¿Qué es un dato?
Clase: BASE DE DATOS 1
Datos proviene del latín “Dtum” cuyo significado es “lo que se da”.
Un dato es la representación de una variable que puede ser cuantitativa o cualitativa, indican un valor que se le asigna a las cosas. Los datos son información.
Los datos
Un dato por sí solo no puede demostrar demasiado, siempre se evalúa el conjunto para poder examinar los resultados. Para examinarlos, primero hay que organizarlos o tabularlos.

Los datos pueden ser generados de forma automática y acumulativa con diferentes tipos de software o bien tienen que ser siempre ingresados para formar una base de datos.

Los datos que se ingresan en una base pueden ser de diversos tipos, según la información que se acumule en dicha base.
Por ejemplo puede ser una base de datos de información personal, entonces los datos serán numéricos, alfabéticos y alfa-numéricos.
En informática, en programación, un dato es la expresión general que va a describir aquellas características de la entidad sobre la que opera. En la estructura de datos, un dato es la más mínima parte de la información.
Como ya dijimos, hay dos tipos de datos:
-
Cualitativos: Son aquellos que responden a la pregunta ¿cuál? O ¿cuáles? Aquí hay datos como el color, los sentimientos, etcétera.
-
Cuantitativos: Son aquellos datos que siempre están referidos a los números. Por ejemplo precio, altura, edad, etcétera.
Dentro de los archivos también encontramos datos. Estos datos consisten generalmente en paquetes más pequeños de otros datos, que son llamados registros. Estos datos están reunidos por características iguales o similares.
Dato
¿Qué es un dato en informática?
Algunos tipos de datos son:
- Caracteres. Dígitos individuales que se pueden representar mediante datos numéricos (0-9), letras (a-z) u otros símbolos.
- Caracteres unicode. Unicode es un estándar de codificación que permite representar más eficazmente los datos, permitiendo así hasta 65535 caracteres diferentes.
- Numéricos. Pueden ser números reales o enteros, dependiendo de lo necesario.
- Booleanos. Representan valores lógicos.
Bases de datos
Definición
Una base de datos se entenderá como una colección de datos relacionados entre sí y que tienen un significado implícito.
Ejemplo
Una agenda con los nombres y teléfonos de un conjunto de personas conocidas es una base de datos, puesto que es una colección de datos relacionados con un significado implícito.
La definición anterior hace referencia a dos elementos para que un conjunto de datos constituya una Base de Datos:
-
Relaciones entre datos, tema que se tratará en las secciones siguientes.
-
Significado implícito de los datos que se atribuye dependiendo del contexto en que se utilizan los mismos. Por ejemplo, el dato fecha en una base de datos de VENTAS puede referirse a la fecha de emisión de las facturas, mientras que si la base de datos es de MÚSICA quizás corresponda a la fecha en que se grabó un tema musical. Es decir, el significado de un dato, depende de la BD que lo contenga.
Modelos de bases de datos
Existen diferentes maneras de ordenar y organizar la información para que este sea accesible para nosotros.
No existe el sistema de base de datos perfecto: hay que elegir aquella estructura que mejor se adapte a nuestras necesidades. Los siguientes son los tipos más comunes:
Modelos de BD
- Bases de datos jerárquicas.
- Bases de datos en red.
- Bases de datos transaccionales.
- Bases de datos relacionales.
- Bases de datos orientadas a objetos.
- Bases de datos documentales.
- Bases de datos NoSQL
código de clase:
djcqcoc
¿Qué es mejor?

Es muy común entre desarrolladores de aplicaciones encontrarse en una situación de tener que elegir si se va a usar una base de datos relacional o no relacional.
La mayoría no se lo piensa demasiado y opta por la opción que más conocen y con la que más cómodos trabajan. Tampoco es una decisión catastrófica; en realidad, ya sea la base de datos relacional o no, se puede construir cualquier cosa.
Un poco de historia
Las bases de datos relacionales o de lenguaje de consulta SQL se empezaron a usar en los años 80 y a día de hoy siguen siendo la opción más popular.
En cambio, las bases de datos no relacionales o de lenguaje de consulta NoSQL solo están empezando a ser más populares en los últimos años.
Bases de datos relacionales
El principio de las bases de datos relacionales se basa en la organización de la información en trozos pequeños, que se relacionan entre ellos mediante la relación de identificadores.
En el ámbito informático se habla mucho de ACID, cuyas siglas vienen de las palabras en inglés: atomicidad, consistencia, aislamiento y durabilidad. Son propiedades que las bases de datos relacionales aportan a los sistemas y les permiten ser más robustos y menos vulnerables ante fallos.
Bases de datos no relacionales
Como su propio nombre indica, las bases de datos no relacionales son las que, a diferencia de las relacionales, no tienen un identificador que sirva de relación entre un conjunto de datos y otros. Como veremos, la información se organiza normalmente mediante documentos y es muy útil cuando no tenemos un esquema exacto de lo que se va a almacenar.

Formatos
La información puede organizarse en tablas o en documentos.
Ejemplo:
Cuando organizamos información en un Excel, lo hacemos en formato tabla y, cuando los médicos hacen fichas a sus pacientes, están guardando la información en documentos.
Lo habitual es que las bases de datos basadas en tablas sean bases de datos relacionales y las basadas en documentos sean no relacionales
Pero esto no tiene que ser siempre así...
En realidad, una tabla puede transformarse en documentos, cada uno formado por cada fila de la tabla. Solo es una cuestión de visualización.
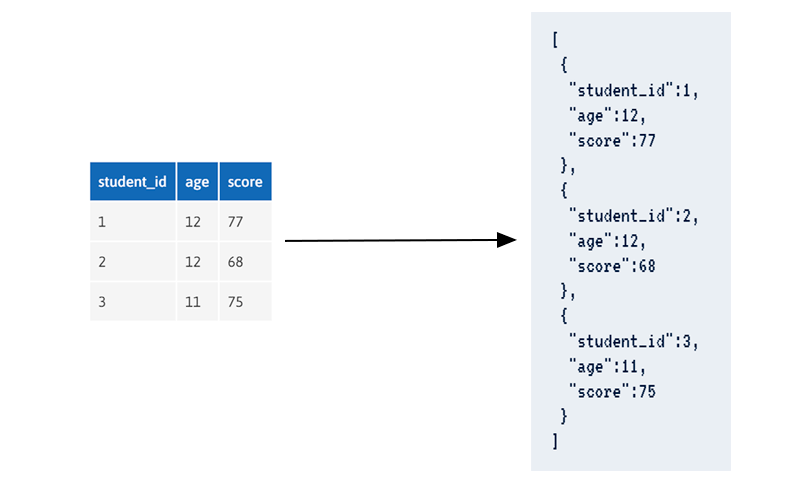
Los dos esquemas de la imagen contienen exactamente la misma información. Lo único que cambia aquí es el formato: cada documento de la figura de la derecha es una fila de la figura de la izquierda.
Se ve más claro en la tabla, ¿verdad?
Lo que pasa es que a menudo en una base de datos no relacional una unidad de datos puede llegar a ser demasiado compleja como para plasmarlo en una tabla.
Por ejemplo, en el documento JSON
Al tener elementos jerárquicos, es más difícil plasmarlo en una tabla plana. Una solución sería plasmarlo en varias tablas y, por tanto, necesitar de relaciones.
[
{
"student_id":1,
"age":12,
"subjects":{
"mathematics":{
"scores":[7,8,7,10],
"final_score":8
},
"biology":{
"scores":[6,6,5,7],
"final_score":6
}
}
}
]Esto explica por qué las bases de datos relacionales suelen servirse de tablas y las no relacionales de documentos JSON.
En cualquier caso, a día de hoy, las bases de datos más competitivas suelen permitir, de una forma u otra, operaciones de los dos tipos.
La diferencia entre el éxito y el fracaso recae, sobre todo, en el diseño del modelo.
¿Un poco perdidos? ¡Pasemos a la acción!
Ejemplo práctico: base de datos relacional
Imaginemos que tenemos una plataforma online que ofrece cursos de idiomas. Los clientes contratan o se suscriben al idioma y al nivel que más les puede interesar, y, además, tienen la opción de elegir qué tipo de suscripción quieren: mensual, trimestral o anual. Y dependiendo de esta opción, se les aplicará un descuento u otro
El primer diseño de base de datos que propongo es una tabla donde cada fila corresponde con un servicio contratado por un cliente. Toda la información está contenida en una sola tabla, por tanto, no es relacional.
| fecha | cliente | idioma | nivel | suscripción | precio | descuento | preciofinal |
|---|
| 25/06/2018 | Pedro | Inglés | Intermedio | Mensual | 7 | 0 | 7 |
|---|---|---|---|---|---|---|---|
| 25/06/2018 | Pedro | Chino | Principiante | Mensual | 9 | 0 | 9 |
| 01/07/2018 | Aurelia | Francés | Avanzado | Anual | 8 | 25 | 6 |
| 03/07/2018 | Federico | Inglés | Intermedio | Trimestral | 7 | 10 | 6.3 |
Problemas que podemos encontrar con este modelo
-
No sabemos si el Pedro de la primera fila es el mismo cliente que el Pedro de la segunda fila o si son dos clientes con el mismo nombre. Sí, podríamos incluir el e-mail para que haga de identificador único, pero es una solución cogida con pinzas.
-
Si algún precio o descuento cambia, hay que modificarlo en todas las filas en las que aparece y, si no se hace correctamente, puede dar lugar a discrepancias. No tiene sentido que la información esté duplicada de esta manera.
| fecha | cliente | idioma | nivel | suscripción | precio | descuento | preciofinal |
|---|
| 25/06/2018 | Pedro | Inglés | Intermedio | Mensual | 7 | 0 | 7 |
|---|---|---|---|---|---|---|---|
| 25/06/2018 | Pedro | Chino | Principiante | Mensual | 9 | 0 | 9 |
| 01/07/2018 | Aurelia | Francés | Avanzado | Anual | 8 | 25 | 6 |
| 03/07/2018 | Federico | Inglés | Intermedio | Trimestral | 7 | 10 | 6.3 |
Problemas que podemos encontrar con este modelo
- Si un cliente cambia su suscripción, habría que cambiar tanto el campo de suscripción como el precio. Y también puede dar lugar a discrepancias si no se hace correctamente.
- Al tener la columna de “precio final” se está duplicando información, ya que se puede calcular fácilmente con las columnas “precio” y “descuento_%”. Esto también puede dar lugar a discrepancias.
- Al tener la columna de “precio final” se está duplicando información, ya que se puede calcular fácilmente con las columnas “precio” y “descuento_%”. Esto también puede dar lugar a discrepancias
¿Cómo solucionamos todos estos problemas?
Está pidiendo a gritos un diseño de base de datos relacional, donde se recoja la información en varias tablas y no solo en una.
Empezamos con la primera tabla; esta contendrá solamente la información del cliente.
| cliente_id | nombre_cliente |
|---|---|
| 1 | Pedro |
| 2 | Aurelia |
| 3 | Federico |
Por otro lado tenemos la tabla contenedora de las clases disponibles. Cada una con su nivel y precio base.
| programa_id | idioma | nivel | precio |
|---|---|---|---|
| 1 | alemán | principiante | 7 |
| 2 | chino | principiante | 9 |
| 3 | francés | avanzado | 8 |
| 4 |
En esta tabla podemos ver todos los cursos disponibles. En el diseño principal, como nadie se había suscrito al curso de alemán, ni siquiera podíamos saber que existía.
A este precio base luego se descontará un porcentaje, según la suscripción que los clientes elijan.
| suscripcion_id | tipo | descuento_% |
|---|---|---|
| 1 | Mensual | 0 |
| 2 | Trimestral | 10 |
| 3 | Anual | 25 |
Y por último, tenemos la tabla que relaciona todo: a cada cliente con la clase o clases contratadas y el tipo de suscripción.
| id | cliente_id | programa_id | suscripcion_id |
|---|---|---|---|
| 1 | 1 | 4 | 1 |
| 2 | 1 | 2 | 1 |
| 3 | 2 | 3 | 3 |
| 4 | 3 | 4 | 2 |
Pedro, que es el cliente con identificador 1, se había suscrito mensualmente (id=1) a inglés intermedio (id=4) y chino principiante (id=2). Por eso, en las dos filas en las que el identificador de cliente “client_id” es 1, el identificador de programa es 4 y 2, y el identificador de suscripción es un 1.
*No hemos apuntado el precio final en ningún lado.
No es necesario, ya que, conociendo el precio del programa y el descuento de la suscripción elegida, se puede calcular de inmediato. Y así evitaremos duplicidad y la posibilidad de discrepancias en nuestros datos.
Ejercicio
¿Cómo harían para incluir la posibilidad de tener cupones de descuento? Pensando que estos cupones son canjeables por cada curso que se contrata y cada uno puede proporcionar un descuento diferente.
| cliente_id | nombre_cliente |
|---|---|
| 1 | Pedro |
| 2 | Aurelia |
| 3 | Federico |
| programa_id | idioma | nivel | precio |
|---|---|---|---|
| 1 | alemán | principiante | 7 |
| 2 | chino | principiante | 9 |
| 3 | francés | avanzado | 8 |
| 4 |
| suscripcion_id | tipo |
|---|---|
| 1 | Mensual |
| 2 | Trimestral |
| 3 | Anual |
| id | cliente_id | programa_id | suscripcion_id | cupon_id |
|---|---|---|---|---|
| 1 | 1 | 4 | 1 | |
| 2 | 1 | 2 | 1 | 1 |
| 3 | 2 | 3 | 3 | 2 |
| 4 | 3 | 4 | 2 | 3 |
| cupon_id | codigo | descuento_% |
|---|---|---|
| 1 | desc10 | 10 |
| 2 | desc20 | 20 |
| 3 | desc30 | 30 |
Modelo entidad-relación
El modelo de datos entidad-relación está basado en una percepción del mundo real que consta de una colección de objetos básicos, llamados entidades, y de relaciones entre esos objetos amorfos.
Entidad.
- Una persona. (Se diferencia de cualquier otra persona, incluso siendo gemelos).
- Un automóvil. (Aunque sean de la misma marca, el mismo modelo,..., tendrán atributos diferentes, por ejemplo, el número de chasis).
- Una casa (Aunque sea exactamente igual a otra, aún se diferenciará en su dirección).
Representa una “cosa”, "objeto" o "concepto" del mundo real con existencia independiente, es decir, se diferencia únicamente de otro objeto o cosa, incluso siendo del mismo tipo, o una misma entidad.
Entonces...
Una entidad puede ser un objeto con existencia física como: una persona, un animal, una casa, etc. (entidad concreta); o un objeto con existencia conceptual como: un puesto de trabajo, una asignatura de clases, un nombre, etc. (entidad abstracta).
Una entidad está descrita y se representa por sus características o atributos. Por ejemplo, la entidad Persona tiene como características: Nombre, Apellido, Género, Estatura, Peso, Fecha de nacimiento.
Atributos.
Los atributos son las características que definen o identifican a una entidad. Estas pueden ser muchas, y el diseñador solo utiliza o implementa las que considere más relevantes.
En un conjunto de entidades del mismo tipo, cada entidad tiene valores específicos asignados para cada uno de sus atributos, de esta forma, es posible su identificación unívoca.
Ejemplo
- (1, Sophia, 15 años, 2)
- (2, Josefa, 19 años, 5)
- (3, Carlos, 20 años, 2)
A la colección de entidades «alumnos», con el siguiente conjunto de atributos en común, (id, nombre, edad, semestre), pertenecen las entidades:
Cada una de las entidades pertenecientes a este conjunto se diferencia de las demás por el valor de sus atributos. Nótese que dos o más entidades diferentes pueden tener los mismos valores para algunos de sus atributos, pero nunca para todos.
Cada una de las entidades pertenecientes a este conjunto se diferencia de las demás por el valor de sus atributos. Nótese que dos o más entidades diferentes pueden tener los mismos valores para algunos de sus atributos, pero nunca para todos.
- (1, Sophia, 15 años, 2)
- (2, Josefa, 19 años, 5)
- (3, Carlos, 20 años, 2)
En particular, los atributos identificativos son aquellos que permiten diferenciar a una instancia de la entidad de otra distinta. Por ejemplo, el atributo identificativo que distingue a un alumno de otro es su número de id.
Atributos
Para cada atributo, existe un dominio del mismo, este hace referencia al tipo de datos que será almacenado a restricciones en los valores que el atributo puede tomar (cadenas de caracteres, números, solo dos letras, solo números mayores que cero, solo números enteros...).
Cuando algún atributo correspondiente a una entidad no tiene un valor determinado, recibe el valor nulo, bien sea porque no se conoce, porque no existe o porque no se sabe nada al respecto del mismo.
Conjunto de relaciones
Consiste en una colección, o conjunto, de relaciones de la misma naturaleza.
Ejemplo:
Dados los conjuntos de entidades "Habitación" y "Huésped", todas las relaciones de la forma habitación-huésped, permiten obtener la información de los huéspedes y sus respectivas habitaciones.
La dependencia o asociación entre los conjuntos de entidades es llamada participación. En el ejemplo anterior los conjuntos de entidades "Habitación" y "Huésped" participan en el conjunto de relaciones habitación-huésped.
Si tenemos dos entidades, CLIENTE y HABITACIÓN, podemos entender la relación entre ambas al tomar un caso concreto (ocurrencia) de cada una de ellas.
Entonces, podríamos tener la ocurrencia Habitación 502, de la entidad HABITACIÓN y la ocurrencia Benito Mussolini de la entidad CLIENTE, entre las que es posible relacionar que la habitación 502 se encuentra ocupada por el huésped de nombre Benito Mussolini.
Vamos explicándolo...
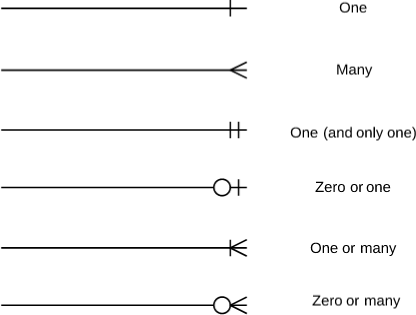
Cardinalidad.
Se refiere al número máximo de veces que una instancia en una entidad se puede relacionar con instancias de otra entidad
Una entidad en A esta asociada con cualquier número de entidades en B (0 ó más) y viceversa
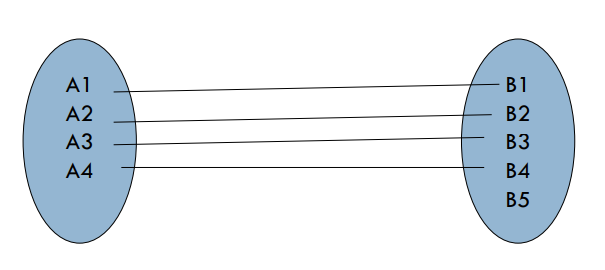
Ejemplos uno a uno
Un paciente en un hospital tiene un solo cuarto y un cuarto pertenece a un solo paciente (hospital privado)
Una entidad en A esta asociada con cualquier número (0 ó más) de entidades en B. Una entidad en B, puede estar asociada a lo mucho con una entidad en A
Ejemplos uno a muchos
El titular de una cuenta de cheques puede tener cualquier número de tarjetas, pero cada tarjeta pertenece a una sola persona
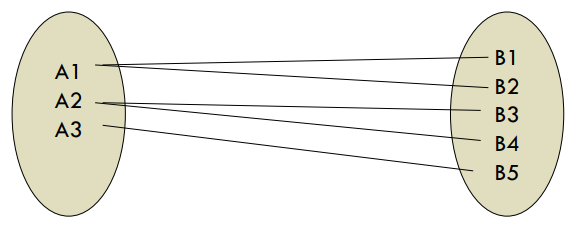
Una entidad en A esta asociada con cualquier número de entidades en B (0 ó más) y viceversa.
Muchos a muchos
En un proyecto de investigación puede haber cualquier número de médicos, un médico puede participar en cero o varios proyectos
Cardinalidad: obligatoria y opcional
Uno a uno obligatorio: un empleado en Una empresa tiene uno y solo un puesto, un Puesto pertenece a un solo empleado
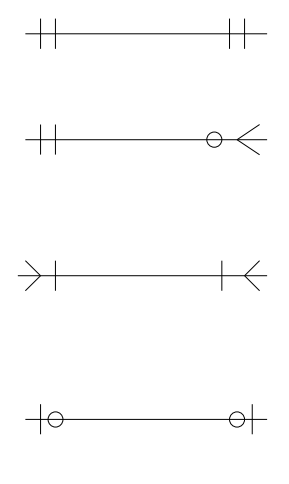
Uno a muchos opcional: un profesor en la Fac. de Ingeniería puede dar 0 o varias clases y una clase está dada por uno y solo un profesor
Muchos a muchos obligatorio: una materia puede pertenecer a una o varias carreras, una carrera está formada por varias materias.
Uno a uno opcional: Un paciente puede estar asignado a un cuarto o a ninguno. En un cuarto puede haber cero o un paciente
Llaves Primarias.
Llaves Foraneas.
Llave Primaria
La clave primaria es el campo, o conjunto de campos, que nos permite identificar de forma única un registro
Llave Foranea
La clave foránea es un campo, o conjunto de campos, que nos permite relacionar un registro de una tabla con otro, generalmente de una tabla distinta
Relevancia
La razón más importante para tener claves primarias y foráneas es la identificación de registros únicos en cada tabla de la base de datos. Las claves primarias también están indexadas en la base de datos, lo que permite que la obtención de un registro solicitado sea más rápida para el servidor de bases de datos. Una clave primaria también puede tener varias claves foráneas establecidas. Por ejemplo, una clave primaria en una tabla de clientes podría tener una clave foránea en las tablas de órdenes y pagos.
Repitamos...
- Cada entidad tiene una llave primaria o campo clave que identifica unívocamente al conjunto de datos.
- Cuando en una entidad figura la clave primaria de otra entidad, ésta se denomina clave foránea.
Ejemplo
| Cleintes |
|---|
| idCliente |
| Nombre |
| Apellido |
| Domicilio |
| Telefono |
| Facturas |
|---|
| idFactura |
| Fecha_emision |
| idCliente |
| idProducto |
| Monto |
| Total |
| Productos |
|---|
| idProducto |
| Descripcion |
| Precio |
| Stock |
Gestores de BD
Motores de BD
- MySQL
- MariaDB
- MongoDB
- SQL Server
Investigar Ventajas y Desventajas.
Tipos de datos que manejan
Que empresas/aplicaciones/startups las utilizan.
Lenguaje SQL
Comandos básicos
Definiendo cómo es almacenada la información.
- CREATE DATABASE se utiliza para crear una nueva base de datos vacía.
- DROP DATABASE se utiliza para eliminar completamente una base de datos existente.
- CREATE TABLE se utiliza para crear una nueva tabla, donde la información se almacena realmente.
- ALTER TABLE se utiliza para modificar una tabla ya existente.
- DROP TABLE se utiliza para eliminar por completo una tabla existente.
Manipulando los datos.
- SELECT se utiliza cuando quieres leer (o seleccionar) tus datos.
- INSERT se utiliza cuando quieres añadir (o insertar) nuevos datos.
- UPDATE se utiliza cuando quieres cambiar (o actualizar) datos existentes.
- DELETE se utiliza cuando quieres eliminar (o borrar) datos existentes.
- REPLACE se utiliza cuando quieres añadir o cambiar (o reemplazar) datos nuevos o ya existentes.
- TRUNCATE se utiliza cuando quieres vaciar (o borrar) todos los datos de la plantilla.