Gensim
Topic Modelling (or not?)
for humans

Gensim




Gensim
- Data streaming
- Fast training using BLAS, multi-core & distributed mode
- Robust implementations of popular models
- Pre-trained models & popular datasets
- Community & support: Twitter, Gitter, mailing list
- Easy installation:
-
pip install -U gensim
-
conda install -c conda-forge gensim
-
Gensim
Vector + Similarity Is All You Need
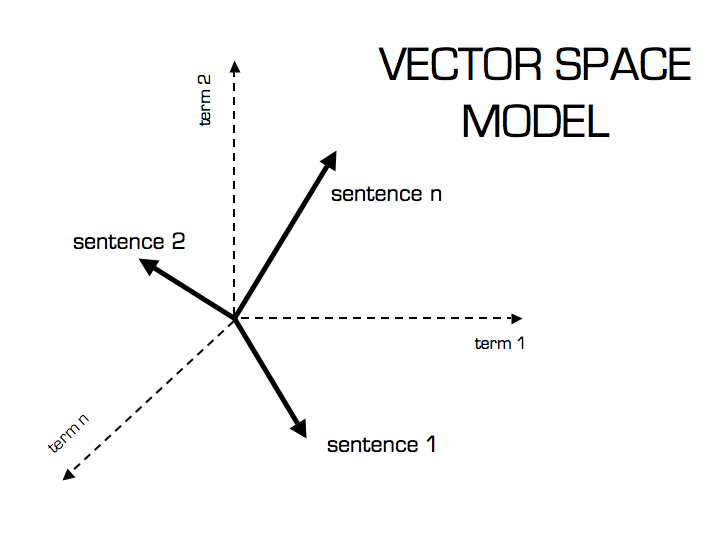

Gensim
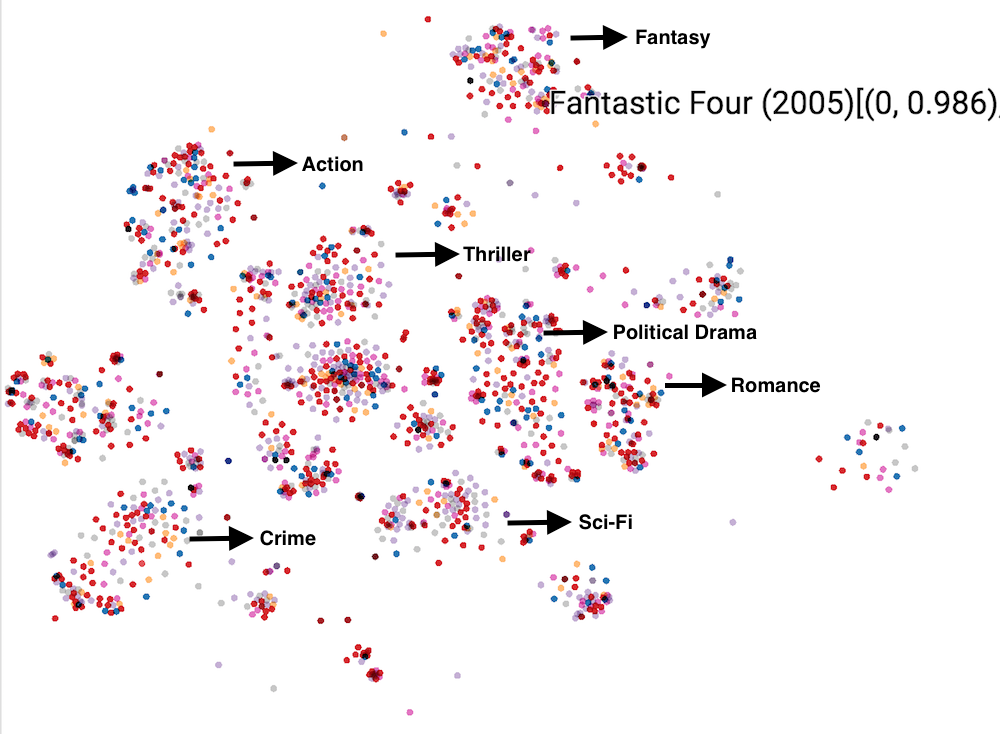
More examples (click)
Gensim
Input: text
XXX.YY.ZZ.AA - - [21/Oct/2018:06:59:38 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 zgrab/0.x"
XXX.YY.ZZ.AA - - [21/Oct/2018:07:11:53 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:47.0) Gecko/20100101 Firefox/47.0"
XXX.YY.ZZ.AA - - [21/Oct/2018:07:47:40 +0200] "t3 12.2.1" 400 182 "-" "-"
XXX.YY.ZZ.AA - - [21/Oct/2018:07:59:49 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
XXX.YY.ZZ.AA - - [21/Oct/2018:08:28:19 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
XXX.YY.ZZ.AA - - [21/Oct/2018:08:41:56 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
XXX.YY.ZZ.AA - - [21/Oct/2018:08:41:56 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
XXX.YY.ZZ.AA - - [21/Oct/2018:08:53:02 +0200] "HEAD /wp-config.php HTTP/1.1" 301 0 "-" "-"
XXX.YY.ZZ.AA - - [21/Oct/2018:09:16:00 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:47.0) Gecko/20100101 Firefox/47.0"
XXX.YY.ZZ.AA - - [21/Oct/2018:10:11:33 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 zgrab/0.x"
XXX.YY.ZZ.AA - - [21/Oct/2018:11:26:50 +0200] "GET /images.php HTTP/1.1" 301 194 "-" "Mozilla/5.0 zgrab/0.x"
XXX.YY.ZZ.AA - - [21/Oct/2018:11:37:09 +0200] "GET /console HTTP/1.1" 301 194 "-" "python-requests/2.19.1"
XXX.YY.ZZ.AA - - [21/Oct/2018:12:46:42 +0200] "GET /wordpress/ HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"
XXX.YY.ZZ.AA - - [21/Oct/2018:14:07:34 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
XXX.YY.ZZ.AA - - [21/Oct/2018:14:19:41 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
XXX.YY.ZZ.AA - - [21/Oct/2018:14:40:01 +0200] "GET /manager/html HTTP/1.1" 301 194 "-" "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; WOW64; Trident/6.0)"
XXX.YY.ZZ.AA - - [21/Oct/2018:15:12:56 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 zgrab/0.x"
XXX.YY.ZZ.AA - - [21/Oct/2018:16:47:36 +0200] "GET / HTTP/1.1" 301 194 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.7 (KHTML, like Gecko) Version/9.1.2 Safari/601.7.7"

Gensim
Text - sequence of tokens
Token ~ "word" (???)
Token ~ "discrete value"

Gensim


Gensim

Gensim
Tasks?
- Classification / Clustering
- Search engine
- Sentiment analysis
- Topic modelling
- Chat-bots
- ...
Vector repr
bag of words

Vector repr
Main idea - matrix factorization
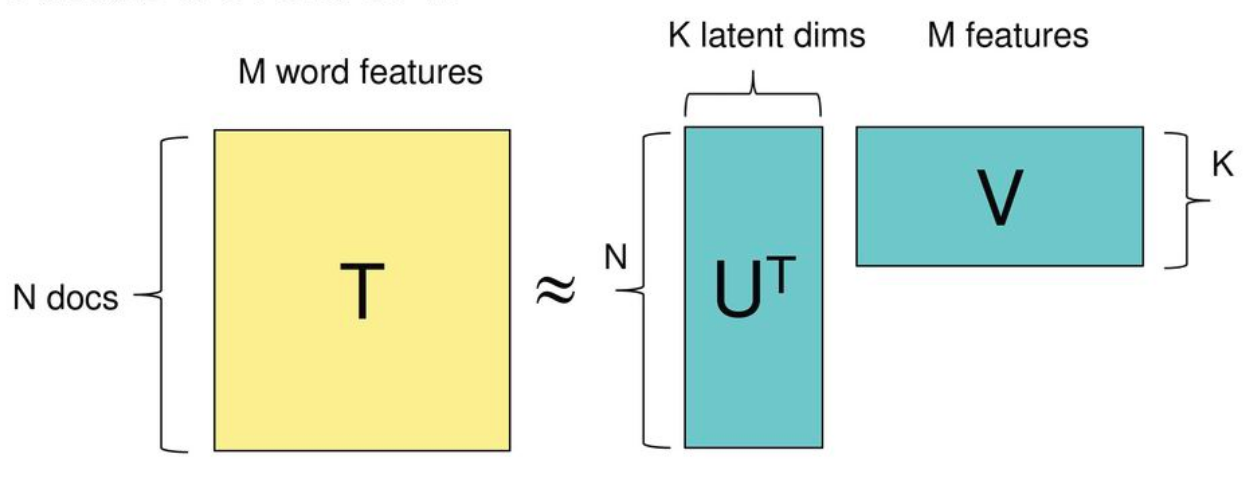
Vector repr
Main idea - matrix factorization
What are the advantages?
- Fast (Train + Infer, w/o GPU)
- Robust
- Simple
- JUST WORKS!
LSI (SVD)
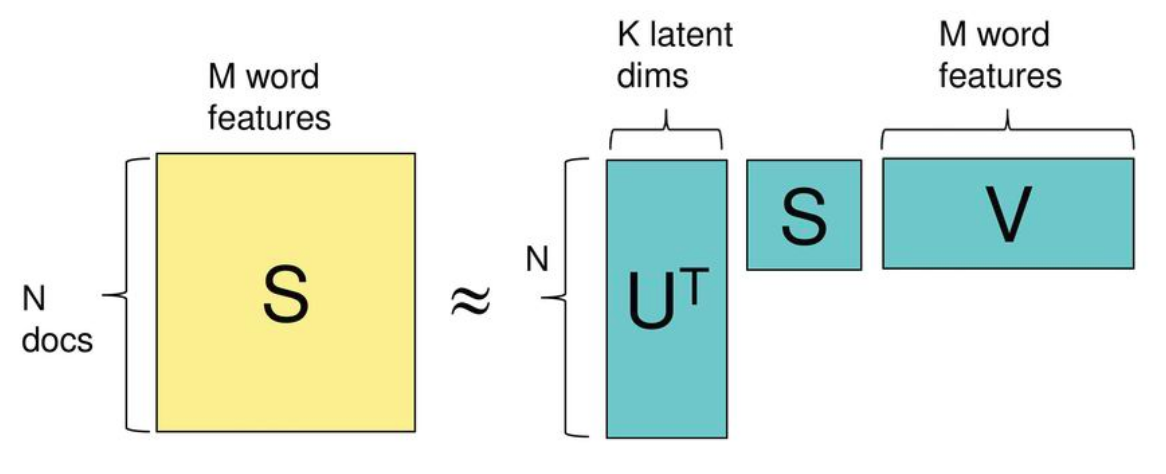
LSI (SVD)
import gensim.downloader as api
from gensim.corpora import Dictionary
from gensim.models import LsiModel
# 1. Load data
data = api.load("text8")
# 2. Create dictionary
dct = Dictionary(data)
dct.filter_extremes(no_below=7, no_above=0.2)
# 3. Convert data to bag-of-word format
corpus = [dct.doc2bow(doc) for doc in data]
# 4. Fit model
model = LsiModel(corpus, id2word=dct, num_topics=300)LSI (SVD)
- Fast (really)
- Great baseline
LDA
LDA
1 dice for choice topic
N dices for choice word from topic


LDA
import gensim.downloader as api
from gensim.corpora import Dictionary
from gensim.parsing import preprocess_string
from gensim.models import LdaModel
# 1. Load data
data = api.load("20-newsgroups")
# 2. Tokenize data
data = [preprocess_string(_["data"]) for _ in data]
# 3. Create dictionary
dct = Dictionary(data)
dct.filter_extremes(no_below=5, no_above=0.15)
# 4. Convert data to bag-of-word format
corpus = [dct.doc2bow(doc) for doc in data]
# 5. Fit model
model = LdaModel(corpus, id2word=dct, num_topics=20, passes=10)LDA
for topic_id, repr in model.show_topics(3, num_words=5):
print("#{}: {}".format(topic_id, repr))
#5: 0.012*"armenian" + 0.009*"kill" + 0.009*"israel" + 0.008*"fbi" + 0.007*"war"
#0: 0.016*"govern" + 0.013*"law" + 0.010*"presid" + 0.010*"gun" + 0.006*"nation"
#9: 0.023*"space" + 0.011*"car" + 0.011*"mission" + 0.010*"earth" + 0.009*"shuttl"
LDA
- Interpretable
- Often nice for classification
- Short texts not our case
although I know hack (:
Word2Vec
M word
features
M
Word2Vec

Word2Vec
import gensim.downloader as api
model = api.load("word2vec-google-news-300")
model.most_similar(
positive=["king", "woman"],
negative=["man"],
topn=1
)
# [(u'queen', 0.7118192911148071)]
model.most_similar("cat")
# [(u'cats', 0.8099379539489746),
# (u'dog', 0.7609456777572632),
# (u'kitten', 0.7464985251426697),
# (u'feline', 0.7326233983039856),
# (u'beagle', 0.7150583267211914),
# (u'puppy', 0.7075453996658325),
# (u'pup', 0.6934291124343872),
# (u'pet', 0.6891531348228455),
# (u'felines', 0.6755931377410889),
# (u'chihuahua', 0.6709762215614319)]
Word2Vec
- Ready2Use models
- Free baseline
- Used as input in DL
Anything else?
- Doc2Vec (Mikolov, Le)
- FastText (Mikolov, Bojanowski, Joulin)
- (soon) Sent2Vec (Pagliardini, Gupta, Jaggi)
- Poincare (Nickel, Kiela)
- Moar TM [author, temporal, etc]
How to choose
what I need?
How to choose
what I need?
2. Start from pre-trained

How to choose
what I need?
3. Implement end2end evaluation
You need something similar, but for your concrete task
Compare all, choose the best!
Production?

Thanks!



