What is the point
Current NLP landscape:
- more or less 1 architecture (Transformer)
- N models pre-trained
- Fine tune a pre-trained model without extending it, the transformer architecture adjusts its inner representation of language to your task
Recent trend: inject features in the input text and fine tune with
What is the point
Essentially, they want to show that given a large enough model, trained on a large and diverse dataset, you can fine tune for any task with "in context" information
NLP landscape with this paradigm:
- more or less 1 architecture (Transformer)
- 1 model trained
- In the input text used for prediction, inject examples from the desired task + a task specific prompt (so that the model either recognise a task already encountered or process the prompt to solve the task on the fly)
- No additional training needed

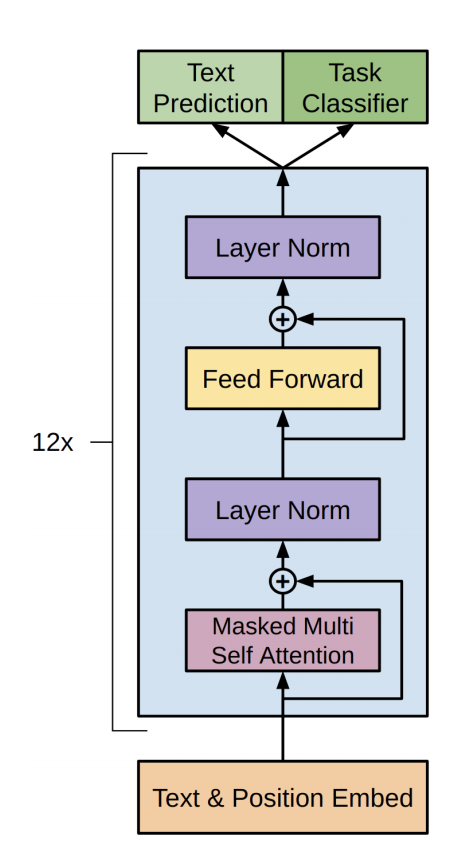
Architecture
Same architecture as GPT and GPT-2, vanilla Transformer with small upgrades accumulated over time.
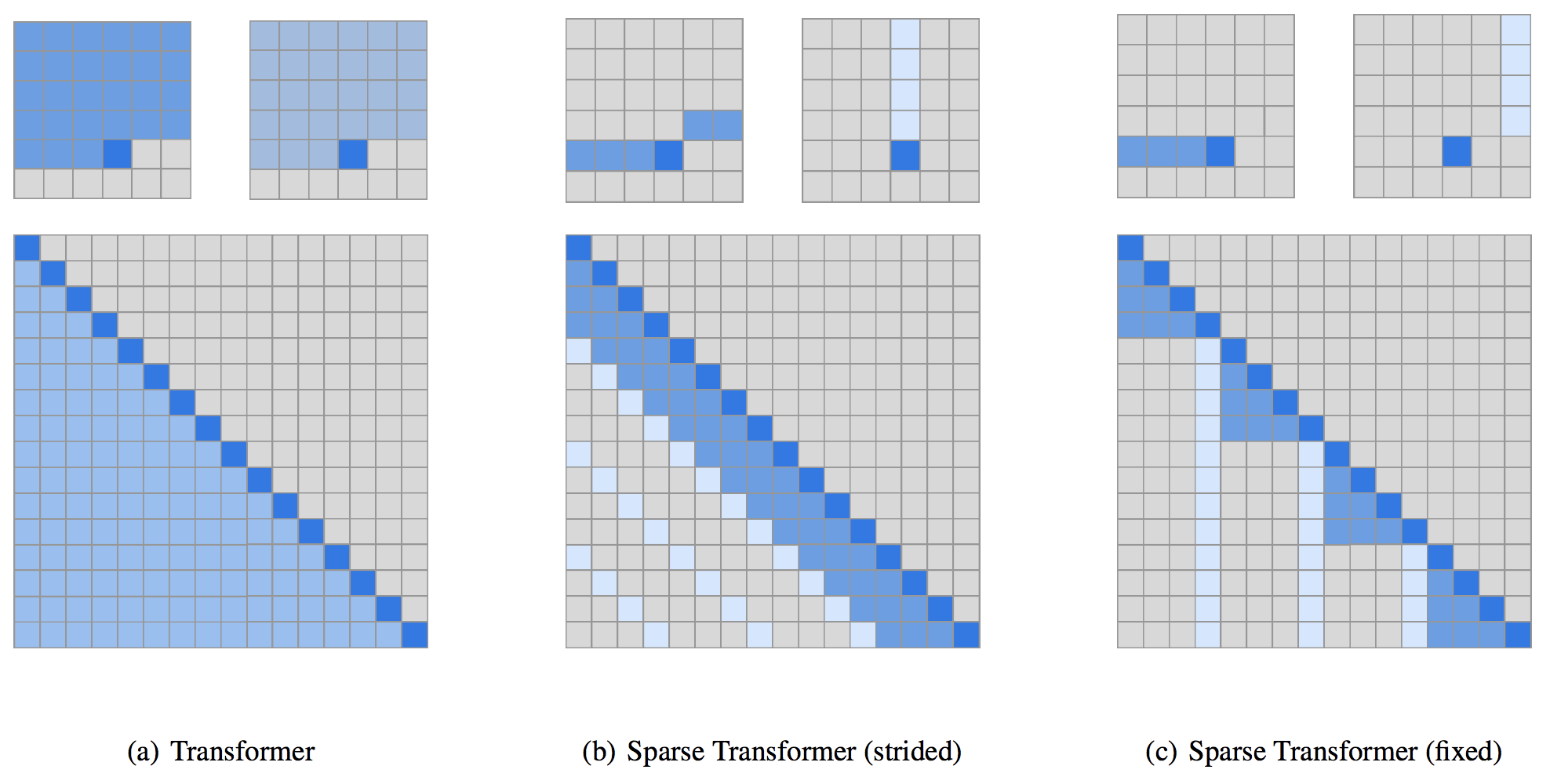
A notable upgrade from GPT-2 to GPT-3 is from Generating Long Sequences with Sparse Transformers where they factorise attention matrices to down the complexity from to
Basically the attention attends to less input, in patterns that minimises the information loss, so that the computation is faster (so for the same amount of computation time you can attend to more token).
Architecture
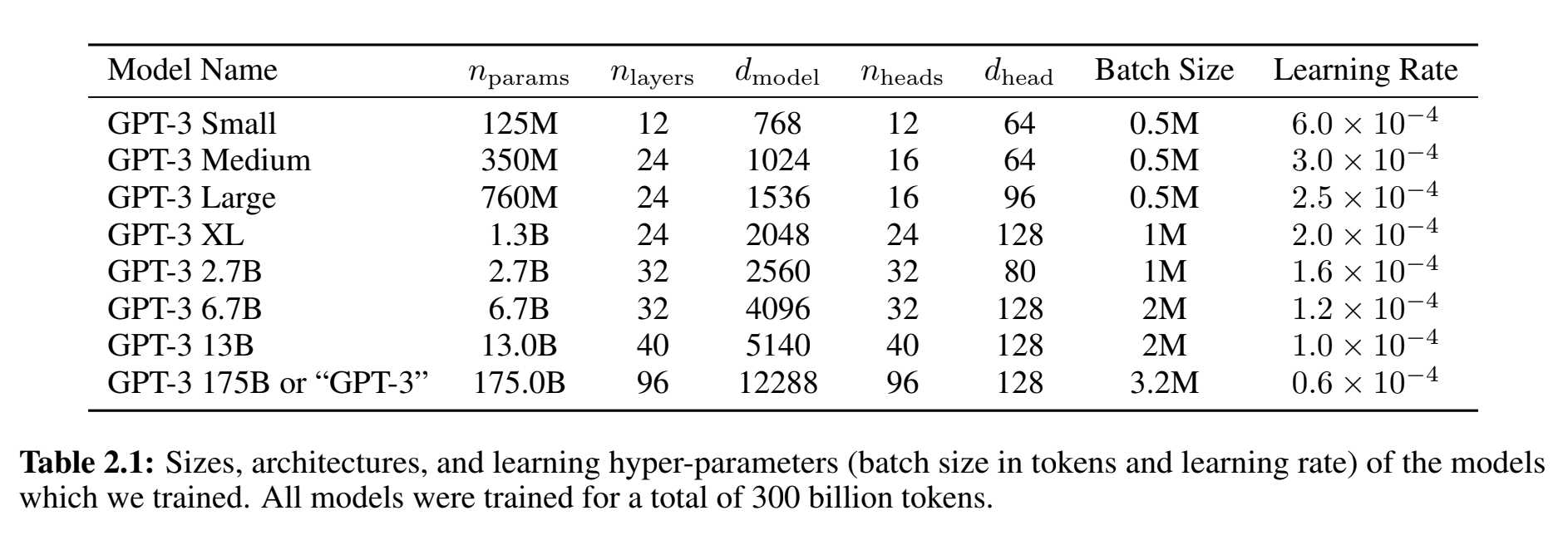
GPT-3 models info
??
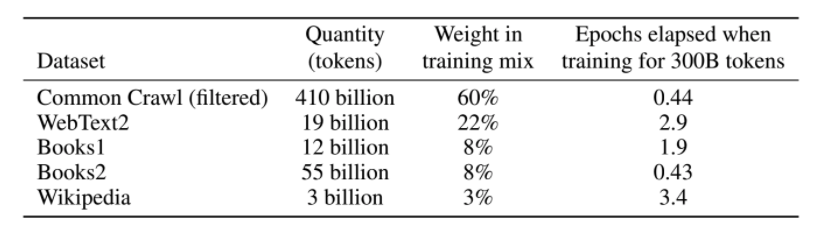
Data
Base: Common Crawl
+ quality filter (based on similarity metric with reference corpora)
+ deduplication (across datasets and within documents)
+ append other reference datasets
570GB
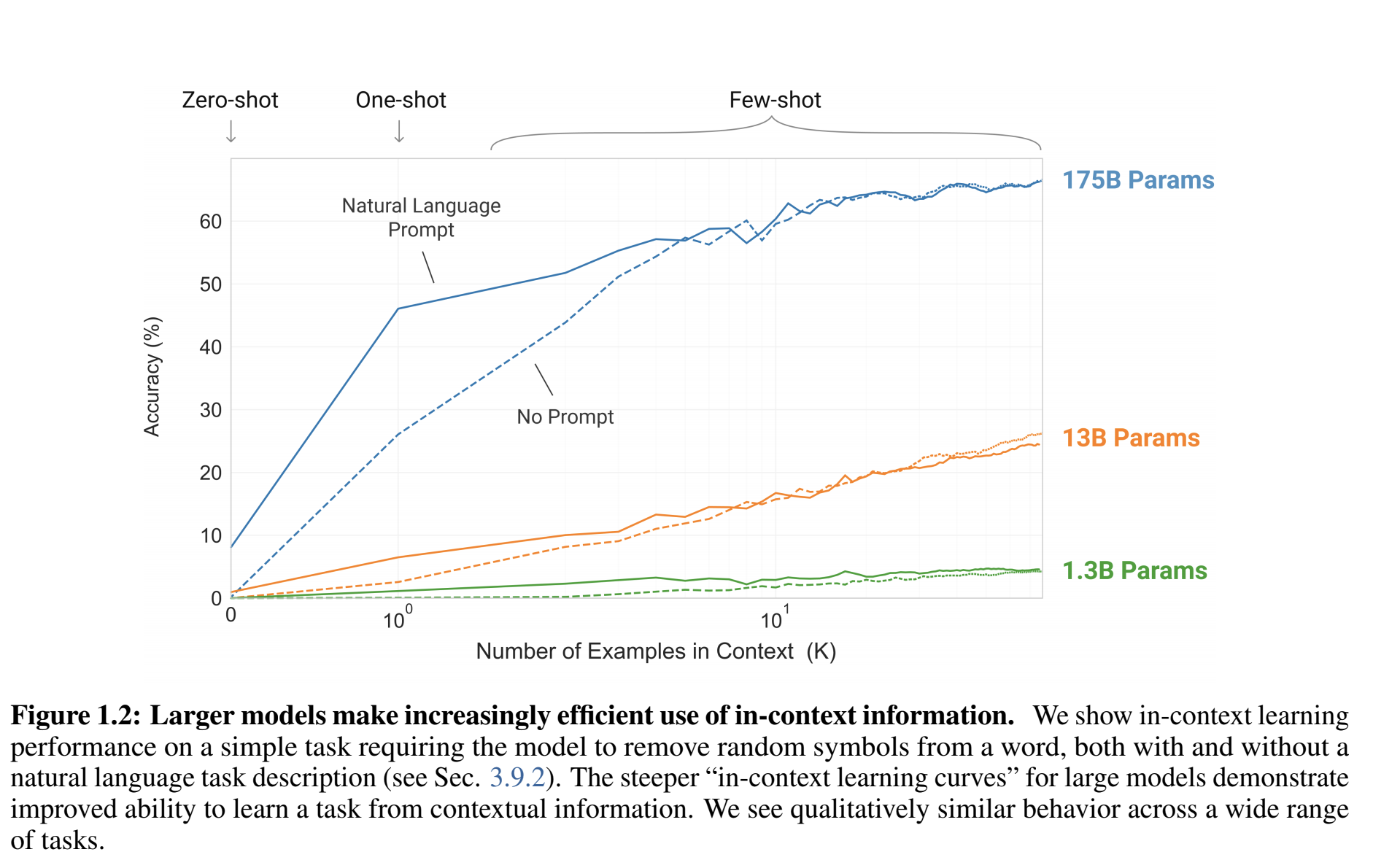
Impact of the prompt and N-shots
Compute
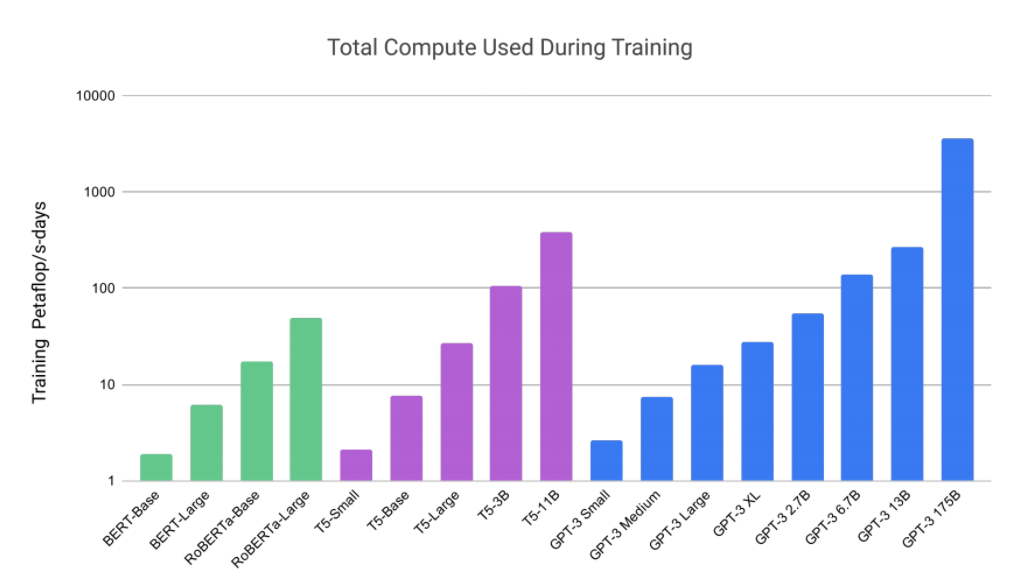
!! log scale here
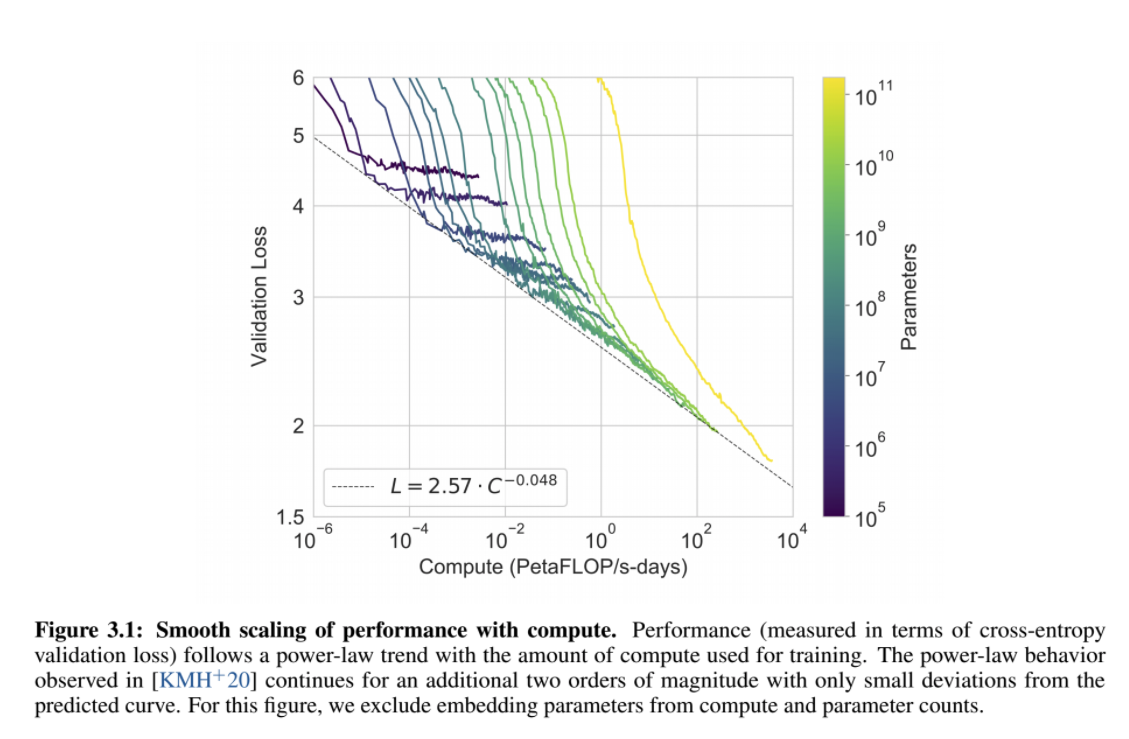
Loss per parameters per compute power
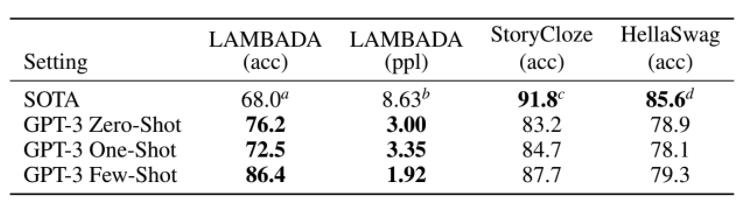
Language modelling

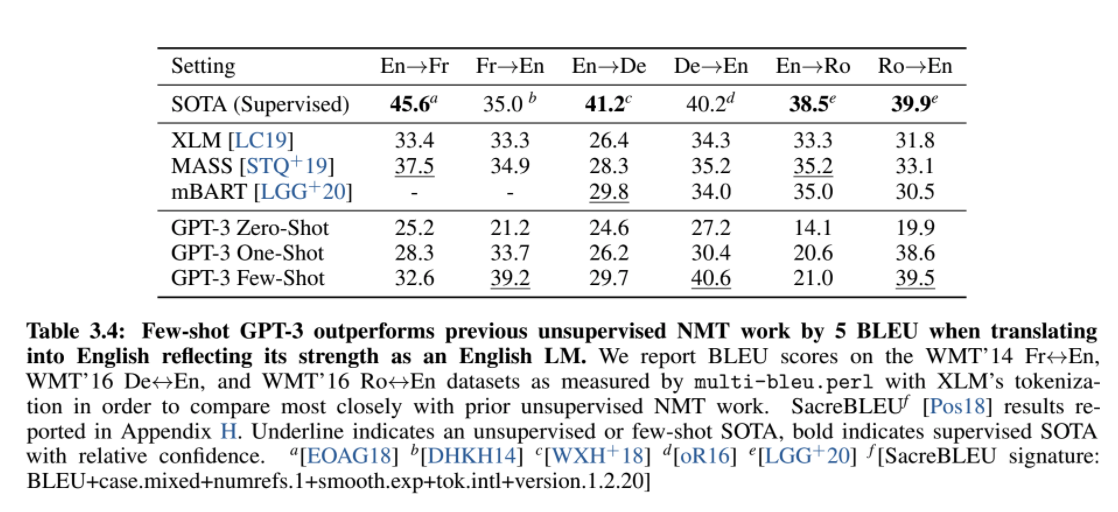
Machine Translation
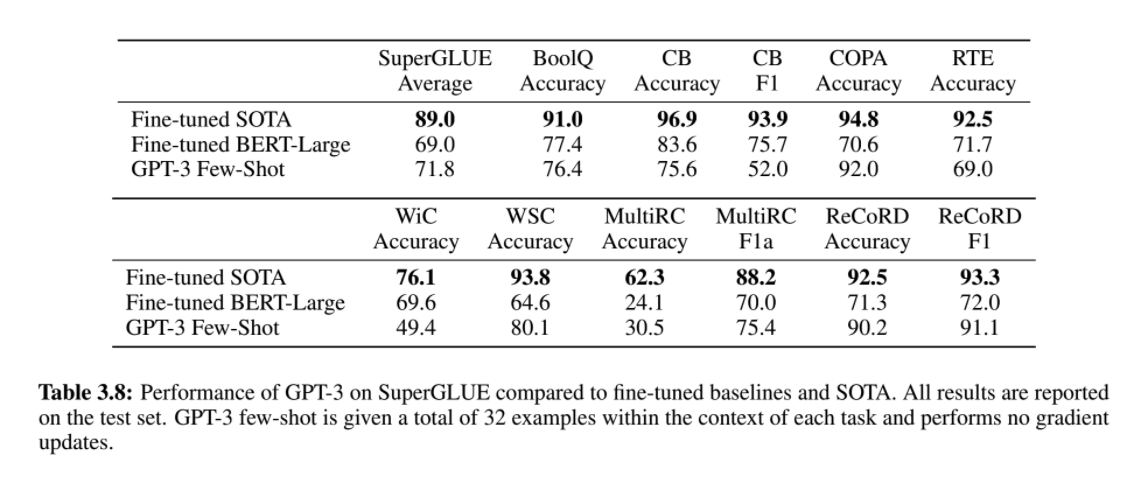
Reading comprehension
News Article Generation
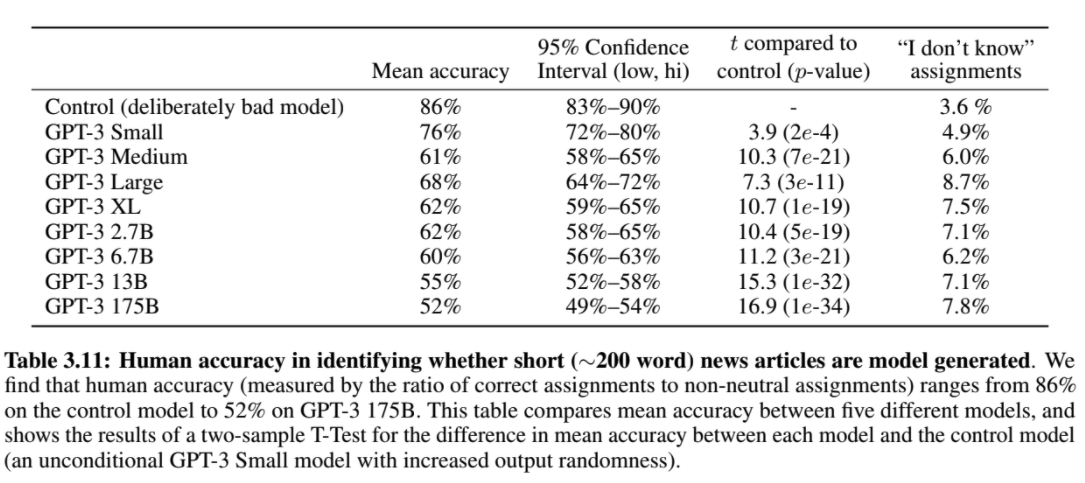
News Article Generation

News Article Generation
With great parameters comes great memorization
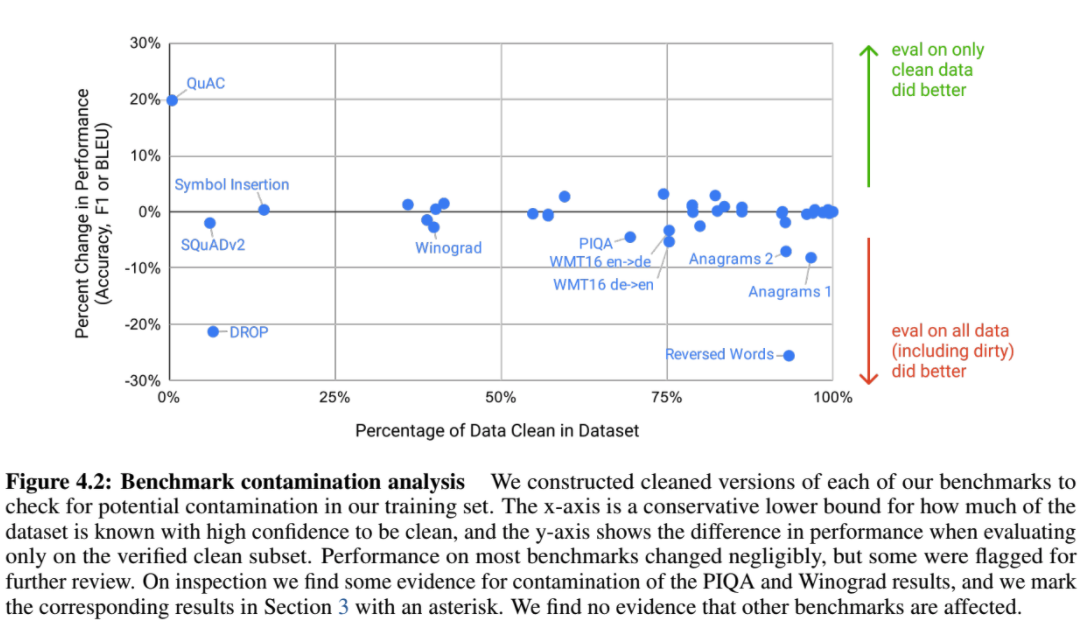
Limitations
- Text generation
- Redundancy
- No bidirectional assessment, information penalty for some tasks (i.e. fill in the blanks tasks)
- Homogeneous supervision reward of any token given any context (interesting point for any language model)
- Lack of structured knowledge of the world (e.g. a plugged knowledge base)
- We still don't know if the prompt actually triggers information about tasks already seen or actually gives enough information on the fly to solve a task never seen
- The compute power needed (e.g. they don't provide fine tuning comparison and leave it for future work because it is costly + they found and reported a bug in their data script they couldn't fix because the model was already trained)
- Results are not easy to interpret