/(Every|some)thing you wanted to know about RegEx/

This talk will:
- Start very theoretical
- End very practical
- Hopefully something for everyone
clear up a term
"Regular Expression"
"Regex"
"Regexp"

What is "language"?
"language" is the ability to use and acquire systems of communication
"a language" is an implementation of one of those systems
Grammar
Rules for the structure of the language, and how that translates to MEANING
Syntax
Rules for more nuanced differentiation in meaning:
active vs passive
declarative vs imperative
Grammar is the difference between "Dog bites man" and "Man bites dog."
subject verb object
I have.
Rule: Independent Clauses contain a Subject, verb
IC = S, V
I have the high ground.
, and optional object
, O*
A combination of symbols that represents a grammar rule is an
expression
IC = SVO*
Note: a regular language is a language that has a well defined and strict grammar
Many spoken languages are not regular, because humans.
So an expression that defines the grammar of a regular language is a
Regular Expression
Pivot
What is a grammar, in the context of a programming language?
programming languages as Languages
Sets of rules (grammars) which defined what keywords, expressions, characters can appear in what order, and what the meaning is of those things.
For example:
An expression is anything that can be on the right of an equals sign.
const a = b + 3
expression
Recursive Definition
Exp =:: Exp
Exp =:: Exp + Exp
Exp =:: Exp - Exp
Exp =:: (Exp)
Exp =:: Exp && Exp
Exp =:: Exp || Exp
Exp =:: ! Exp
State Machines
Any computer program can be modeled as a "state machine", shown as a graph with edges and nodes
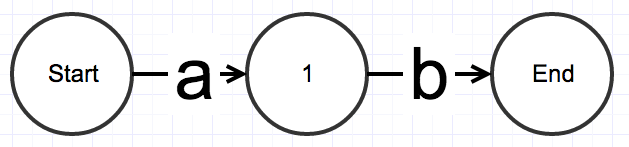
Input to a state machine moves the current state from Start to End
State Machines === Regular Expressions
ab
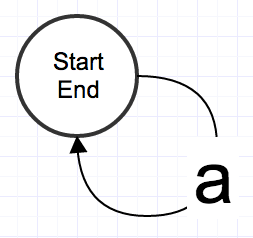
a*
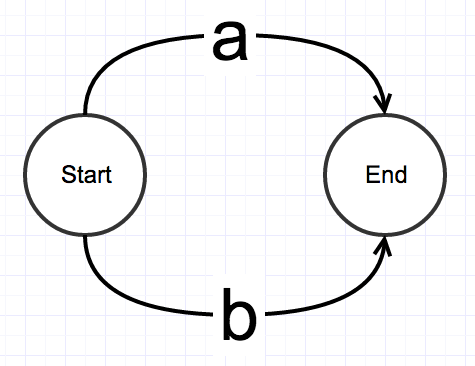
a|b
state machines
validate input
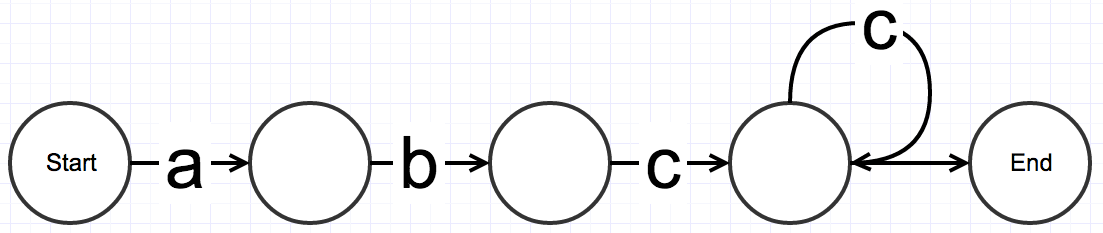
"abc"
"abc...c"
"ab"


End
Takeaway
A regular expression is a definition of a language grammar
State machines validate input for a regular expressions
Valid input == part of a language
Pivot
Epiphany: Hey, we can use this for pattern matching!
When you define a regular expression for a string, you are (behind the scenes) defining a grammar for a new language that the string is a part of
is a regular expression for the grammar of a language in which "Hello There!" is the only valid entry

anatomy of regular expressions
/Hello There!/gi
Pattern:
a set of characters which describe possible matches (or rather, described the grammar of a language which words may or may not be a part of)
Flags:
describe the way that the pattern should be applied to possible matches
global
ignore case
multi-line
/Hello There!/
Characters:
character literals on which to match
Metacharacters:
provide instructions on how to interpret characters

metacharacters
"no"
/no/
"nooo"
/nooo/
"nooo"
/no{3}/
"no...o"
/no{3,10}/
"no..."
/no{3,}/
"no..."
/no{1,}/
"n..."
/no*/
quantifier
any
"n..."
/na{0,}/
"no..."
/no+/
one or more

metacharacters
"abc"
/abc/
"abc"
/[abc]*/
"abcd"
/[a-d]*/
"abYZ"
/[a-zA-Z]*/
"aB123"
/[a-zA-Z0-9]*/
"aB123"
/\w*/
set
word character
set and range
"a3ç∂eƒ"
/[a-zA-Z0-0\W\s]*/
"a3ç∂eƒ"
/.*/
any character
metacharacters
quantifiers
{n,n}
* any of
+ one or more
? zero or one
sets, ranges
[n-n]
\w alphanumeric
\d digit
\W symbol
grouping
(nn)
(nn) capture
(?=nn) non-capture
^ start of word
$ end of word
| or
how regular expressions are applied strings
consider
"Dexter Jettster"
"Dexter"
Greediness



Greediness
Regular expressions by default will match the longest string possible
consider
"<p>TO͇̹̺ͅƝ̴ȳ̳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡</p>"
match as few characters as possible
"<p>TO͇̹̺ͅƝ̴ȳ̳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡</p>"
Laziness

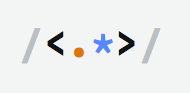
Let's build one
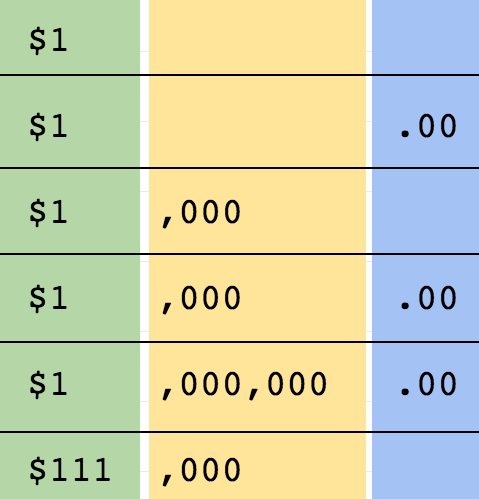
currency
Should validate these:
$1 $1.00 $1,000 $1,000,000.00
And invalidate these
$1, $1,00 $11,00
Version: 1
- A currency symbol
- One or more digits
- Zero or one:
- period followed by 2 digits

$1
$1.00
$1,000
$1,000.00
Let's step back and plan this out
$0.10
$1
$1.10
$1,000
$1,000.00
$100,000,000
$0 .10
$1
$1 .10
$1 ,000
$1 ,000 .00
$111 ,000,000
$1,
$1,00
1.00
$11,00
$01,000
$00,000
$1 ,
$1 ,00
1 .00
$11 ,00
$01 ,000
$000 ,000
Currency Symbol
1-3 digits
(no leading 0 unless it is the only character)
0 or more groups of a comma and 3 digits
0 or 1 of a period and 2 digits
Currency Symbol
1-3 digits (no leading zeros)
0 or more: groups of a comma and 3 digits
0 or 1 of: a period and 1 or 2 digits
\$(0|[1-9][0-9]{0,2})
(,\d{3})*
(\.\d{1,2})?
Version: 2
- implement 3 rules
- add start and end characters
$1
$1.00
$1,000
$1,000.00

$1,
$1,00
$01.00
$00,000.00
Let's build one
Date:
MM/DD/YYYY
M/D/YYYY
Version: 1

1 or 2 digits
a slash
1 or 2 digits
a slash
4 digits
allows:
1/1/2018
11/12/2018
99/99/9999
Version: 2
A group of
- "0" and a single 1-9 digit
- OR a "1" and single 0-2 digit
A slash
A group of
- an optional "0" and a single 1-9 digit
- OR "12"
A slash
4 digits
allows:
1/1/2018
11/12/2018
Fails:

99/99/2018
11/12/0000
211/12/20189
Version: 3
Start of word
A group of
- "0" and a single 1-9 digit
- OR a "1" and single 0-2 digit
A slash
A group of
- an optional "0" and a single 1-9 digit
- OR "12"
A slash
"19" or "20 and any 2 digits
End of word
allows:
1/1/2018
11/12/2018
Fails:
99/99/2018
11/12/0000
211/12/20189

Leap year!
But wait...
^(((0[1-9]|[12][0-9]|3[01])[- /.](0[13578]|1[02])|(0[1-9]|[12][0-9]|30)[- /.](0[469]|11)|(0[1-9]|1\d|2[0-8])[- /.]02)[- /.]\d{4}|29[- /.]02[- /.](\d{2}(0[48]|[2468][048]|[13579][26])|([02468][048]|[1359][26])00))$
Let's build one
email address
A word character, hyphen, underscore, or period
an @ symbol
1 or more word characters
a period
between 2 to 5 word characters

international TLD
like .co.uk
an ip address instead of a domain
spaces inside quotation marks
comments inside parenthesis (WHAT?)
international characters or 😀.com
Uhhh...
rfc822 email address

or
/.+@.+/
then send a confirmation link
Recap
- Language and Grammar
- Expressions == state machines == languages
- Building blocks of Regular Expressions
- Lazy vs Greedy
- Creating a regex, planning
- Nail & Hammer problems
/b?eg?i?n?ni?n?g?d?/
"end"
"beginning"
Thank you!
References
usd currency parsing https://regexr.com/3ivk1
metacharacters https://help.relativity.com/9.0/Content/Relativity/Regular_expressions/Regular_expression_metacharacters.htm
RFC Email spec http://www.ex-parrot.com/~pdw/Mail-RFC822-Address.html
regular languages https://nikic.github.io/2012/06/15/The-true-power-of-regular-expressions.html
lea verou regex talk https://www.youtube.com/watch?v=EkluES9Rvak
greedy vs lazy https://www.regular-expressions.info/repeat.html
parsing regular expressions http://matt.might.net/articles/parsing-regex-with-recursive-descent/