Abasictaskinfirstlanguageacquisitionlikelyinvolvesdiscoveringtheboundariesbetweenwordsormorphemesininputwherethesebasicunitsarenotovertlysegmented...
A basic task in first language acquisition likely involves discovering the boundaries between words or morphemes in input
where these basic units are not overtly segmented.
Started in 2017... Just published!

Why to present it?
- mini-case of development issues in the team
- was a set of heteregoneous tools from various sources
- needed a unified pipeline, easy to use, reliable
What inside?
- a Python library and collection of command-line tools
- several algorithms (pure Python or wrapped C++)
- standardized interfaces and evaluations
- good coding standards
Full pipeline for word segmentation
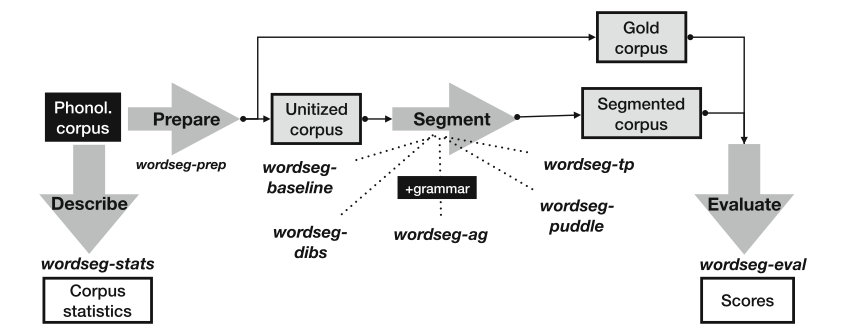
A "hello world" example
$ echo "hello world" | phonemize -p ' ' -w ';eword ' -b festival
hh ax l ow ;eword w er l d ;eword
$ echo "hh ax l ow w er l d" | wordseg-baseline -P 0.2
hhaxloww erld$ echo "hh ax l ow ;eword w er l d ;eword " | wordseg-prep -p' ' -w';eword' -g gold.txt
hh ax l ow w er l d
$ cat gold.txt
hhaxlow werld- text preparation
- text phonemization
- text segmentation
- segmentation evaluation
$ echo "hhaxloww erld" | wordseg-eval gold.txt
token_fscore 0
type_fscore 0
boundary_all_fscore 0.6667
boundary_noedge_fscore 0
... more skipped ...Segmentation algorithms
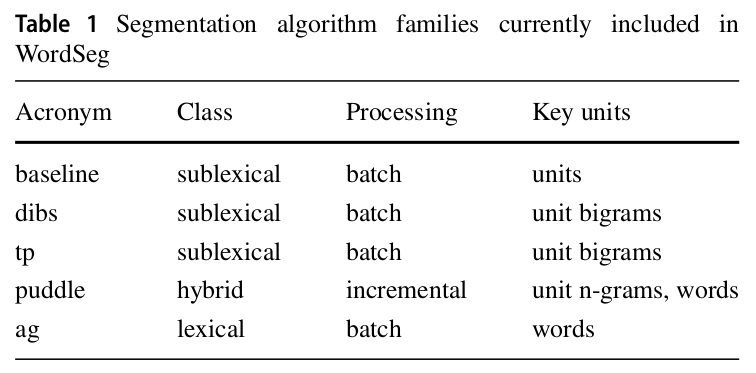
dpseg ?? ?? ?? C++ external (bug)
language origin
python own
python external
python own
python internal
C++ external
heteregoneous implementation but homogoneous interface :
- python
- bash
segmented_text = segment(input_text, **args)cat input_text | wordseg-XXX [--args] > segmented_textCoding standards
- coding style
- unit tests
- docstrings
- hosting
hosted on private gitlab => deploy to oberon
mirrored on public github => public access
- continuous integration

def gold(text, separator=Separator()):
"""Returns a gold text from a phonologized one
The returned gold text is the ground-truth segmentation. It has
phone and syllable separators removed and word separators replaced
by a single space ' '. It is used to evaluate the output of
segmentation algorithms.
Parameters
----------
text : sequence
The input text to be prepared for segmentation. Each element
of the sequence is assumed to be a single and complete
utterance in valid phonological form.
separator : Separator, optional
Token separation in the `text`
Returns
-------
gold_text : generator
Gold utterances with separators removed and words separated by
spaces. The returned text is the gold version, against which
the algorithms are evaluated.
"""
# delete phone and syllable separators. Replace word boundaries by
# a single space.
gold = (line.replace(separator.syllable, '')
.replace(separator.phone or '', '')
.replace(separator.word, ' ') for line in text)
# delete any duplicate, begin or end spaces. As for prepare, we
# ignore empty lines.
return (line for line in (utils.strip(line) for line in gold) if line)
Docstrings using sphinx
Unit tests using pytest
def test_paiwise():
assert list(_pairwise([])) == []
assert list(_pairwise([1])) == []
assert list(_pairwise([1, 2])) == [(1, 2)]
assert list(_pairwise([1, 2, 3])) == [(1, 2), (2, 3)]
@pytest.mark.parametrize('utt', BAD_UTTERANCES)
def test_bad_utterances(utt):
with pytest.raises(ValueError):
check_utterance(utt, separator=Separator())
@pytest.mark.parametrize('utt', GOOD_UTTERANCES)
def test_good_utterances(utt):
assert check_utterance(utt, separator=Separator())
@pytest.mark.parametrize(
'utt', ['n i2 ;eword s. w o5 ;eword s. əɜ n ;eword m o-ɜ ;eword',
'ɑ5 ;eword j iɜ ;eword (en) aɜ m (zh) ;eword',
't u b l i ;eword p o i i s^ s^ ;eword'])
def test_punctuation(utt):
with pytest.raises(ValueError):
list(prepare([utt], check_punctuation=True))
list(prepare([utt], check_punctuation=False))
def test_empty_lines():
text = ['', '']
assert len(list(prepare(text))) == 0
assert len(list(gold(text))) == 0
text = [
'hh ax l ;esyll ow ;esyll ;eword',
'',
'hh ax l ;esyll ow ;esyll ;eword']
assert len(list(
prepare(text, separator=Separator(), unit='phone'))) == 2
assert len(list(gold(text, separator=Separator()))) == 2
(wordseg) mathieu@deaftone:~/dev/wordseg$ pytest
============================= test session starts ==============================
platform linux -- Python 3.7.2, pytest-4.3.1, py-1.8.0, pluggy-0.9.0
cachedir: .pytest_cache
rootdir: /home/mathieu/dev/wordseg, inifile: setup.cfg
plugins: cov-2.6.1
collected 290 items
test/test_algo_ag.py::test_grammar_files PASSED [ 0%]
test/test_algo_ag.py::test_check_grammar PASSED [ 0%]
test/test_algo_ag.py::test_segment_single PASSED [ 1%]
test/test_algo_ag.py::test_counter PASSED [ 1%]
test/test_algo_ag.py::test_yield_parses PASSED [ 1%]
test/test_algo_ag.py::test_setup_seed PASSED [ 2%]
test/test_algo_ag.py::test_ignore_first_parses[-10] PASSED [ 2%]
test/test_algo_ag.py::test_ignore_first_parses[-5] PASSED [ 2%]
test/test_algo_ag.py::test_ignore_first_parses[-1] PASSED [ 3%]
test/test_algo_ag.py::test_ignore_first_parses[0] PASSED [ 3%]
test/test_algo_ag.py::test_ignore_first_parses[5] PASSED [ 3%]
test/test_algo_ag.py::test_ignore_first_parses[6] PASSED [ 4%]
test/test_algo_ag.py::test_parse_counter[1] PASSED [ 4%]
test/test_algo_ag.py::test_parse_counter[2] PASSED [ 5%]
test/test_algo_ag.py::test_parse_counter[4] PASSED [ 5%]
test/test_algo_ag.py::test_parse_counter[10] PASSED [ 5%]
test/test_algo_ag.py::test_default_grammar PASSED [ 6%]
test/test_algo_ag.py::test_mark_jonhson PASSED [ 7%]
test/test_algo_baseline.py::test_proba_bad[1.01] PASSED [ 7%]
test/test_algo_baseline.py::test_proba_bad[-1] PASSED [ 7%]
test/test_algo_baseline.py::test_proba_bad[a] PASSED [ 8%]
test/test_algo_baseline.py::test_proba_bad[True] PASSED [ 8%]
test/test_algo_baseline.py::test_proba_bad[1] PASSED [ 8%]
test/test_algo_baseline.py::test_hello PASSED [ 9%]
test/test_algo_dibs.py::test_basic[gold-0-None] PASSED [ 9%]
test/test_algo_dibs.py::test_basic[gold-0-0.2] PASSED [ 10%]
test/test_algo_dibs.py::test_basic[gold-0.5-None] PASSED [ 10%]
...
test/test_wordseg_commands.py::test_command_help[baseline] PASSED [ 98%]
test/test_wordseg_commands.py::test_command_help[ag] PASSED [ 98%]
test/test_wordseg_commands.py::test_command_help[dibs] PASSED [ 98%]
test/test_wordseg_commands.py::test_command_help[dpseg] PASSED [ 99%]
test/test_wordseg_commands.py::test_command_help[tp] PASSED [ 99%]
test/test_wordseg_commands.py::test_command_help[puddle] PASSED [100%]
=================== 280 passed, 10 skipped in 45.54 seconds ====================Build system
- mix of Python and C++
- use CMake instead of setup.py
- not really portable on Windows
- provide a Docker image
git clone https://github.com/bootphon/wordseg.git
mkdir -p wordseg/build && cd wordseg/build
cmake ..
make
make test
make installContinuous integration
push
on master


build
test
install
oberon
mirror


build / test
test coverage
doc

citation
Usage on the cluster
./wordseg-slurm.sh <jobs-file> <output-directory> [<options>]- <jobs-files> defines the jobs, one per line
-
simply schedule a list of wordseg jobs
<job-name> <input-file> <unit> <separator> <wordseg-command>
exemple ./input.txt phone -p ' ' -w ';eword' wordseg-baseline -P 0.2- after execution, <output-directory>/<job-name> contains:
input.txt
gold.txt
stats.json
output.txt
eval.txt
eval_summary.json
log.txt
job.sh- for each job, execute the full processing pipeline
input | stats | prepare | segment | evaluate