Роль ML в компиляторах
Как улучшить сервис, не поменяв ни одной строки исходного кода
Литвинов Михаил

@litvinovmitch11
План доклада
-
Введение в тему
-
Обзор существующих проблем
-
Обзор решений
-
Прикладное сравнение решений
-
Заключение
2/61
План доклада
-
Введение в тему
-
Обзор существующих проблем
-
Обзор решений
-
Прикладное сравнение решений
-
Заключение
- Быстрое погружение в тему (или не очень...)
2/61
План доклада
-
Введение в тему
-
Обзор существующих проблем
-
Обзор решений
-
Прикладное сравнение решений
-
Заключение
- Быстрое погружение в тему (или не очень...)
- Постараемся ответить на важный вопрос:
"Сырая ли это технология?"
2/61
Обзор существующих проблем
-
Phase Ordering Problem
-
Auto Vectorization
-
Register Allocation
-
Inlining
3/61
Обзор существующих проблем
-
Phase Ordering Problem
-
Auto Vectorization
-
Register Allocation
-
Inlining
- Порядок трансформаций
3/61
Обзор существующих проблем
-
Phase Ordering Problem
-
Auto Vectorization
-
Register Allocation
-
Inlining
- Порядок трансформаций
- Векторизация инструкций
3/61
Обзор существующих проблем
-
Phase Ordering Problem
-
Auto Vectorization
-
Register Allocation
-
Inlining
- Порядок трансформаций
- Векторизация инструкций
- Аллокация регистров
3/61
Обзор существующих проблем
-
Phase Ordering Problem
-
Auto Vectorization
-
Register Allocation
-
Inlining
- Порядок трансформаций
- Векторизация инструкций
- Аллокация регистров
- Встраивание функций
3/61
Обзор решений
-
CompilerGym - Facebook Research
-
ML-LLVM - IITH Research
-
MLGO - Google Research
4/61
Обзор решений
-
CompilerGym - Facebook Research
- Phase Ordering Problem
-
ML-LLVM - IITH Research
-
MLGO - Google Research
4/61
Обзор решений
-
CompilerGym - Facebook Research
- Phase Ordering Problem
- Phase Ordering, AutoVectorization, RegAlloc
-
ML-LLVM - IITH Research
-
MLGO - Google Research
4/61
Обзор решений
-
CompilerGym - Facebook Research
- Phase Ordering Problem
- Phase Ordering, AutoVectorization, RegAlloc
-
ML-LLVM - IITH Research
-
MLGO - Google Research
- RegAlloc, Inlinig
4/61
Прикладное сравнение решений
-
Простота использования
-
Время компиляции
-
Профит (codesize и performance)
5/61
Прикладное сравнение решений
-
Простота использования
-
Время компиляции
-
Профит (codesize и performance)
- Сколько страдать, чтобы заработало
5/61
Прикладное сравнение решений
-
Простота использования
-
Время компиляции
-
Профит (codesize и performance)
- Сколько страдать, чтобы заработало
- Сколько страдать, чтобы завершилось
5/61
Прикладное сравнение решений
-
Простота использования
-
Время компиляции
-
Профит (codesize и performance)
- Сколько страдать, чтобы заработало
- Сколько страдать, чтобы завершилось
- Сколько страдать, чтобы понять, что все (не) зря
5/61
Начинаем!
Что такое компилятор?
C++
Исполняемый файл
int main(int argc, const char **argv) {
llvm::sys::PrintStackTraceOnErrorSignal(argv[0]);
// Initialize targets for clang module support.
llvm::InitializeAllTargets();
auto ExpectedParser =
CommonOptionsParser::create(argc, argv, ClangCheckCategory);
if (!ExpectedParser) {
llvm::errs() << ExpectedParser.takeError();
return 1;
}
...
}ELF Header:
Magic: 7f 45 4c 46 02 01 01 03 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - GNU
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0xe143f0
Start of program headers: 64 (bytes into file)
...6/61
Что такое компилятор?
Исполняемый файл
ELF Header:
Magic: 7f 45 4c 46 02 01 01 03 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - GNU
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0xe143f0
Start of program headers: 64 (bytes into file)
...C++
int main(int argc, const char **argv) {
llvm::sys::PrintStackTraceOnErrorSignal(argv[0]);
// Initialize targets for clang module support.
llvm::InitializeAllTargets();
auto ExpectedParser =
CommonOptionsParser::create(argc, argv, ClangCheckCategory);
if (!ExpectedParser) {
llvm::errs() << ExpectedParser.takeError();
return 1;
}
...
}6/61
Что такое компилятор?
Исполняемый файл
ELF Header:
Magic: 7f 45 4c 46 02 01 01 03 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - GNU
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0xe143f0
Start of program headers: 64 (bytes into file)
...ОПТИМИЗИРУЮЩИЙ?
C++
int main(int argc, const char **argv) {
llvm::sys::PrintStackTraceOnErrorSignal(argv[0]);
// Initialize targets for clang module support.
llvm::InitializeAllTargets();
auto ExpectedParser =
CommonOptionsParser::create(argc, argv, ClangCheckCategory);
if (!ExpectedParser) {
llvm::errs() << ExpectedParser.takeError();
return 1;
}
...
}6/61
Что такое компилятор?
С, C++, Rust, ...
LLVM IR
Program analysis
Transform & optimize
CodeGen
ARM, X86, ...
7/61
Что такое трансформация?
Clang
С++
LLVM IR
INFO
OPT
CodeGen
ARM, X86
Opt
LLVM - PASS
Pipelines (O1-O3, Os, Oz)
8/61
Что такое трансформация?
Clang (всемогущий)
С++
LLVM IR
INFO
OPT
CodeGen
ARM, X86
Opt
LLVM - PASS
Pipelines (O1-O3, Os, Oz)
8/61
Что такое трансформация?
С++
LLVM IR
INFO
OPT
CodeGen
ARM, X86
Opt (чуть менее всемогущий)
LLVM - PASS
Pipelines (O1-O3, Os, Oz)
Clang (всемогущий)
8/61
Удаление неиспользуемого кода
Простейший вид CFG
Control Flow Graph
NODE №1
NODE №2
NODE №3
NODE №4
Граф потока управления
9/61
Удаление неиспользуемого кода
Простейший вид CFG
Control Flow Graph
Граф потока управления
Заметим, что в NODE №3 никак не попасть
9/61
NODE №1
NODE №2
NODE №3
NODE №4
Удаление неиспользуемого кода
Простейший вид CFG
Control Flow Graph
Граф потока управления
Заметим, что в NODE №3 никак не попасть - ее можно не генерировать.
9/61
NODE №1
NODE №2
NODE №4
Удаление неиспользуемого кода
Простейший вид CFG
Control Flow Graph
Граф потока управления
- Упростили граф
- Уменьшили codesize
- Уменьшили время компиляции
9/61
NODE №1
NODE №2
NODE №4
Удаление неиспользуемого кода
Простейший вид CFG
Control Flow Graph
Граф потока управления
- Упростили граф
- Уменьшили codesize
- Уменьшили время компиляции
Не забыли
похвалить себя
9/61
NODE №1
NODE №2
NODE №4
Распространение констант
x = 10 y = 40
z = y - 30 y = 20
q = input() q *= z - x
Простейший вид CFG
Control Flow Graph
Граф потока управления
Рассмотрим тот же граф. Но добавим в вершины осмысленные выражения.
z = 10
10/61
Распространение констант
x = 10 y = 40
z = y - 30
y = 20 Простейший вид CFG
Control Flow Graph
Граф потока управления
Добавим аннотации к каждой переменной в каждой вершине.
x = 10, y = 40
z, q = undef.
q = input() q *= z - x
z = 10
10/61
Распространение констант
x = 10 y = 40
z = y - 30
y = 20 Простейший вид CFG
Control Flow Graph
Граф потока управления
x = 10, y = 40
z, q = undef.
x, z = 10 y = 20 q = undef.
q = input() q *= z - x
Добавим аннотации к каждой переменной в каждой вершине.
z = 10
10/61
Распространение констант
x = 10 y = 40
z = y - 30
y = 20 Простейший вид CFG
Control Flow Graph
Граф потока управления
x = 10, y = 40
z, q = undef.
x, z = 10 y = 20 q = undef.
q = input() q *= z - x
Добавим аннотации к каждой переменной в каждой вершине.
z = 10
x, z = 10
y = 40 q = undef.
10/61
Распространение констант
x = 10 y = 40
z = y - 30
y = 20 Простейший вид CFG
Control Flow Graph
Граф потока управления
x = 10, y = 40
z, q = undef.
x, z = 10 y = 20 q = undef.
q = input()
q *= z - x
Добавим аннотации к каждой переменной в каждой вершине.
z = 10
x, z = 10
y = 40 q = undef.
10/61
Распространение констант
x = 10 y = 40
z = y - 30
y = 20 Простейший вид CFG
Control Flow Graph
Граф потока управления
x = 10, y = 40
z, q = undef.
x, z = 10
y, q = undef.
q = input()
q *= z - x
Добавим аннотации к каждой переменной в каждой вершине.
x, z = 10 y = 20 q = undef.
z = 10
x, z = 10
y = 40 q = undef.
10/61
Распространение констант
x = 10 y = 40
z = y - 30
y = 20 q = input()
Простейший вид CFG
Control Flow Graph
Граф потока управления
x = 10, y = 40
z, q = undef.
q *= z - x
x, z = 10
y = undef.
z - x = 0
q = 0
Добавим аннотации к каждой переменной в каждой вершине.
x, z = 10 y = 20 q = undef.
x, z = 10
y, q = undef.
z = 10
x, z = 10
y = 40 q = undef.
10/61
Распространение констант
x = 10 y = 40
q = input()
Простейший вид CFG
Control Flow Graph
Граф потока управления
q = 0
- Упростили выражения
- Получили выигрыш в рантайме
z = 10
z = 10
y = 20 10/61
Распространение констант
x = 10 y = 40
q = input()
Простейший вид CFG
Control Flow Graph
Граф потока управления
q = 0
- Упростили выражения
- Получили выигрыш в рантайме
Не забыли
похвалить себя
z = 10
z = 10
y = 20 10/61
Примеры посложнее
Оптимизации - это трансформации
11/61
Примеры посложнее
Оптимизации - это трансформации
Трансформации - это функции
11/61
Примеры посложнее
Оптимизации - это трансформации
Трансформации - это функции
У функций есть гиперпараметры
11/61
Примеры посложнее
Оптимизации - это трансформации
Трансформации - это функции
У функций есть гиперпараметры
А вот настроить эти гиперпараметры - поможет ML!
11/61
Примеры посложнее
Оптимизации - это трансформации
Трансформации - это функции
У функций есть гиперпараметры
А вот настроить эти гиперпараметры - поможет ML!
Ура, удалось связать ML и компиляторы...
11/61
Phase ordering problem
В компиляторе большое число (>100) независимых трансформаций.
От порядка выполнения трансформаций зависит результат.
PASS 1
PASS 2
PASS 3
PASS 4
PASS 1
PASS 2
PASS 3
PASS 4
PASS 1
PASS 2
PASS 3
PASS 4
PASS 1
PASS 2
PASS 3
PASS 4
12/61
Phase ordering problem & ML
Выбор наилучшей последовательности - NP полная задача.
Существуют дефолтные пайплайны, написанные экспертами, но они хороши лишь В СРЕДНЕМ.
На помощь приходит RL!
PASS 1
PASS 2
PASS 3
PASS 4
PASS 1
PASS 2
PASS 3
PASS 4
PASS 1
PASS 2
PASS 3
PASS 4
PASS 1
PASS 2
PASS 3
PASS 4
13/61
Reinforcement learning
Agent
Env
Actions
Reward
14/61
Reinforcement learning
Agent
Env
Actions
Reward
14/61
Reinforcement learning
Agent
Env
Actions
Reward
14/61
Reinforcement learning
Env
Actions
Reward
Agent
14/61
Reinforcement learning
Env
Actions
Reward
Agent
14/61
Reinforcement learning
Env
Actions
Reward
Agent
Продолжаем,
пока не устроит ревард
14/61
AutoVectorization
Векторные вычисления — такие вычисления, когда при выполнении одной инструкции процессора производится одновременно несколько однотипных операций.
Что такое векторные инструкции?
eax, ebx, ecx, edx,...
xmm0 - xmm7,...
VS.
15/61
AutoVectorization
vector<uint32_t> v1(n), v2(n), out(n);
for (size_t i = 0; i < n; ++i) {
out[i] = v1[i] + v2[i];
}LLVM обнаружит, что цикл независим, данные выровнены, и тип данных подходит для векторизации. Цикл будет векторизован.
uint32_t a, b, c, d, e, f;
a = b + c;
d = e + f;
LLVM обнаружит, что операции независимы и имеют одинаковую структуру. Операции будут объединены в одну векторную операцию.
16/61
AutoVectorization & ML
Поиск мест, подходящих для векторизации - задача, использующая различные эвристики.
Для этого поиска можно использовать ML.
Также существует возможность переорганизации кода таким образом, чтобы векторизация стала возможна (тоже ML).
17/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........- У виртуальных регистров есть время жизни
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
- Количество физических регистров ограничено
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........y- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
- Количество физических регистров ограничено
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........yxx- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
- Количество физических регистров ограничено
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........yxzx- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
- Количество физических регистров ограничено
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........yxzxt- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
- Количество физических регистров ограничено
18/61
RegAlloc
x = y + 1z = x + yt = 10 * zq = t * yo = z + yb = y + t........yxzxtq- У виртуальных регистров есть время жизни
- Количество виртуальных регистров не ограничено
- В моменты использования виртуальных регистров - им должны соответствовать физические
- Количество физических регистров ограничено
18/61
RegAlloc & ML
На самом деле RegAlloc -
это решаемая NP сложная задача (задача о рюкзаке)
19/61
RegAlloc & ML
На самом деле RegAlloc -
это решаемая NP сложная задача (задача о рюкзаке)
Однако, как мы увидим далее, можно использовать различные эвристики и методы ML, чтобы честно не решать эту задачу
19/61
Inlinig
for (size_t i = 0; i < n; ++i) {
f(i, v);
}Инлайнинг - встраивание тела функции, вместо ее вызова
uint32_t f(size_t idx, vector<int> &v) {
v[idx] = 42;
}
20/61
Inlinig
for (size_t i = 0; i < n; ++i) {
f(i, v);
}Инлайнинг - встраивание тела функции, вместо ее вызова
uint32_t f(size_t idx, vector<int> &v) {
v[idx] = 42;
}
20/61
Inlinig
for (size_t i = 0; i < n; ++i) {
f(i, v);
}Инлайнинг - встраивание тела функции, вместо ее вызова
uint32_t f(size_t idx, vector<int> &v) {
v[idx] = 42;
}
20/61
for (size_t i = 0; i < n; ++i) {
v[i] = 42;
}Inlinig
for (size_t i = 0; i < n; ++i) {
f(i, v);
}Инлайнинг - встраивание тела функции, вместо ее вызова
uint32_t f(size_t idx, vector<int> &v) {
v[idx] = 42;
}
for (size_t i = 0; i < n; ++i) {
v[i] = 42;
}А теперь можно применить векторизацию!
20/61
Inlinig & ML
Сейчас решение о необходимости встраивать функции компилятор принимает на основе различных эвристик (бюджет инлайнинга и др.)
Ручные формулы можно заменить на ML алгоритм, который выдедет наилучшую формулу инлайнинга в конкретном коде, а также сможет сам выделять признаки.
21/61

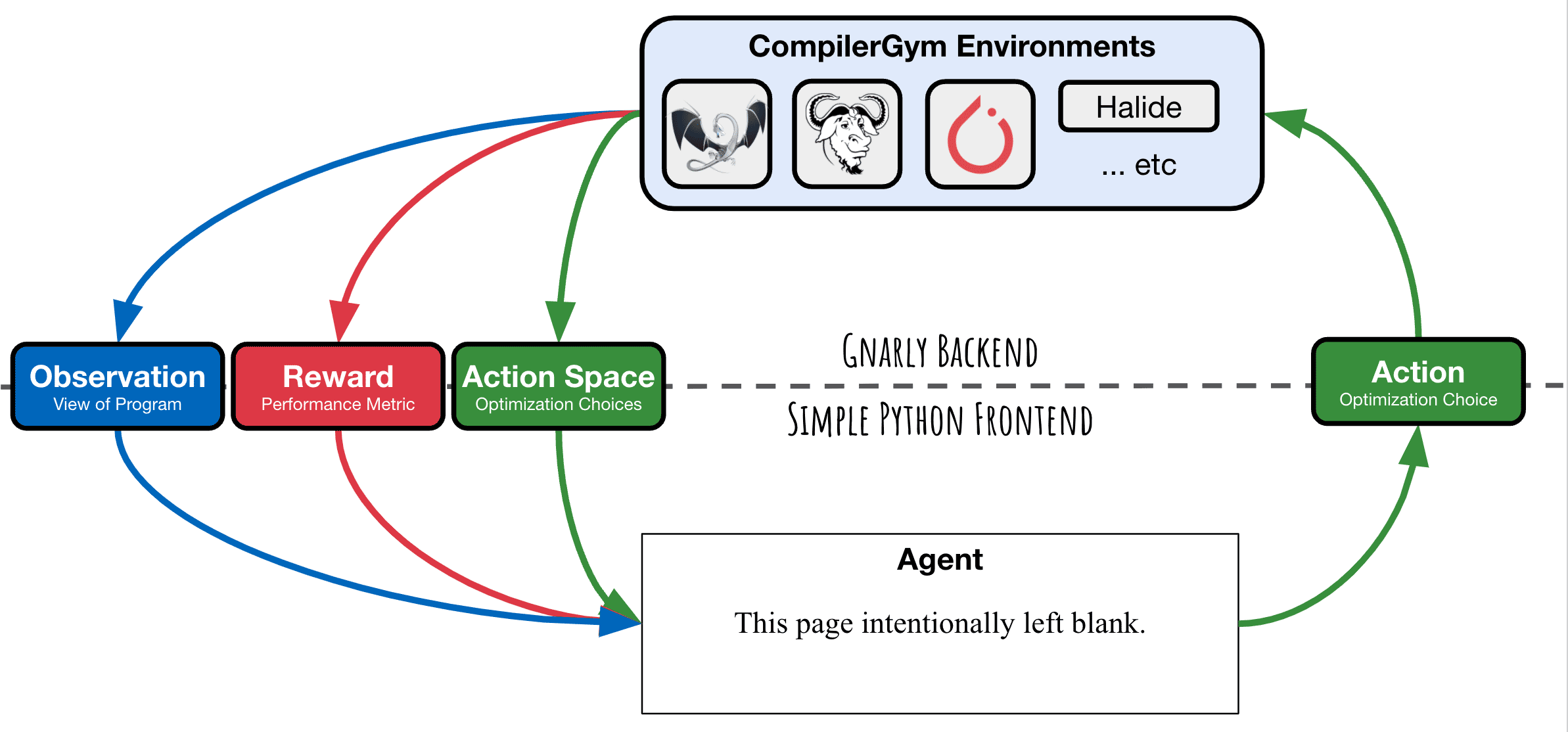
CompilerGym - Facebook Research
Окружение для циклических алгоритмов обучения с подкреплением
GYM
22/61
Environment
Задача оптимизации и модель компилятора
1.
Action Space
Текущее состояние среды, пространство действий
2.
Reward
Метрика оптимизации
4.
Observation
Текущее представление окружения
3.
CompilerGym - Facebook Research
23/61
CompilerGym - Facebook Research
GCC
LLVM
MLIR
loop_tool
Enviroments
Основное окружение - LLVM
Похожее окружение - GCC
Цикловые оптимизации - loop
Перемножение матриц - MLIR
24/61
Action space
Дискретно. Состоит из 123 трансформаций
(llvm opt --passes)
CompilerGym - Facebook Research (LLVM)
-add-discriminators
|
Add DWARF path discriminators
|
-adce
|
Aggressive Dead Code Elimination
|
-aggressive-instcombine
|
Combine pattern based expressions
|
-alignment-from-assumptions
|
Alignment from assumptions
|
-always-inline
|
Inliner for always_inline functions
|
-argpromotion
|
Promote ‘by reference’ arguments to scalars
|
-attributor
|
Deduce and propagate attributes
|
|
|
|
and more...opt --passesПространство действий
25/61
Observations
CompilerGym - Facebook Research (LLVM)
AUTOPHASE
INST2VEC
PROGRAML
ETC.
INST2VEC
Представления кода
26/61
Observation Autophase
Observation
Состоит из 56 чисел, которые описывают различные статистики LLVM-IR
|
0 |
BBNumArgsHi |
Number of BB where total args for phi nodes is gt 5 |
|
1 |
BBNumArgsLo |
Number of BB where total args for phi nodes is [1, 5] |
|
2 |
onePred |
Number of basic blocks with 1 predecessor |
|
3 |
onePredOneSuc |
Number of basic blocks with 1 predecessor and 1 successor |
|
4 |
onePredTwoSuc |
Number of basic blocks with 1 predecessor and 2 successors |
|
5 |
oneSuccessor |
Number of basic blocks with 1 successor |
|
6 |
twoPred |
Number of basic blocks with 2 predecessors |
И так далее
27/61
Observation Inst2Vec
Observation
Состоит из 200 чисел, полученных специальной кодировкой исходного кода
Предобработка кода
Кодирование текста
Получение эмбедингов
28/61
Observation ProGraML
Observation
Основанное на графах представление LLVM-IR, которое включает в себя поток управления, поток данных и поток вызовов.
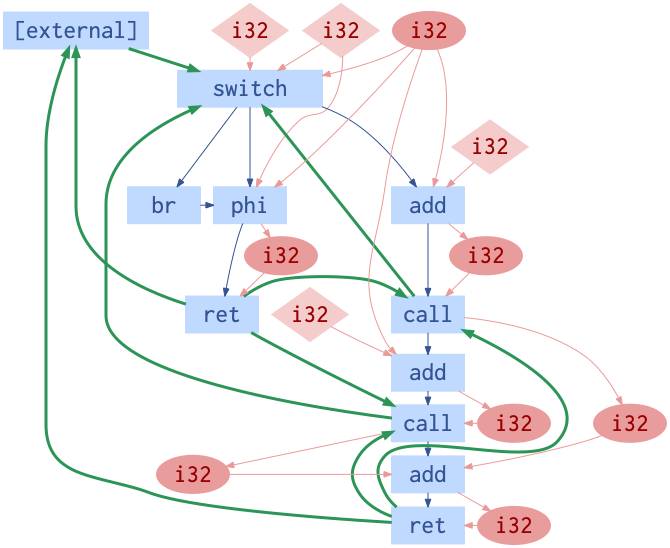
Основанное на графах представление LLVM-IR, которое включает в себя поток управления, поток данных и поток вызовов.
29/61
Reward
CompilerGym - Facebook Research (LLVM)
Награда - разница стоимостей
Ее можно нормировать на начальное значение
Либо на разницу с бейзлайном (O1-O3, Oz)
30/61
CompilerGym - Facebook Research (LLVM)
IR Instruction Count
Количество LLVM-IR инструкций в программе
Codesize
Размер .TEXT секции
Cost functions
31/61
CompilerGym - Facebook Research (LLVM)
IR Instruction Count
Количество LLVM-IR инструкций в программе
Codesize
Размер .TEXT секции
Cost functions
Потому что
измерять
performance
дорого
31/61
CompilerGym - Facebook Research (LLVM)
Как запустить?
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cpp32/61
CompilerGym - Facebook Research (LLVM)
Как запустить?
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppНа одном файле?
32/61
Как запустить?
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppНа одном файле? Легко!
clang++-10 \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppbazel run \
-c opt //compiler_gym/bin:random_search -- \
--env=llvm-ic-v0 \
--benchmark=file:///$PWD/bench.bcCompilerGym - Facebook Research (LLVM)
32/61
А интегрировать в проект?
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppТут могла бы быть реклама вашего скрипта...CompilerGym - Facebook Research (LLVM)
33/61
А интегрировать в проект?
Вам оно точно нужно?...
CompilerGym - Facebook Research (LLVM)
33/61
А интегрировать в проект?
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppВам оно точно нужно?...
Тут могла бы быть реклама вашего скрипта...Пишем код обучения модели на Python
Пишем обертку над компилятором, которая включит:
1) Преобразование исходников в LLVM IR (clang -emit-llvm)
2) Вызов модели (вызов встроенного opt)
3) Преобразование LLVM IR в байткод (clang )
CompilerGym - Facebook Research (LLVM)
33/61
А интегрировать в проект?
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppВам оно точно нужно?...
Тут могла бы быть реклама вашего скрипта...А еще поддержан
только LLVM-10
CompilerGym - Facebook Research (LLVM)
Пишем код обучения модели на Python
Пишем обертку над компилятором, которая включит:
1) Преобразование исходников в LLVM IR (clang -emit-llvm)
2) Вызов модели (вызов встроенного opt)
3) Преобразование LLVM IR в байткод (clang )
33/61
ML-LLVM - IITH - POSET-RL
Отличия от CompilerGym:
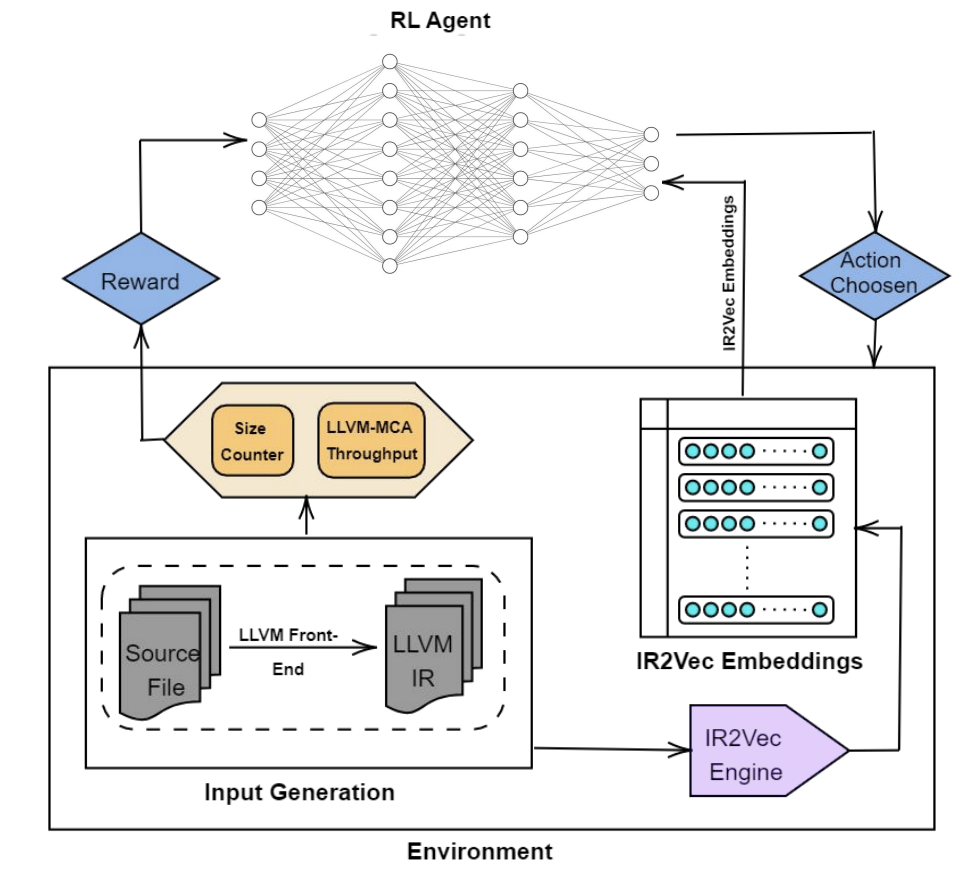
Эмбединги кода - IR2Vec
Метрика - не только codesize,
но и performance
34/61
ML-LLVM - IITH - POSET-RL
Отличия от CompilerGym:
Эмбединги кода - IR2Vec
Метрика - не только codesize,
но и performance
А еще алгоритм обучения
интегрирован в форк LLVM...
34/61
ML-LLVM - IITH - IR2Vec
IR2Vec - это отдельный проект от IITH
Используется для генерации распределенных представлений исходного кода.
Он может выделять внутренние характеристики кода, как это делал Inst2Vec.
Предобучение и выделение начального словаря представлений
Получение исходного кода
Генерация эмбедингов
35/61
ML-LLVM - IITH - Loop Distribution
Распределение циклов (деление циклов) используется для переорганизации циклов с целью дальнейшей векторизации или локализации.
for (size_t i = 0; i < 2n; ++i) {
v[i] += 42;
}36/61
ML-LLVM - IITH - Loop Distribution
Распределение циклов (деление циклов) используется для переорганизации циклов с целью дальнейшей векторизации или локализации.
for (size_t i = 0; i < n; ++i) {
v[i] += 42;
}
for (size_t i = n; i < 2n; ++i) {
v[i] += 42;
}
for (size_t i = 0; i < 2n; ++i) {
v[i] += 42;
}36/61
ML-LLVM - IITH - Loop Distribution
Распределение циклов (деление циклов) используется для переорганизации циклов с целью дальнейшей векторизации или локализации.
for (size_t i = 0; i < n; ++i) {
v[i] += 42;
}
for (size_t i = n; i < 2n; ++i) {
v[i] += 42;
}
for (size_t i = 0; i < 2n; ++i) {
v[i] += 42;
}А теперь можно применить векторизацию!
36/61
ML-LLVM - IITH - Loop Distribution
Награда для модели рассчитывается с учётом стоимости инструкций и количества промахов кэша в цикле.
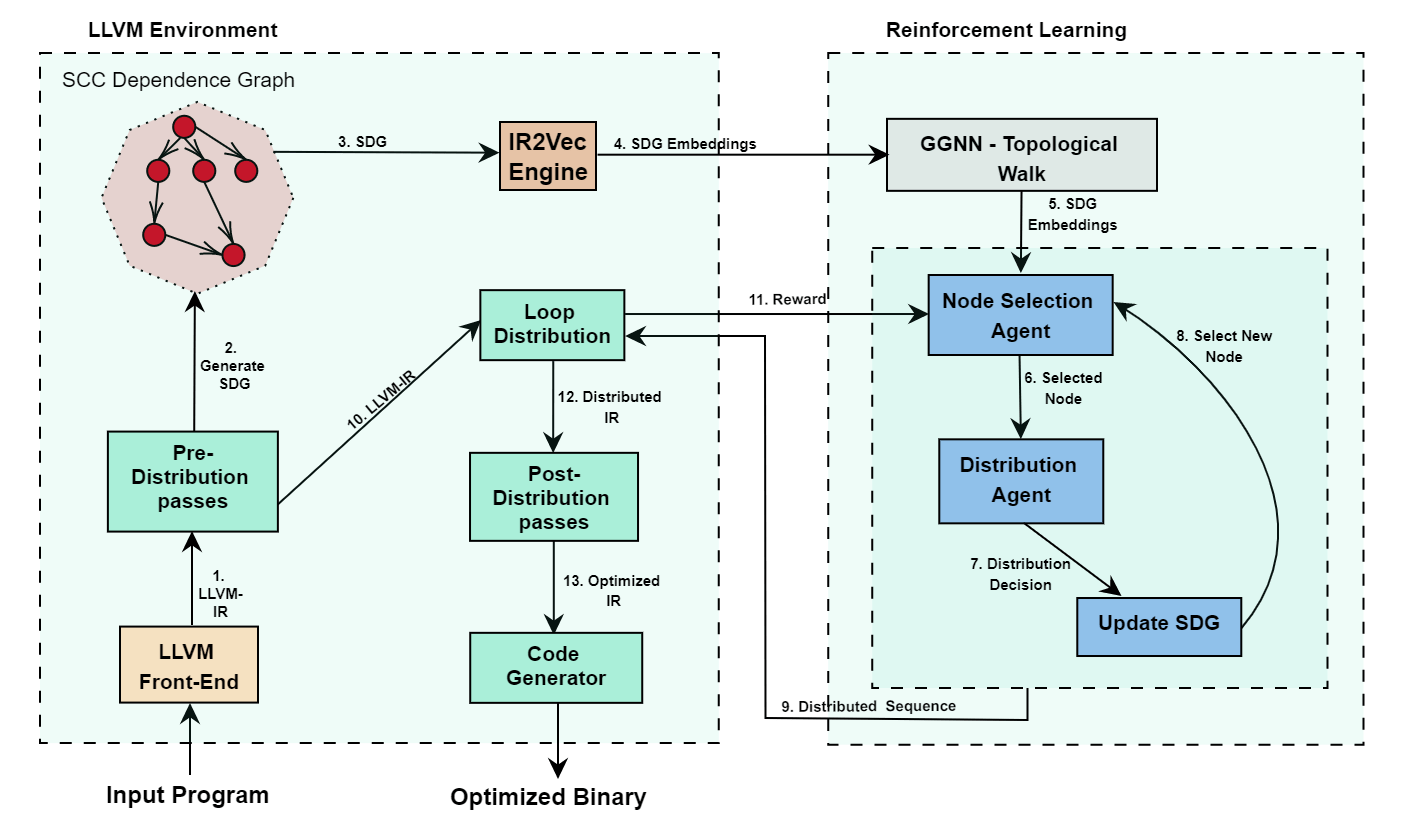
Генерируем граф зависимостей для каждого цикла в программе.
Модель учится прогнозировать порядок распределения цикла.
37/61
ML-LLVM - IITH - Rl4ReAl
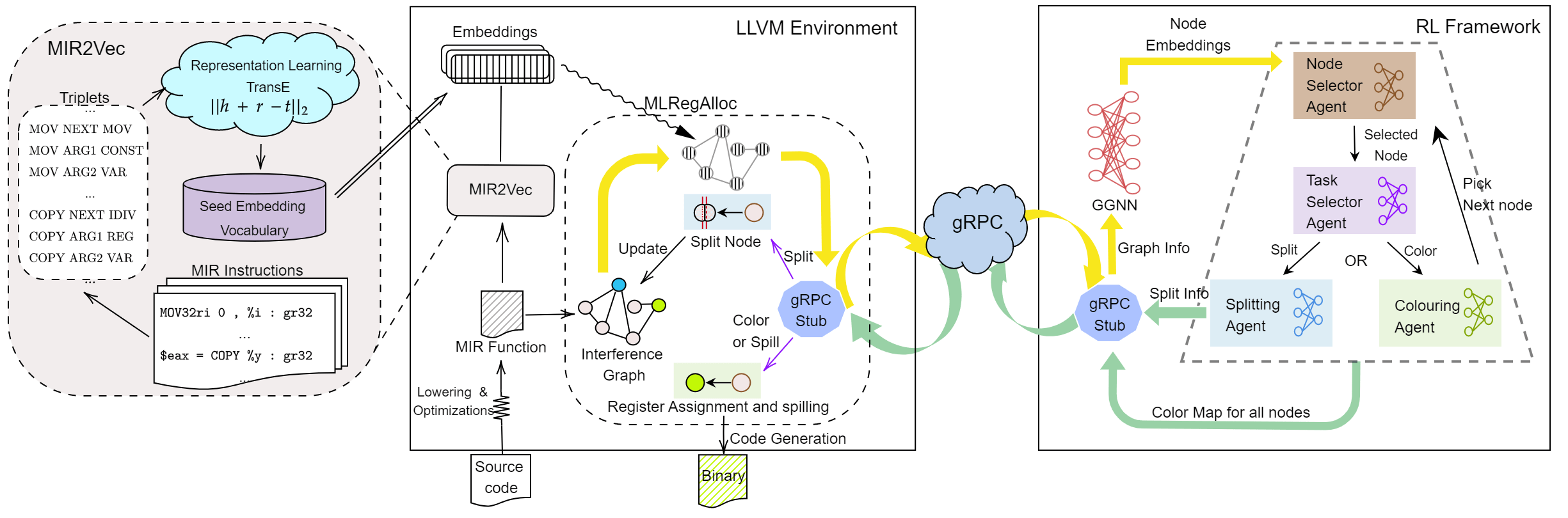
Используя раскраски графов и уже изученный IR2Vec для эмбедингов, с помощью RL агента решается задача аллокации регистров
38/61
ML-LLVM - IITH
Как запустить?
39/61
ML-LLVM - IITH
Как запустить?
К счастью, больше писать Python код не придется. У IITH есть свой форк LLVM - ML-LLVM
(LLVM-10)
Проект RL4ReAl интегрирован в clang
Проекты POSET-RL и Loop-Distribution интегрированы в opt
39/61
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppML-LLVM - IITH
А на большом проекте?
40/61
clang++ \
-emit-llvm -c -O0 -Xclang -disable-O0-optnone \
-Xclang -disable-llvm-passes \
bench.cppСобрать ML-LLVM, с ONNX-runtime, получить clang и optML-LLVM - IITH
А на большом проекте?
Имеется возможность обучать свои моделиВ кейсе clang просто подменяем компилятор с дефолтным конфигом настроек моделиВ кейсе opt пишем обертку - скрипт, который сначала дергает clang -emit-llvm, затем opt, затем clang40/61
MLGO - Google Research - RegAlloc
Уже много раз обсуждалась задача аллокации регистров.
MLGO создали RegAlloc Advisor - специальный советник,
который предсказывает с помощью ML распределение регистров и помогает избрать лучшее распределение с целью увеличения perfomance.
41/61
MLGO - Google Research - RegAlloc
Уже много раз обсуждалась задача аллокации регистров.
MLGO создали RegAlloc Advisor - специальный советник,
который предсказывает с помощью ML распределение регистров и помогает избрать лучшее распределение с целью увеличения perfomance.
Главное отличие от IITH - это интегрировано в основной LLVM-project!
41/61
MLGO - Google Research - Inlinig
Бюджет инлайнинга - число, определяющее какую сумму можно потратить на инлайнинг.
42/61
MLGO - Google Research - Inlinig
Бюджет инлайнинга - число, определяющее какую сумму можно потратить на инлайнинг.
Стоимость инлайнинга - число, для каждого вхождения функции, определяющее стоимость ее инлайнинга.
42/61
MLGO - Google Research - Inlinig
Бюджет инлайнинга - число, определяющее какую сумму можно потратить на инлайнинг.
Стоимость инлайнинга - число, для каждого вхождения функции, определяющее стоимость ее инлайнинга.
Расчет стоимости инлайнинга зависит от некотрых эвристик.
MLGO призван обучить ML модель, чтобы не изобретать формулы стоимостей инлайнинга.
42/61
MLGO - Google Research
Как запустить?
43/61
MLGO - Google Research
Как запустить?
Оба проекта интегрированы в дефолтный LLVM!
Нужно лишь запустить clang с правильными флагами
Дефолтные решения
clang++ -Oz -mllvm -enable-ml-inliner=default bench.cppclang++ -mllvm -regalloc-enable-advisor=default bench.cpp43/61
MLGO - Google Research
Как использовать модели?
44/61
MLGO - Google Research
Как использовать модели?
Имеется возможность обучать свои моделиСобрать ml-compiler-opt, с tflite, обучить моделиСобрать LLVM,с флагами -DTENSORFLOW_AOT_PATH, -DLLVM_INLINER_MODEL_PATH
44/61
MLGO - Google Research
Как использовать модели?
Имеется возможность обучать свои моделиСобрать ml-compiler-opt, с tflite, обучить моделиЕсть классное demo на Github MLGO!
44/61
Собрать LLVM,с флагами -DTENSORFLOW_AOT_PATH, -DLLVM_INLINER_MODEL_PATH
MLGO - Google Research
Как запустить на большом проекте?
45/61
MLGO - Google Research
Как запустить на большом проекте?
Никаких проблем, просто в CMake указываем дополнительные флаги компилятору (если с моделями, то компилятору, собранному с флагами TF)!
-DCMAKE_CXX_FLAGS_RELEASE="-Oz -mllvm -enable-ml-inliner=release"-DCMAKE_CXX_FLAGS_RELEASE="-mllvm -regalloc-enable-advisor=default"45/61
Сравнение всех решений
CodeSize VS. Performance
Легко измерить и понять насколько хорош алгоритм или нет
Очень дорого собирать данные для обучения и замерять профит
46/61
Сравнение всех решений
Размер программы
InstCount
47/61
Сравнение всех решений
Размер программы
InstCount - проще, обычно уже имеем
47/61
Сравнение всех решений
Размер программы
CodeSize
InstCount - проще, обычно уже имеем
47/61
Сравнение всех решений
Размер программы
CodeSize - сложнее, нужен лишний пайплайн для сборки
InstCount - проще, обычно уже имеем
47/61
Сравнение всех решений
Скорость выполнения
Создание окружения
48/61
Сравнение всех решений
Скорость выполнения
Создание окружения - очень дорого
48/61
Сравнение всех решений
Скорость выполнения
Создание окружения - очень дорого
LLVM-MCA
48/61
Сравнение всех решений
Скорость выполнения
LLVM-MCA - моделирует пропускную способность конвейера инструкций
Создание окружения - очень дорого
48/61
Сравнение всех решений - бенчмарки
Phase Ordering Problem
| Алгорим | Время | Codesize (geomean) |
|---|---|---|
| PPO + Guided Search | 69.821s | 1.070× |
| Random search (t=10800) | 10,512.356s | 1.062× |
CompilerGym
llvm-ic-v0 environment
cbench-v1 dataset
49/61
Сравнение всех решений - бенчмарки
Phase Ordering Problem
POSET-RL
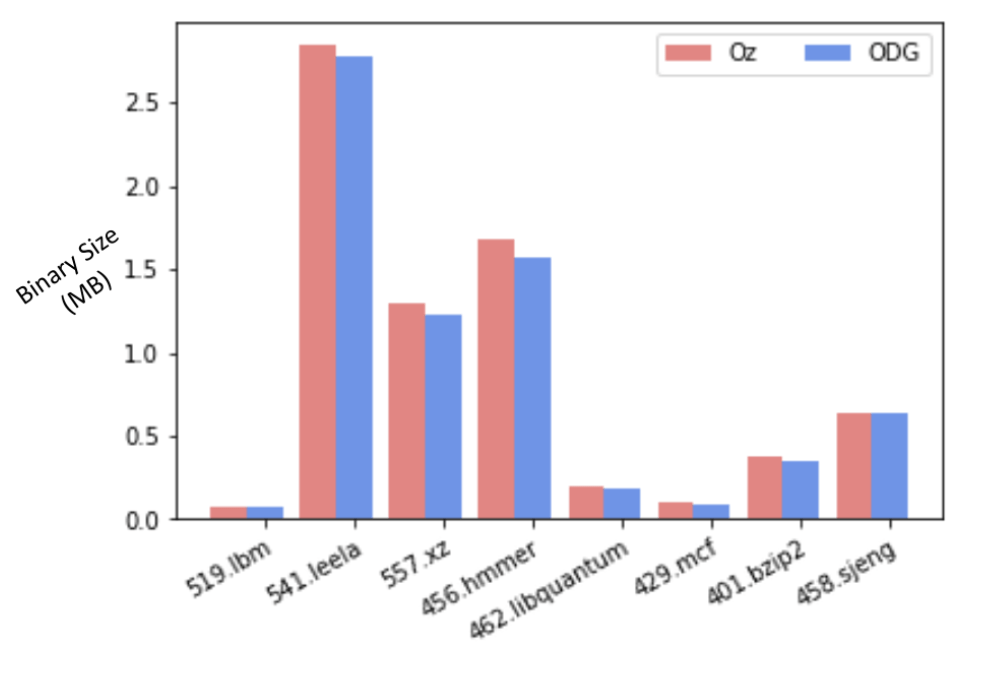
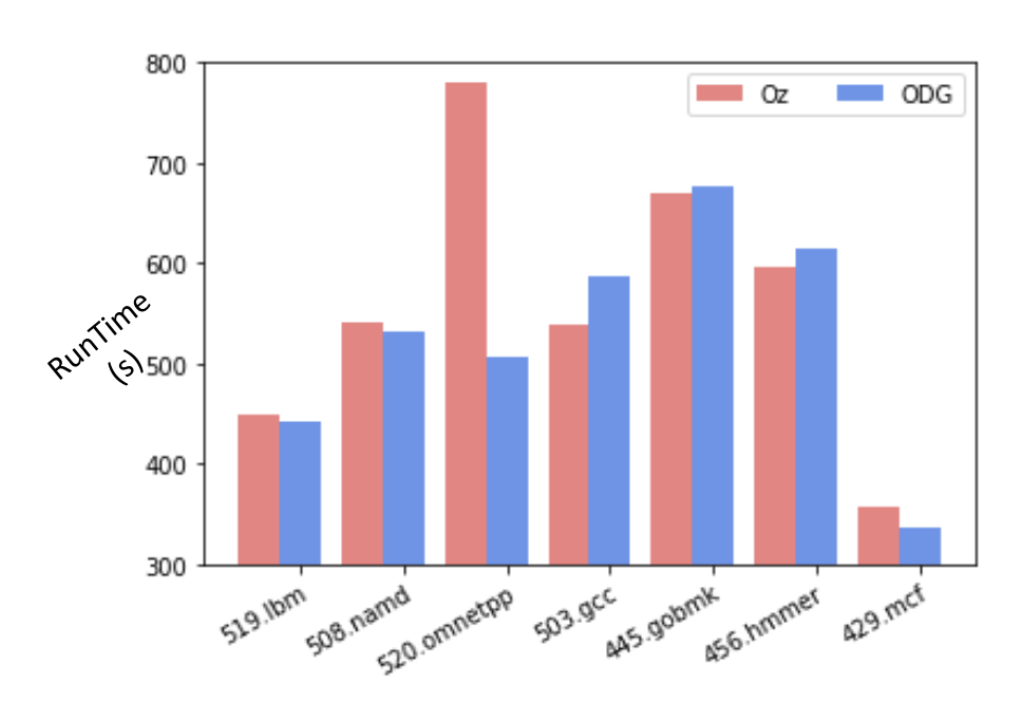
50/61
Сравнение всех решений - бенчмарки
Auto Vectorization
Loop Distibution
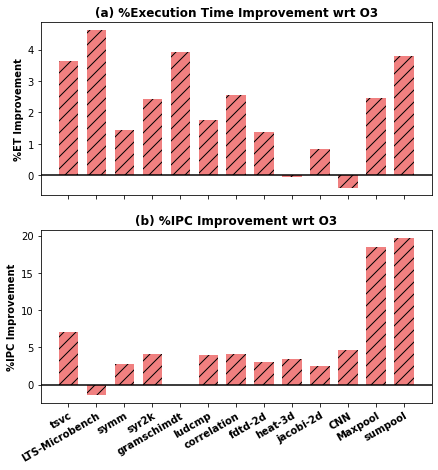
Phase Ordering Problem
51/61
Сравнение всех решений - бенчмарки
Phase Ordering Problem
Register Allocation
RL4ReAl
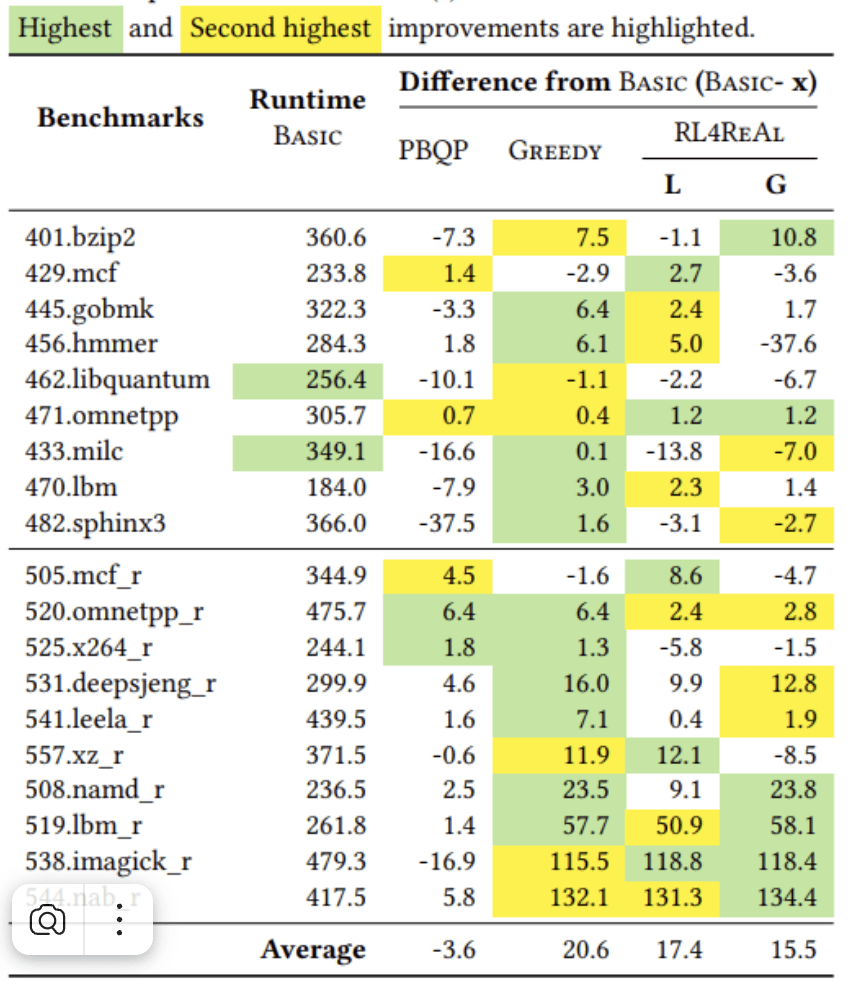
52/61
Сравнение всех решений - бенчмарки
Register Allocation
MLGO
Утверждается, что получался прирост от 0.3% до 1.5% запросов в секунду
53/61
Сравнение всех решений - бенчмарки
Inlinig
MLGO
Результаты Oz:
clang 3%
SPEC2006: до 6% (в среднем 1.75%)
Внутри Google: до 7%
54/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 4 потоках: ~ 1 час
Размер директории ./bin: 3.560 G
clang - 190.6 Mb
LLVM-18 -O3
55/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 16 потоках: ~ 1 день
Размер директории ./bin: 3.7772 G
clang - 203.16 Mb
CompilerGym RandomSearch - 1000 steps
56/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 16 потоках: ~ 1 день
Размер директории ./bin: 3.7772 G
clang - 203.16 Mb
CompilerGym RandomSearch - 1000 steps
Фокус не удался(
CompilerGym необходимо настраивать, из коробки не работает
56/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 16 потоках: ~ 1 день, но на больших файлах - fallback
Размер директории ./bin: 3.536 G
clang - 186.06 Mb
PosetRL -O3
57/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
PosetRL -O3
Фокус удался!
Из коробки получили прирост в codesize для O3 ~ 1.004
57/61
Время компиляции при 16 потоках: ~ 1 день, но на больших файлах - fallback
Размер директории ./bin: 3.536 G
clang - 186.06 Mb
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 16 потоках: ~ 1.5 дня, так еще и приходилось рестартовать (где-то память, где-то ошибки)
Размер директории ./bin: 3.579 G
clang - 188.8 Mb
RL4ReAl -O3
58/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
RL4ReAl -O3
Фокус под вопросом?
Оверхед на размер не большой
58/61
Время компиляции при 16 потоках: ~ 1.5 дня, так еще и приходилось рестартовать (где-то память, где-то ошибки)
Размер директории ./bin: 3.579 G
clang - 188.8 Mb
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 4 потоках: ~ 1 час
Размер директории ./bin: 4.381 G
clang - 219.65 Mb
LLVM-18 -Oz
59/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 4 потоках: ~ 1 час
Размер директории ./bin: 3.832 G
clang - 196.45 Mb
MLGO Inlinig -Oz
60/61
Сравнение всех решений - сборка LLVM
Дефолтная сборка LLVM
Время компиляции при 4 потоках: ~ 1 час
Размер директории ./bin: 3.832 G
MLGO Inlinig -Oz
60/61
Фокус удался!
Из коробки получили прирост в codesize для Oz ~ 1.143
Время компиляции при 4 потоках: ~ 1 час
Размер директории ./bin: 3.832 G
clang - 196.45 Mb
Заключение
Можно ли что-то применить сейчас?
Или пока не готово к промышленному использованию?
61/61
Заключение
Можно ли что-то применить сейчас?
Или пока не готово к промышленному использованию?
Творческий вопрос, на который каждый сам ответит)
Но если не чуть-чуть приложить усилия и обучить модели - вполне!
61/61
The end!
Литвинов Михаил
@litvinovmitch11

Ссылки
CompilerGym - https://compilergym.com
AutoPhase - https://arxiv.org/pdf/2003.00671
Inst2Vec - https://arxiv.org/pdf/1806.07336
ProGraML - https://arxiv.org/pdf/2003.10536
CompilerGym GitHub - https://github.com/facebookresearch/CompilerGym
IITH - POSET-RL - https://compilers.cse.iith.ac.in/projects/posetrl
IITH - IR2VEC - https://compilers.cse.iith.ac.in/projects/ir2vec
IITH - LoopDist - https://compilers.cse.iith.ac.in/publications/rl_loop_distribution
IITH - RL4ReAl - https://compilers.cse.iith.ac.in/publications/rl4real
IITH - ML-LLVM - https://github.com/IITH-Compilers/ml-llvm-project
62/61