The Snowflake Elastic Data Warehouse
Papers We Love San Diego
February 6th, 2020
Presented by Michael Jalkio

Today
- Data Warehousing History
- Enter Snowflake, Inc.
- Innovations in the paper
- Changes in the last few years
Data Warehousing History
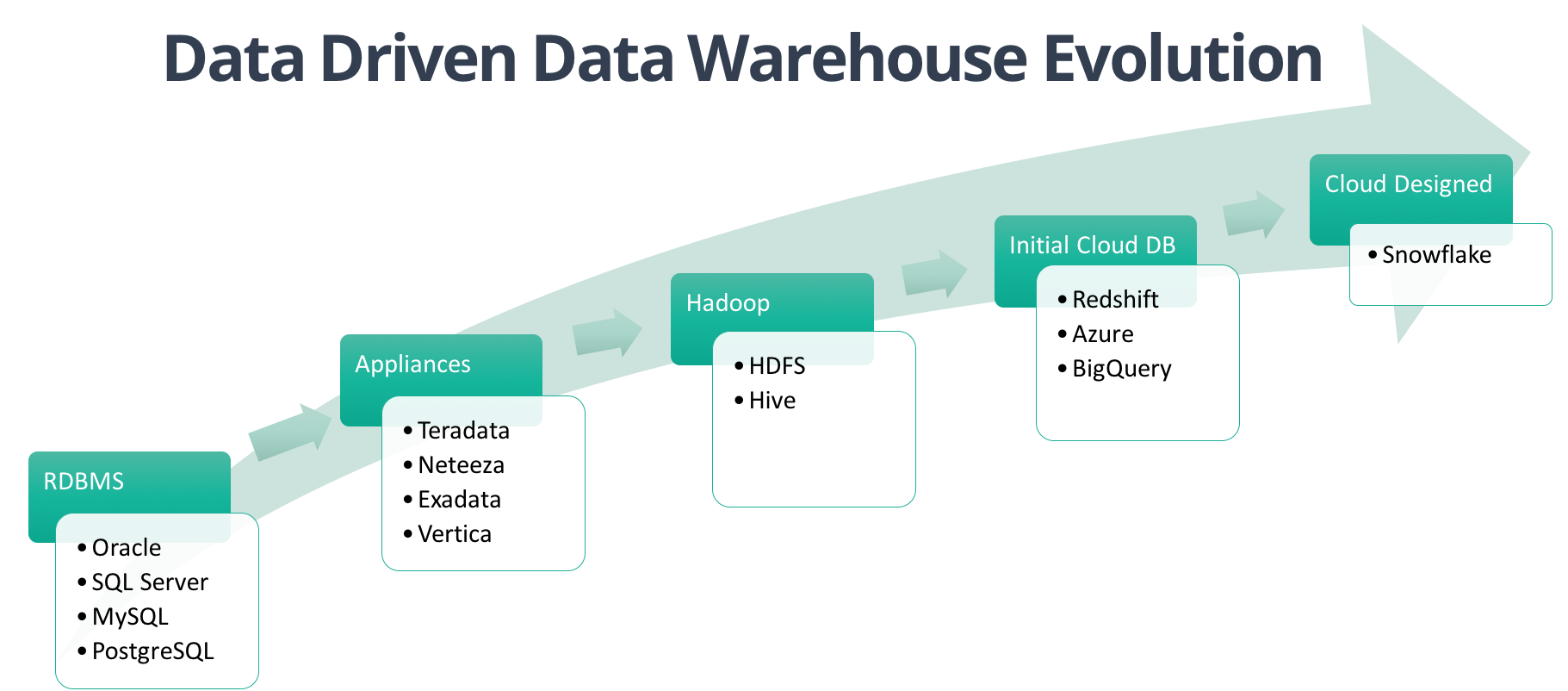
Relational Database Management System (RDBMS)
- First proposed by EF Codd at IBM in 1970
- Commercial systems available from 1979 (with SQL)
- SQL Server (1989), MySQL (1995), PostgreSQL (1996)
- Mainly designed for transaction processing, start to hit issues with scaling
OLTP vs OLAP Databases
- OLTP = Transaction = Row-Based
- OLAP = Analytics = Column-Based
- OLAP is optimized for aggregations over large datasets
- OLTP is optimized for INSERTs, UPDATEs, DELETEs, etc.
Specialized DW Appliances
- Teradata, Netezza, Vertica, etc.
- Massively parallel processing (MPP) architectures
- Very expensive, only for large enterprises
- No elasticity, Monday mornings are very hard

Google File System (2003)
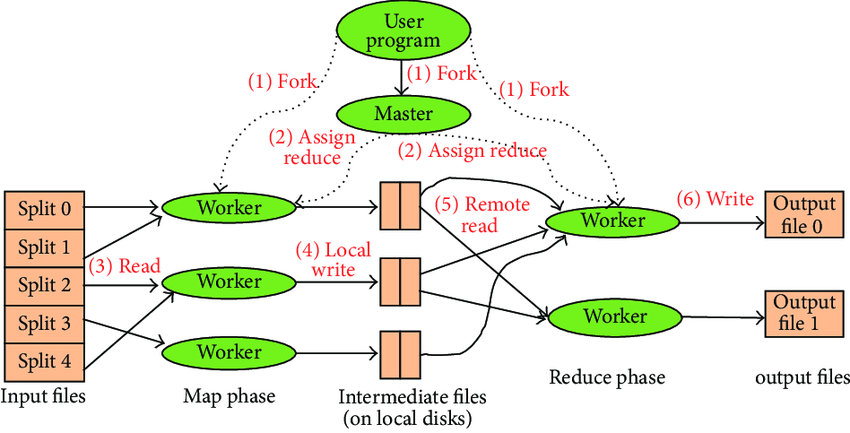
MapReduce (2004)
Hadoop (2006)

Issues with the Hadoop Ecosystem
- New model to gain expertise in
- Didn't play nicely with existing tooling
- Complemented the data warehouse
AWS (2006)

BigQuery (2010)

Redshift (2012)

Snowflake (2014/2015)

About Snowflake
- Raised over $920M with a valuation of $3.9B
- 1,400+ customers
- ~1,000 employees
- Available on all major public clouds
The Paper!
Introduction
- The cloud is great
- Data warehouses (DWs) don't fit the cloud model
- Today's data can't be processed by many DWs
- Big Data platforms don't fit the DW model
- Can we build a DW for the cloud?
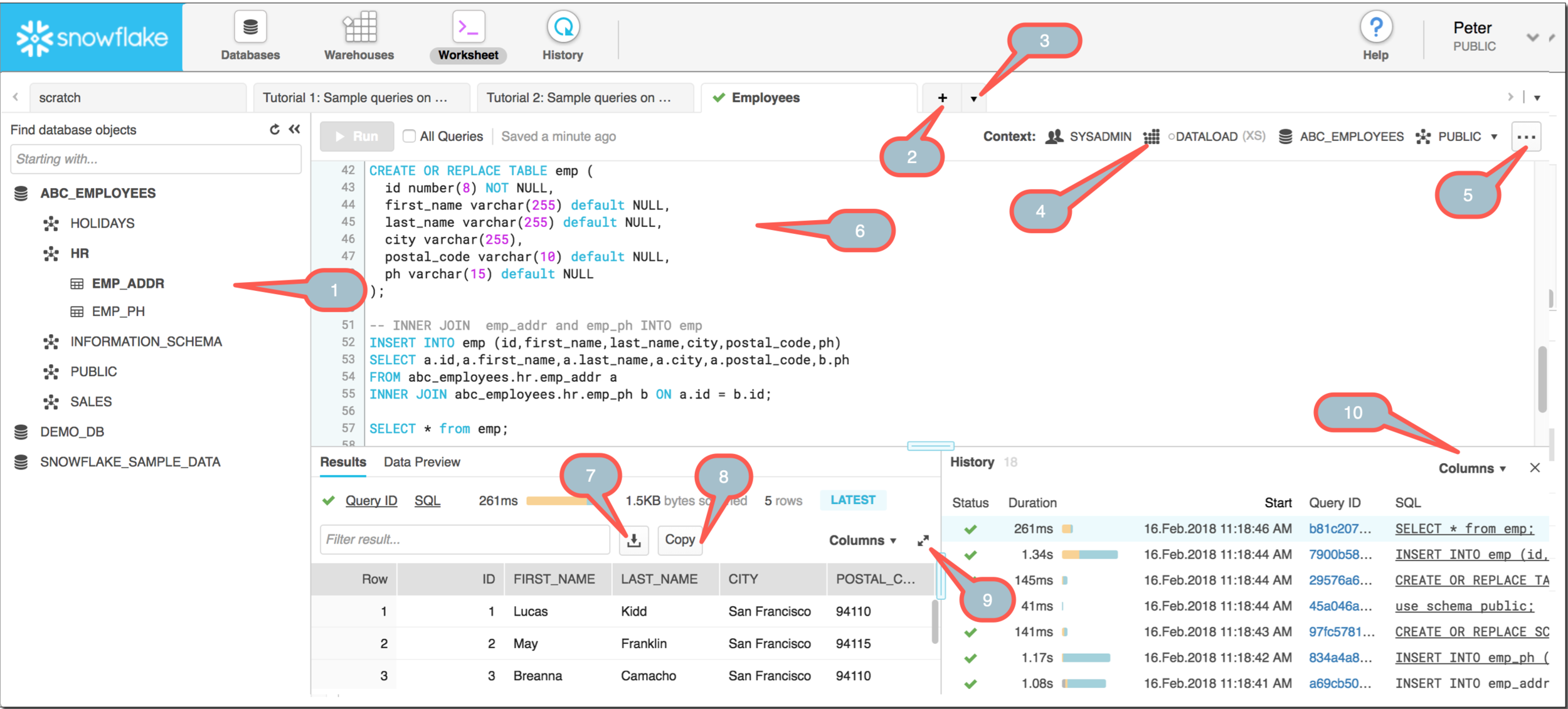
Key Features of Snowflake
- Software-as-a-service (SaaS) experience
- Relational w/ ANSI SQL and ACID transactions
- Semi-Structured data support (JSON)
- Elastic: storage and compute are independent
- Highly available
- Durable
- Cost-efficient
- Secure
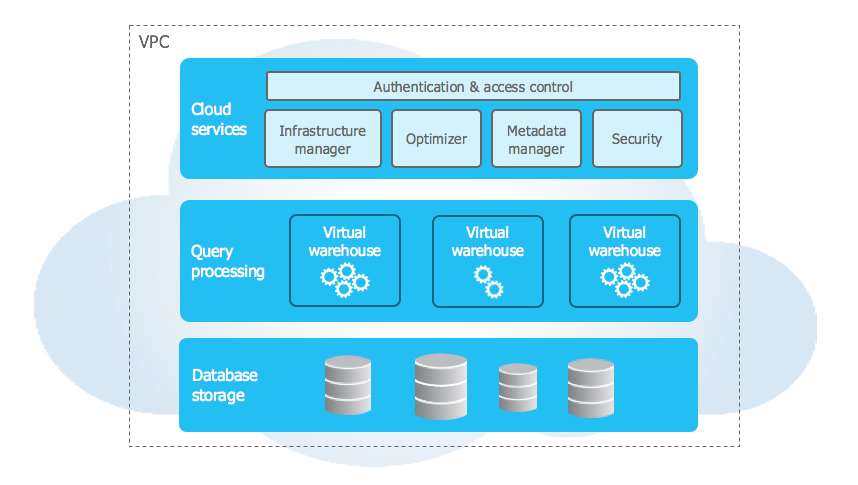
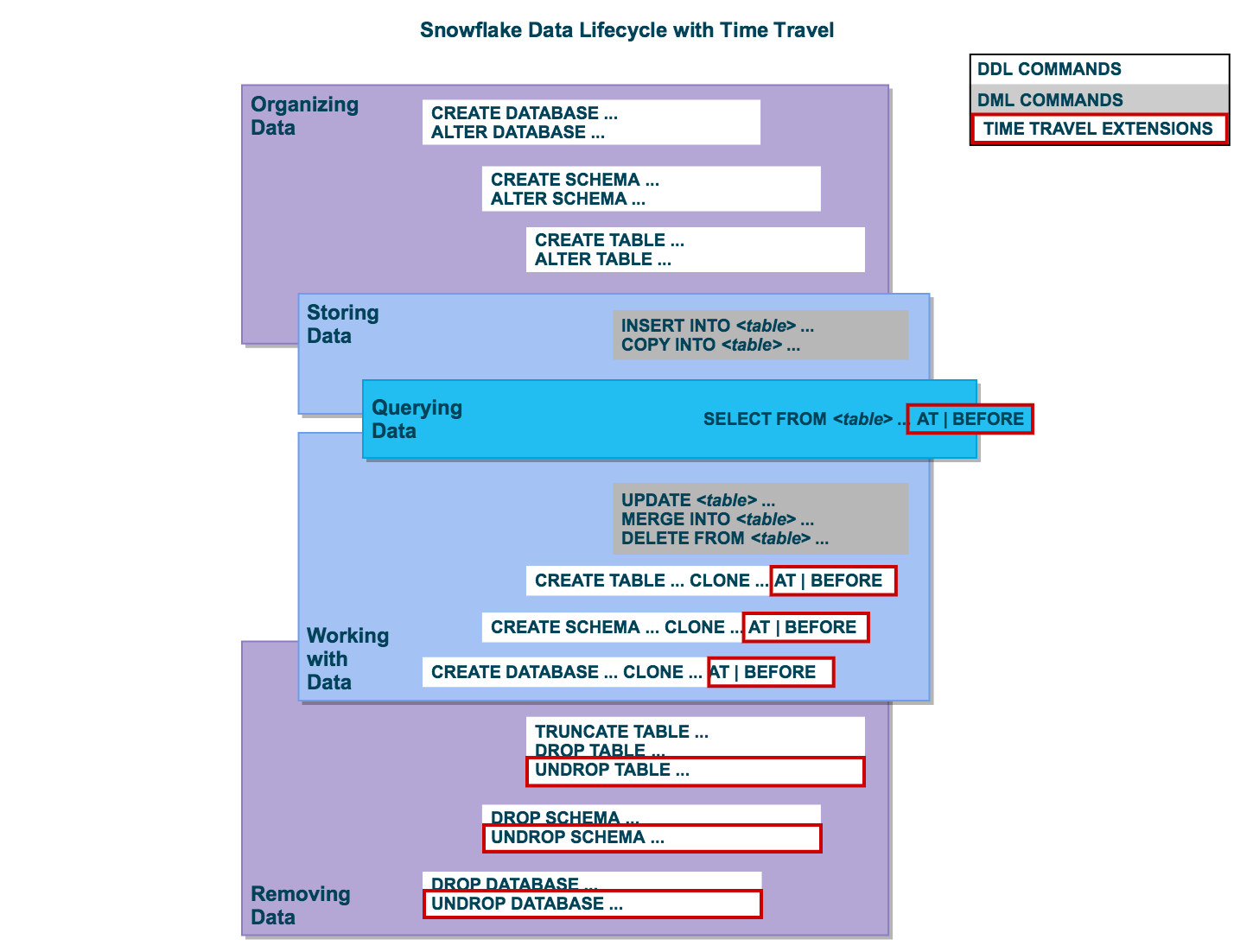
The Secret Sauce
- Random access of files & custom data format
- Columnar storage lends itself to compression

The Secret Sauce
- Provides availability & durability
- Immutability provides some of Snowflake's best features
- Storage is cheap
Virtual Warehouses
- Easy to start/stop and scale up/down
- Allows different teams/processes to be isolated
- Claims of "better performance for same price"
Cloud Stuff
- Fault resilience across AZs (except warehouses)
- Designed to be seamlessly upgraded
JSON/XML Support
- Allows Snowflake to be used for ELT
- Basically encourages you to dump tons of data straight into your warehouse
- Automated type inference for columnar storage
- Happens for each file, which supports schema changes over time and makes it more efficient
- Optimistic conversion of types
Snowflake vs Competitors
(at the time)
Redshift
- No database maintenance and tuning
- Faster scale up and down
- Compute and storage are separated
- JSON support
BigQuery
- Actual ANSI SQL
- Supports updates and deletes for data
Today...
Redshift Spectrum
- Allows compute and storage to be separated
- Files in S3 need to be managed manually and schema needs to be defined
- Still requires a Redshift cluster (but it's not used)
- Compute capacity is not something the user controls
- Pay per data scanned, not servers
BigQuery
- It's really, really good now
- No tuning (not even t-shirt sizes)
- Pay per-query or for dedicated resources
Questions?
