RESILIENCE PATTERNS
What is resilience?
AWS: “The capability to recover when stressed by load (more requests for service), attacks (either accidental through a bug, or deliberate through intention), and failure of any component in the workload’s components.”
Ability to handle unexpected errors and failures, recover from those failures, and maintain a consistent level of performance despite external challenges.
Main goal is build robust components that can tolerate faults within their scope.
The more components a system has, the more likely it is that something will fail.
Libraries for resilience patterns
# RESILIENCE
- Resilience4j is a lightweight Java library for creating resilient and fault-tolerant applications.
- Hystrix, a library developed by Netflix, is considered deprecated.
- Polly is a library for handling resilience and transient faults in .NET.
- Go-resilience is library in Golang
# RESILIENCE
| Polly | Resilience4j |
|---|---|
| C# | Java |
| Dynamic configuration - allowing runtime changes to resilience policies without modifying source code | Static configuration - often relying on annotations. Well-suited for applications with relatively stable policy requirements |
| Offers integrations with various .NET monitoring and metrics systems | Includes built-in support for monitoring |
Key differences between Polly and Resilience4j :
- Reactive (Responding to failure after they occur)
- Proactive (Preventing, optimizing failures)
Two types of resilience patterns:
Reactive patterns
# RESILIENCE
Respond to issues and challenges after they occur, such as error handling, recovery mechanisms, and failover procedures.
Retry
1.
Wait and retry
2.
Circuit Breaker
3.
Fallback
4.
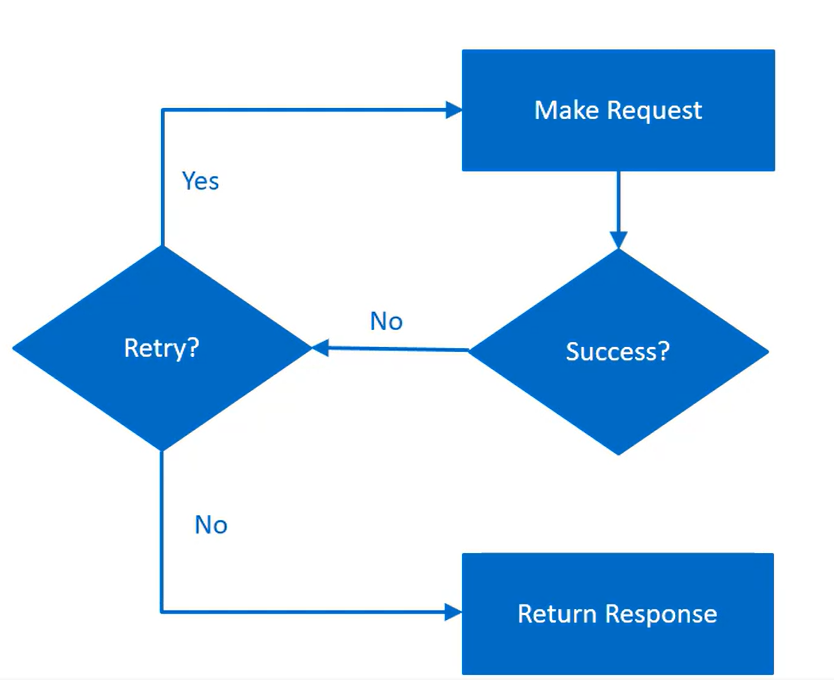
Retry
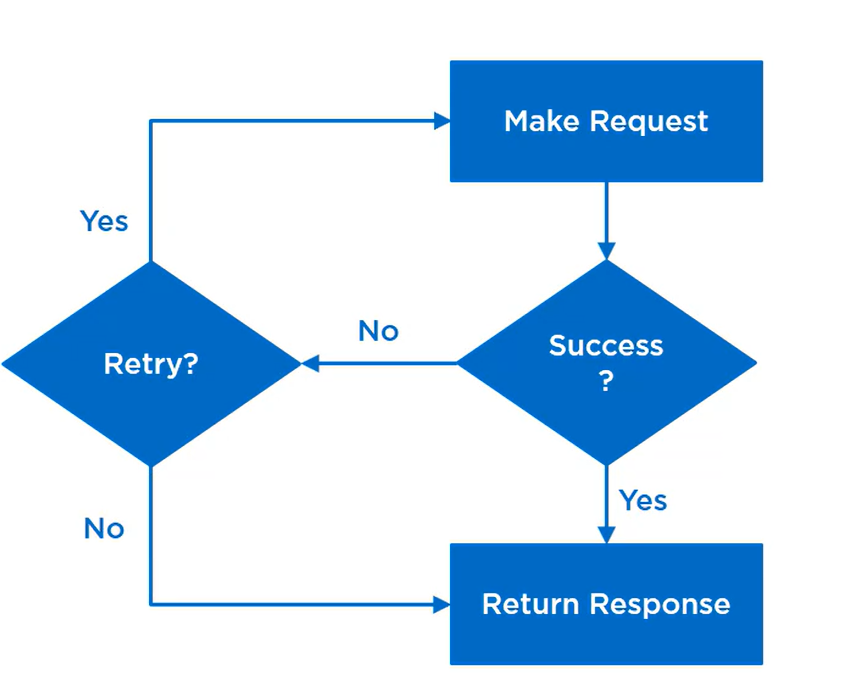
Enabling an application to handle transient failures when it tries to connect to a service, by transparently retrying a failed operation.
This minimizes the effects faults can have on the business tasks the application is performing.
Strategies:
- Cancel
- Retry
- Wait and retry
# RETRY
When not to use:
- when a fault is likely to be long lasting
- for handling failures that aren't due to transient faults (internal exceptions, errors in business logic)

# CONFIGURATION
#path=resilience4j.retry.instances.retryApi
path.max-attempts=3
path.wait-duration=2s
path.enable-exponential-backoff=true
path.exponentialBackoffMultiplier=2
resilience4j.retry.metrics.legacy.enabled=true
resilience4j.retry.metrics.enabled=true// Retry a specified number of times, using a function to
// calculate the duration to wait between retries based on
// the current retry attempt (allows for exponential back-off)
// In this case will wait for
// 2 ^ 1 = 2 seconds then
// 2 ^ 2 = 4 seconds then
// 2 ^ 3 = 8 seconds then
// 2 ^ 4 = 16 seconds then
// 2 ^ 5 = 32 seconds
Policy
.Handle<SomeExceptionType>()
.WaitAndRetry(5, retryAttempt => TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)));Circuit Breaker
The idea of circuit breaker is to prevent calls to a remote service if we know that the call is likely to fail or time out. This way, we don’t unnecessarily waste critical resources both in our service and in the remote service.
If there are failures in the Microservice ecosystem, then you need to fail fast by opening the circuit. This ensures that no additional calls are made to the failing service so that we return an exception immediately.
Two types of circuit breaker:
1. Original (Simple sum of failures, no minimum throughput)
2. Advanced (Percentage of failures over time, has minimum throughput)
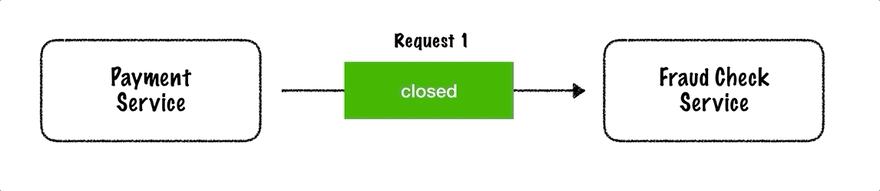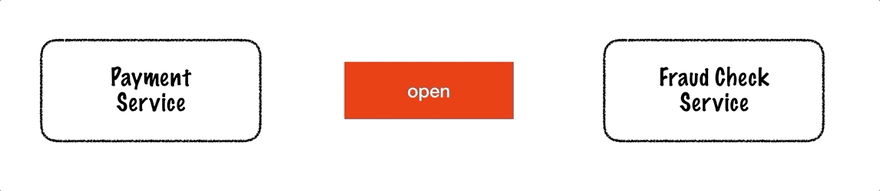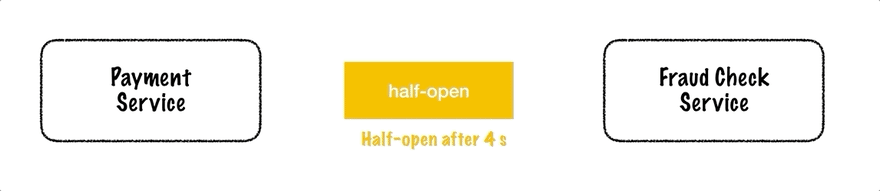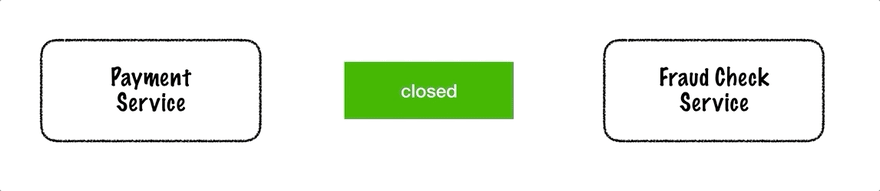
Circuit breaker has 3 states:
- Closed
- Open
- Half-Open
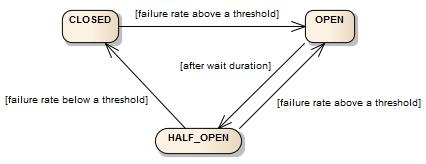
# STATES
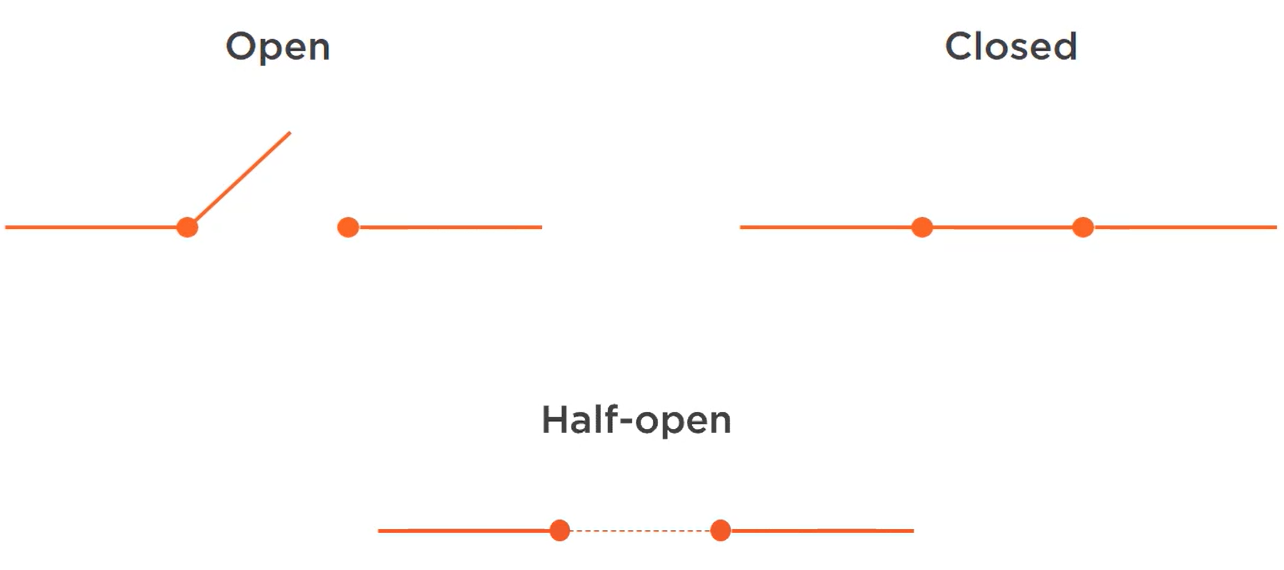
# CIRCUIT BREAKER
When not to use circuit breaker?
- when the system can't afford downtime
- when the system is designed to handle failures
- when the system is experiencing non intermittent failures
@Override
@CircuitBreaker(name = "circuitBreakerApi",
fallbackMethod = "fallback")
public String getCircuitBreaker() throws Exception {
System.out.println("Hello World");
throw new Exception("Error");
}
public String fallback(Throwable t) {
System.out.println("Fallback");
return "Sorry ... Service not available!!!";
}# RESILIENCE4J
#path=resilience4j.circuitbreaker.instances.circuitBreakerApi
path.registerHealthIndicator=true
path.ringBufferSizeInClosedState=44
path.ringBufferSizeInHalfOpenState=2
path.waitDurationInOpenState=30s
path.failureRateThreshold=60// Break the circuit after the specified number of consecutive exceptions
// and keep circuit broken for the specified duration.
Policy
.Handle<SomeExceptionType>()
.CircuitBreaker(2, TimeSpan.FromMinutes(1));# POLLY
// Break the circuit if, within any period of duration samplingDuration,
// the proportion of actions resulting in a handled exception exceeds failureThreshold,
// provided also that the number of actions through the circuit in the period
// is at least minimumThroughput.
Policy
.Handle<SomeExceptionType>()
.AdvancedCircuitBreaker(
failureThreshold: 0.5, // Break on >=50% actions result in handled exceptions...
samplingDuration: TimeSpan.FromSeconds(10), // ... over any 10 second period
minimumThroughput: 8, // ... provided at least 8 actions in the 10 second period.
durationOfBreak: TimeSpan.FromSeconds(30) // Break for 30 seconds.
);Fallback
When a primary operation or service fails, an application or system seamlessly switches to an alternative or backup process.
This allows the system to continue functioning with reduced functionality, ensuring a graceful degradation of service rather than a complete failure.
Fallback mechanisms are essential for maintaining essential functionality and a better user experience during adverse conditions or service disruptions.
Proactive patterns
# RESILIENCE
Strategies implemented in advance to prevent issues, optimize performance, and enhance resilience, including load balancing, caching
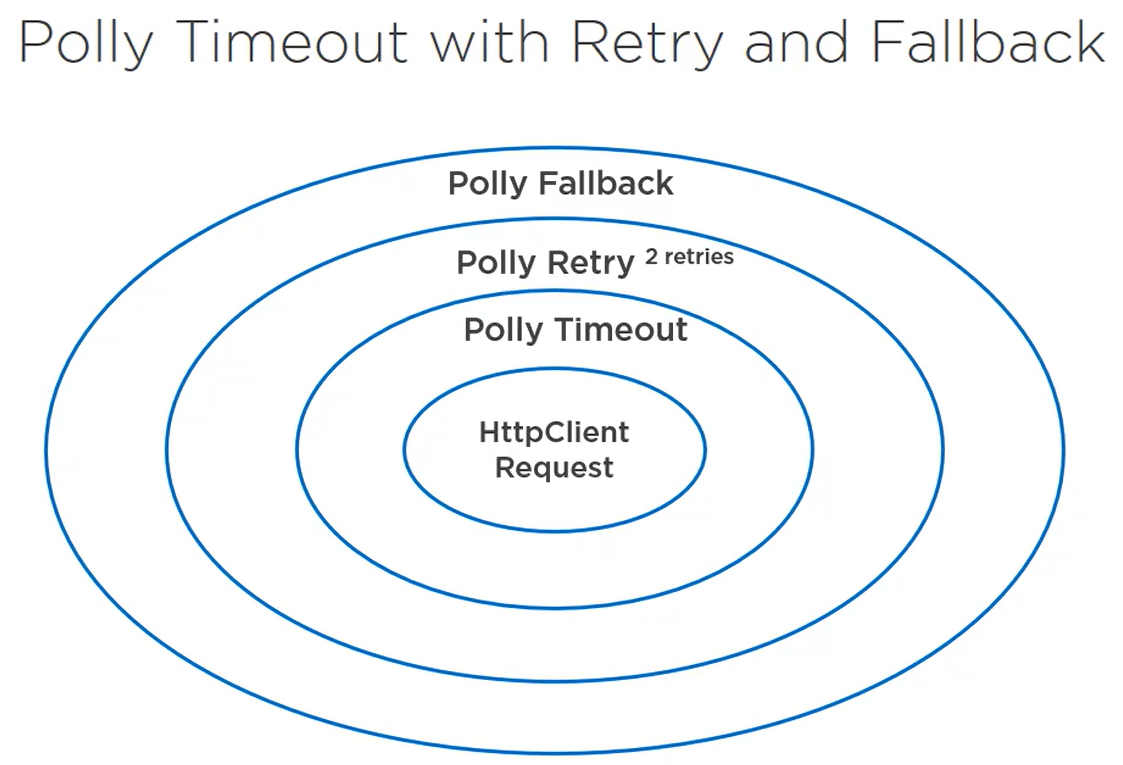
Timeout
1.
Rate Limiter
2.
Caching
3.
Bulkhead
4.
Time Limiter
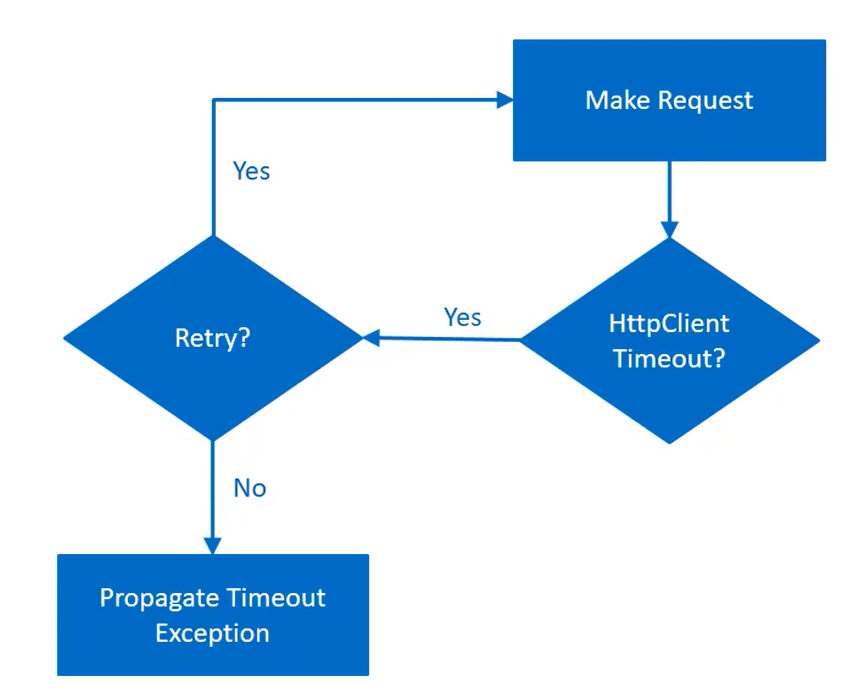
Amount of time we are willing to wait for an operation to complete is called time limiting. If the operation does not complete within the time, it will throw exception.
This pattern ensures that users don't wait indefinitely or take server's resources indefinitely.
Main goal is to not hold up resources
for too long.
# CONFIGURATION

#path=resilience4j.timelimiter.instances.timeLimiterApi
resilience4j.timelimiter.metrics.enabled=true
path.timeout-duration=2s
path.cancel-running-future=true# CONFIGURATION
// Timeout, calling an action if the action times out
Policy
.Timeout(30, onTimeout: (context, timespan, task) =>
{
// Add extra logic to be invoked when a timeout occurs, such as logging
});
var timeoutPolicy =
Policy.TimeoutAsync(
TimeSpan.FromSeconds( 20 ),
TimeoutStrategy.Optimistic,
async ( context, timespan, task ) => {
//write here the cancel request
} );Rate Limiter
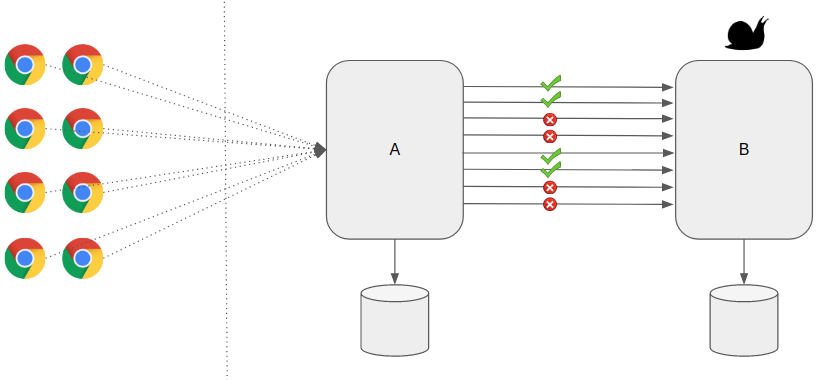
Rate limiting is a technique used to control the rate at which a service or system processes requests in order to prevent it from being overwhelmed or degraded.
It can be used to maintain performance and stability, and ensure that resources are used efficiently.
Incoming requests are analyzed and compared to a set of rules, and only a certain number of requests are allowed to pass through per unit of time.
# RATE LIMITER
When not to use rate limiter?
- system requires real-time responsivness
- when sending batch, large volumes of data
#path=resilience4j.ratelimiter.instances.rateLimiterApi
resilience4j.ratelimiter.metrics.enabled=true
path.register-health-indicator=true
path.limit-for-period=5
path.limit-refresh-period=60s //how often the rate limiter resets and allows the maximum
number of requests again
path.timeout-duration=0s //immediately rejected rather than being held in a queue
path.allow-health-indicator-to-fail=true
path.subscribe-for-events=true
path.event-consumer-buffer-size=50# CONFIGURATION
// Allow up to 20 executions per second.
Policy.RateLimit(20, TimeSpan.FromSeconds(1));
// Allow up to 20 executions per second with a burst of 10 executions.
Policy.RateLimit(20, TimeSpan.FromSeconds(1), 10);
// Allow up to 20 executions per second, with a delegate to return the
// retry-after value to use if the rate limit is exceeded.
Policy.RateLimit(20, TimeSpan.FromSeconds(1), (retryAfter, context) =>
{
return retryAfter.Add(TimeSpan.FromSeconds(2));
});
Caching
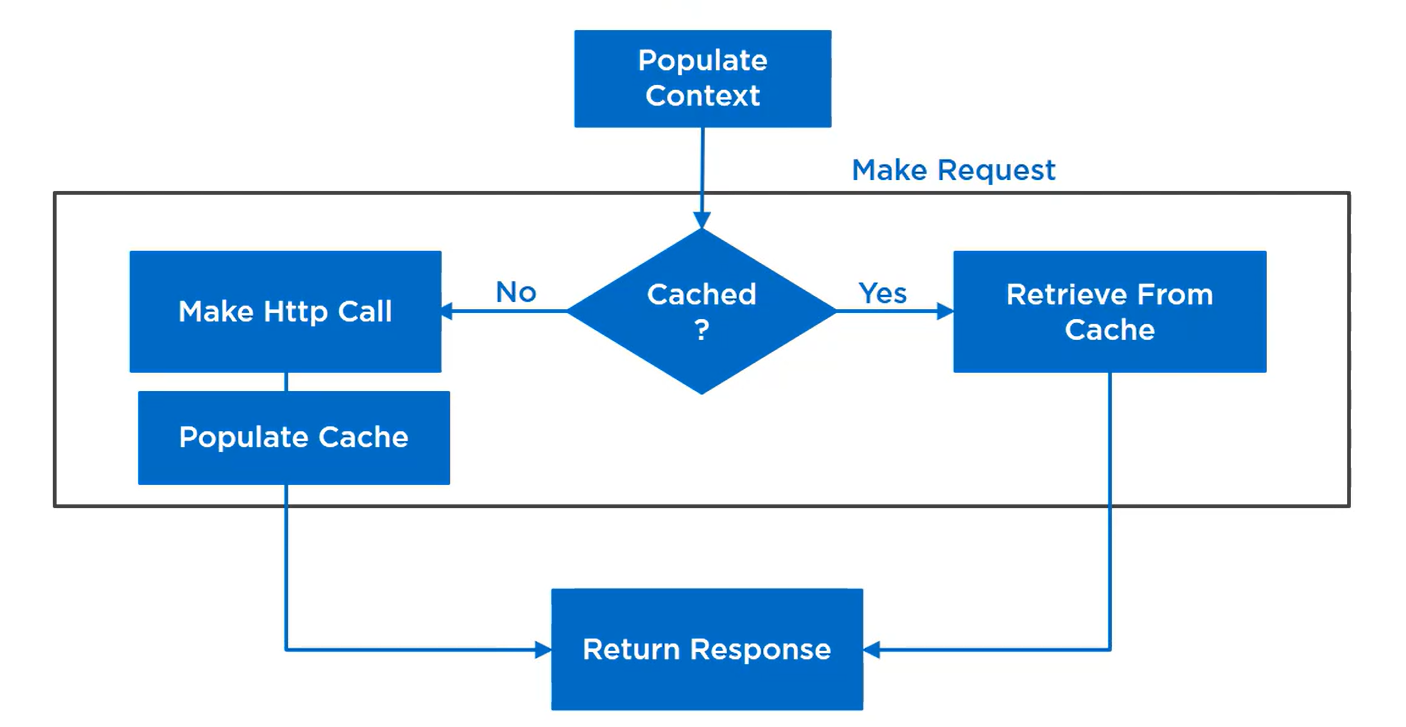
Caching is a valuable resilience pattern that can enhance system reliability and performance by reducing the load on critical resources, such as databases.
Significantly improves system responsiveness and user experience by providing rapid access to frequently requested data.
It's crucial to carefully manage cache invalidation and maintain data consistency.
Implementing cache expiration validations, and strategies for handling stale data are very important for using this pattern effectively
# CONFIGURATION
Bulkhead
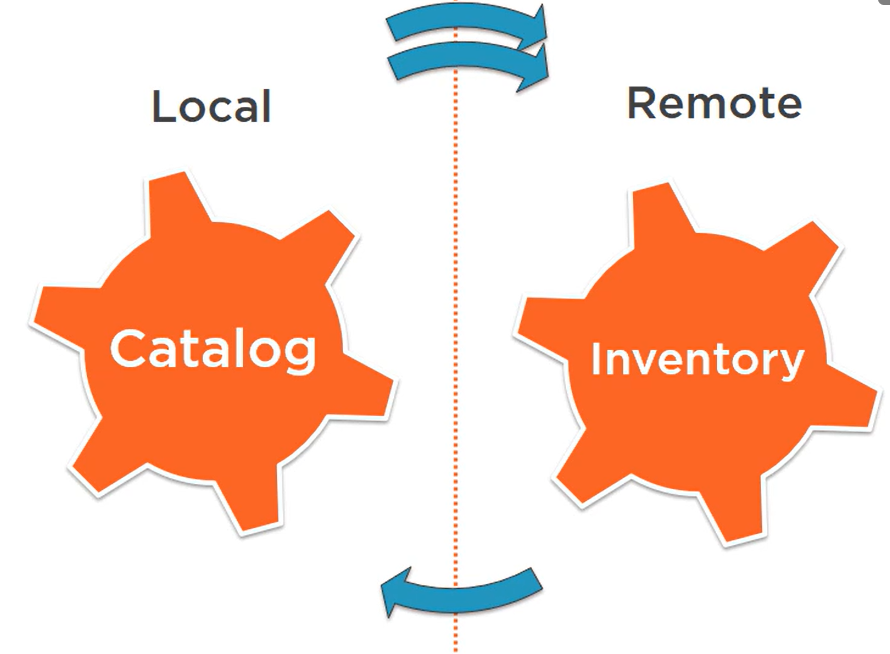
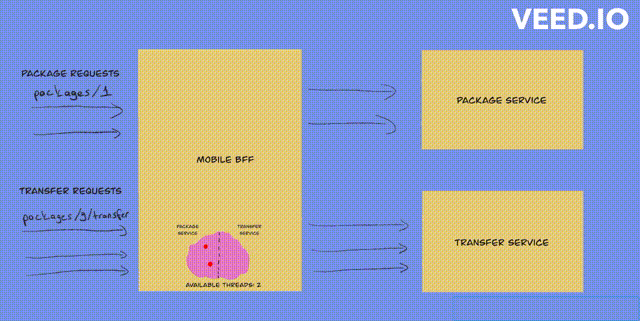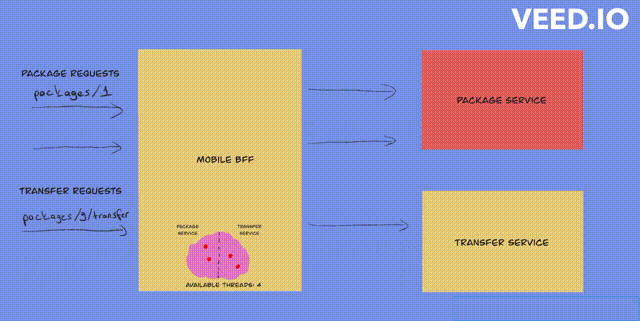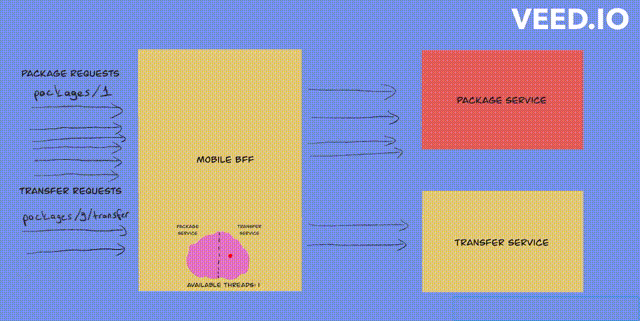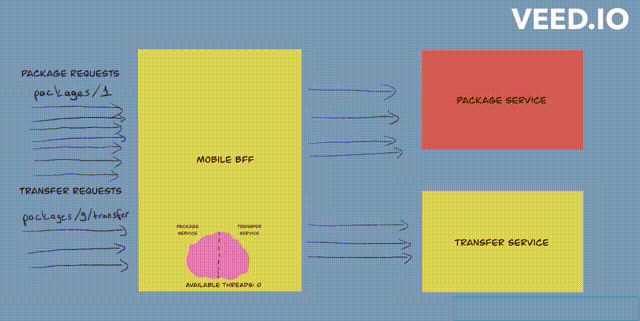
In a bulkhead architecture, elements of an application are isolated into pools so that if one fails, the others will continue to function.
All services need to work independently of each other, so that bulkhead can be implemented.
Strategies:
- semaphore
- fixed thread pool bulkhead
# BULKHEAD
Key reponsibilities:
- prevents overloading
- resource allocation(execution slots and queue between controllers)
- scaling(based on parallel requests and requests in queue)
- load shedding(fail-fast)
- wrapping(used with other patterns, e.g fallback)
# BULKHEAD
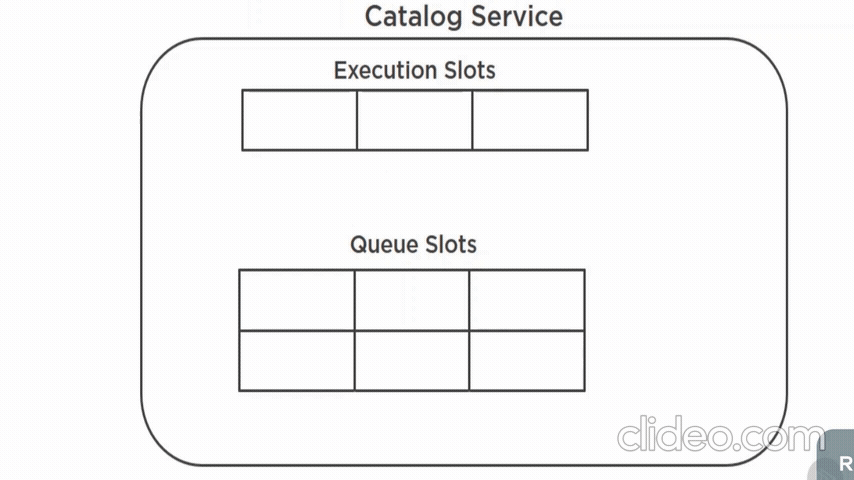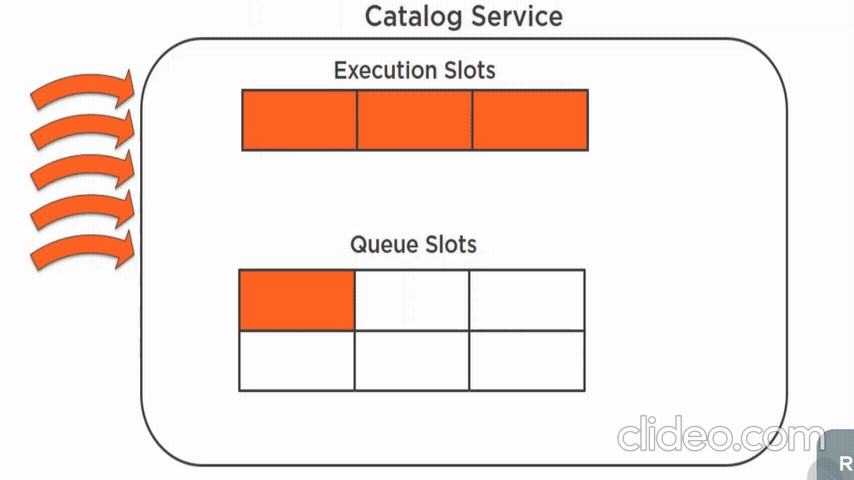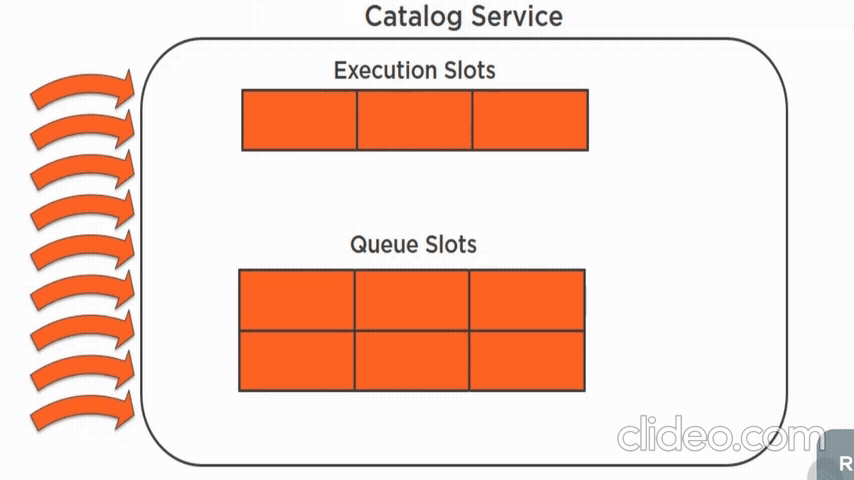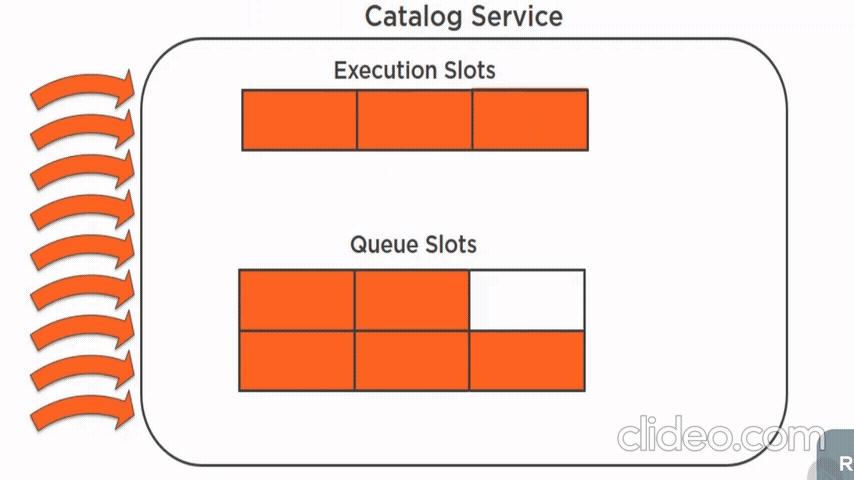
# BULKHEAD
What bulkhead do:
- limits number of requests to the remote that can execute in parallel
- limits number of requests that can in in a queue awaiting an execution slot
- load shedding - goal is to keep latency low for the requests that the server decides to accept so that the service replies before the client times out
# BULKHEAD
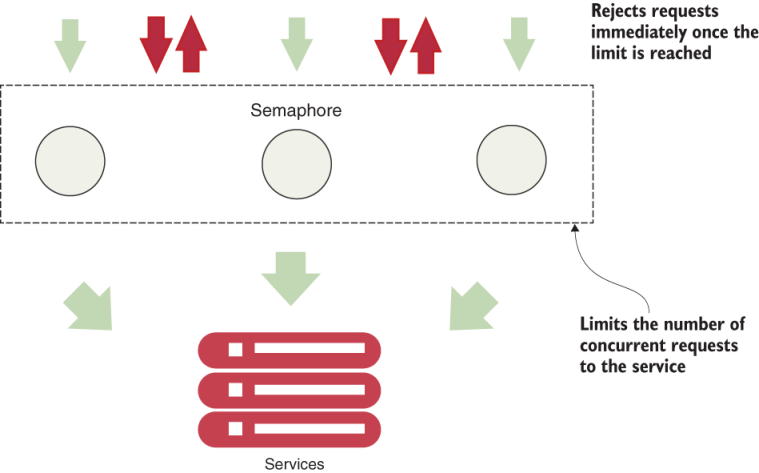
When to use bulkhead:
- when the system is not experiencing high concurrent request load
- when the system does not depend on external resources
# BULKHEAD
Fixed thread pool bulkhead
#path=resilience4j.bulkhead.instances.bulkheadApi
resilience4j.bulkhead.metrics.enabled=true
path.max-concurrent-calls=3
path.max-wait-duration=1# CONFIGURATION
// Restrict executions through the policy to a maximum of twelve concurrent actions.
Policy
.Bulkhead(12)
// Restrict executions through the policy to a maximum of twelve concurrent actions,
// with up to two actions waiting for an execution slot in the bulkhead if all slots are taken.
Policy
.Bulkhead(12, 2)
// Restrict concurrent executions, calling an action if an execution is rejected
Policy
.Bulkhead(12, context =>
{
// Add callback logic for when the bulkhead rejects execution, such as logging
});
// Monitor the bulkhead available capacity, for example for health/load reporting.
var bulkhead = Policy.Bulkhead(12, 2);
// ...
int freeExecutionSlots = bulkhead.BulkheadAvailableCount;
int freeQueueSlots = bulkhead.QueueAvailableCount;Sources:
- https://resilience4j.readme.io/docs
- https://firatkomurcu.com/microservices-bulkhead-pattern
- https://blog.codecentric.de/resilience-design-patterns-retry-fallback-timeout-circuit-breaker
- https://www.datacore.com/blog/availability-durability-reliability-resilience-fault-tolerance/
- https://www.baeldung.com/spring-boot-resilience4j
- https://github.com/App-vNext/Polly
- https://learn.microsoft.com/en-us/ef/core/miscellaneous/connection-resiliency