Processing In Memory
Nayan Deshmukh
MEmory Wall
Since 1980, CPU has outpaced DRAM


The bandwidth Wall
The increase in pin count is not proportional to the increase in transistor density
what is the Solution?
- Cache Compression
- DRAM Cache
- Link Compression
- Sector Cache
reduce the memory traffic
But these are roundabout ways to avoid the actual problem
let's look more closely at the dram


Hybrid Memory Cube
<DETOUr>


HMC Structure
HMC structure




</DETOUr>
how to integrate PiM?
What modifications are needed in our existing architecture?
tesseract
A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing

page rank
for (v: graph.vertices) {
value = 0.85 * v.pagerank / v.out_degree;
for (w: v.successors) {
w.next_pagerank += value;
}
}list_for (v: graph.vertices) {
value = 0.85 * v.pagerank / v.out_degree;
for (w: v.successors) {
put(w.id, function() { w.next_pagerank += value; });
}
}Tesseract exploits:-
- Memory level parallelism
- DRAM internal bandwidth
- Offloading
Normal Code
PIM Code
Performance

-
DDR3-OoO: 32 4 GHz four-wide out of-order cores connected to a DDR3 memory system
-
HMC-OoO: 32 4 GHz four-wide out of-order cores
-
HMC-MC: 512 single-issue, in-order cores externally connected to 16 memory cubes
-
Tesseract: 512 single-issue, in-order cores with prefetchers on logic layer of memory cubes
-
32 cores per cube
-
What's the catch?
- Needs a lot of changes in software stack
- Fails to utilize the large on-chip caches
- Higher AMAT when results are accessed by host processor
Can we do better?

PIM-Enabled Instructions
(PEI)
Potential of ISA Extension as PIM Interface
The key to coordination between PIM and host processor is single-cache-block restriction
- Each PEI can access at most one last-level cache block
- Localization: each PEI is bounded to one memory module
- Interoperability: easier support for cache coherence and virtual memory
BENEFITS:-
architecture






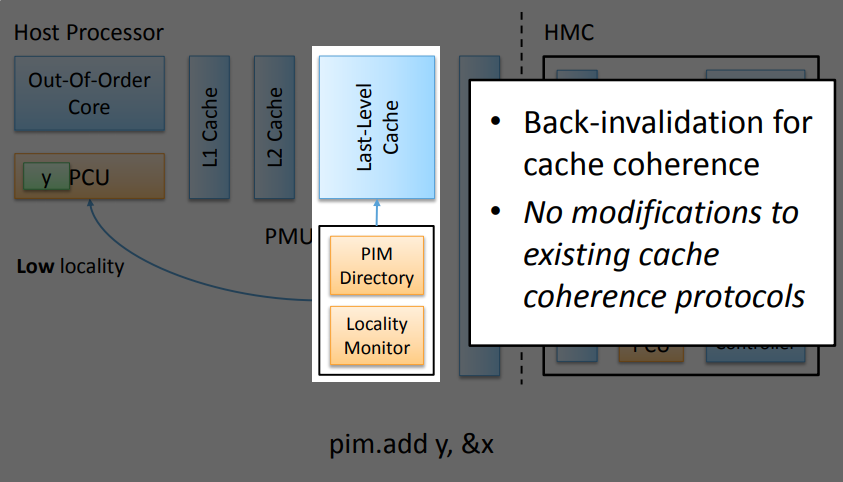


Memory-side PEI Execution
Host-side PEI Execution
conclusion
The speed gap between CPU, memory and mass storage continues to widen. We need to rethink our memory systems. Processing in Memory is one of the possible hope to fight the memory wall

Acknowledgements
- https://people.inf.ethz.ch/omutlu/pub/pim-enabled-
instructons -for-low-overhead-pim_isca15-talk.pdf - https://people.inf.ethz.ch/omutlu/pub/tesseract-
pim -architecture-for-graph-processing_isca15-talk.pdf - http://www.eecs.umich.edu/courses/eecs573/lectures/nmc_slides-main.pdf
- http://extremecomputingtraining.anl.gov/files/2015/03/kogge-jul29-1115.pdf
- http://www.hotchips.org/wp-content/uploads/hc_archives/hc23/HC23.18.3-memory-FPGA/HC23.18.320-HybridCube-Pawlowski-Micron.pdf
- http://www2.sbc.org.br/sbac/2015/files/Keynote_OnurMutlu.pdf