Replication
Reasons
- keep data close to end-users - reduce latency
- continue working if some parts failed - increase availability
- scale-out number of machines to serve read queries - increase read throughput
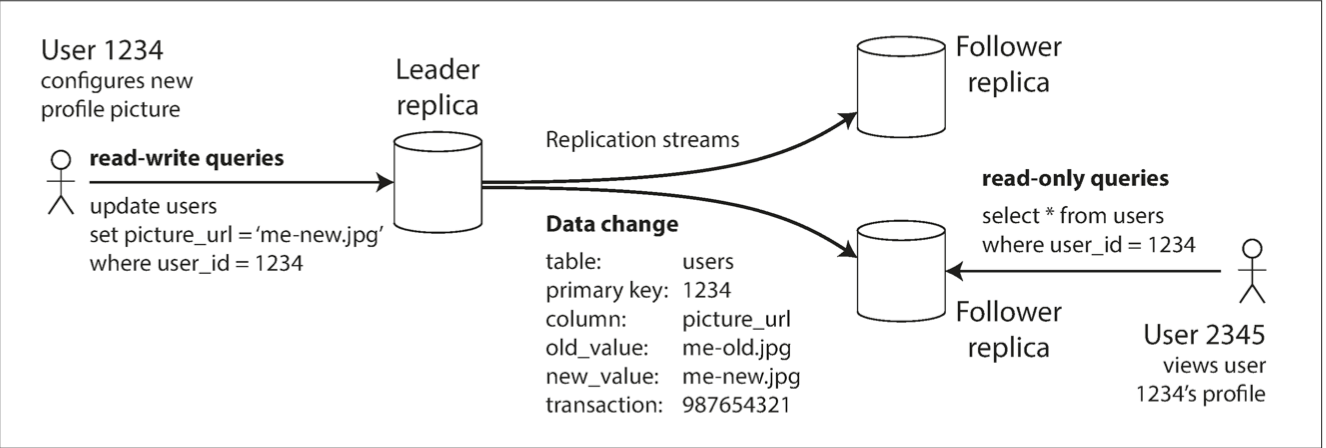
Leader Based (active/passive)
write requests are sent to the Leader
Leader on each write sends new data to Followers through replication log or change stream
Followers apply all writes in the same order
Reads are done by either Leader or Followers
Sync vs Async
Sync
- slows down write throughput
- cannot be completed if the follower is unavailable
- in practice (semi-sync): one is async, and the others are async. If sync failed then one of the asyncs is promoted to be sync
Async
- if leader fails then writes might be lost
the delay between a write happening on the leader and being reflected on a follower—the replication lag
Chain Replication (TBC)
2nd Problem: disk storage limitations
since we only append to the log but do not delete it will grow infinitely
solution: break the log into segments of specific size by closing a segment file when it reaches a particular size, and making subsequent writes to a new segment file
compaction - removing duplicate values within a segment

Setting up Follower & Failures
1. take a snapshot and create a replica
2. follower requests all changes starting from the snapshot (log sequence number, binlog coordinates)
Follower failure: keep log of updates. When recovered - request updates from the last in the log
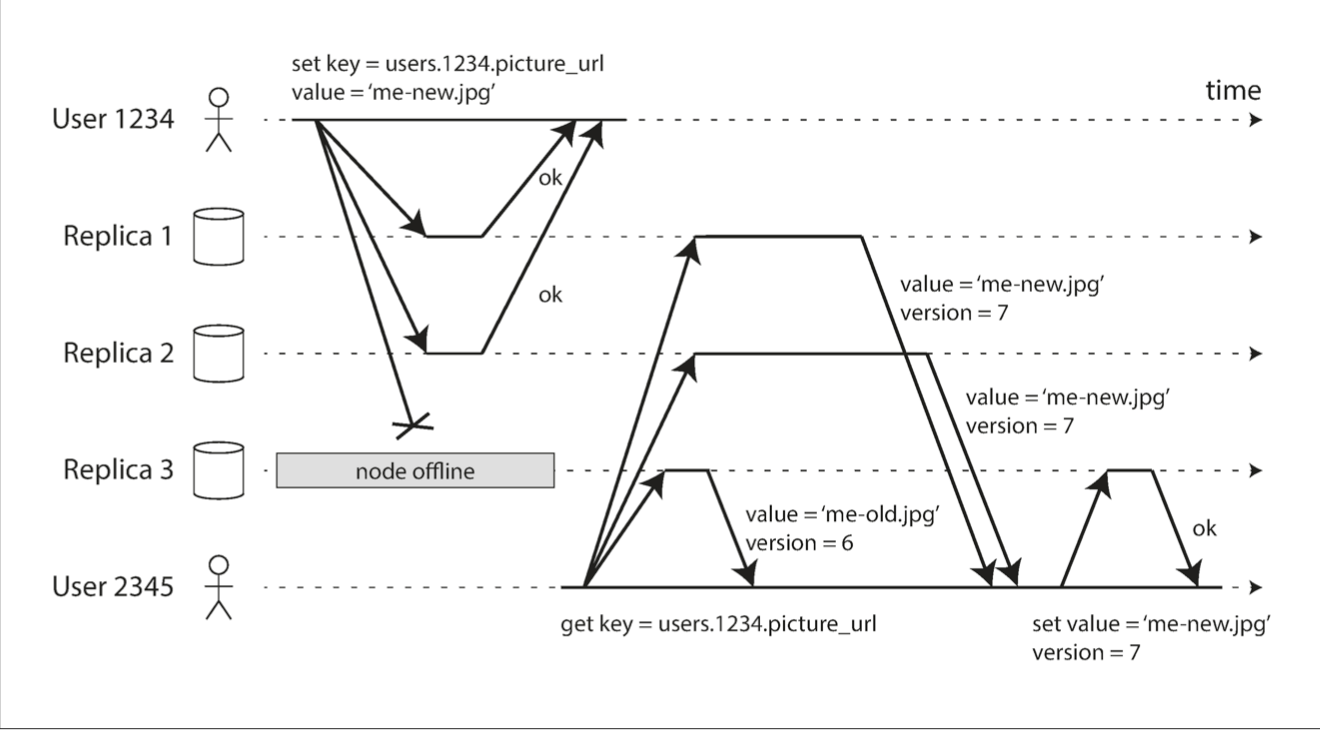
Leader failure (failover):
- determine that leader failed (health checks)
- choose new leader
- reconfiger system to new leader
Failover problems
Problems:
- leader revives, and recently promoted follower doesn't have all writes from old leader (normally discarded)
- discarded writes are sent to other systems (github sent primary keys to redis)
- 2 nodes think they are leaders (split brain) - issue because no conflict resolution in place. Can be solved with fencing - when all but one leader are killed
- how to choose a health check timeout? If long then long time for recovery. If short then might lead to false positives
Replication Log types
Statement-based: all statements (REST) sent to followers and executed. Should be deterministic (not NOW or RAND). Order must be preserved. Side effects also shall be deterministic. Not used much anymore.
Write-ahead-log (WAL) shipping: sequence of bytes. Contains unnecessary low-level details like disk blocks making replicas coupled to the storage engine. If different versions of DB run on different storage engines then it might lead to issues. Because of this cannot update software one by one - which requires downtime.
Logical (row-based) log replication: different formats for storage (physical) and replication (logical) logs. A transaction that modifies several rows generates several such log records, followed by a record indicating that the transaction was committed. Can also be used for imports to other systems (change data capture).
Trigger-based replication: done on the application layer. Trigger changes to a special table which will be read by an external system. Prone to have many bugs but has great flexibility.
Replication Lag Problems
Read-your-write or read-after-write consistency: if writes to leader and reads from not up to date follower. Solutions: modifiable data (own profile) read from leader, others from follower; check last update date and based on that read from leader or follower; monitor replication lag on followers and do not read from those which very much outdated; client remembers timestamp and reads until gets response with same or a higher one. Another issue is cross-device read-your-write consistency: no data about recent update timestamp in the app; may connect to different data centers.
Monotonic read: several reads from different replicas showing up-to-date data first, and outdated data later. Solution: always route the same user to the same replica. Has to be rerouted if the replica fails though.
Consistent prefix reads: sequence of writes should be reading the same order (like a conversation in chat). Normally an issue with multiple partitions handling writes in parallel. Solution: keep track of causal dependencies.
Multi-Leader (active/active) replication
solves problems when a single reader fails, although autoincrementing keys, triggers, and integrity constraints can be problematic
makes sens only with async replicas between leaders otherwise could be implemented with a single one
multi-datacenter: reduces latency between client/server, and also for replication flows
clients with offline operation: each device is a leader since it accepts writes being offline
collaborative editing
Multi-Leader: resolving conflicts
conflicts do not arise immediately but later in time - which means no manual resolution by user
Approaches:
avoiding conflicts: partition writes to a particular leader (works only until one of the leaders fails)
converging conflicts: give write a unique ID(if timestamp then last write wins (LWW) approach; give replica an ID and use a value from the highest (most up to date) replica; merge values; record the conflict to be resolved later
custom application-level logic: on write, or on reading (when multiple versions returned for manual or automatic resolution)
Advanced Conflict Resolution
Conflict-free replicated datatypes (CRDTs): are a family of data structures for sets, maps, ordered lists, counters, etc. that can be concurrently edited by multiple users, and which automatically resolve conflicts in sensible ways. Some CRDTs have been implemented in Riak 2.0.
Mergeable persistent data structures: track history explicitly, similarly to the Git version control system, and use a three-way merge function (whereas CRDTs use two-way merges).
Operational transformation: is the conflict resolution algorithm behind collaborative editing applications such as Etherpad and Google Docs. It was designed particularly for concurrent editing of an ordered list of items, such as the list of characters that constitute a text document.
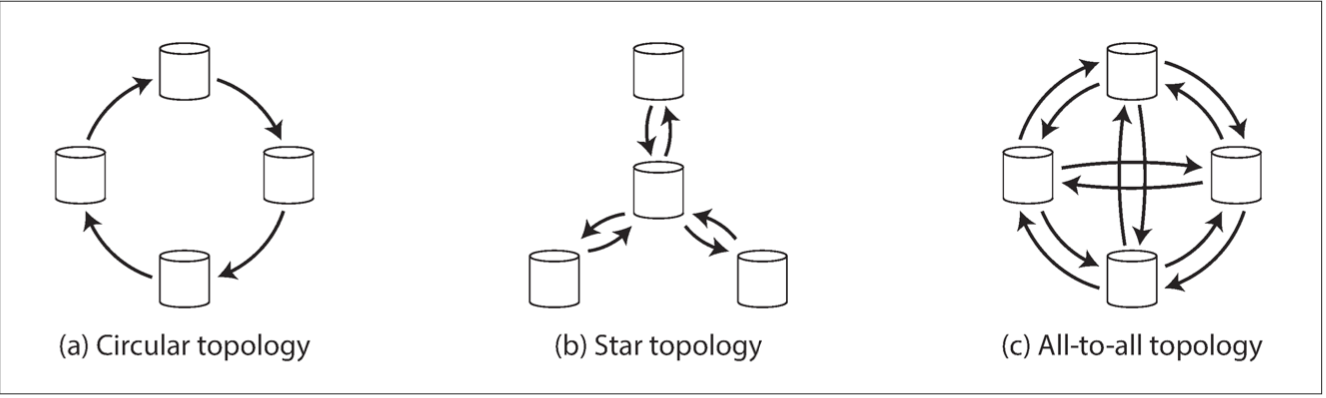
Topologies
most general: all-to-all
star topology can be generalized to a tree
To prevent infinite replication loops, each node is given a unique identifier, and in the replication log, each write is tagged with the identifiers of all the nodes it has passed through.
Circular and Star have issues if a node fails
All-to-all: writes can arrive in the wrong order
Multi-Leader
If you are using a system with multi-leader replication, it is worth being aware of these issues, carefully reading the documentation, and thoroughly testing your database to ensure that it really does provide the guarantees you believe it to have
Leaderless
Used in Dynamo DB hence is called Dynamo-style
client directly sends its writes to several (quorum) replicas + reads are done from several (quorum) replicas
or
a coordinator node does this on behalf of the client. However, unlike a leader database, that coordinator does not enforce a particular ordering of writes
Failover
Read repair: client reads from many replicas and updates stale data by looking at the version. Good for systems when reads happen often.
Anti-entropy process: background process that constantly checks for stale data. Unlike the replication log in the leader-based approach, it doesn't copy writes in a particular order.
Quorum
if there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read
As long as w + r > n, we expect to get an up-to-date value when reading, because at least one of the r nodes we’re reading from must be up to date.
a workload with few writes and many reads may benefit from setting w = n and r = 1. This makes reads faster, but has the disadvantage that just one failed node causes all database writes to fail.
Normally, reads and writes are always sent to all n replicas in parallel. The parameters w and r determine how many nodes we wait for
note: if multiple data-centers: important to understand if these numbers are defined within one data-center or across multiple
Quorum Problems
sloppy quorum: when more than n nodes (partitions) we can write/read to the node which normally doesn't hold the variable. Once correct nodes are back data is sent to them (hinted handoff). Increases write availability but also breaks stale read guarantees.
concurrent writes:
parallel reads and writes
if write succeded on less than w replicas, it will not be rolled back
a failed node may be restored from a replica with old data the number of writes would be less than w
Conflict Resolution Strategies
Last Write Wins (LWW): causes data loss. Works well if data is immutable: say generate uuid for each write.
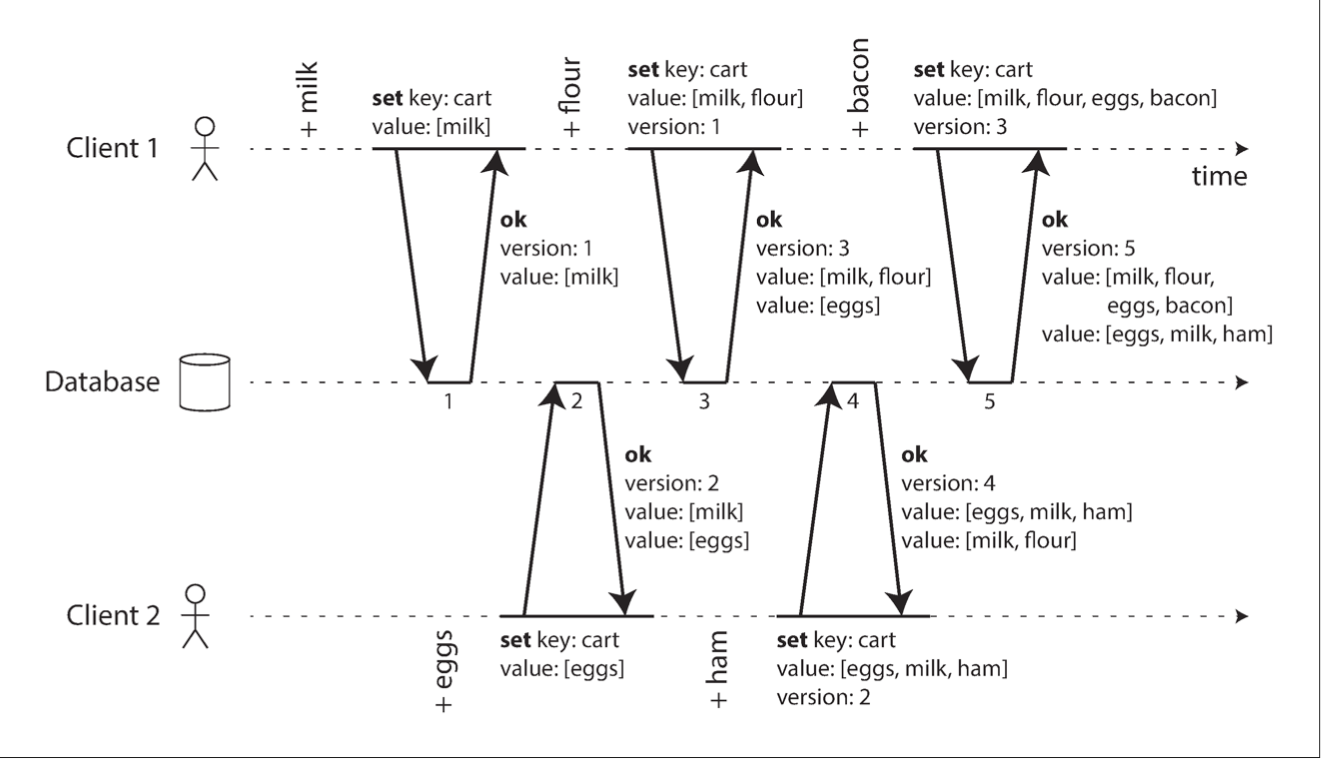
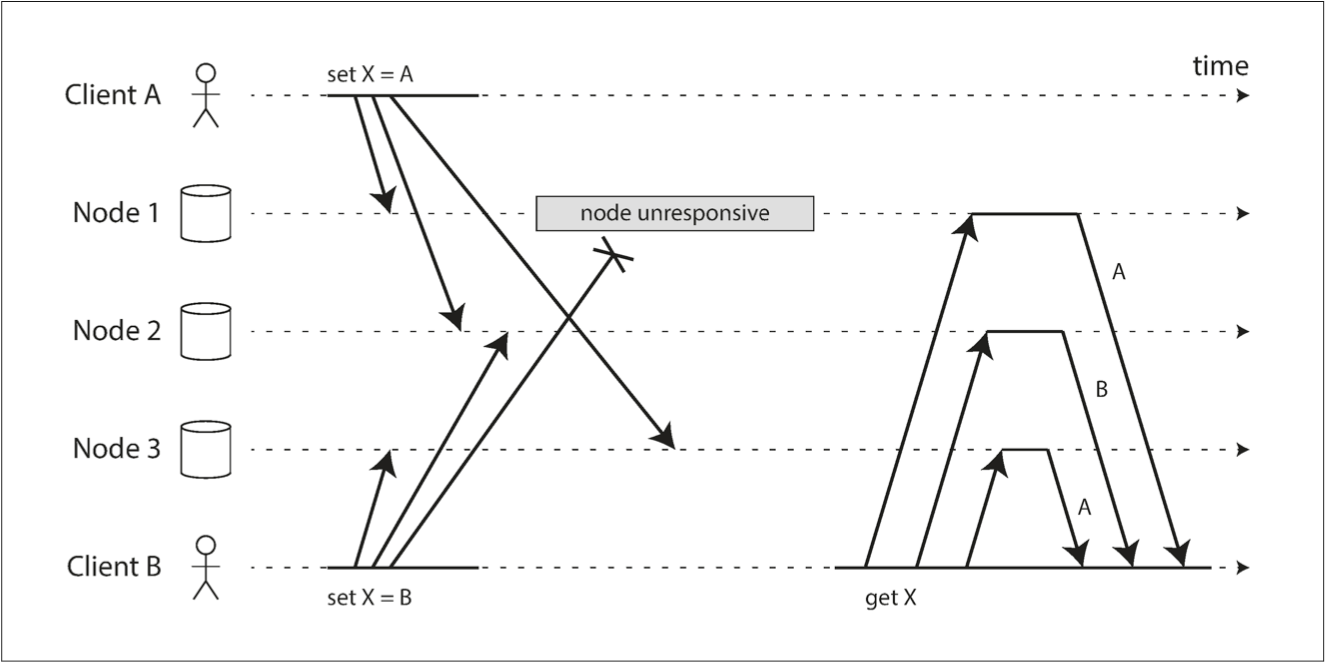
Casual dependency: on the left figure B is casually dependent on A. On the right figure they are independent
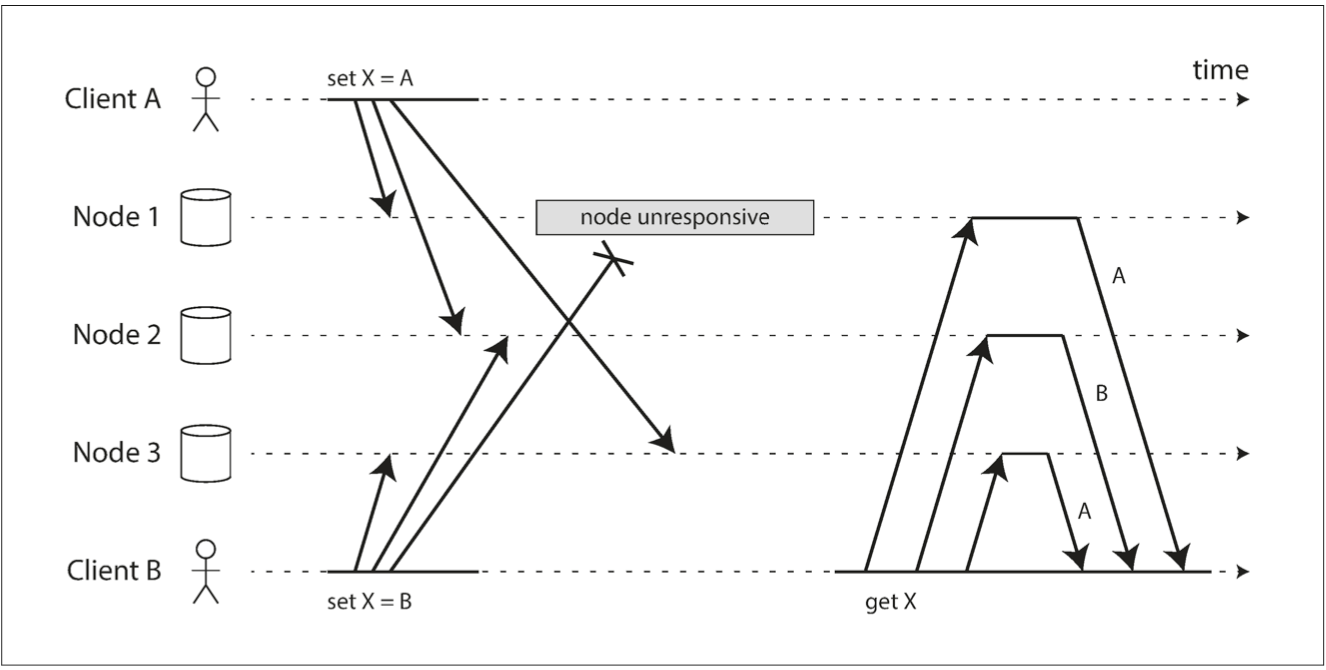
Casual Dependency
There are multiple versions of the same data (for multiple replicas use a vector)
A client must read a key before writing. The server returns all values + latest version
When performing a write, the client sends the version number it got on read. It also merges all values into one
Server overwrites all versions <= than the version received from the client leaving higher versions intact