How a journalist does Django
Michael Corey @mikejcorey
We're doing a story about pesticides.
There's good data on this one.
What should we do?
IR doing it rong
CSVs
Django
JSON and GeoJSON
QGIS/TileMill
S3
Cloudfront

What do we have?
Question 1
Pile o' CSVs
Each year
RTFM
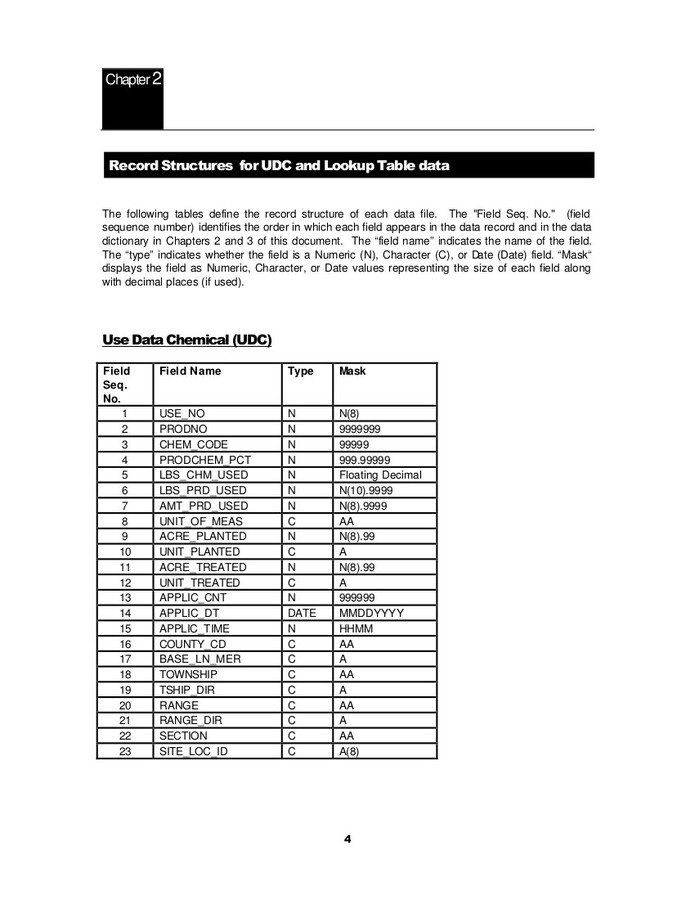
What do I want to end up with?
Question 2
Apps we considered
- Searchable database of applications
- Who's the biggest applicator of pesticides?
- What farmers use the most?
- Search by chemical and see where it's applied
- Map of where most chemicals were applied
- Lookup of where I live, what's applied there
What we ended up with
- Map of where most chemicals were applied
- Lookup of where I live, top 5 chemicals applied there
Why Django?
Question 3
What should my models be?
Question 4
Project overview
-
apps
- grid
- countymap
- core
- chemicals
- oxnard
chemicals models
class Application(models.Model):
use_no = models.CharField(max_length=25, db_index=True)
record_id = models.CharField(max_length=5, db_index=True) # Used to determine agricultural use or not
ag_use = models.BooleanField(default=False, db_index=True) # Helper category based on record_id
chemical = models.ForeignKey(Chemical, null=True)
product = models.ForeignKey(Product, null=True)
crop = models.ForeignKey(Crop, null=True)
lbs_chem_used = models.DecimalField(max_digits=30, decimal_places=20, null=True)
lbs_prod_used = models.DecimalField(max_digits=30, decimal_places=20, null=True)
prod_chem_pct = models.FloatField(null=True)
acres_planted = models.FloatField(null=True)
acres_treated = models.FloatField(null=True)
application_date = models.DateField(null=True, blank=True)
application_year = models.IntegerField(null=True) # Based on application_date
record_year = models.IntegerField(null=True) # What year's file this came in. In some odd cases may differ from above. Use application_year except when data cleaning for this specific issue.
county = models.ForeignKey(County, null=True)
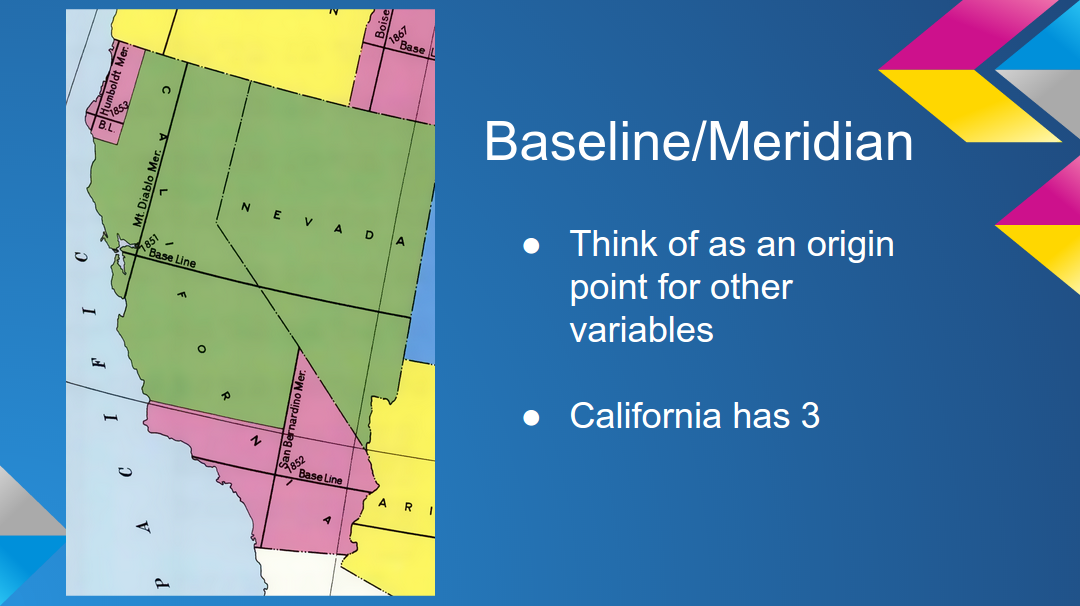
base_ln_mr = models.CharField(max_length=25, blank=True)
township = models.CharField(max_length=25, blank=True)
tship_dir = models.CharField(max_length=25, blank=True)
range = models.CharField(max_length=25, blank=True)
range_dir = models.CharField(max_length=25, blank=True)
section = models.CharField(max_length=25, blank=True)
has_errors = models.BooleanField(default=False) # Helper based on Error table
fumigant_used = models.BooleanField(default=False) # Based on chemical, not productPLSS mapping fields
class Application(models.Model):
...
county = models.ForeignKey(County, null=True)
base_ln_mr = models.CharField(max_length=25, blank=True)
township = models.CharField(max_length=25, blank=True)
tship_dir = models.CharField(max_length=25, blank=True)
range = models.CharField(max_length=25, blank=True)
range_dir = models.CharField(max_length=25, blank=True)
section = models.CharField(max_length=25, blank=True)
...
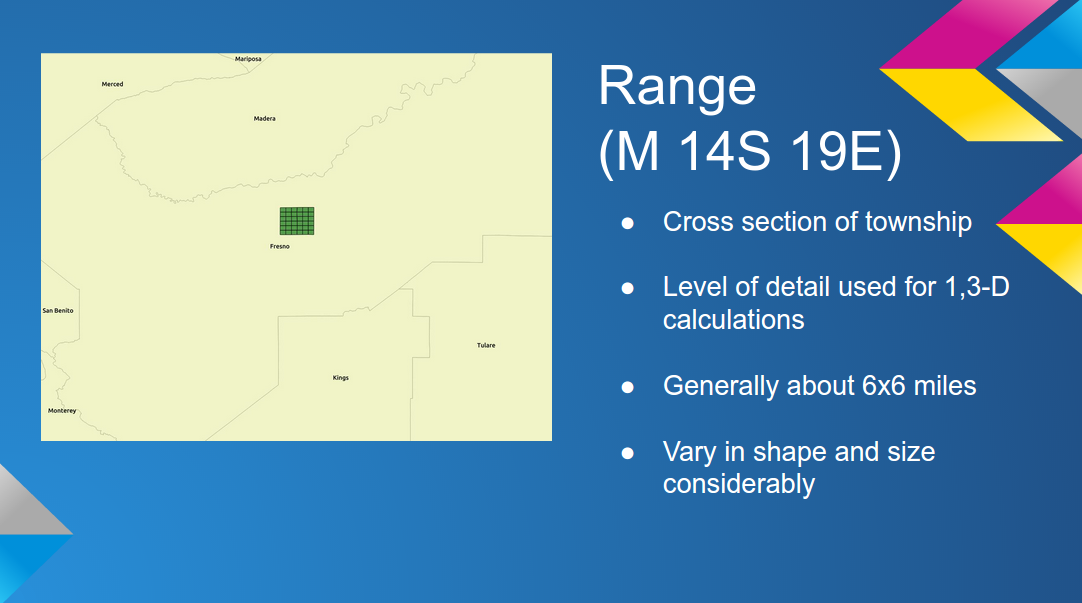
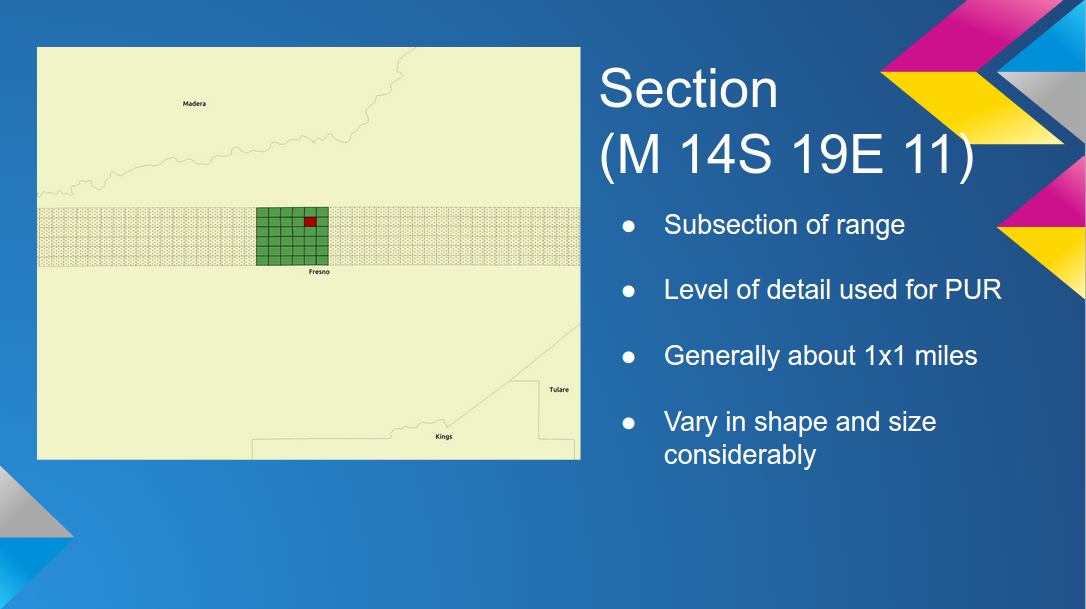
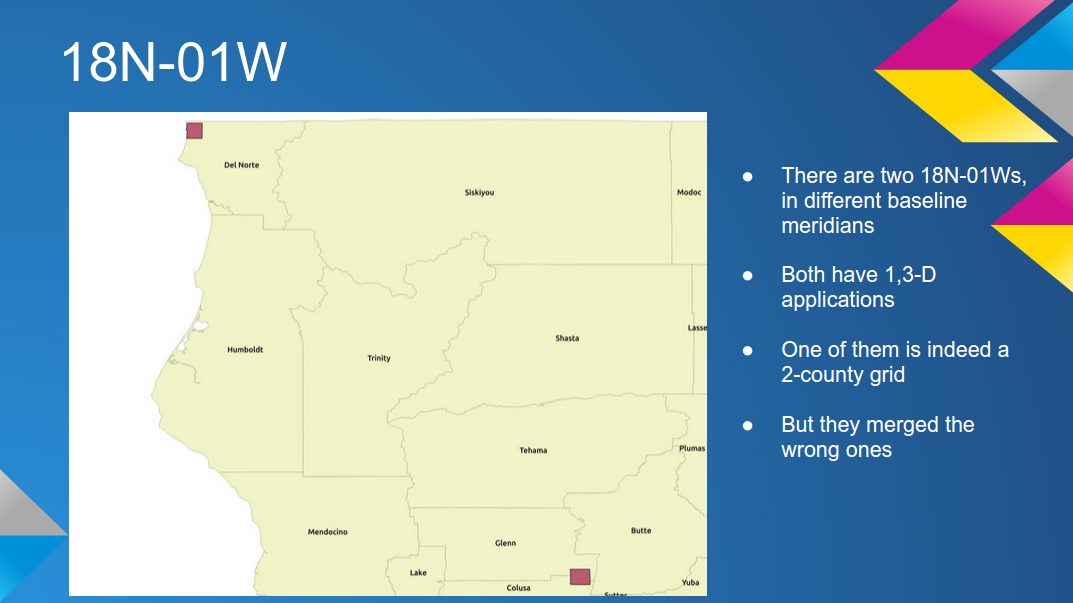
grid models
class CAGrid(models.Model):
...
county_cd = models.CharField(max_length=2)
range = models.CharField(max_length=3)
section = models.CharField(max_length=2)
base_ln_me = models.CharField(max_length=1)
township = models.CharField(max_length=3)
geom = models.MultiPolygonField(srid=4326)
total_application_count = models.IntegerField(default=0)
objects = models.GeoManager()
class CAMetaGrid(models.Model):
county_cd = models.CharField(max_length=2, blank=True)
range = models.CharField(max_length=3)
base_ln_me = models.CharField(max_length=1)
township = models.CharField(max_length=3)
section = models.CharField(max_length=1, null=True, default=None)
# Section is always none. Defined anyway to make aggregating stats easier
geom = models.MultiPolygonField(srid=4326)
...
class CAMetaGridMerged(models.Model): # For use with 1,3-D data from Dow
...Foreign keys ...
from django.contrib.gis.db import models
class Year(models.Model):
...
class ConcernCategory(models.Model):
name = models.CharField(max_length=100)
match_code = models.CharField(max_length=10)
description = models.TextField(blank=True)
active = models.BooleanField(default=True)
class Chemical(models.Model):
code = models.CharField(max_length=25, db_index=True)
name = models.CharField(max_length=255)
fumigant = models.BooleanField(default=False)
chem_of_concern = models.NullBooleanField()
concern_categories = models.ManyToManyField(ConcernCategory, null=True)
class County(models.Model):
...
class ErrorCode(models.Model):
code = models.CharField(max_length=5, db_index=True)
description = models.TextField(blank=True)
dealbreaker = models.BooleanField(default=False)
class Error(models.Model):
...Which applications are important?

What's NOT important?

How am I going to import this efficiently?
Pile o' CSVs
Each year
~3.5 million/year
First draft: All ORM
for row in csv_object:
try:
chemical = Chemical.objects.get(code=row['chem_code'].strip())
except:
chemical = None
try:
product = Product.objects.get(code=row['prodno'].strip())
except:
product = None
crop, crop_created = Crop.objects.get_or_create(
code=row['site_code'].strip()
)
county, county_created = County.objects.get_or_create(
no=row['county_cd'].strip()
)
appdate = datetime.datetime.strptime(row['applic_dt'].strip(), "%m/%d/%Y").date()
appyear = appdate.year
application = Application(
use_no=row['use_no'].strip(),
record_id=row['record_id'].strip(),
ag_use=ag_use,
chemical=chemical,
product=product,
crop=crop,
lbs_chem_used=self.mk_decimal(row['lbs_chm_used']),
lbs_prod_used=self.mk_decimal(row['lbs_prd_used']),
prod_chem_pct=self.mk_decimal(row['prodchem_pct']),
acres_planted=self.mk_decimal(row['acre_planted']),
acres_treated=self.mk_decimal(row['acre_treated']),
application_cnt=self.mk_decimal(row['applic_cnt']),
application_date=appdate,
application_year=appyear,
record_year=year,
county=county,
base_ln_mr=row['base_ln_mer'].strip(),
township=row['township'].strip(),
tship_dir=row['tship_dir'].strip(),
range=row['range'].strip(),
range_dir=row['range_dir'].strip(),
section=row['section'].strip(),
site_loc_id=row['site_loc_id'].strip(),
grower_id=growers[row['grower_id'].strip()],
batch=row['batch_no'].strip(),
document=row['document_no'].strip(),
license_id=licenses[row['license_no'].strip()],
)
application.save()Second draft: All ORM, bulk insert
bulk_create_objects, counter = [], 1
for row in csv_object:
try:
chemical = Chemical.objects.get(code=row['chem_code'].strip())
except:
chemical = None
try:
product = Product.objects.get(code=row['prodno'].strip())
except:
product = None
crop, crop_created = Crop.objects.get_or_create(
code=row['site_code'].strip()
)
county, county_created = County.objects.get_or_create(
no=row['county_cd'].strip()
)
appdate = datetime.datetime.strptime(row['applic_dt'].strip(), "%m/%d/%Y").date()
appyear = appdate.year
application = Application(
use_no=row['use_no'].strip(),
record_id=row['record_id'].strip(),
ag_use=ag_use,
chemical=chemical,
product=product,
crop=crop,
...
)
bulk_create_objects.append(application)
if counter % 10000 == 0:
Application.objects.bulk_create(bulk_create_objects)
bulk_create_objects = []
logger.info('Inserted %s applications' % counter)
if counter % 50000 == 0:
self.clear_query_cache()
counter += 1
Application.objects.bulk_create(bulk_create_objects)
logger.info('Inserted %s applications' % counter)Third draft: Lookup dicts, foo_id
chem_codes = dict(Chemical.objects.all().values_list('code', 'pk'))
prod_codes = dict(Product.objects.all().values_list('prodno', 'pk'))
crop_codes = dict(Crop.objects.all().values_list('no', 'pk'))
for row in csv_object:
try:
chemical = chem_codes[row['chem_code'].strip()]
# Compare to: chemical = Chemical.objects.get(code=row['chem_code']).pk
except:
chemical = None
application = Application(
use_no=row['use_no'].strip(),
record_id=row['record_id'].strip(),
ag_use=ag_use,
chemical_id=chemical,
product_id=product,
crop_id=crop,
...
)
bulk_create_objects.append(application)Things we could have tried
- Raw bulk insert (PostgreSQL COPY, MySQL LOAD DATA INFILE)
- Raw models, translate to production models
- Divide and conquer on EC2
OK, data is loaded.
Now what?
Aggregate stats
Too big to fail
Stats models
Not really accounted for in MVC, but the ORM still loves us and wants us to be happy.
STAT_TYPE_CHOICES = (
('lbs_chem', 'Pounds (chemical weight)'),
('lbs_fum_chem', 'Pounds of fumigant (chemical weight)'),
('lbs_concern_chem', 'Pounds of chemicals of concern (chemical weight)'),
)
class GridStatPack(models.Model):
grid = models.ForeignKey(CAGrid, null=True)
metagrid = models.ForeignKey(CAMetaGrid, null=True)
chemical = models.ForeignKey(Chemical, null=True)
stat_type = models.CharField(max_length=20, choices=STAT_TYPE_CHOICES)
relation_id = models.IntegerField(null=True)
year = models.IntegerField(null=True)
month = models.IntegerField(null=True)
lbs = models.DecimalField(max_digits=30, decimal_places=20, null=True)
application_count = models.IntegerField(null=True)
related_stats = models.TextField(blank=True)
concern_stats = models.TextField(blank=True)
percentile = models.IntegerField(null=True)Adding up stats
def totals(self, year=None, month=None, day=None, fumigants_only=None, chemicalid=None, chem_of_concern_only=False, meta_totals=False, ignore_county=False):
kwargs = {}
if year:
kwargs['application_year'] = year
if month:
kwargs['application_date__month'] = month
if day:
kwargs['application_date__day'] = day
if fumigants_only:
kwargs['fumigant_used'] = True
if chemicalid:
kwargs['chemical_id'] = chemicalid
if chem_of_concern_only:
kwargs['chemical__chem_of_concern'] = True
totals = Application.active_objects.exclude(section__exact='').filter(**kwargs).values(
'base_ln_mr',
'township',
'tship_dir',
'range',
'range_dir',
'county__no'
).annotate(
lbs_chem_used=Sum('lbs_chem_used')
).annotate(
application_count=Count('pk')
)
return totals
def matching_stats(self, totallist, blinemer, tship, tshipdir, range_only, rangedir, section, county_cd):
match = [k for k in totallist if k['base_ln_mr'] == blinemer if k['township'] == tship if k['tship_dir'] == tshipdir if k['range'] == range_only if k['range_dir'] == rangedir if k['section'] == section if k['county__no'] == county_cd]
return match
def create_stat_pack(self, totals, grid, stat_type, year, month, weight_var, chemical=None, relation_id=None):
# Find match in totals lookup list
match = self.matching_stats(totals, grid.base_ln_me, grid.township_only, grid.township_dir, grid.range_only, grid.range_dir, grid.section, grid.county_cd)
if len(match) == 1:
sp = GridStatPack(
grid=grid,
stat_type=stat_type,
relation_id=relation_id,
chemical_id=chemical,
year=year,
month=month,
lbs=match[0][weight_var],
application_count=match[0]['application_count'],
)Methods to retrieve stats
class CAGrid(models.Model):
...
def total_lbs_used_concern_chemical(self):
try:
stats = GridStatPack.objects.get(grid=self, stat_type='lbs_concern_chem', year=None, month=None)
return int(round(stats.lbs))
except:
return None
def top_chemicals(self):
try:
return json.loads(self.main_stat_pack().related_stats)
except:
return []Model managers help me sleep
class ActiveApplicationManager(models.Manager):
def get_queryset(self):
return super(ActiveApplicationManager, self).get_queryset().filter(
has_errors=False,
ag_use=True
)
class Application(models.Model):
...
objects = models.Manager()
active_objects = ActiveApplicationManager()
Application.active_objects.filter(stuff='blahblahblah')Get dynamic to get static
Use Django to build an API
API powers all the things
Get dynamic to get static
Model methods
GeoJSON views
Cache GeoJSON
GeoJSON to S3, elsewhere
GeoJSON views: What I did then
class CAGridGeoJSON(GenericGeoJSON):
property_fields = [
'county_cd',
'base_ln_me',
'township',
'range',
'section'
]
model_methods = [
'total_lbs_used_fumigants_chemical',
'total_lbs_used_all_chemical',
'total_lbs_used_concern_chemical',
'top_chemicals',
'top_chemicals_of_concern',
'county_name'
]
geom_field = 'geom'
def get_queryset(self):
queryset = CAGrid.objects.filter(total_application_count__gt=0)
return querysetGeoJSON views: What to do now
from djgeojson.views import GeoJSONLayerView
class OKQuakeBinsGeoJSON2015(GeoJSONLayerView):
geometry_field = 'wgs84_geom'
properties = [
'county_cd',
'base_ln_me',
'township',
'range',
'section',
'total_lbs_used_fumigants_chemical',
'total_lbs_used_all_chemical',
'total_lbs_used_concern_chemical',
'top_chemicals',
'top_chemicals_of_concern', # As long as it's a @property
'county_name'
]
def get_queryset(self):
return CAGrid.objects.filter(total_application_count__gt=0)Or: https://docs.djangoproject.com/en/1.8/ref/contrib/gis/serializers/
Caching views, the dirty hacky way
from django.core.management.base import BaseCommand
from django.test.client import Client
class Command(BaseCommand):
help = 'Parse super-complex totals into static JSON, upload to S3.'
def cache_and_deliver(self, content, filename):
if not os.path.exists(os.path.join(settings.SITE_ROOT, 'assets', 'json')):
os.makedirs(os.path.join(settings.SITE_ROOT, 'assets', 'json'))
cached_json = open(os.path.join(settings.SITE_ROOT, 'assets', 'json', filename), 'w')
cached_json.write(content)
cached_json.close()
self.stdout.write('Cached file: %s.\n' % (filename,))
return cached_json
def handle(self, *args, **options):
try:
c = Client()
response = c.get('/json/cagridmap.json', {}, follow=True)
self.cache_and_deliver(response.content, 'cagrids_cached.json')
response = c.get('/json/cametagridmap.json', {}, follow=True)
self.cache_and_deliver(response.content, 'cametagrids_cached.json')Why not ...
- Tastypie/Django REST framework?
- Django bakery
Fun with TileMill!
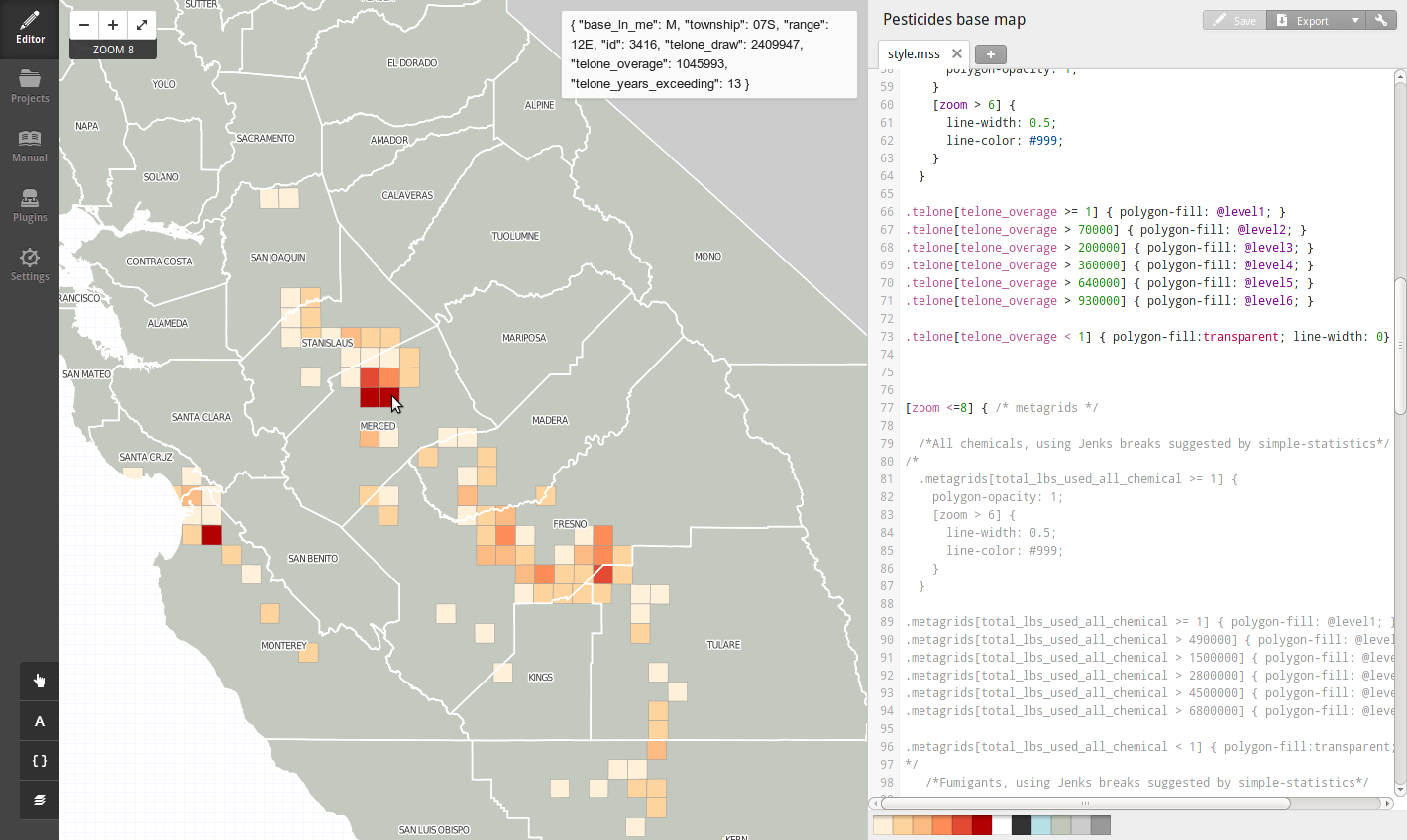
This isn't just
about graphics
Things we could only say in our story
because of the data
- More than 1 million people affected by overages
- How many times the state exceeded its own guidelines
- Six places exceeded every year
- One place exceeded by over 1 million pounds
- Strawberries account for 8 percent of state pesticide use (but only 1 percent of total farmland)
- Strawberry growers’ use of 1,3-D tripled over 10 years