GSA AGILE BPA PROTOTYPE IMPLEMENTATION
6/21/2015 - 6/30/2015 Timelines

Project Peachtree
Peachtree application is targeted towards the general public and aims to disseminate high level data made available through OpenFDA. Users can explore:
- Top drugs and devices by reported adverse events grouped by type/brand.
- The States that have the most food recalls.
- The ability to search for a brand name drug and see what the most common symptoms reported are.
Scope
Project Peachtree
This project was managed using Agile Methodology Scrum Framework and planned around Product Backlog.
For planning purposes it was divided into sprints each being one day in length and every two consecutive sprints result in a release.
The CodeBase is housed openly on GitHub under the repository found here: https://github.com/NETESOLUTIONS/peachtree
Scope
Project Peachtree
• Assemble the team together
• Create a Repository in GitHub
• Identify the functional requirements for the prototype and create/manage a product backlog
• Study the existing tools providing similar result sets and identify the target audience
• Identify 3 “Human Centered Design” Techniques and Tools
• Study/Analyze the FDA DataSets and APIs
• Create a Technical Architecture Diagram
• Create a working design prototype
• Implement the User Stories based on priority as part of daily sprints
• Write Unit tests for the code
• Setup continuous integration system to automate running of tests
• Set up Continuous monitoring
• Perform usability tests with people
• Create documentation to install and run the prototype
Project Management Tasks
Project Peachtree
• Build a system/tool to report side effects of adverse Drugs, Vaccines and Devices
• User Profile Management – User authentication and Authorization – High Priority (Moved to later sprints)
• Provide Summary visualizations in form of charts for all 3 entities – High Priority
• Get Top 10 drug names by AE count – High Priority
• Provide Item details including the effects and when it was reported – Medium priority
• Ability to report a side effect – Medium priority
• Search Products (Drugs, Vaccines and Devices) with Adverse Effects – LOW Priority
• Ability to add alerts for a specific entity for updated AE – Low priority
• Provide Filter capability – Low Priority
• Get count of patient reactions related to a drug – Low priority
• Return the list of All Drugs – High Priority
• Build a page with Food recalls – Add summary visualization for Top 10 recalls per state – Medium priority
• Add sort filter on Drugs Page – Medium priority
List of Requirements
Project Peachtree
Timeline

June 2015
21
• Identify Scope and Data Sets
• Put the team together
• Setup GitHub repository
Project Kickoff Meeting
Project Peachtree
Timeline
June 2015
22
• Setup the Project framework
• Create the Team channel in Slack
• Develop the use case - Display Top 10 Drugs by adverse events reported.
• Framework added to repository
Sprint 1
Project Peachtree
Timeline
June 2015
23
• Develop the use case - User profile authentication
• Create working design prototype for Backlog Items
• Set up Continuous Monitoring
• Create wireframes for Sprint 3 and Sprint 4 Items
• Start the usability tests
Sprint 2
Project Peachtree
Timeline
June 2015
24
• Develop the use case – Design and Implement Dashboard
• Develop the use case - Visualize summary charts (adverse effects) for drugs and devices
• Deploy to cloud using Heroku
• Start working on Digital Playbook checklist
Sprint 3
Project Peachtree
Timeline
June 2015
25
• Develop use case – Visualize summary charts for Top 10 food recalls per US state
• Setup PostGres SQLDB
• Design PeachTree Icon and integrate
• Publish the complete set of usability tests
• Update US Digital Service Playbook Checklist
Sprint 4
Project Peachtree
Timeline
June 2015
26
• Perform regression tests
• Develop Use case – Drugs Page reporting Adverse Effects
• Integrate the database with application for future enhancements
• Develop Use case – Map visualization for Food Recalls
Sprint 5
Project Peachtree
Timeline
June 2015
29
• Develop the use case - Map Visualization
• Complete Digital Services Playbook
Sprint 7
Project Peachtree
Timeline
June 2015
30
• Develop the use case - User authentication and authorization
Sprint 8
Project Peachtree
Tech Stack and Tools
- Server Side
- Data Back End
- Client Side
- UI Frameworks/Font Libraries
- Hosting
- Other Tools
Project Peachtree
Architecture Diagram
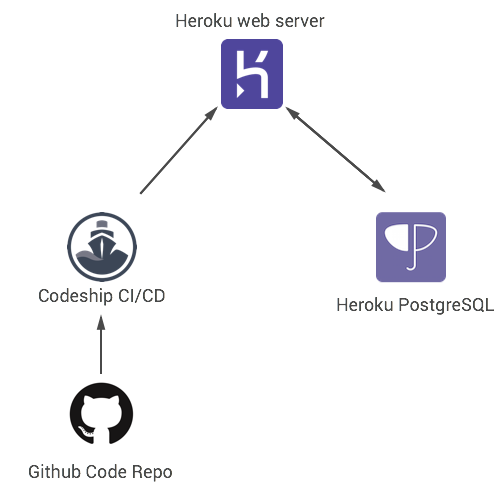
* Note all images are property of Heroku, Codeship and Github.
Commits trigger Codeship to run automated tests after cloning the repository
Code is hosted on Github Repository
If all tests are succesfull the code is deployed to the heroku webserver
Finally a cloud backend is bundled with the web server to facilitate persistent data storage
Project Peachtree
Assumptions & Constraints
Displayed Adverse effects are reported by end users and maintained by the FDA. NETE is not responsible for any inaccuracies inherent in the data.
APIs released are fully tested and will exist for the duration of the BPA assessment effort.