Relationale Datenbanksysteme

von
Michael Albrecht - Ausbilder FIAN
team neusta GmbH
Agenda
Motivation & Historie
Relationen & Entitäten
Datenbankdesign
Normalisierung
Structured Query Language
Sonstiges

Vorstellungsrunde
Wie heiße ich und was ist meine Motivation FIAN zu werden?
Was bringe ich zum Thema Datenbanksysteme bereits für Vorkenntnisse mit?
Was erwarte ich am Ende des Kurses?

Möglichst zu jeder Frage 1-2 Sätze und insgesamt nicht länger als 2 Minuten
Relationale Datenbanksysteme
Motivation & Historie
Programme & Daten
Natürlich brauchen wir Daten vor allem, um sie in Programmen verarbeiten, verwenden und neue Daten erzeugen können.
Nur der reinen Datenhaltung halber ist seltener der Fall.
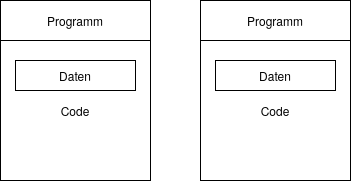

Probleme bei Datenverwaltung mit Dateien
- Redundanz
- Inkonsistenz
- Programm-Daten-Abhängigkeit
Architektur eines Datenbanksystems
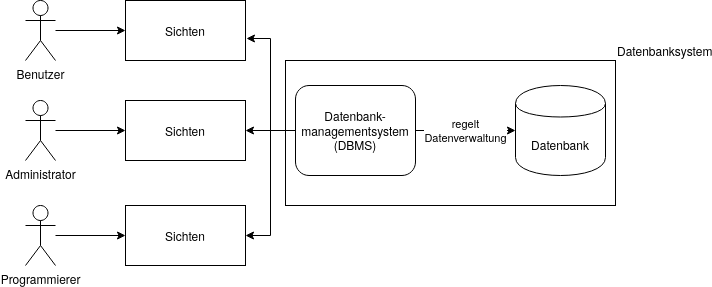
Relationale Datenbanksysteme
Entitäten & Relationen
Entitäten
Entitäten (lat.: entitas - Ding) sind Objekte unseres Denkens und Handelns.
Für ein Datenbanksystem also die Artefakte, die es zu speichern gilt.

Attribute
Attribute (lat.: attributere - zuordnen) sind Eigenschaften, die den Entitäten zugeordnet werden, um sie zu beschreiben oder auch voneinander zu unterscheiden.
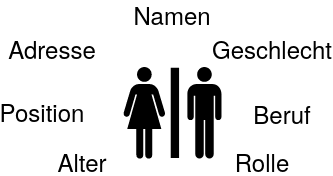
Relationen
Eine Relation (lat.: relatio - das Zurücktragen) ist eine Beziehung zwischen Entitäten.
Dabei nehmen die Entitäten evtl. unterschiedliche Rollen ein bzw. können mehrere Beziehungen zueinander haben.
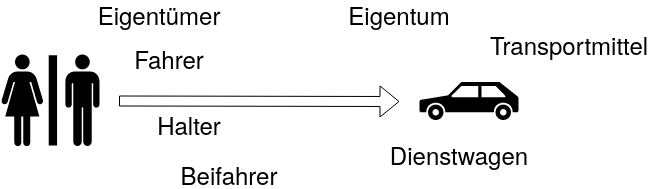
1.Aufgabe
Sammle alle Entitäten, die Du im Rahmen dieser Schulungsmassnahme siehst!
3.Aufgabe
Finde alle Relationen zwischen den Entitäten, die im Rahmen dieser Schulung von Bedeutung sind!
2.Aufgabe
Sammle anschließend alle Attribute der Entitäten, die Du in Aufgabe 1 gefunden hast!
Entitäten
- Ausbilder
- Präsentation
- Auszubildende
- Berufschule
- Dozent
- Firma
Attribute
- Ausbilder
- Name
-
Alter(besser: Geburtstdatum)
- Präsentation
- Titel
- Beschreibung
- Auszubildende
- ID
- Vorname
- Nachname
- Berufschule
- Klassen
- Lehrer
- Standort
- Dozent
- Name
- Alter
- Firma
- Name
- Standort
Relationen
- Firma - Ausbilder: Eine Firma hat mehrere Ausbilder.
- Firma - Auszubildende: Eine Firma hat mehrere Auszubildende.
- Präsentation - Dozent: Ein Dozent hält mehrere Präsentationen.
- Ausbilder- Präsentation: Ein Ausbilder besitzt mehrere Präsentationen.
- Berufsschule - Auszubildende: Eine Berufsschule hat mehrere Auszubildende.
- Ausbilder - Auszubildende: Ein Ausbilder unterrichtet mehrere Auszubildende.
Schlüssel
Manche Attribute reichen hin, um einzelne Entitäten des gleichen Typs zu unterscheiden.
Diese nennt man Schlüssel.
Nicht-Schlüssel
Alle Attribute, die nicht Teil eines Schlüssel sind, nennt man Nicht-Schlüsselattribute.
Technischer Schlüssel
Schlüssel, die explizit als Schlüssel eingeführt werden, nennt man technische Schlüssel - Bsp.: ID
Fachlicher Schlüssel
Schlüssel, die aufgrund der Natur der Daten als Schlüssel dienen, nennt man fachliche Schlüssel.
Bsp.: Personalnummer
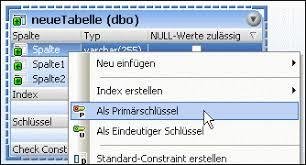
Primärschlüssel
Es kann innerhalb einer Entität viele Attribut(kombinationen) geben, die als Schlüssel dienen.
Einer sollte davon ausgezeichnet werden, indem man ihn Primärschlüssel nennt.
ER-Modell
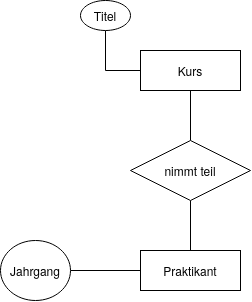
Entitäten sind Rechtecke.
Relationen sind Diamanten, die mit den Entitäten, die Teil der Relation sind, verknüpft werden.
Attribute werden als Kreise an die Rechtecke oder Diamanten gehängt.
Kardinalitäten
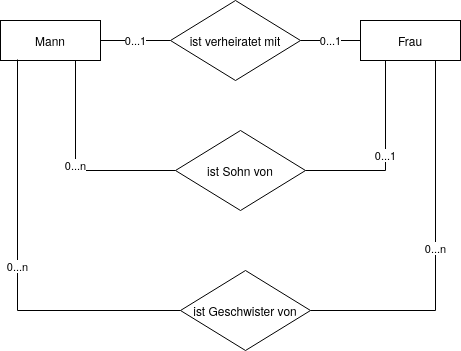
Es gibt folgende 3 Relationstypen:
- 1:1 Beziehung
- 1:n Beziehung
- m:n Beziehung
Die Kardinalitäten lassen sich mit 0...n bzw. 1...n feiner granulieren.
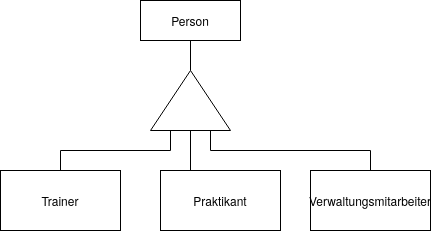
Spezialisierung & Generalisierung
Relationale Datenbanksysteme
Datenbank Design
ER-Modell Tabellen
- Entitäten in Tabellen
- 1:n - Relationen in Tabellen
- 1:1 - Relationen in Tabellen
- m:n - Relationen
- Attributierte Relationen
- Spezialisierung / Generalisierung
Entitäten in Tabellen
Entitäten werden natürlich 1:1 in Tabellen umgesetzt.
Dabei sollte der Name der Entität zum Tabellennamen werden.
Die Attribute werden zu Spalten(überschriften).
Der Wertebereich der Attribute bestimmt dabei den Typ der Spalten.
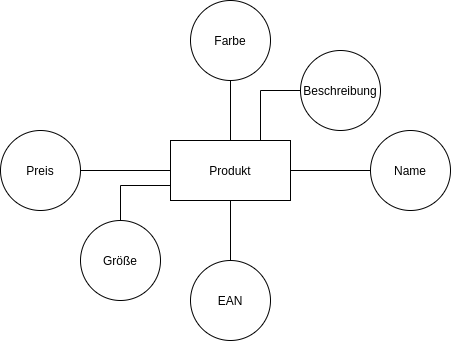
| EAN (PK) | Name | Beschreibung | Farbe | Größe | Preis |
|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... |
1:n - Relationen
Der Tabelle der Children-Entitäten wird der Primärschlüssel der Parent-Entität als Fremdschlüssel hinzugefügt.
| EAN (PK) | ProduktTypID (FK) | Name | ... |
|---|---|---|---|
| ... | ... | ... | ... |

1:1 - Relationen in Tabellen
Analog zu 1:n Relationen, wobei die Entscheidung, welche Seite Parent und welche Child ist, frei bleibt.
| ID | Ehefrau (FK) | Name | ... |
|---|---|---|---|
| ... | ... | ... | ... |
| ID | Name | ... |
|---|---|---|
| ... | ... | ... |
Frau
Mann
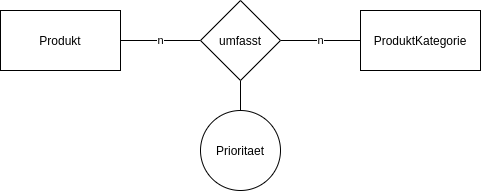
m:n - Relationen
m:n - Relationen werden über eine Mapping Tabelle abgebildet.

| EAN (PK) | Name | ... |
|---|---|---|
| 2000891 | Heimtrikot | ... |
| ID (PK) | Name | ... |
|---|---|---|
| 10 | Trikots | ... |
| 20 | Herren | ... |
Produktkategorie
Produkt
| EAN (PK, FK) | ID (PK, FK) |
|---|---|
| 2000891 | 10 |
| 2000891 | 20 |
Produkt2Produktkategorie
Attributierte Relationen
Im Falle der 1:n bzw. 1:1 Relationen werden die Attribute der Relation neben den Fremdschlüssel gestellt.
Im Falle der m:n - Relationen werden die Attribute zu Spalten der Mapping-Tabelle.
Spezialisierung / Generalisierung
Die Spezialisierung in weitere Entitäten, die eigene Attribute besitzen, wird behandelt wie eine 1:1 - Relation, wobei die allgemeine Entität der Parent ist.
Die Spezialisierung in weitere Entitäten, die keine eigenen Attribute besitzen, wird
- entweder über ein Typ-Attribut der Parent-Entität aufgelöst
- oder jede Child-Entität erhält seine eigene Tabelle mit gleichen Attributen.
Spezialisierung durch FK
| Email (PK) | Name | ... |
|---|---|---|
| ... | ... | ... |
Person
| Email (PK, FK) | Jahrgang | ... |
|---|---|---|
| ... | ... | ... |
Praktikant
Spezialisierung durch Typattribut
| Email (PK) | Name | Funktion |
|---|---|---|
| ... | ... | Trainer/Verwaltungsmitarbeiter/... |
Person
Spezialisierung durch Tabellensplitting
| Email (PK) | Name | .. |
|---|---|---|
| ... | ... | ... |
Praktikant
| Email (PK) | Name | ... |
|---|---|---|
| ... | ... | ... |
Trainer
| Email (PK) | Name | ... |
|---|---|---|
| ... | ... | ... |
Verwaltungsmitarbeiter
Relationale Datenbanksysteme
Normalisierung
Anomalien
Anomalien sind Unregelmäßigkeiten in den Datensätzen, die aufgrund der Pflege durch einzelne Benutzer oder im Mehrbenutzerbetrieb auftauchen können.
Normalisierung
- Normalform
- Normalform
- Normalform
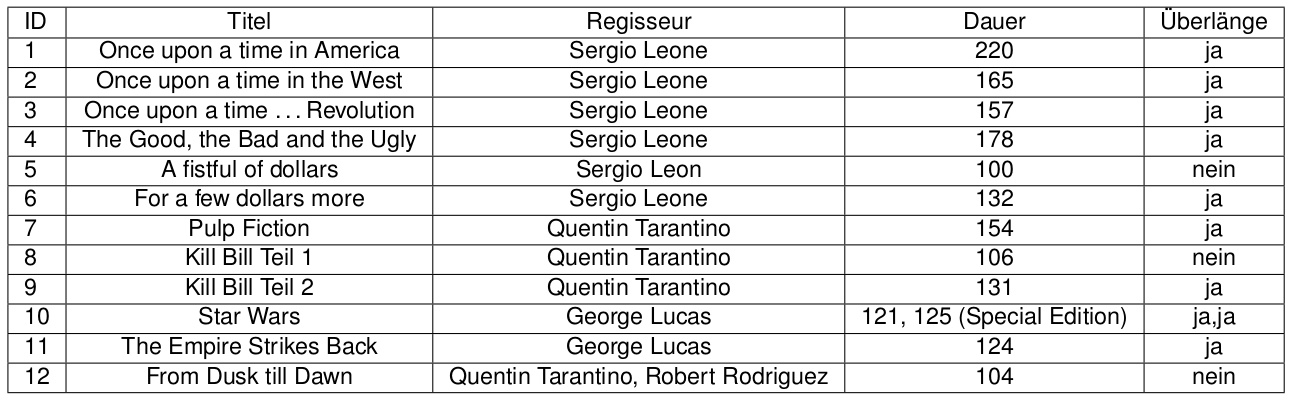
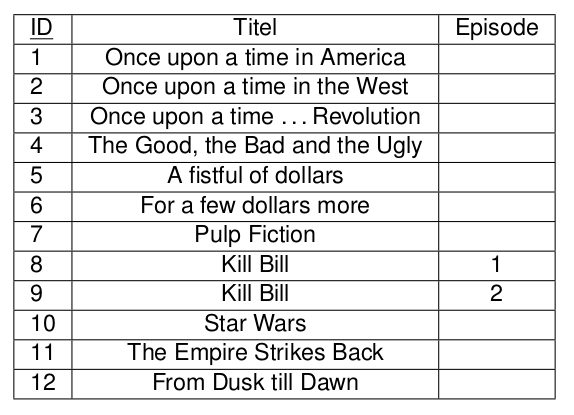
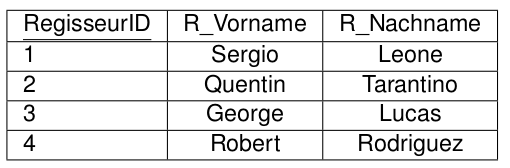
1.Normalform
Eine Relation ist in 1.Normalform, wenn alle ihre Attribute atomar sind.


Regisseur hat Vor- und Nachname
Dauer gibts 2mal.
Titel besteht aus Titel und Teil.
Aufspaltung in mehrere Attribute oder in mehrere Relationen.
Massnahme
Ergebnis
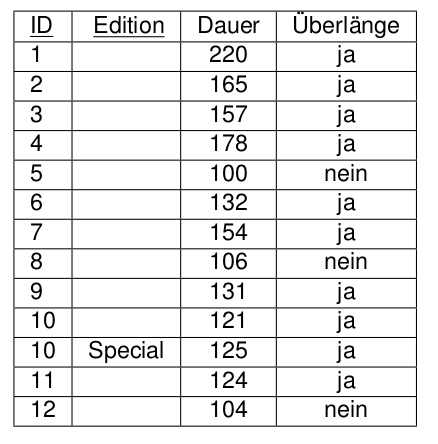
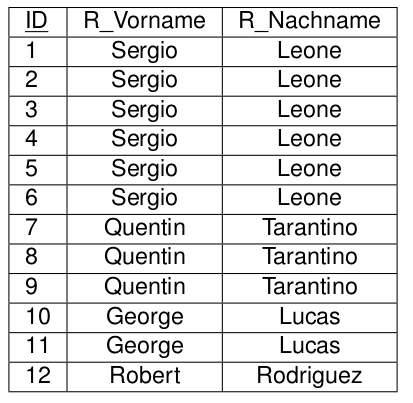
2.Normalform
Eine Relation ist in 2.Normalform, wenn sie
- in 1.Normalform ist und
- jedes Nicht-Schlüsselattribut voll funktional vom Schlüssel abhängt.
Ein Attribut A hängt von {B1, B2, B3} funktional ab, wenn bei Gleichheit in den Werten {B1, B2, B3} die Gleichheit in A folgt.
A hängt voll von {B1, B2, B3} funktional ab, wenn die Menge {B1, B2, B3} nicht verkleinert werden kann, ohne die funktionale Abhängigkeit zu verlieren.
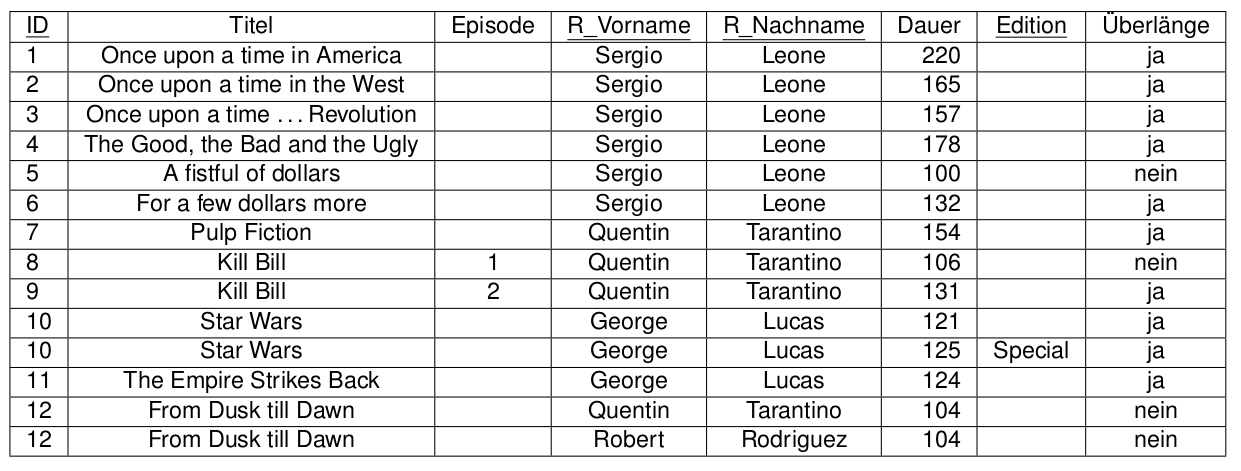
Wo gibt es hier funktionale Abhängigkeit?
Here we are...
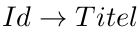
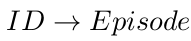
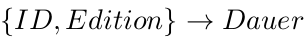
2.Normalform
Eine Relation ist in 2.Normalform, wenn sie
- in 1.Normalform ist und
- jedes Nicht-Schlüsselattribut voll funktional vom Schlüssel abhängt.
Aufspaltung in mehrere Tabellen, so dass jedes Nicht-Schlüsselattribut voll funktional vom Schlüssel abhängt..
Massnahme
Ergebnis
3.Normalform
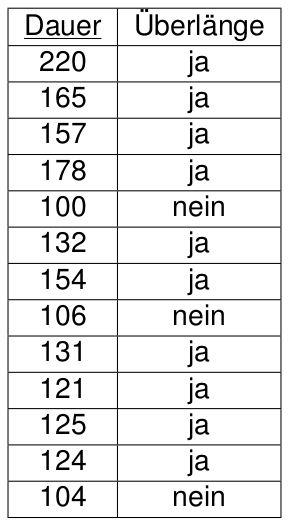
Eine Relation ist in 3.Normalform, wenn sie
- in 2.Normalform ist und
-
kein Nicht-Schlüsselattribut funktional
von Nicht-Schlüsseln abhängt.
Voneinander abhängige Attribute in
eigene Tabelle ausgelagern
Massnahme
Ergebnis
Relationale Datenbanksysteme
Structured Query Language
SQL ist ein Standard für RDBMSe
- DDL - Data Description Language
- DML - Data Manipulation Language
- DCL - Data Control Language
SQL
DDL
CREATE / DROP DATABASE
CREATE DATABASE datenbankSchemaName;
DROP DATABASE datenbankSchemaName;Mit diesen Befehlen erzeugt und löscht man ein neues Datenbankschema.
CREATE / DROP TABLE
CREATE TABLE tableName (
spaltenname1 sql_data_types [constraints],
spaltenname2 sql_data_types [constraints],
spaltenname3 sql_data_types [constraints],
...
);
DROP TABLE tableName;Mit diesen Befehlen erzeugt und löscht man eine Tabelle.
ALTER TABLE
ALTER TABLE tableName
ADD new_spaltenname sql_data_types [constraints];
ALTER TABLE tableName
DROP COLUMN spaltenname1;
ALTER TABLE tableName
MODIFY COLUMN spaltenname1 sql_data_types [constraints];Mit diesen Befehlen ändert man eine bestehende Tabelle.
1.Aufgabe
Lege eine Datenbank Filme an!
3.Aufgabe
Befülle alle Tabellen mit den gleichen Werten aus dem Skript!
2.Aufgabe
Erstelle alle normalisierten Tabellen lt. Skript, also:
- Filme
- Regisseure
- Dauer
- FilmRegisseure
Hinweis
Wenn im ersten CREATE Schritt etwas schiefgeht, versuche es mit ALTER Befehlen zu korrigieren.
SQL
DML
SELECT ... FROM ...
SELECT [DISTINCT][Aggregatfunktionen] ...
FROM ...
[ JOIN ... ON ... ]
[ WHERE ... ]
[ GROUP BY ... HAVING ... ]
[ ORDER BY ... [ASC/DESC]]SELECT
SELECT titel FROM Filme;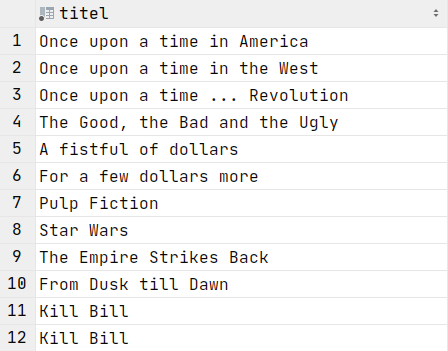
SELECT DISTINCT
SELECT DISTINCT titel FROM Filme;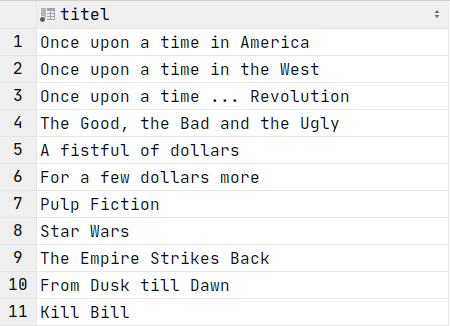
SELECT * FROM ...
SELECT * FROM Filme;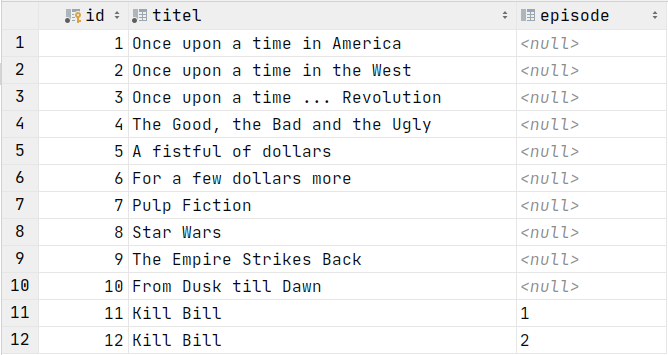
Das Sternchen * heißt hier Asterisk und wird als Platzhalter für alle Attribute verwendet.
Mehrere Attribute
SELECT titel, episode, id FROM Filme;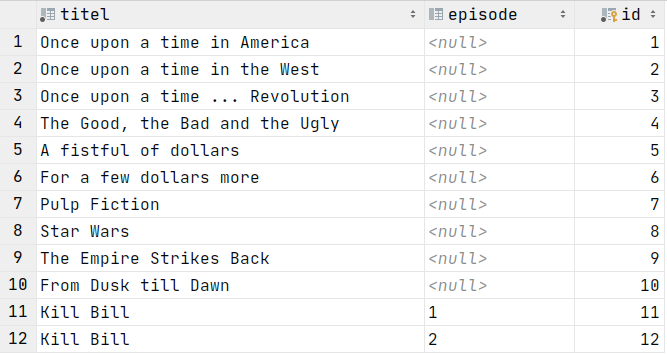
SQL kann noch mehr...
SELECT titel, 12*3, ln(1), 'Hallo' FROM Filme;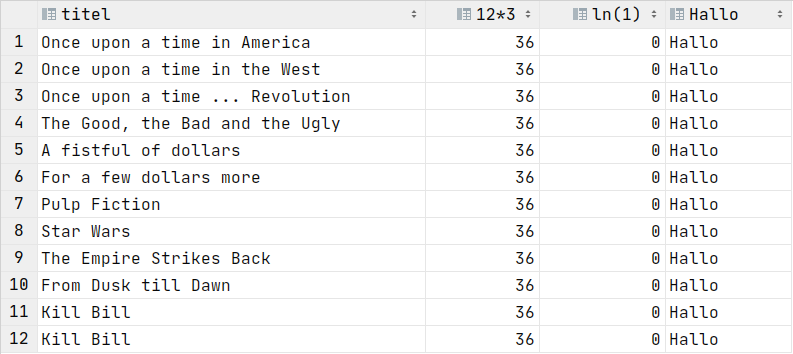
Aliase
SELECT titel AS Filmtitel FROM Filme;
Aggregatfunktionen
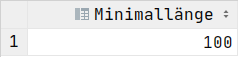
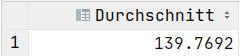
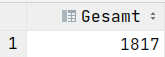
SELECT COUNT(*) AS Anzahl FROM Dauer;SELECT MAX(dauer) AS Maximallänge FROM Dauer;SELECT MIN(dauer) AS Minimallänge FROM Dauer;SELECT AVG(dauer) AS Durchschnitt FROM Dauer;SELECT SUM(dauer) AS Gesamt FROM Dauer;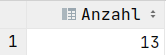
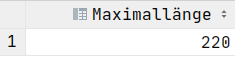
...WHERE...
SELECT * FROM Dauer WHERE dauer > 150;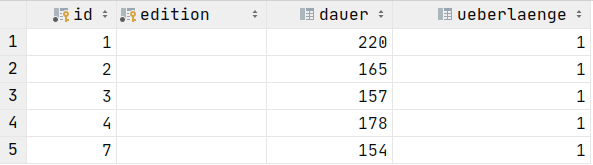
Operatoren
SELECT * FROM Dauer WHERE dauer = 100;
SELECT * FROM Dauer WHERE dauer IN (131,132,133);
SELECT * FROM Dauer WHERE dauer BETWEEN 100 AND 120;
SELECT * FROM Dauer WHERE dauer >= 155;
SELECT * FROM Dauer WHERE dauer > 150;
SELECT * FROM Dauer WHERE dauer != 100; -- Manchmal auch <>Logische Operatoren
SELECT * FROM Dauer WHERE dauer = 100 OR dauer > 150 AND ueberlaenge = 1;
Es gilt die Punkt-vor-Strich - Regel:
AND geht vor OR
Andernfalls müssen wir Klammern setzen.
LIKE und die Wildcards
SELECT * FROM Filme WHERE titel LIKE 'From Dusk till Dawn';
SELECT * FROM Filme WHERE titel LIKE 'From Dusk _ill Dawn';
SELECT * FROM Filme WHERE titel LIKE 'From%';_ repräsentiert genau 1 Zeichen.
% repräsentiert 0, ein oder beliebig viele Zeichen
1.Aufgabe
Finde alle IDs der Filme von Sergio Leone heraus!
3.Aufgabe
Finde alle Regisseure heraus, die Filme ohne Überlänge produzierten!
2.Aufgabe
Finde alle Sergio Leone - Filme, die länger als 3h gehen!
4.Aufgabe
Finde alle Regisseure, deren Filme einen (bestimmten/unbestimmten) Artikel enthalten!
Bisher ...
SELECT [DISTINCT][Aggregatfunktionen] ...
FROM ...
[ JOIN ... ON ... ]
[ WHERE ... ]
[ GROUP BY ... HAVING ... ]
[ ORDER BY ... [ASC/DESC]]Mehrere Tabellen
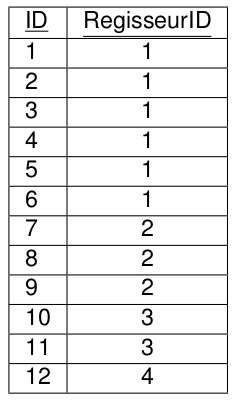
SELECT * FROM Filme, Regisseure;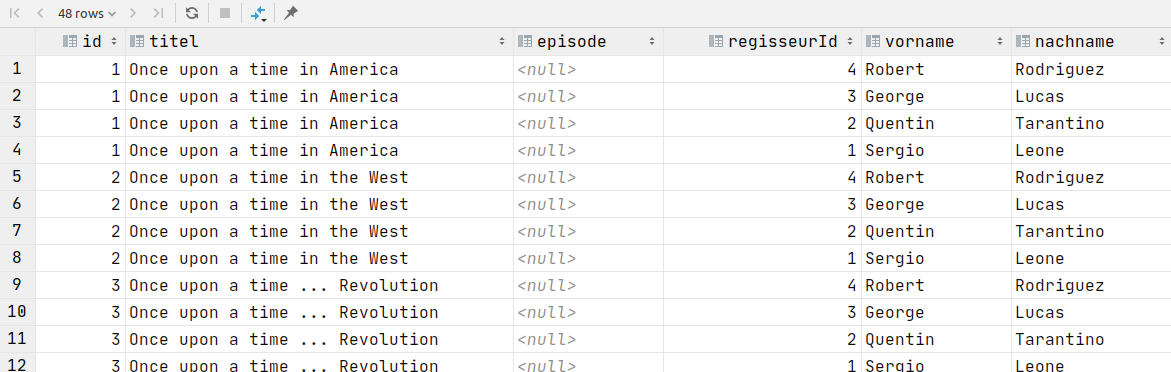
Mehrere Tabellen
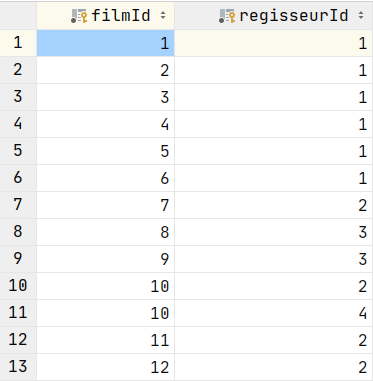
SELECT COUNT(*) FROM Filme, FilmRegisseure, Regisseure;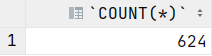
Wir haben 12 Filme in der Datenbank.
Wir haben 4 Regisseure.
Es gibt 13 Zuordnungen von Regisseuren zu Filmen.
12 * 4 * 13 = 624.
Verküpfungen schaffen...
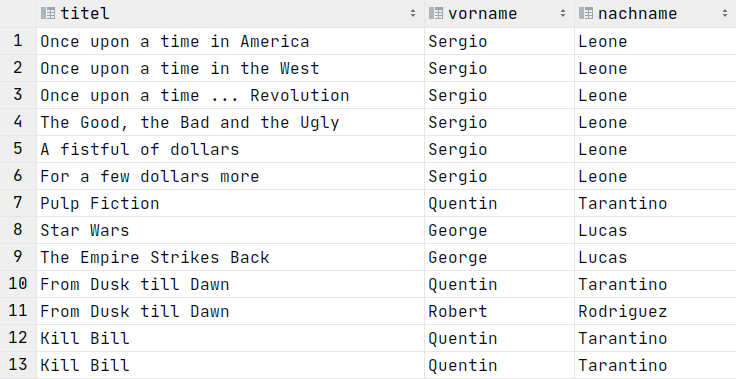
SELECT Filme.titel, Regisseure.vorname, Regisseure.nachname
FROM Filme, FilmRegisseure, Regisseure
WHERE Filme.id = FilmRegisseure.filmId
AND FilmRegisseure.regisseurId = Regisseure.regisseurId;
Mit Aliases arbeiten
SELECT f.titel, r.vorname, r.nachname
FROM Filme AS f, FilmRegisseure AS f2r, Regisseure AS r
WHERE f.id = f2r.filmId
AND f2r.regisseurId = r.regisseurId;
...Ergebnisse liefern!
Joins
SELECT f.titel, r.vorname, r.nachname
FROM Filme AS f
JOIN FilmRegisseure AS f2r ON f.id = f2r.filmId
JOIN Regisseure AS r ON f2r.regisseurId = r.regisseurIdNatural Join
SELECT f.titel, r.vorname, r.nachname
FROM Filme AS f
JOIN FilmRegisseure AS f2r ON f.id = f2r.filmId
NATURAL JOIN Regisseure AS r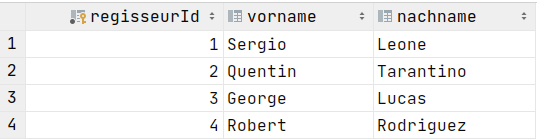
Arten von JOINs
- NATURAL JOIN
- (Inner) JOIN
- Outer JOINs
- LEFT JOIN
- RIGHT JOIN
- FULL JOIN
Left Join
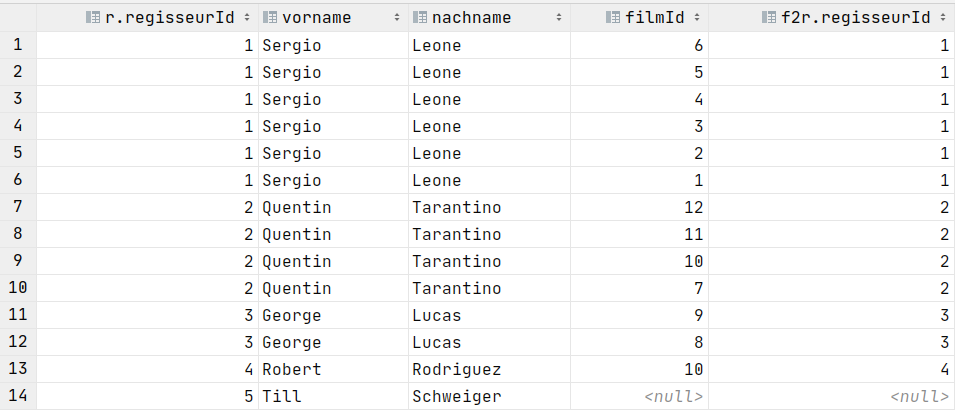
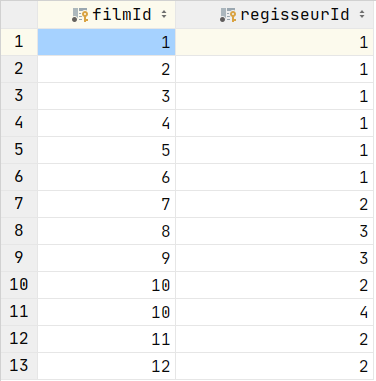
SELECT *
FROM Regisseure AS r
LEFT OUTER JOIN FilmRegisseure AS f2r
ON r.regisseurId = f2r.regisseurId;Full Join
SELECT * FROM Regisseure AS r FULL OUTER JOIN FilmRegisseure AS f2r;Leider wird der FULL JOIN in MySQL NICHT unterstützt, weshalb wir eine Alternative benötigen...
SELECT * FROM ...
UNION ALL
SELECT * FROM ...Union
SELECT value1 FROM table1
UNION
SELECT value2 FROM table2;UNION führt zwei Abfrageresultate zusammen und streicht gleiche Datensätze.
SELECT value1 FROM table1
UNION ALL
SELECT value2 FROM table2;UNION ALL führt zwei Abfrageresultate zusammen und streicht gleiche Datensätze NICHT.
Bisher ...
SELECT [DISTINCT][Aggregatfunktionen] ...
FROM ...
[ JOIN ... ON ... ]
[ WHERE ... ]
[ GROUP BY ... HAVING ... ]
[ ORDER BY ... [ASC/DESC]]Groups
Group By
SELECT r.vorname, r.nachname, COUNT(f2r.regisseurId)
FROM Regisseure AS r
LEFT JOIN FilmRegisseure AS f2r ON r.regisseurId = f2r.regisseurId
GROUP BY r.regisseurId
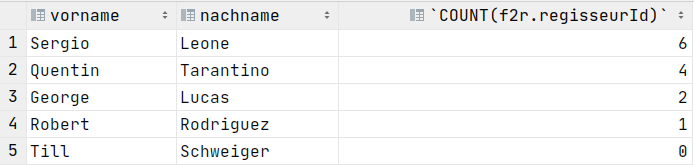
Having
SELECT r.vorname, r.nachname, COUNT(f2r.regisseurId)
FROM Regisseure AS r
LEFT JOIN FilmRegisseure AS f2r ON r.regisseurId = f2r.regisseurId
GROUP BY r.regisseurId
HAVING COUNT(f2r.regisseurId) > 3

Order By
SELECT vorname, nachname
FROM Regisseure
ORDER BY nachname DESC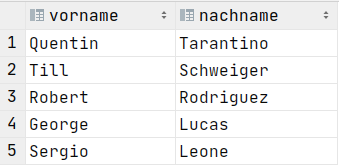
Union
SELECT vorname, nachname FROM Regisseure
UNION
SELECT vorname, nachname FROM Schauspieler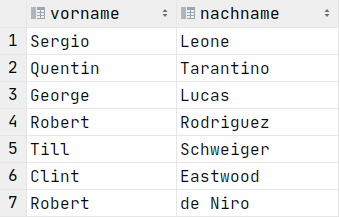
Exists
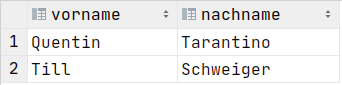
SELECT r.vorname, r.nachname FROM Regisseure AS r
WHERE
EXISTS(
SELECT *
FROM Schauspieler AS s
WHERE s.vorname = r.vorname AND s.nachname = r.nachname
)
Any / All
SELECT r.vorname, r.nachname
FROM Regisseure AS r
WHERE r.regisseurId =
ALL (
SELECT r.regisseurId
FROM Filme AS f
JOIN FilmRegisseure AS f2r ON f.id=f2r.filmId
JOIN Regisseure AS r on f2r.regisseurId = r.regisseurId
JOIN Dauer AS d ON d.id = f.id
)ANY und ALL Subselects müssen mit einem Vergleichsoperator verknüpft werden,
also =, != bzw. <>, <,>,<=,>=
Case Statements
CASE
WHEN bedingung1 THEN ergebnis1
WHEN bedingung2 THEN ergebnis2
WHEN bedingung3 THEN ergebnis3
ELSE standardergebnis
ENDINSERT INTO ... VALUES
INSERT INTO Tabellenname [(spaltenname1, spaltenname2, ...)]
VALUES (spaltenwert1, spaltenwert2, ...)INSERT INTO Tabellenname [(spaltenname1, spaltenname2, ...)]
SELECT ...Alternativ kann auch ein Abfrageergebnis eingefügt werden:
DELETE FROM...
DELETE FROM Tabelle
[WHERE ...]Ohne WHERE - Bedingung werden ALLE Datensätze der Tabelle gelöscht.
UPDATE
UPDATE Tabelle
SET spalte1=wert1, spalte2=wert2, ...
[WHERE ...]Ohne WHERE - Bedingung werden ALLE Datensätze der Tabelle aktualisiert.
Es können 1 bis n Spalten aktualisiert werden.
SQL
DCL
GRANT / REVOKE
GRANT {ALL|EXECUTE|SELECT|andere Privilegien}
ON Tabellenname
TO {Benutzername|PUBLIC|Rollenname}
[WITH GRANT OPTION]REVOKE {ALL|EXECUTE|SELECT|andere Privilegien}
ON Tabellenname
FROM {Benutzername|PUBLIC|Rollenname}Relationale Datenbanksysteme
Sonstiges
Transaktionen
Eine Datenbanktransaktion besteht aus einer Gruppe von Teilaktionen, die in einer oder mehreren Datenbanktabellen erfolgreich ausgeführt werden müssen, bevor sie endgültig festgeschrieben (Commit) werden können.
try {
...
conn.setAutoCommit(false);
// INSERT, UPDATE, DELETE
// passieren hier
// und werfen ggf. SQL-Exceptions
// Wenn alles ok ist, ...
conn.commit();
} catch(SQLException e) {
// ...andernfalls
conn.rollback();
}Schlägt eine der Teiltransaktionen in der Gruppe fehl, werden alle anderen Teilaktionen ebenfalls rückgängig gemacht (Rollback).
A tomicity
C onsistency
I solation
D urability
Datenbank Indices
Ein Datenbank Index beschleunigt die Suche nach Werten in den indizierten Feldern
CREATE [UNIQUE] INDEX <index name>
ON <table name> (<column(s)>);Nachteil:
Beim Einfügen neuer Datensätze verschlechtert die Indizierung die Performanz.
Ausgangssituation

No Index:
Nach dem (wahllosen) Einfügen neuer Datensätze braucht es für die Suche eines bestimmten Elements meist:
n / 2 - viele Zugriffe
,wobei n die Anzahl aller Elemente ist.
Wir nennen dies: O(n) "Landau Notation"
Die Dauer wächst linear mit der Anzahl der eingefügten Elemente.
B-Tree
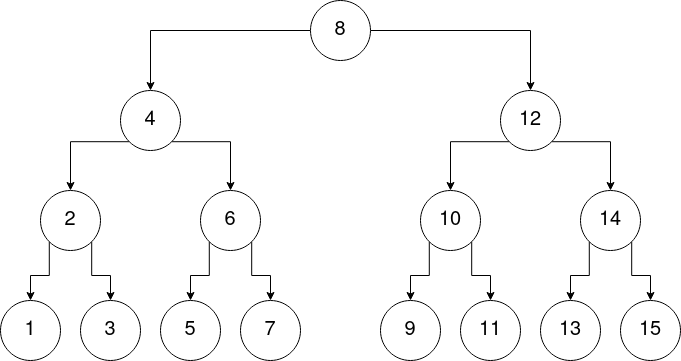
Ein Binärbaum ist so aufgebaut, dass nach einer festzulegenden Regel, manche Elemente links und manche rechts einsortiert werden.
Hier:
kleinere Elemente -> links
größere Elemente -> rechts
Endsituation
With Index:
Hier braucht es für die Suche eines bestimmten Elements meist:
log(n) - viele Zugriffe
,wobei n die Anzahl aller Elemente ist und log der Logarithmus zur Basis 2.
Wir nennen dies: O(log(n))
| n | O(n) | O(log(n)) |
|---|---|---|
| 100 | 100 | 6 |
| 10000 | 10000 | 14 |
| 1.000.000 | 1.000.000 | 20 |
| 1.000.000.000 | 1.000.000.000 | 30 |