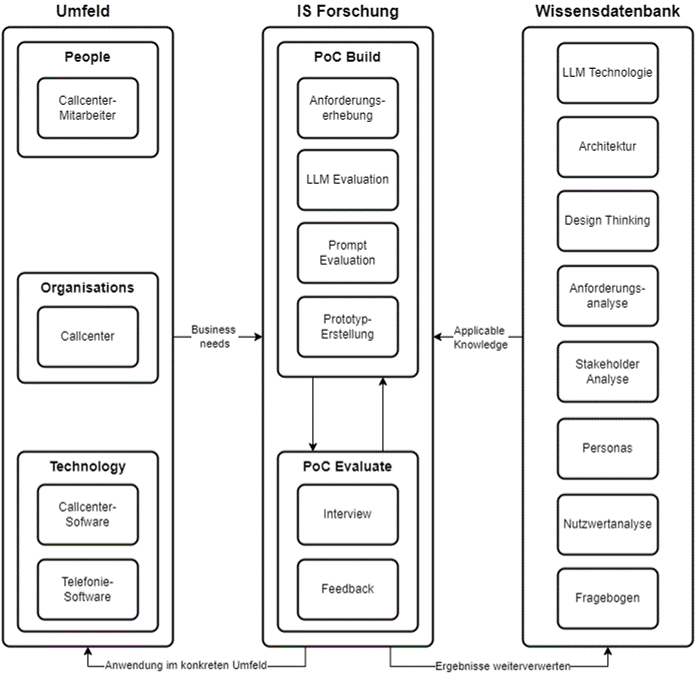
Design Science in Information Systems Research - Hevner et al. (2004, S. 80)
IBM
Method - Design Thinking
Design Thinking - (Bender-Salazar, 2023, S.9)
Challenge Solution
IBM
Challenge Solution
IBM

Challenge Solution
IBM

Challenge Solution
IBM
Challenge Solution
IBM
Topic: What?
Intents: Why?
Process Mining: How?
Named Entities: Who?
Challenge Solution
IBM
Solution

IBM
Architecture
IBM





Speech2Text
Data Store
Architecture
IBM
LLM
RAG
Data Store
Process Discovery
Demo - Understand
IBM

Demo - Generate
IBM
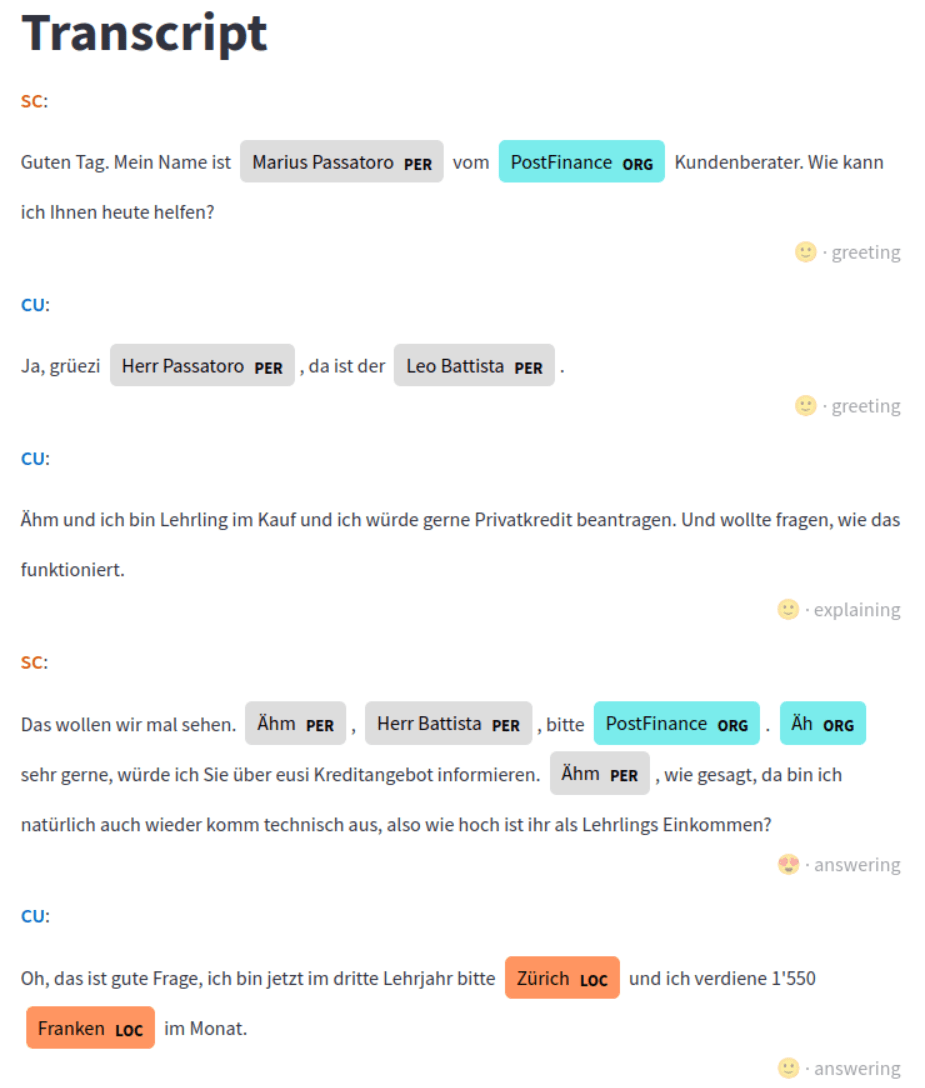
Demo - Transcription
IBM
Demo - Transcription
IBM
Demo - Analysis
IBM
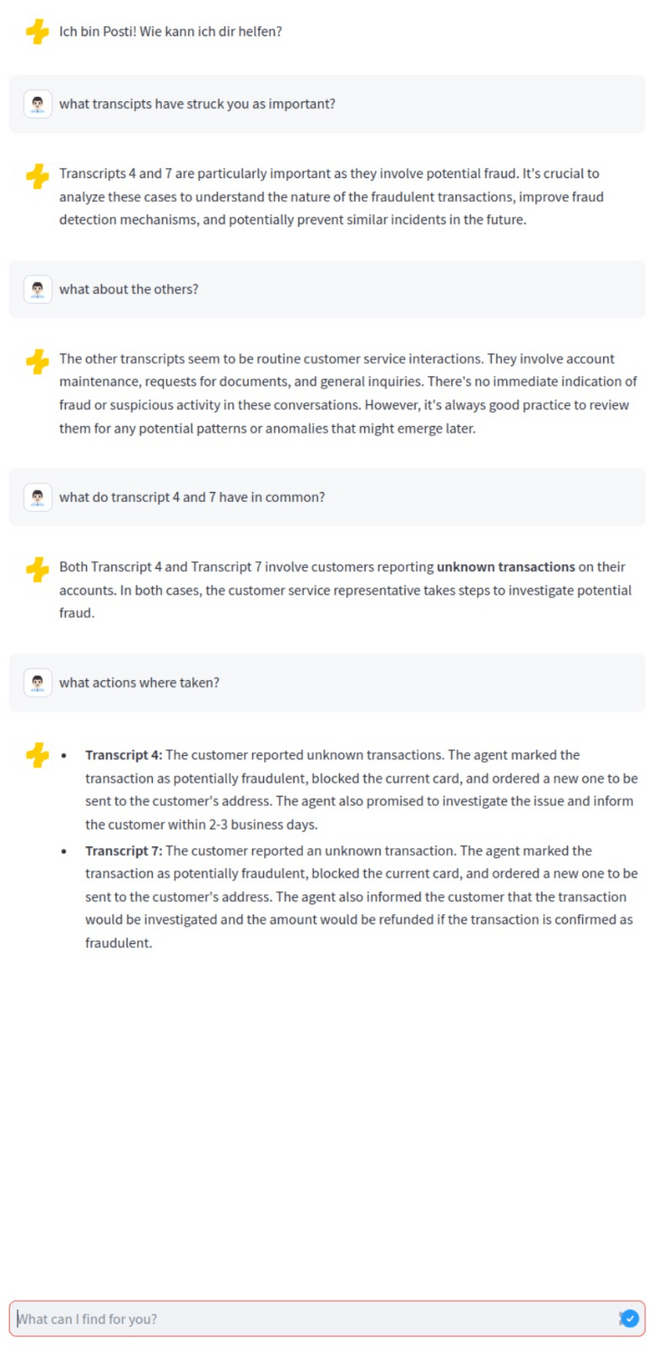
Demo - Chat
IBM
Demo - Chat / RAG
IBM
Demo - Chat / RAG
IBM
IBM
Transcription
Transcription
IBM
Audio / Transcript / Insights
Dedicated steps
more predictable
fine tuning
Audio / Transcript + Insights
Multi modality
extract sentiment from audio
single step pipeline
Evaluation of LLMs & Speech2Text Models
IBM
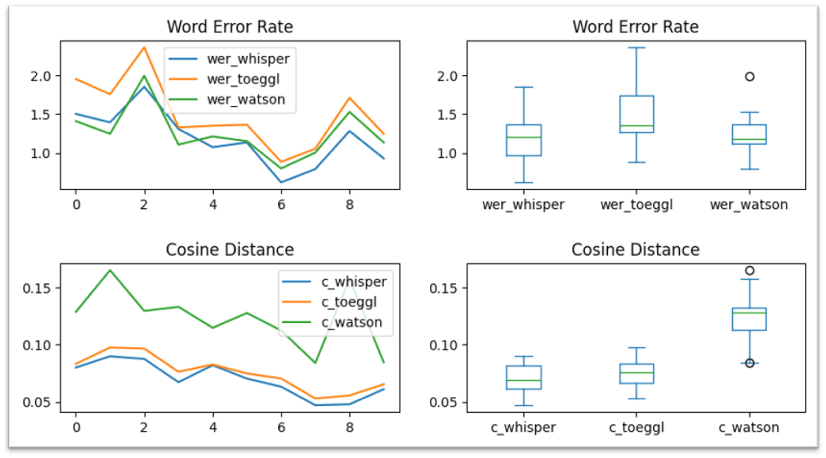
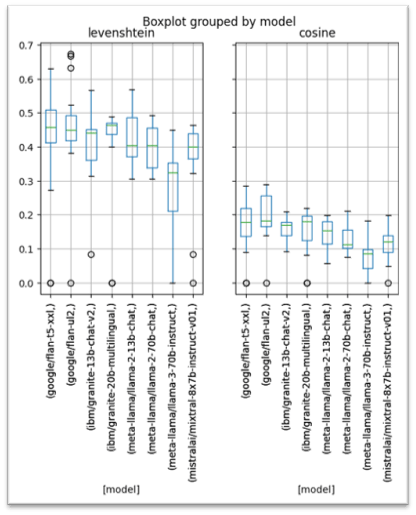
IBM
import streamlit as st
from config import MODEL_STRING
from langchain_google_vertexai import VertexAI
from langchain_core.messages import HumanMessage
from vertexai.generative_models import GenerativeModel, Part
import vertexai.preview.generative_models as generative_models
import base64
import json
import os
import time
def invoke(audio):
llm = GenerativeModel(MODEL_STRING)
text = """Summarize the conversation in maximun 1 sentence.
Then diarize this conversation in German. Mark the service center agent with SC and the customer with CU. Keep all successive sentences of the same speaker in the same string if sentiments does not change.
Possible products are: E-Finance, Privatkonto, Sparkonto, Yuh, Twint, Kreditkarte
Use the format: {"summary": "SUMMARY", "tags": [TAG1, TAG2], "products": [PRODUCT1, PRODUCT2], "wordcloud":[W1, W2, W3], "diarization": ["(SC|CU) (SENTIMENT) (greeting|answering|complaining|acknowledging|explaining|concluding|closing|requesting|other) (TIME): TEXT"]}
Sample output: {"summary": "The customer has questions about fees and interests on his account", "tags": ["fees", "taxes"], "products": ["e-finance", "savings account", "account"], "wordcloud":["Address Change", "Paper Documents"], "diarization": ["(CU) (neutral) (requesting) (2:10): "How can I change my address? I tried to do it in the e-banking without any luck! Can you help mi with that?", "(SC) (friendly) (answering) (2:43): "You can change the address in the my-profiles page. Do you have all the logins with you at the moment?"]}
"""
file = Part.from_data(mime_type="audio/mpeg", data=audio)
return llm.generate_content(
[text, file],
generation_config={
"max_output_tokens": 8192,
"temperature": 1,
"top_p": 0.95,
},
safety_settings={
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
}
)
st.markdown("# Upload an audio file\n Keep in mind that hate speach or sexual content can not be processes")
uploaded_file = st.file_uploader("Upload an .mp3 for transcription", type=["mp3"])
if uploaded_file is not None:
audio = uploaded_file.getvalue()
filename = uploaded_file.name.strip().replace(" ", "_").replace("-", "_")
result = invoke(audio)
content = json.loads(result.text.strip().rstrip("."))
content["filename"] = filename
ts = time.strftime("%Y%m%d-%H%M%S")
with open(os.path.join("uploads", f"{ts}.json"), "w") as file:
file.write(json.dumps(content))
with open(os.path.join("uploads", f"{ts}.mp3"), "w") as file:
file.write(json.dumps(content))
st.markdown("# Raw Transcript Data from LLM \n")
st.write(content)Transcription
Understand
IBM
Placeholder:
- add some information about process miners
import streamlit as st
import re
import pandas
import pm4py
import datetime
import os
from wordcloud import WordCloud
from PIL import Image
import numpy as np
from data import get_transcripts
transcripts = get_transcripts()
def flatten(xss):
return [x for xs in xss for x in xs]
st.set_page_config(page_title="Analyse multiple calls", page_icon="open_book")
st.title("Process Analysis")
st.sidebar.title("Filter")
selected_tag1 = st.sidebar.selectbox(
"Select first tags",
flatten([transcript.tags for transcript in transcripts]),
index=None,
)
selected_tag2 = st.sidebar.selectbox(
"Select second tags",
[
t
for t in flatten(
[
transcript.tags
for transcript in transcripts
if selected_tag1 in transcript.tags
]
)
if t != selected_tag1
],
index=None,
)
selected_tags = [t for t in [selected_tag1, selected_tag2] if t]
selected_product = st.sidebar.selectbox(
"Select the product",
list(set(flatten([transcript.products for transcript in transcripts]))),
index=None,
)
selected_transcripts = [
transcript
for transcript in transcripts
if all([tag in transcript.tags for tag in selected_tags])
and (selected_product in transcript.products if selected_product else True)
]
if len(selected_transcripts):
words = flatten([transcript.wordcloud for transcript in selected_transcripts])
st.markdown("# Word cloud \n")
pf_mask = np.array(
Image.open(
os.path.join(
os.path.dirname(__file__) if "__file__" in locals() else os.getcwd(),
"pf.png",
)
)
)
wc = WordCloud(
background_color="white",
colormap="Oranges",
mask=pf_mask,
contour_color="#FFCC00",
contour_width=2,
).generate(" ".join(words))
st.image(wc.to_array())
start = datetime.datetime.now()
df = pandas.DataFrame()
for index, transcript in list(enumerate(selected_transcripts)):
df = pandas.concat(
[
df,
pandas.DataFrame(
[
{
"case_id": index,
"speaker": entry.speaker,
"activity": entry.activity,
"text": entry.text,
"timestamp": start
+ datetime.timedelta(minutes=int(entry.time.split(":")[0]))
+ datetime.timedelta(seconds=int(entry.time.split(":")[1])),
}
for id, entry in enumerate(transcript.diary)
]
),
]
)
log = pm4py.format_dataframe(
df, case_id="case_id", activity_key="activity", timestamp_key="timestamp"
)
map = pm4py.discover_heuristics_net(log)
ts = pm4py.convert_to_bpmn(map)
pm4py.save_vis_bpmn(ts, file_path="/tmp/model-net.svg", format="svg")
l, s, e = pm4py.discover_dfg(log)
pm4py.save_vis_dfg(
l, s, e, file_path="/tmp/model-tree.svg", format="svg", rankdir="LR"
)
st.markdown(
"# Statistics \n- "
+ "\n- ".join(
[
f"Selected tags: {', '.join(selected_tags)}",
f"Selected product: {selected_product}",
f"Count transcripts: {len(selected_transcripts)}",
]
)
)
st.markdown("# Models \n")
st.markdown(
"## DFG \n" + f"- Start: {','.join(s.keys())} \n- End: {', '.join(e.keys())}"
)
st.image("/tmp/model-tree.svg", caption="Directly-follows graph")
st.markdown("## BPMN Model \n")
st.image("/tmp/model-net.svg", caption="BPMN Model")
st.markdown("# Raw Data \n")
st.dataframe(log)
else:
st.markdown("No Transcripts found, sorry!")
Understand
IBM
IBM
Transcription
Audio / Transcript / Insights
Dedicated steps
more predictable
fine tuning
Audio / Transcript + Insights
Multi modality
extract sentiment from audio
single step pipeline
Reflection
IBM
Reflection
IBM
- Swiss German is a difficult language to understand for Speech-to-Text-Models with its many dialects and variants
- The advancements in the AI-field are from large-scale and very fast
- The usage of AI has huge potential in callcenters, it can optimize processes in an effective and efficient way
- Our PoC confirms the feasibility of the planned solution
- Different models and LLMs have significantly different performance results
Reflection
IBM
Feasibility
Usability
Improved Workflow
Conclusion & Next Steps
IBM
- PoC works and usuability was confirmed in our tests
- Concept could be integrated by PF
- Still some finetuning needed
Next Steps:
- Evaluation for newly available LLMs important as they can optimize the performance significantly
- RAG integration
- Testing
- Finetuning
- How to get it runing @postfinance
Next Steps
IBM
Try it out:
https://ibmpf.eigenmann.dev
- nFDPA / Compliance
- Evaluate with real data
- Finetune for swiss german
- Improve performance (and costs)
- Deploy and use
Call to Action
IBM
Let's meet up for a coffee to further discuss the implementation!








IBM
How to apply @PostFinance
How can we apply IBM's solutions at PF?
Check notes from Q&A from 21.05.24
Limitations
IBM
- Monetary resources have been to scarce for large testing in combination with time scarcity
- No real data from the customer calls available, because of data protection
- Only the LLMs which are integrated in WatsonX have been easily available to work with
Thank You!
Value Mapping
| Area | Value |
|---|---|
| Approach | Design Thinking: Interview / Persona / Value Benefit analysis / technical analysis / PoC & evaluation / MVP |
| Technical | Speech2Text / LLM / RAG / Process mining & discovery |
| Usability |
Customer needs: tags, summaries, discovery and tagging High effort: viable pipeline Unused data: scalability and RAG |
| Artifacts | Personas, MVP |
| Compliance | everything works on premise or @ IBM |
| Know-how |
Well known tech stack: Steamlit (Python), docker and jupiter notebooks. (Works in any container-engine/k8s-cluster) |
Literature
IBM
Bender-Salazar, R. (2023). Design thinking as an effective method for problem-setting and needfinding for entrepreneurial teams addressing wicked problems. Journal of Innovation and Entrepreneurship, 12(1), 24. https://doi.org/10.1186/s13731-023-00291-2 
Hevner, March, Park, & Ram. (2004). Design Science in Information Systems Research. MIS Quarterly, 28(1), 75. https://doi.org/10.2307/25148625
Appendix
IBM