RL in Systems-land
Nikhilesh Singh
Many examples taken from David Silver's UCL course
(literally took screenshots this time!)
https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDMOYHWgPebj2MfCFzFObQ
What we know?
RL agent attributes
- Policy
- Value Function
- Model
The parts left out
- But, how exactly are the actions chosen?
- How do you update the values?
- It's all just tables, there is a limit to what we can store, right?
- My problem has states unimaginably large, what to do?
- How do you do it in real life? Any algorithm?
- ...
- Wait a minute, how did the AlphaGo guys did it?

Q. What do we want?
A. An optimal way to behave in the environment.
The Search for Optimality
To get the optimal policy
- Evaluation (Prediction Problem)
- Comparison
- Improvement (Control Problem)
Prediction
Some terms
- Return:
- Value function:
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots + \gamma^{T-1}R_{T}
v_\pi(s) = E_\pi[G_t | S_t=s]
Remember that Markov thingy?
- Since we are taking decisions we call it MDP.
- Markov Decision Process
- Just a fancy name for our setup!
- If we know the MDP, DP would do.
(\mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\gamma)
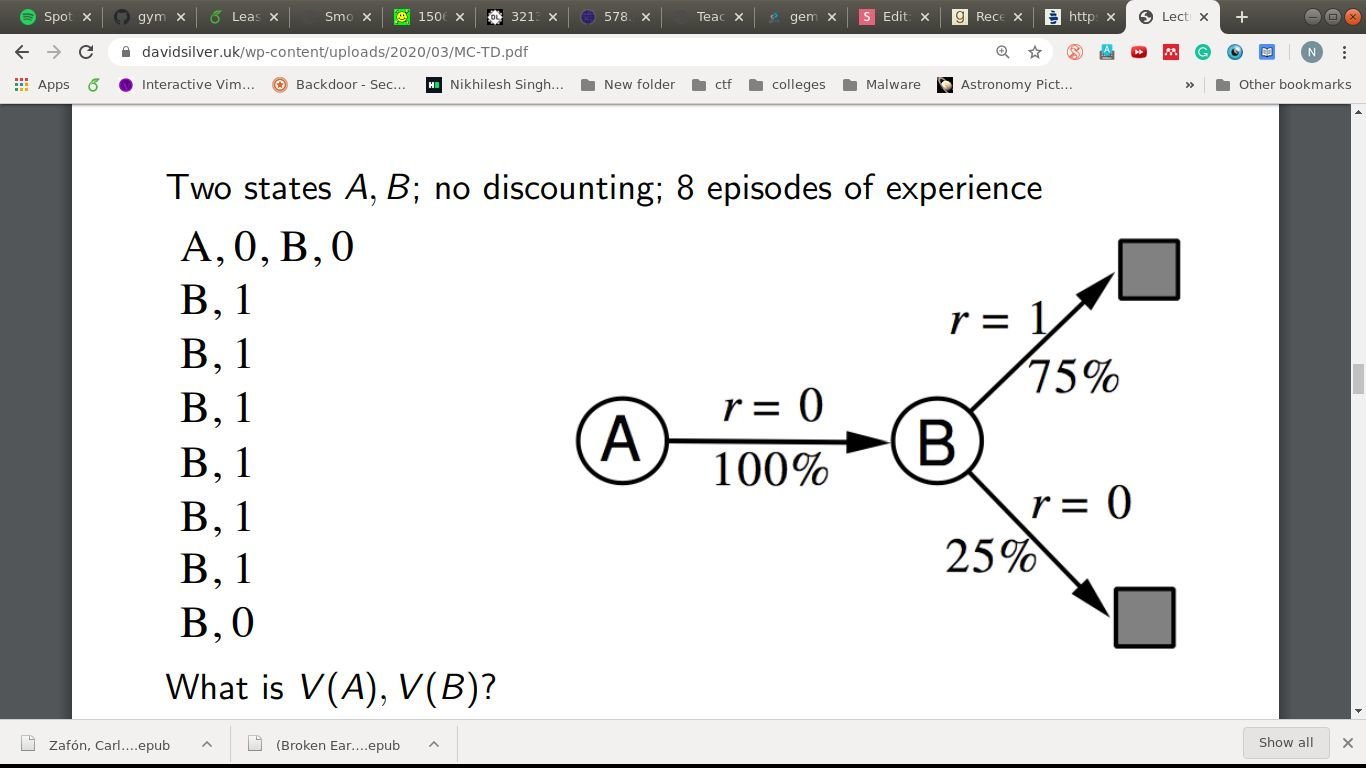
If we have an Oracle...
- Dynamic Programming
- Wait, doesn't DP require some properties?
- Optimal substructure
- Overlapping sub-problems
- MDPs have that, always!
Q. What if we have an unknown MDP?
A. We sample.
A common theme
- We want to estimate some value x.
- There is some Target value (some function of x) and the observed value.
- Error = Target - Observed
- Update x to push in the direction that reduces error
- x = x + k*(Target - Observed)
- Iterate
Q. I have a sample, what now?
A. Update accordingly.
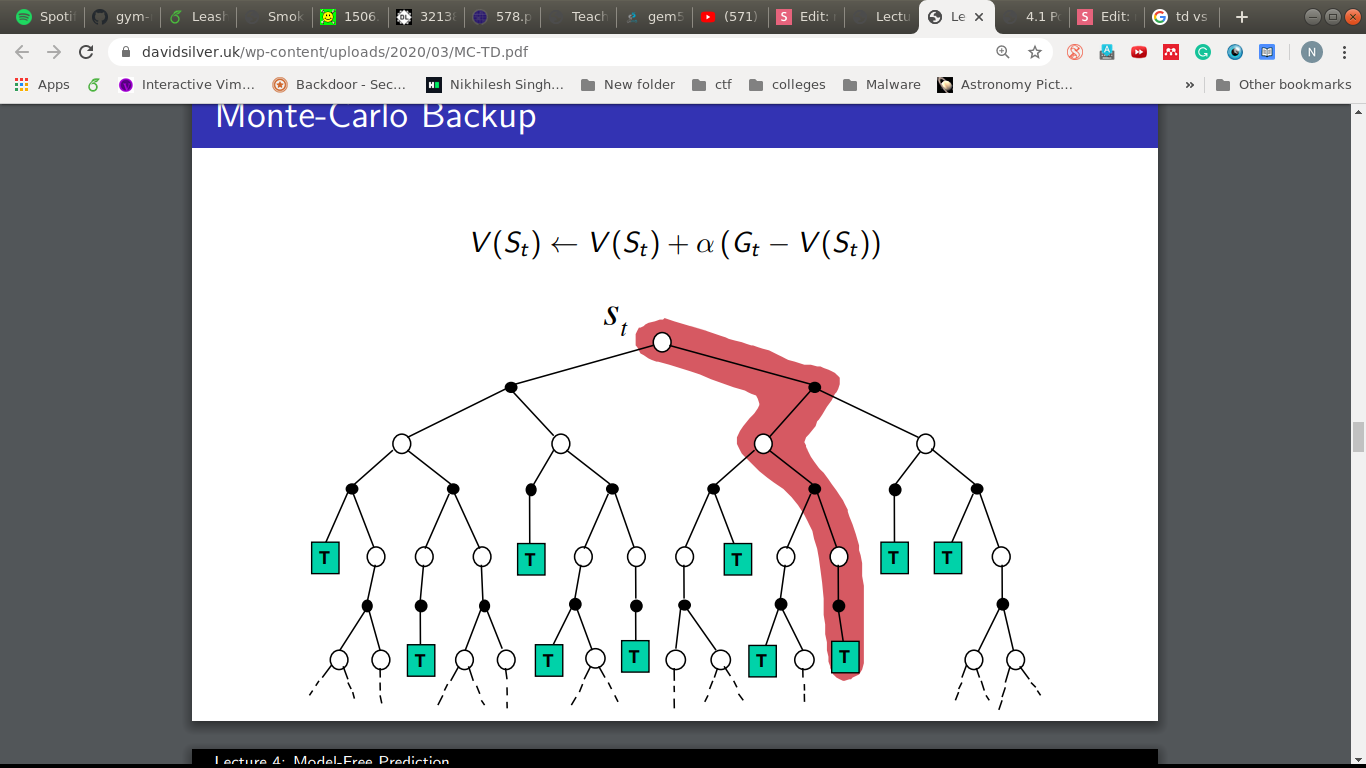
How about this?
- Generate an episode.
- Log when you visit a state.
- Take the average return you get from each state.
How about this?
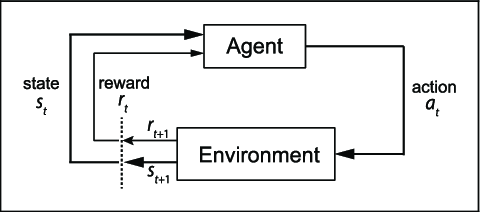
Monte-Carlo Policy Evaluation
- First-visit/Every-visit
- Updates done at the end of the episode.
- But what if the episodes are really, really long?
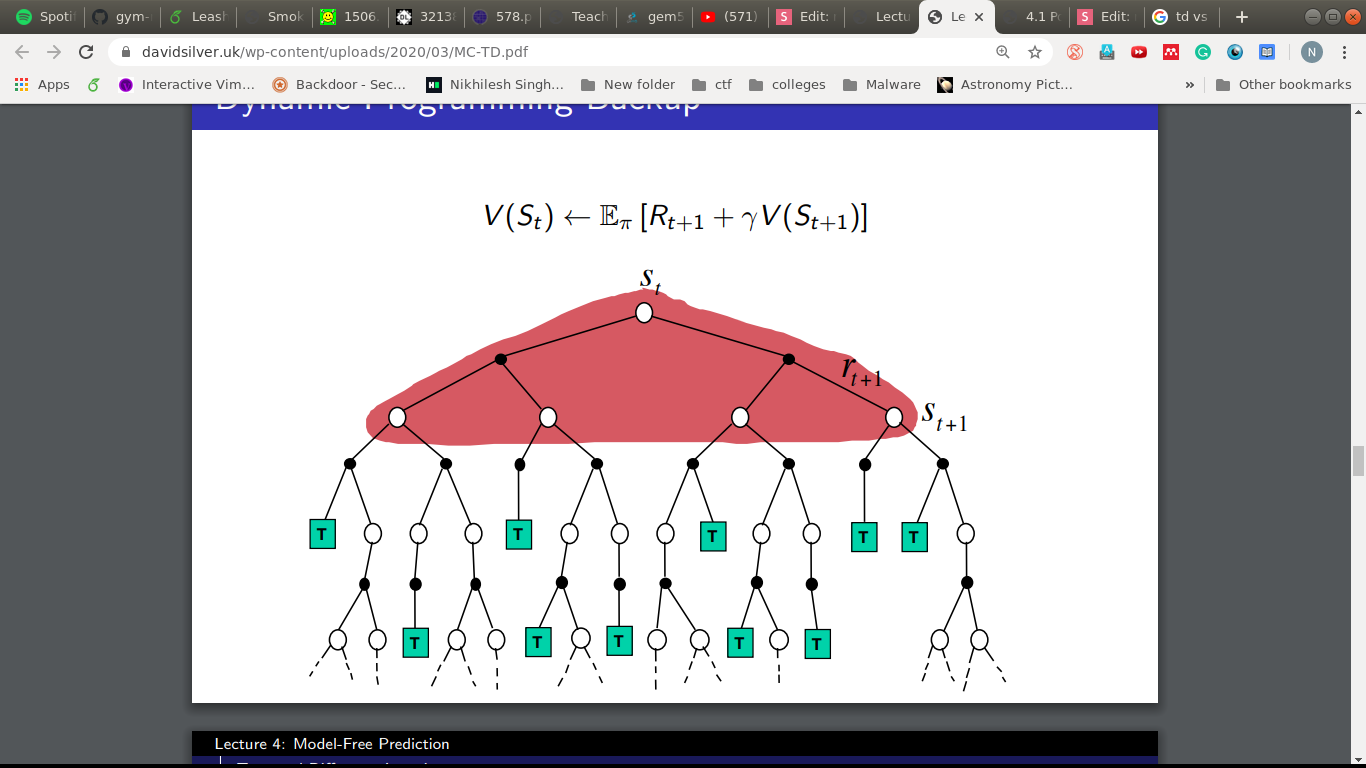
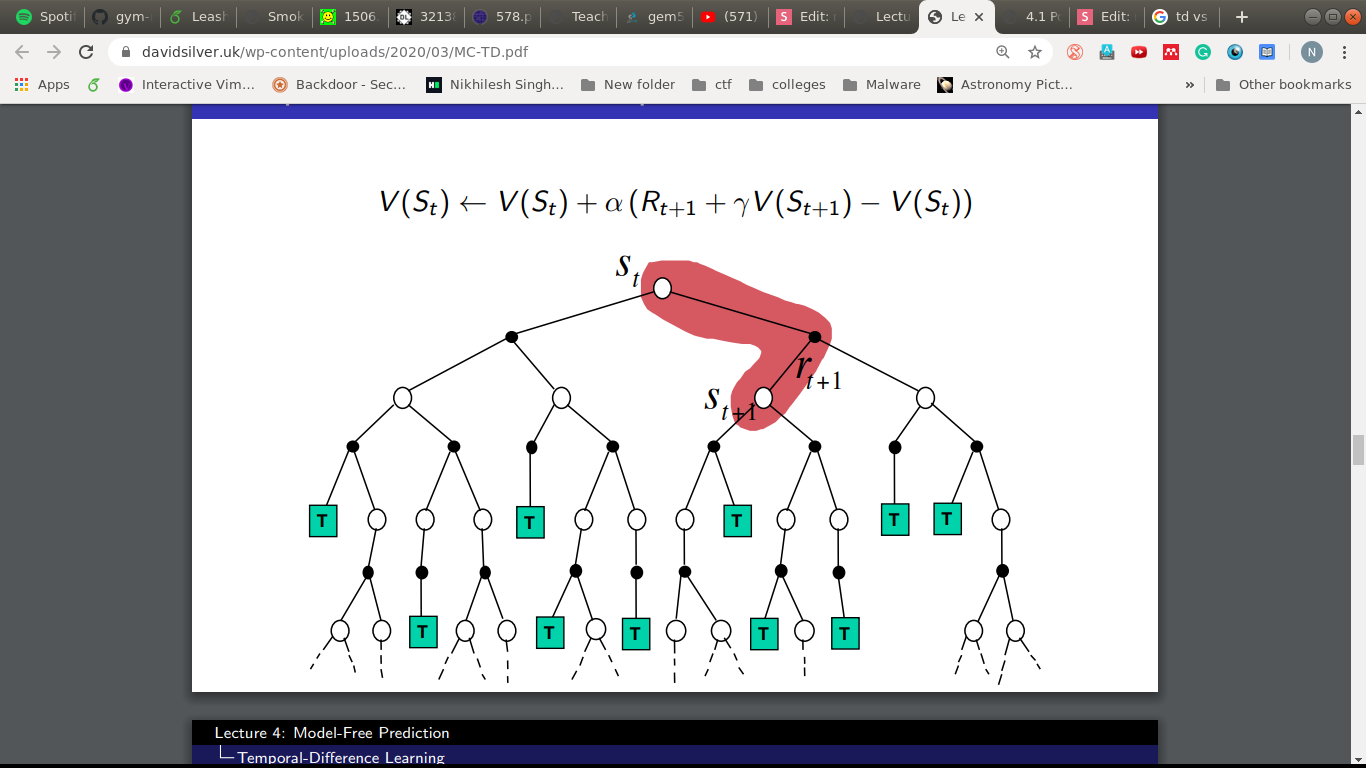
How about this?
- Try attempting updates at every step.
- But we need a target to move towards, G_t in MC.
- Idea: use the estimated return as the target.
How about this?

TD(0) Learning
- Incomplete episodes, bootstrapping.
- Guessing towards a guess.
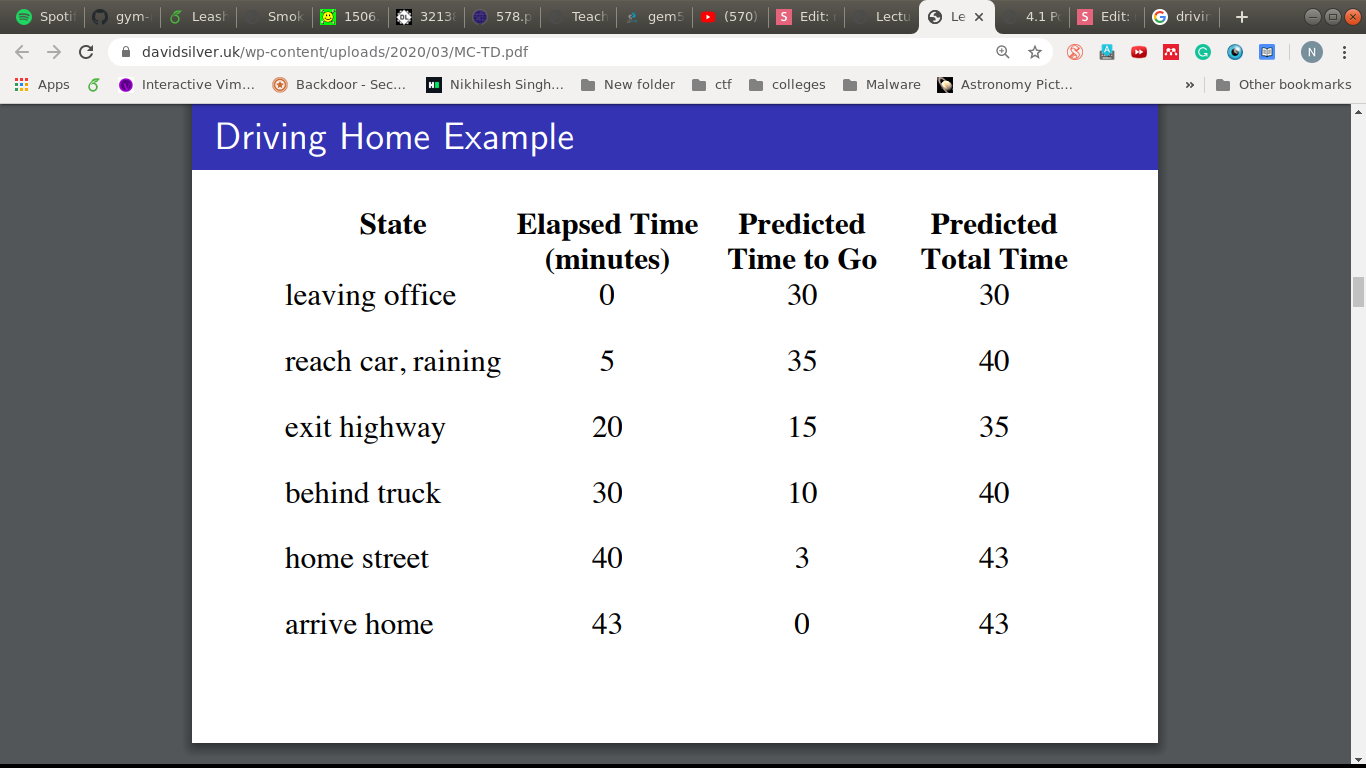
MC vs TD(0)
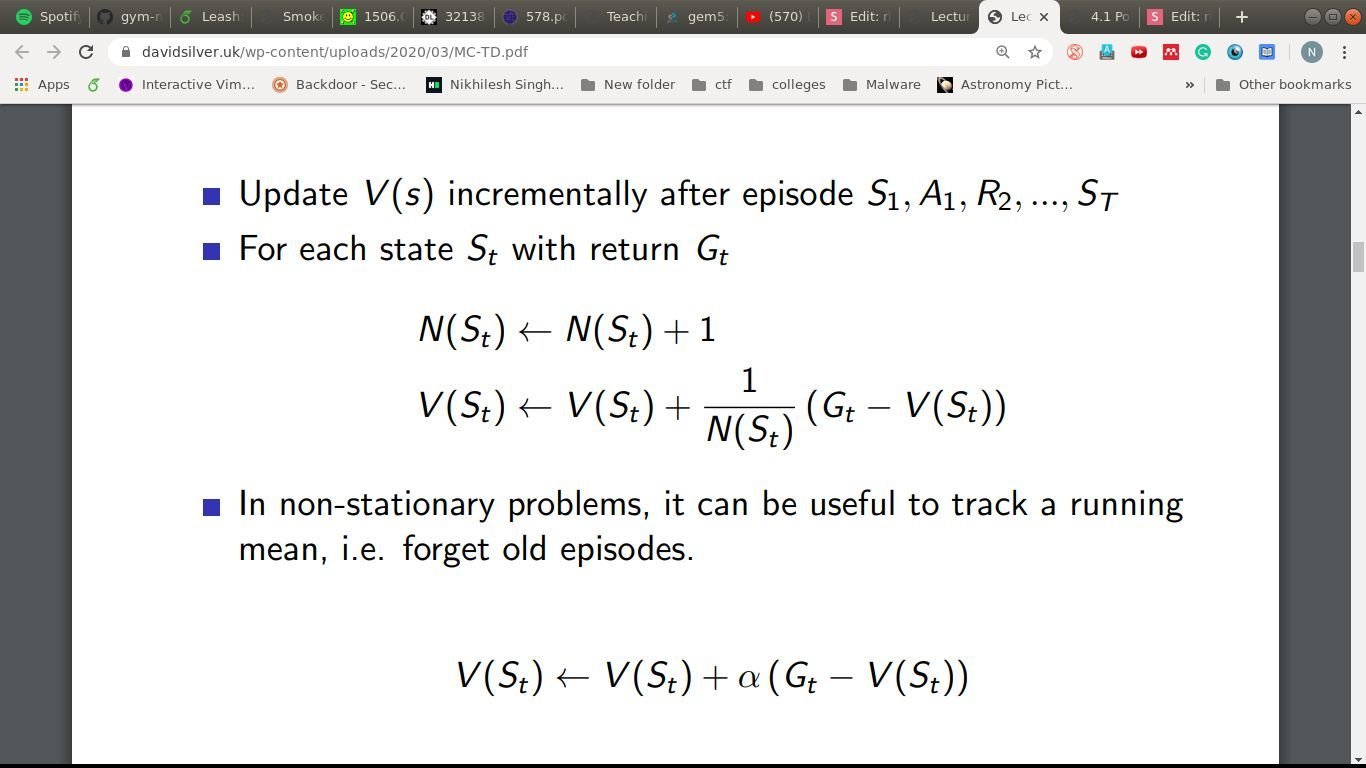
An overused example
- Two states, A and B, no discounting, 8 episodes.
- A,0,B,0
- B,1
- B,1
- B,1
- B,1
- B,1
- B,1
- B,0
- V(A) = ?, V(B) = ?
MC
- Best Fit to observed returns
- V(B) = 6/8 = 0.75
- V(A) = avg return when A was visited = 0/1 = 0
TD(0)
- Solution to the underlying MDP
- V(B) = 0.25*0 + 0.75*1 = 0.75
- V(A) = avg on all transitions = (1*(0.75)) = 0.75
DP
MC vs TD(0)
The link
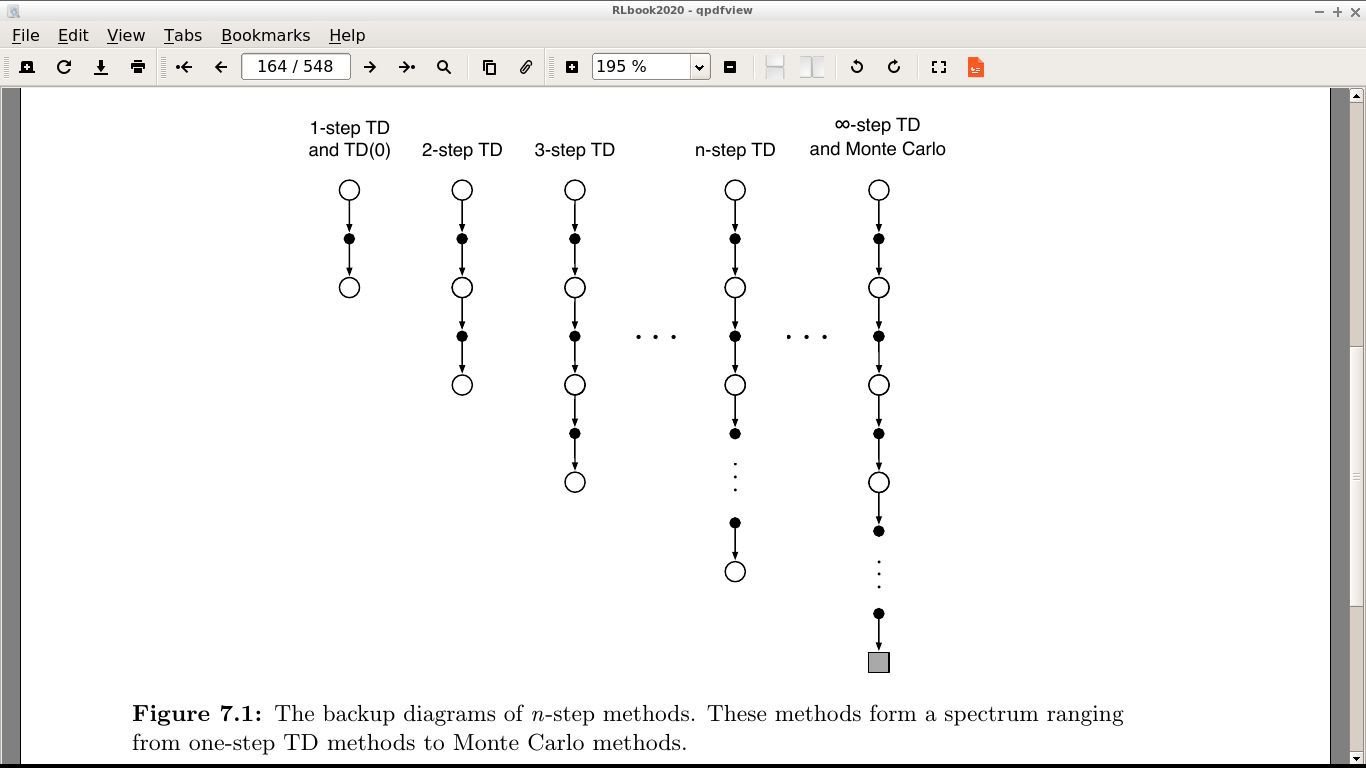
Mean of all worlds!
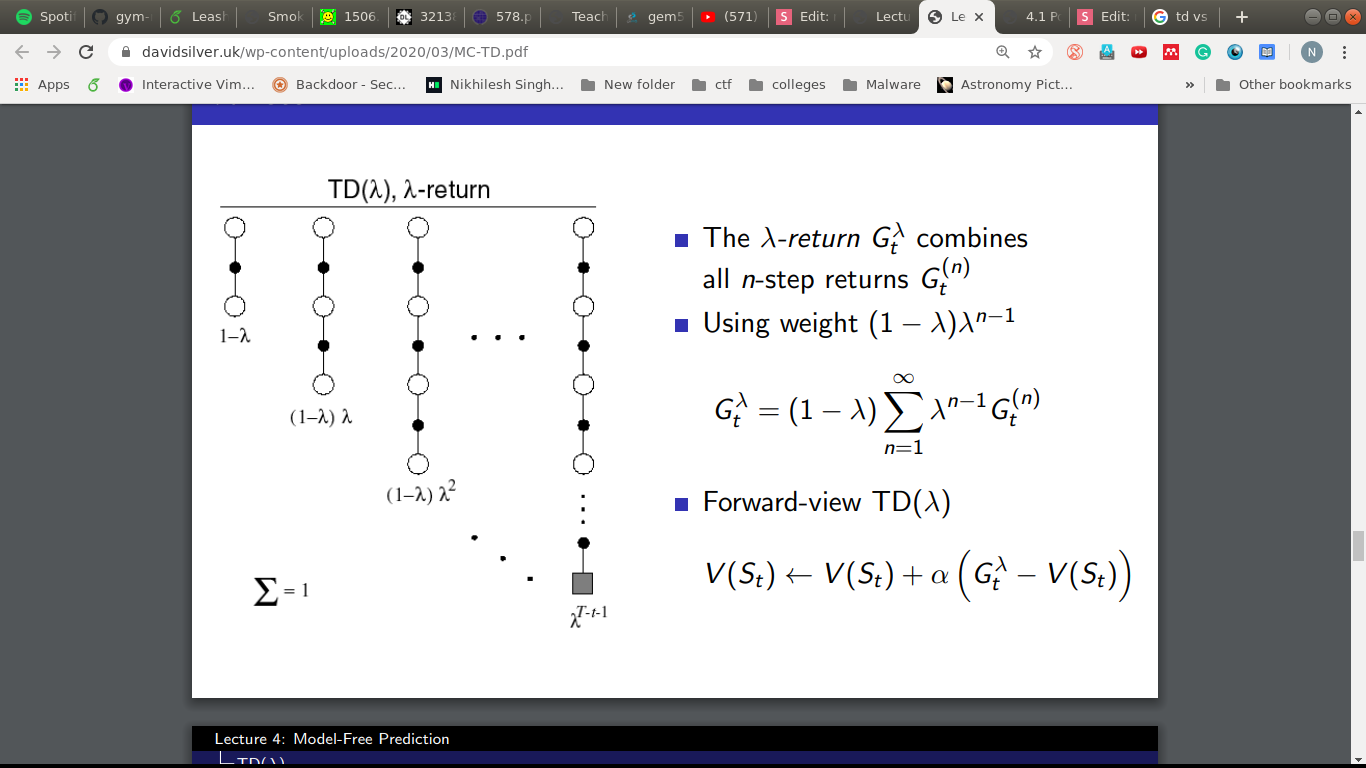
Put lambda = 0 and it becomes TD(0)
Are we done?
- We have solved the Prediction Problem.
- We still have to solve Control, to improve and get the optimal behavior.
Control
Value Function
- V(s) - State Value Function
- Q(s,a) - State-Action Value Function
A common theme
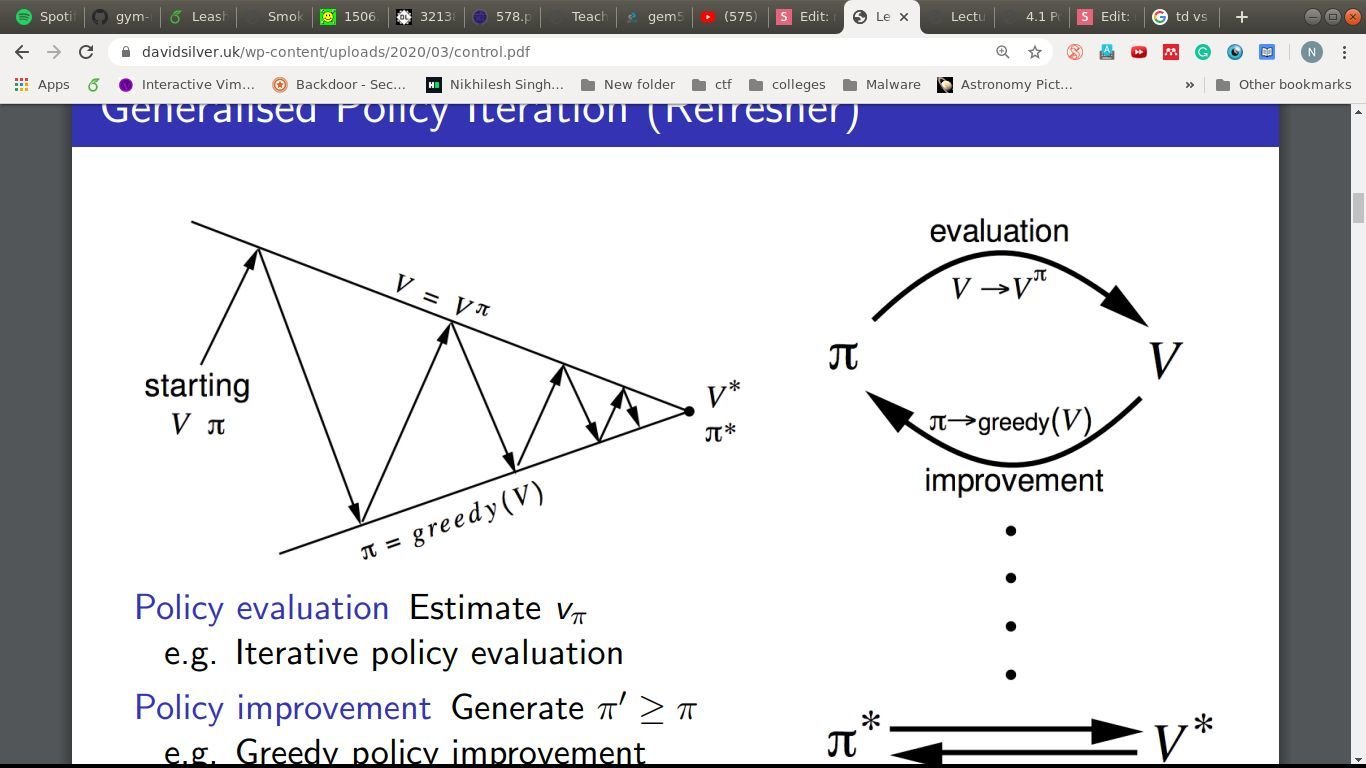
Policy Evaluation: Estimate
Policy Improvement: Generate
\pi^\prime \geq \pi
V_\pi
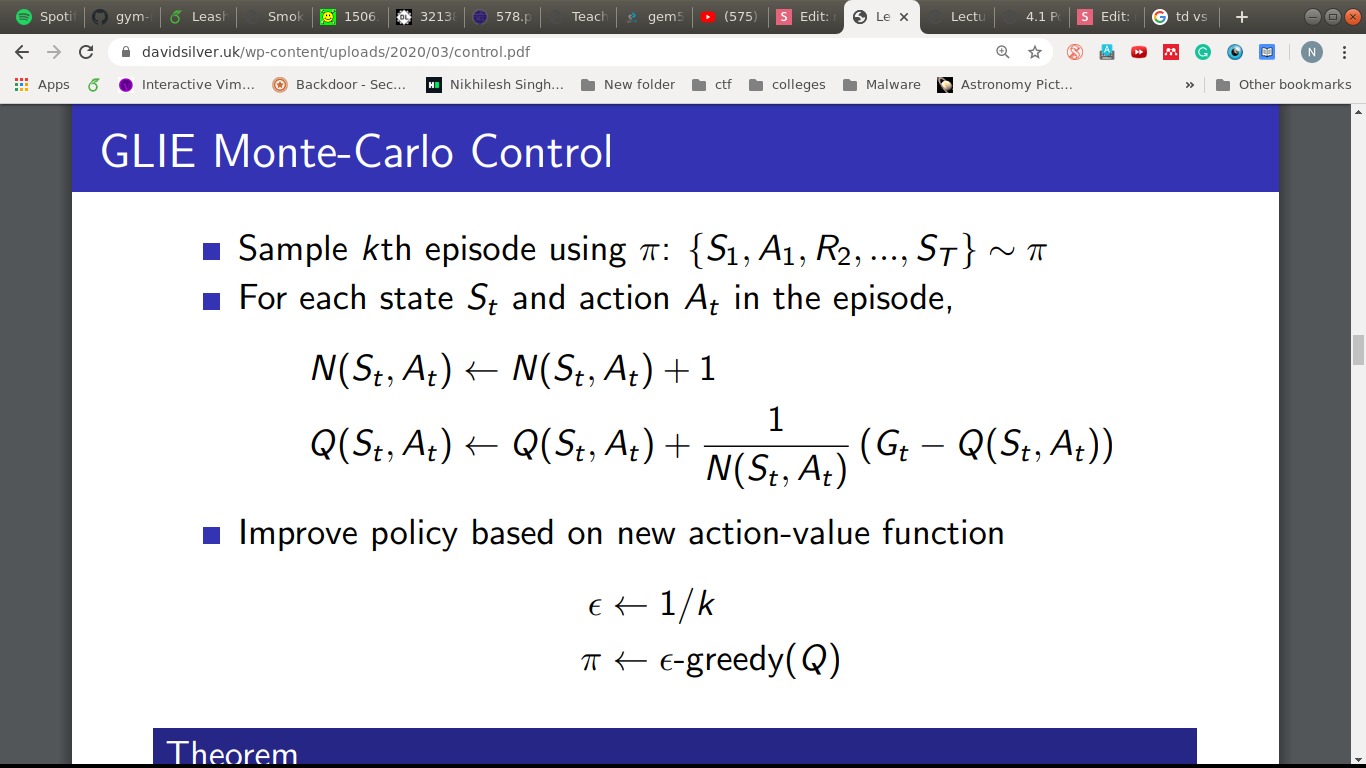
Monte-Carlo
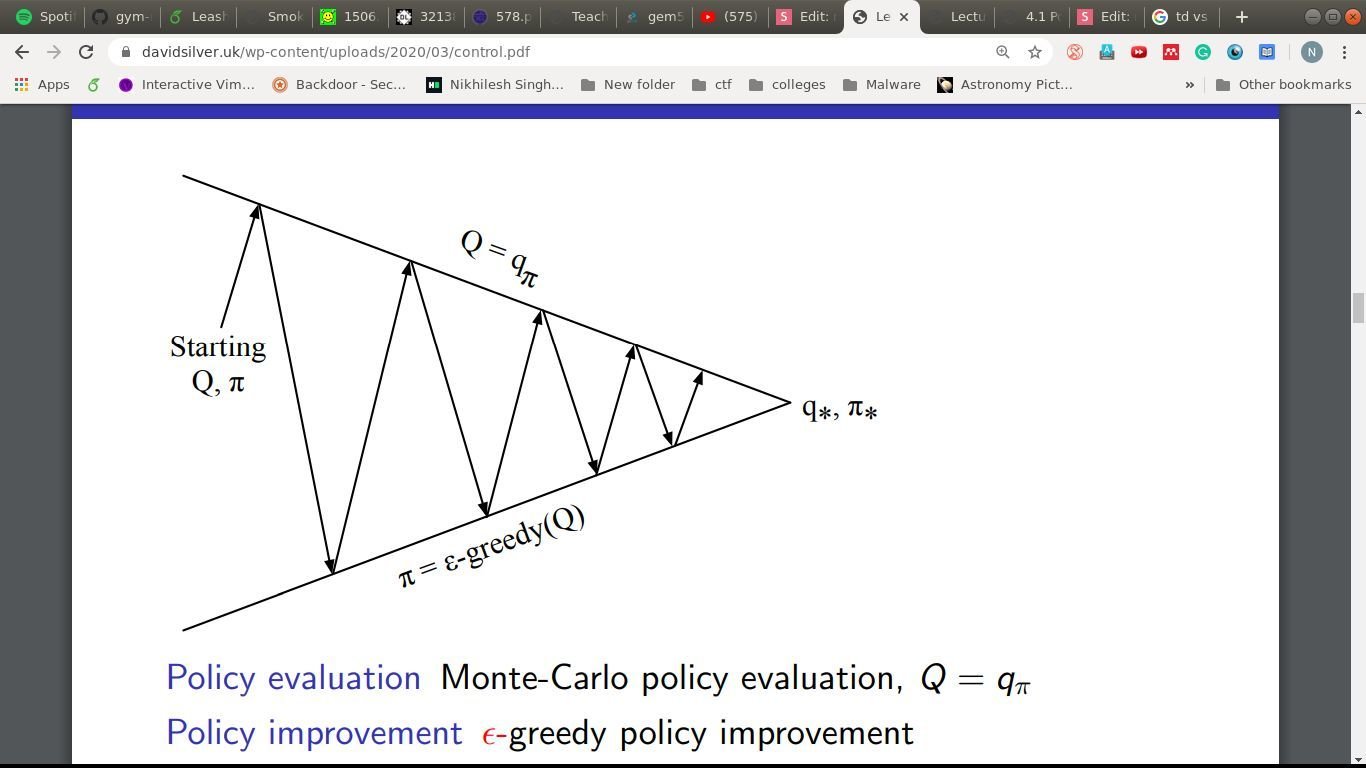
Policy Evaluation: MC evaluation
Policy Improvement: -Greedy
\epsilon
Beneath the illustration
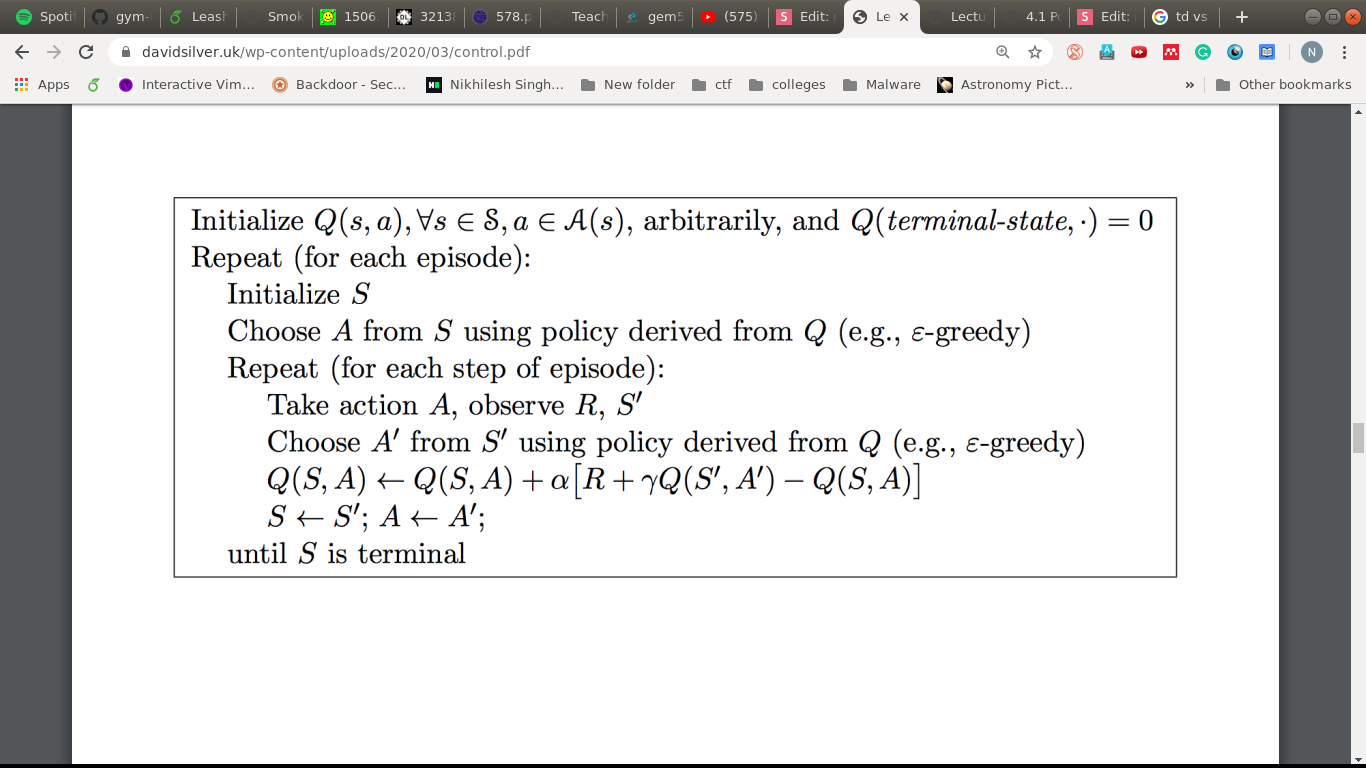
TD version
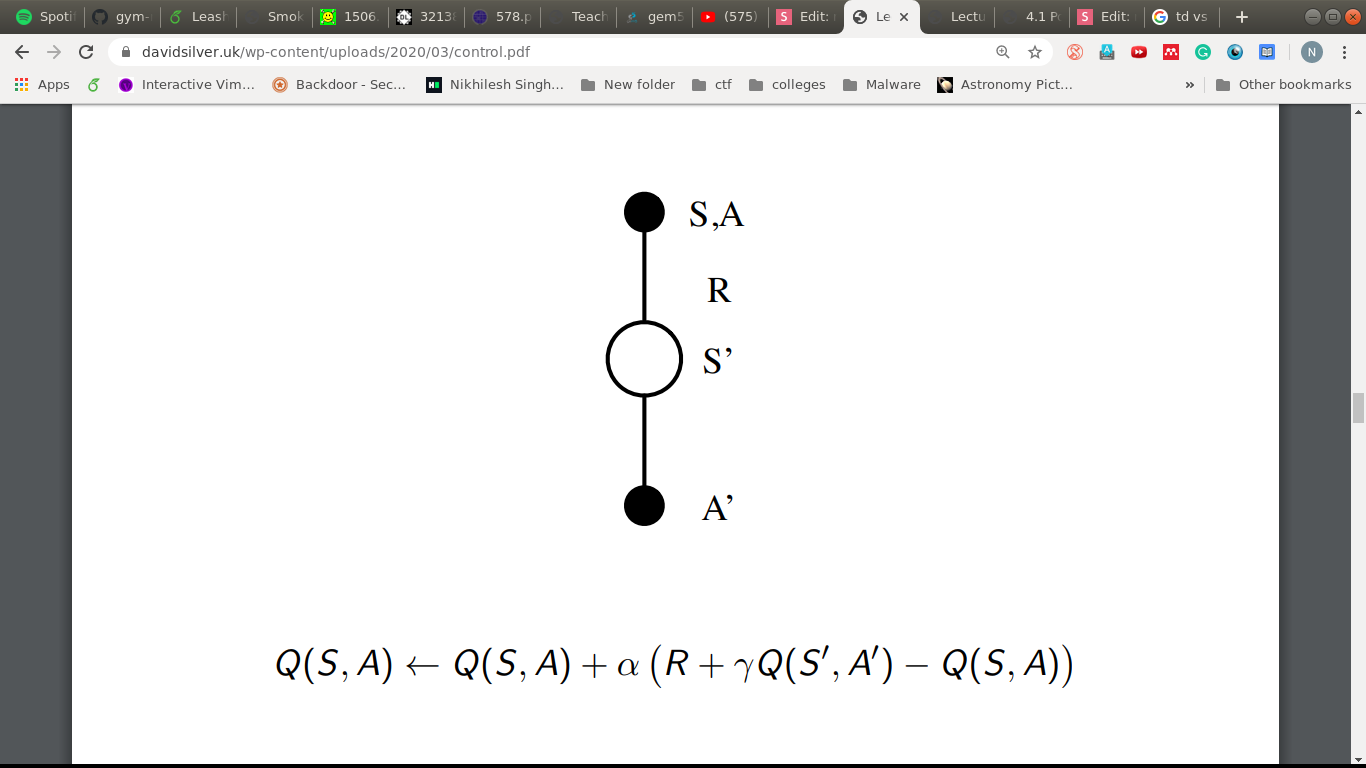
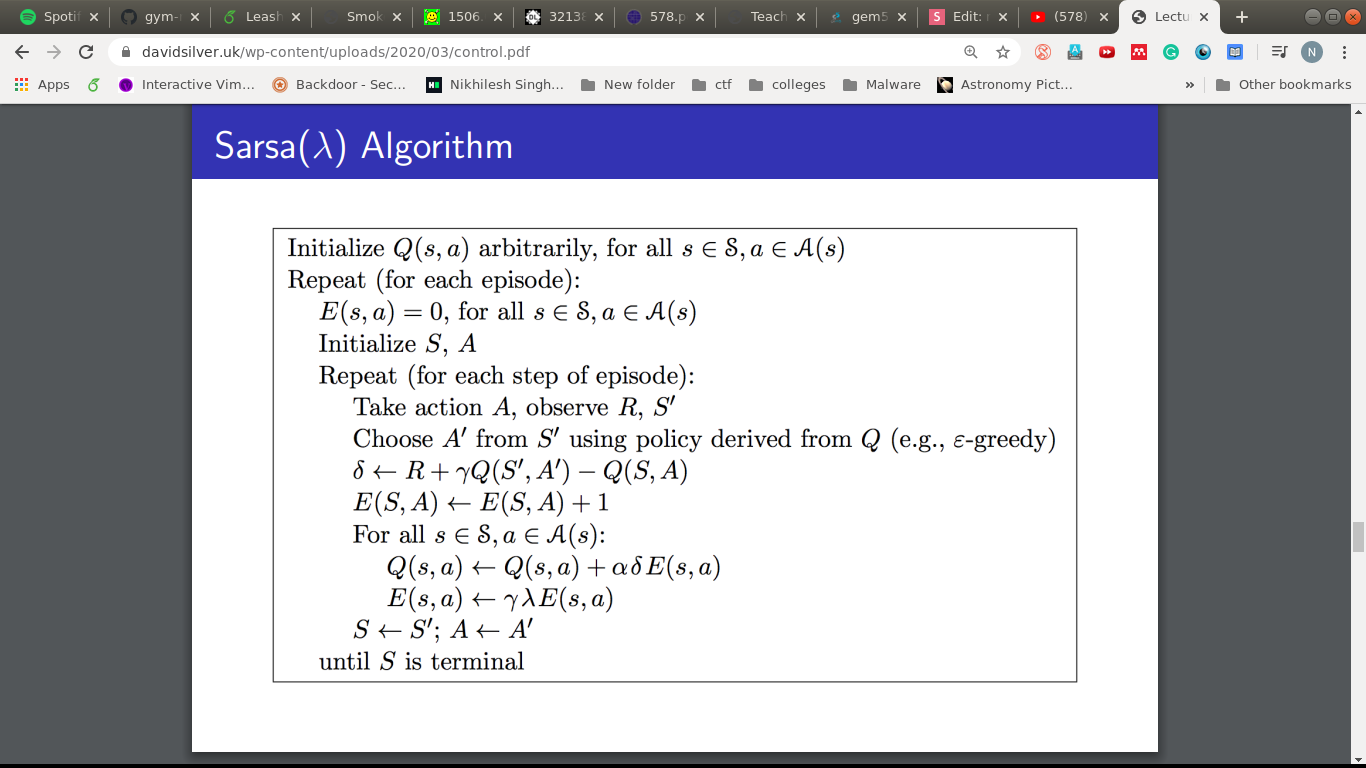
SARSA
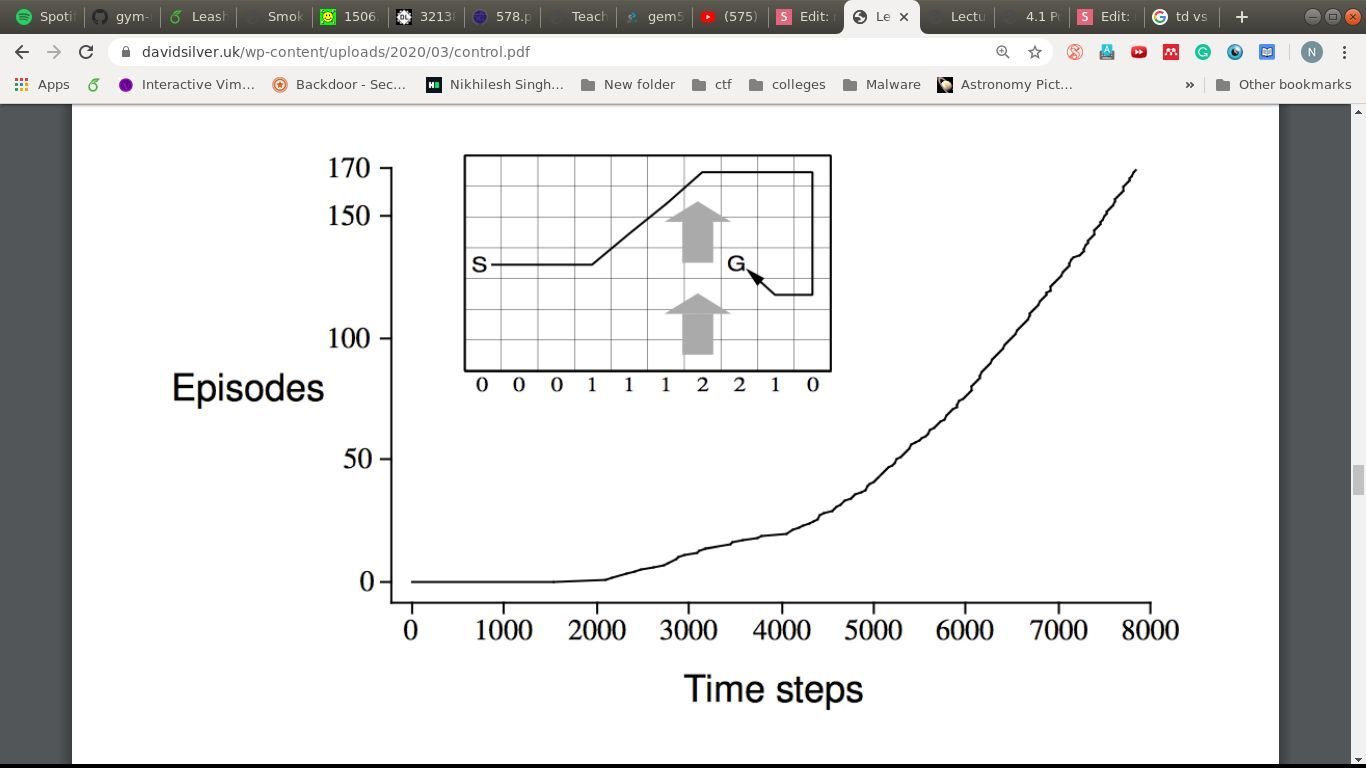
A windy example!
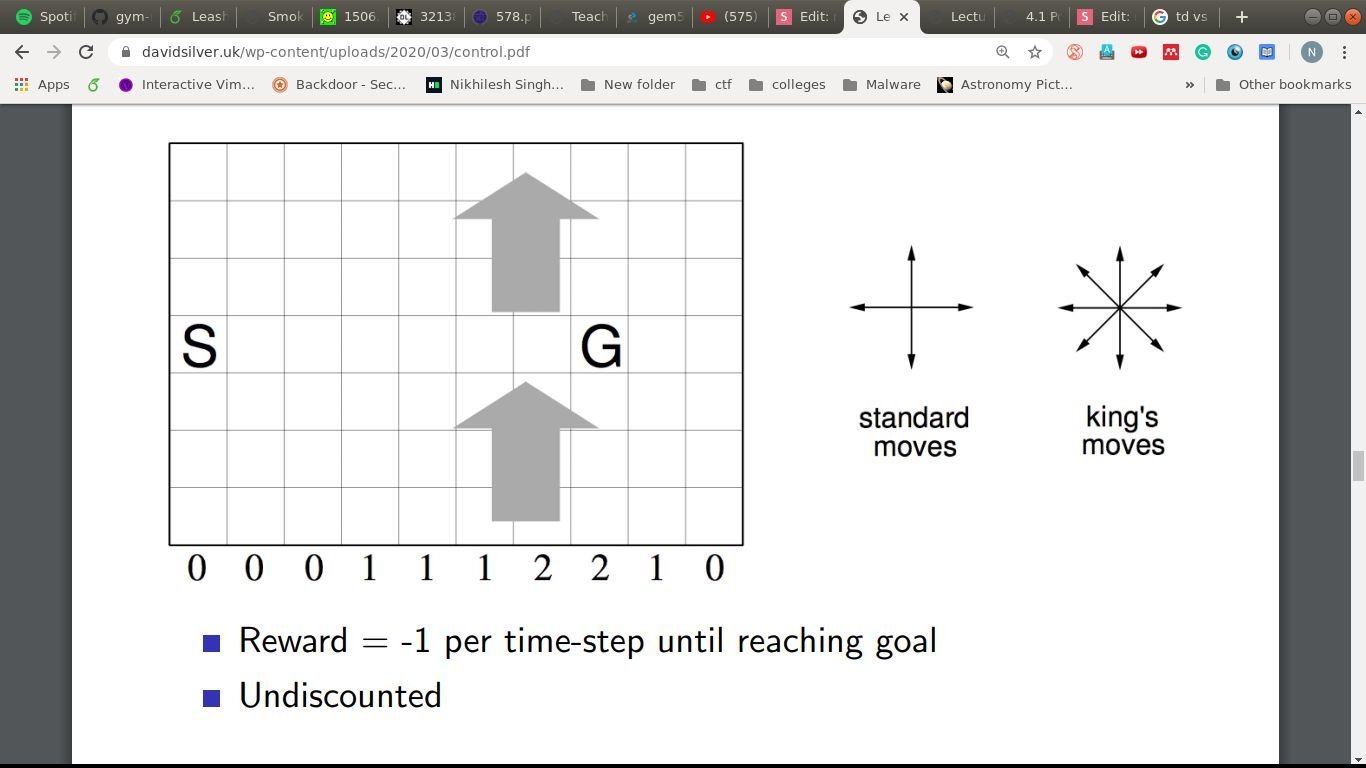
Goal: Reach G in the least time-steps
State: Location in the grid
Actions: U, D, L, R, Diag.
Rewards: -1 per timestep
A windy example!
Remember that thing?
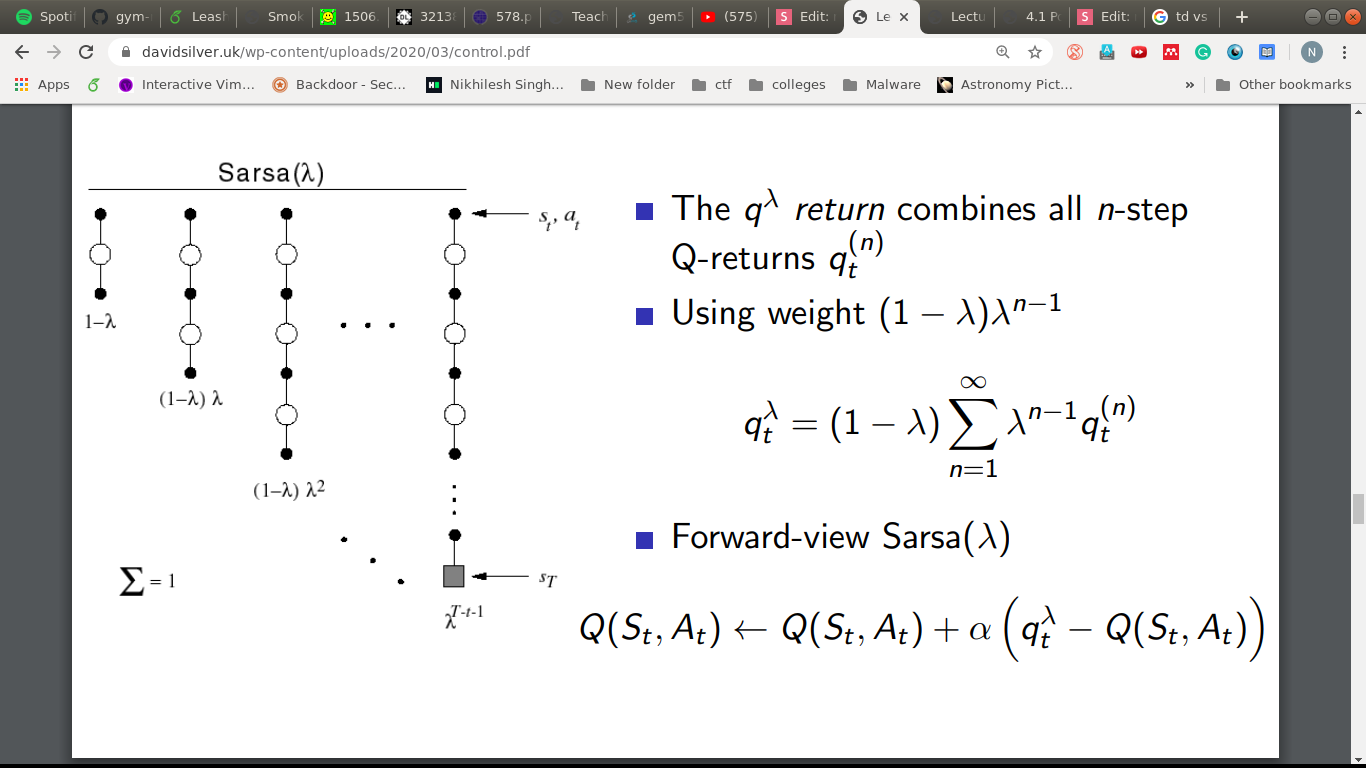
\lambda
The impact of
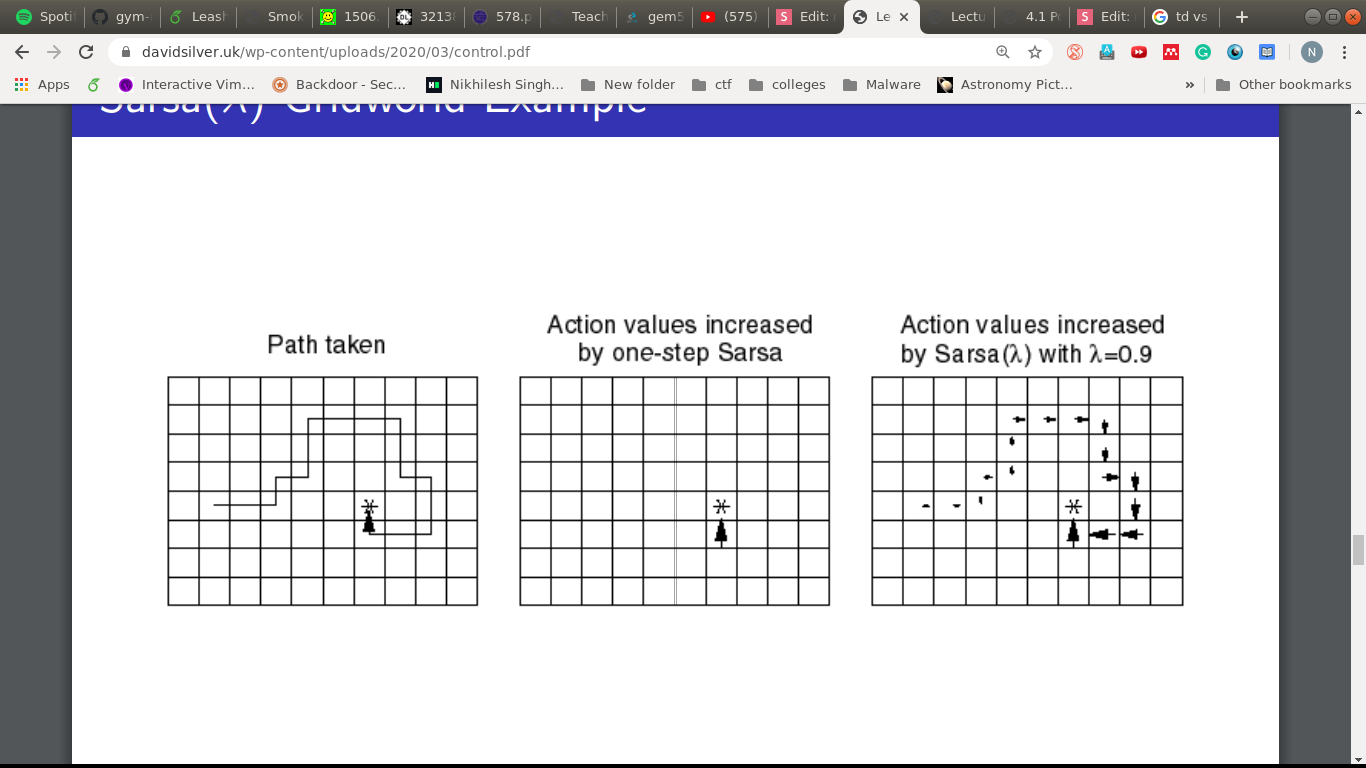
\lambda
Underneath SARSA( )
\lambda
"The wise learn from the mistake of others."
- Otto Van Bismarck
Off-policy
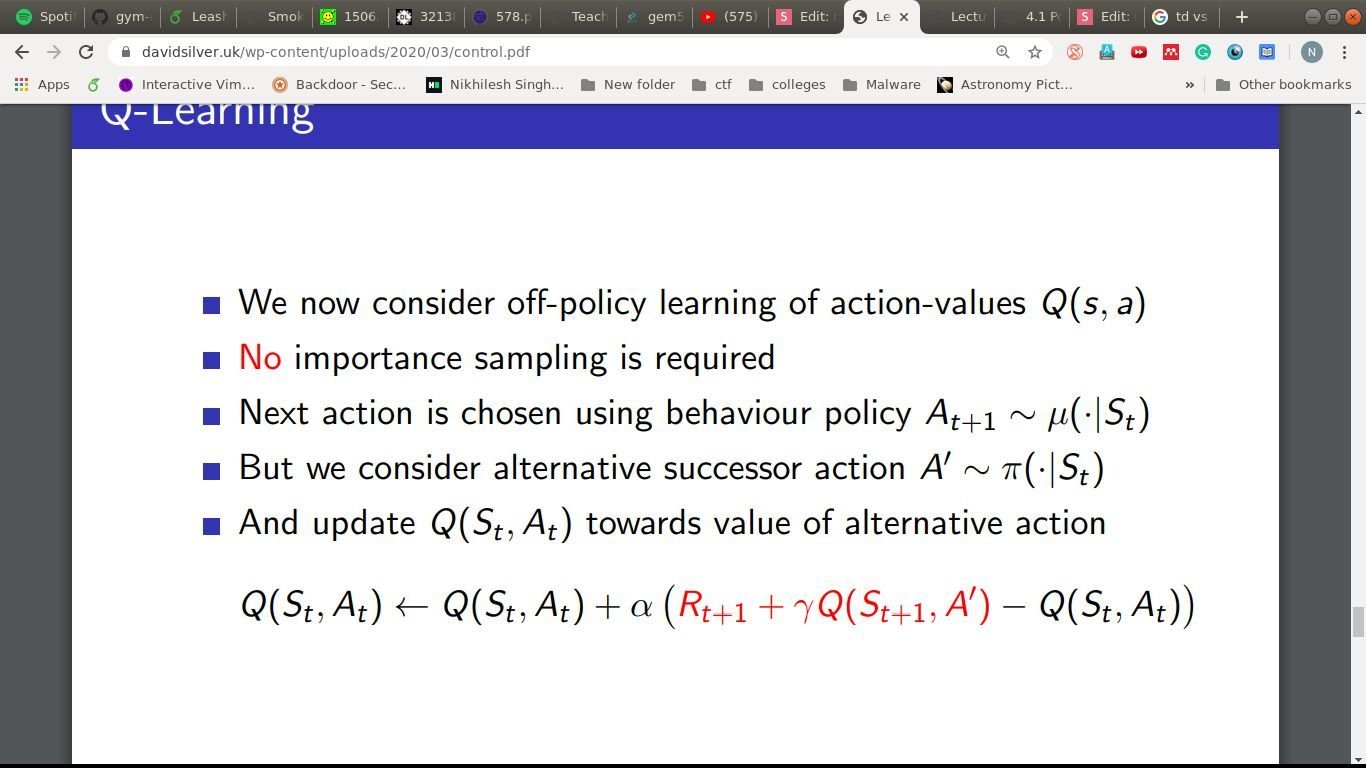
Q-learning
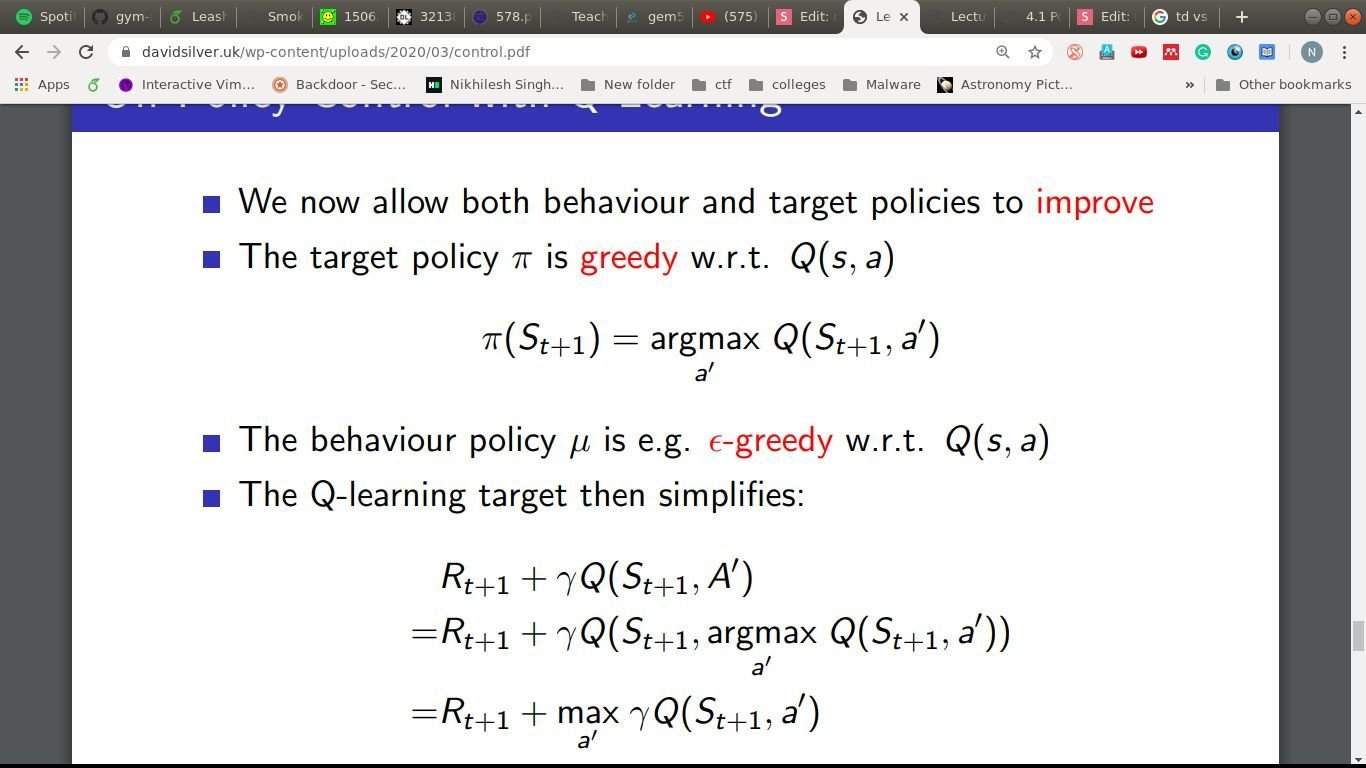
Q-learning
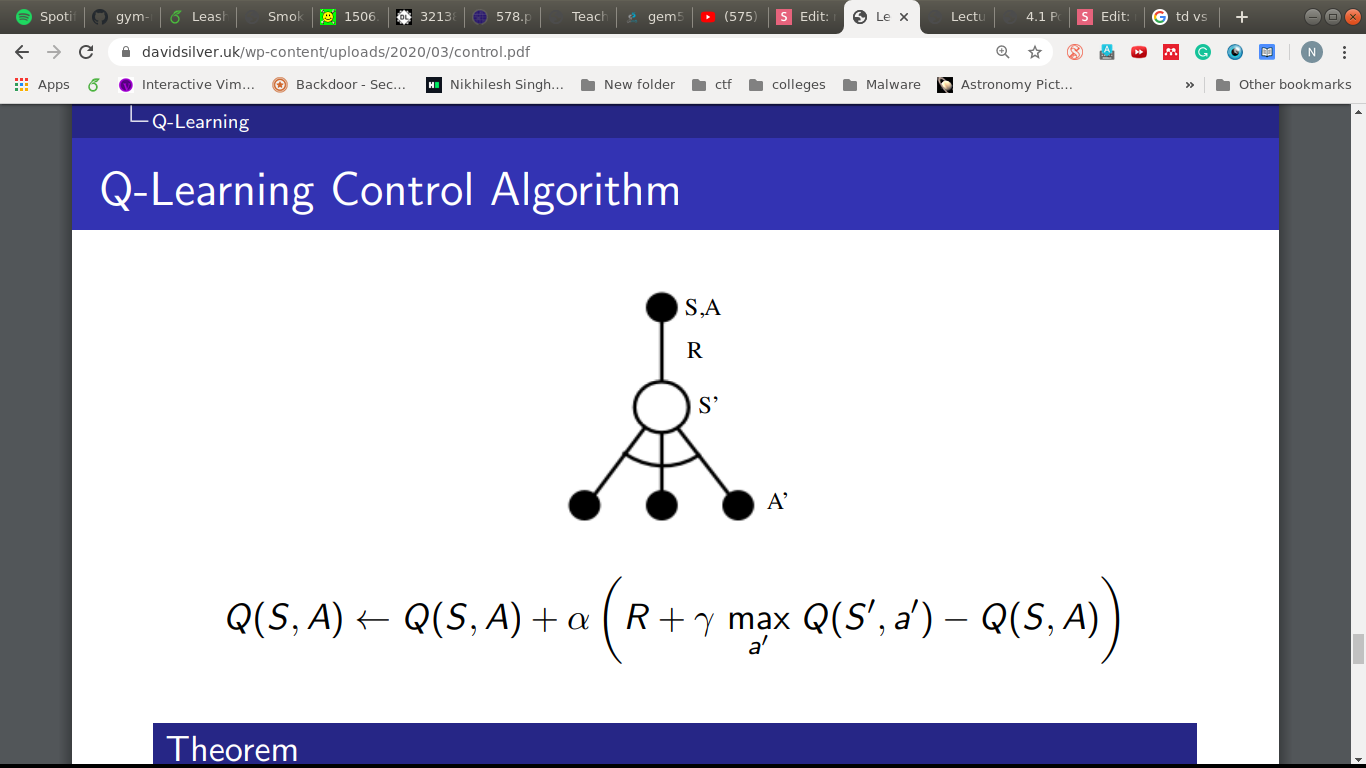
Q. All these have tables, what if we have lots and lots of states?
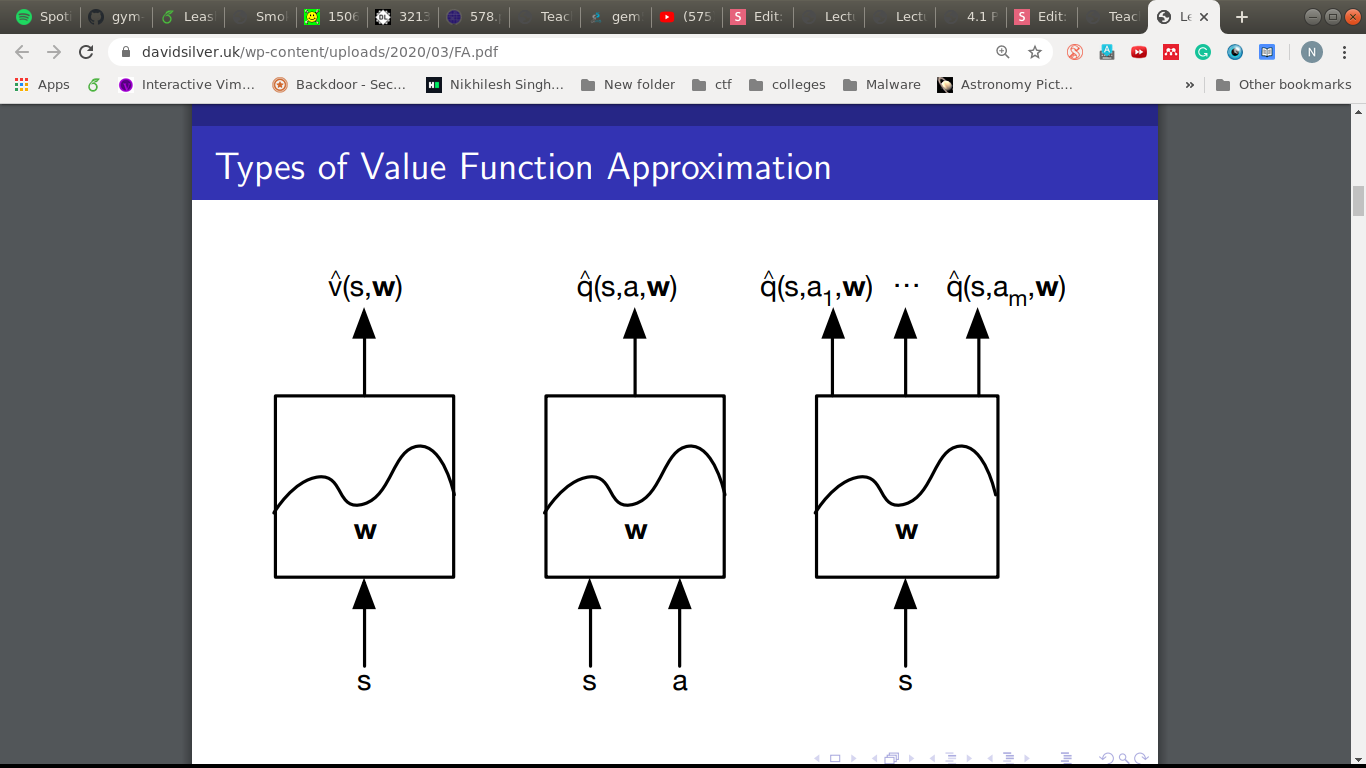
What do we need?
- Q(s,a) for all s and a
- Problems:
- We need to visit each state enough.
- And the tables can be huge.
Q. What do we do when we don't know a function correctly?
A. Approximate.

Key Idea
- We already have the sampled episodes.
- Use them as labeled data.
- Feed it to the approximator (IID).
- Not proven for convergence but works quite well in practice.
An example
Mapping to our ideas
- Goal: Break into a malware detection system.
- Environment: The system.
Mapping to our ideas
-
State: A 2530-dimensional feature vector
- PE header metadata
- Section metadata: section name, size and characteristics
- Import and Export Table metadata
- Counts of human-readable strings (e.g. file paths, URLs, and registry key names)
- Byte histogram
Mapping to our ideas
-
Actions: Should not break the code
- adding a function to the import address table that is never used
- manipulating existing section names
- creating new (unused) sections
- appending bytes to extra space at the end of sections
- removing signer information
- packing or unpacking the file
- manipulating debug info
Mapping to our ideas
-
Rewards: Should drive towards the goal
- 0 - malware sample was detected.
- R - evaded.
Mapping to our ideas
-
Algorithm:
- A form of Q-Learning
Next steps
- Check out sentdex tutorials on youtube.
- Explore gym framework.
- In fact Endgame had released a gym framework for PE.
