Введение в информационный поиск
Лекция 3
Ранжирование в векторной модели документа
Обзор
- Векторная модель документа (TF-IDF)
- Ранжирование в векторной модели документа
- Варианты TF-IDF
Векторная модель документа
Взвешивание терминов
- Хотим не только сопоставлять (matching) термины из запроса с документами*, но ранжировать документы!
- запрос q, документ d => числовая оценка релевантности d для q (ranking score) => ранг d в поисковой выдаче для q
- Не все термины одинаково полезны при поиске
- напр., стоп-слова, слова с высокой документной частотой
- Если в документе часто встречается слово из запроса => возможно, оно более значимо и должно давать больший вклад
*см. булевский поиск
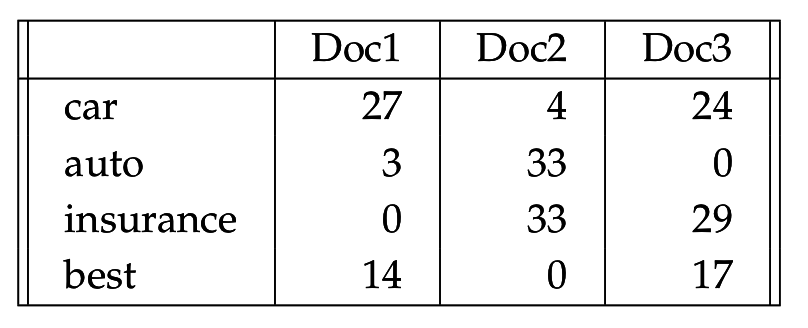
Взвешивание терминов по частоте
- tf(t,d) - частота термина t в документе
- tf - показатель важности термина для данного документа
- набор tf(t,d) для всех t - профиль документа d => модель документа "мешок слов" (bag of words)
- игнорируется порядок появления слов
Взвешивание терминов по документной частоте
- df(t) - документная частота, число документов, в которых встретился термин t
- Вспомним закон Ципфа*: , где cf - частота i-го термина в коллекции, i - ранг t по cf(t)
- В некотором приближении cf(t) ~ df(t), т.е.
- =>
- =>
- Пусть , N - количество документов в коллекции
- Получаем формулу для idf - обратной документной частоты ("ранг термина с i-й df")
cf_i = c*i^{-1}
cfi=c∗i−1
df_i = \hat{c} * i^{-1}
dfi=c^∗i−1
\log df_i = \log \hat{c} - \log i
logdfi=logc^−logi
\log i = \log \hat{c} - \log df_i
logi=logc^−logdfi
\hat{c} = N
c^=N
idf_t = \log \frac{N}{df_t}
idft=logdftN
*неформальный вывод, см. вероятностную интерпретацию в Robertson (2004)
Взвешивание терминов по документной частоте
idf_t = \log \frac{N}{df_t}
idft=logdftN
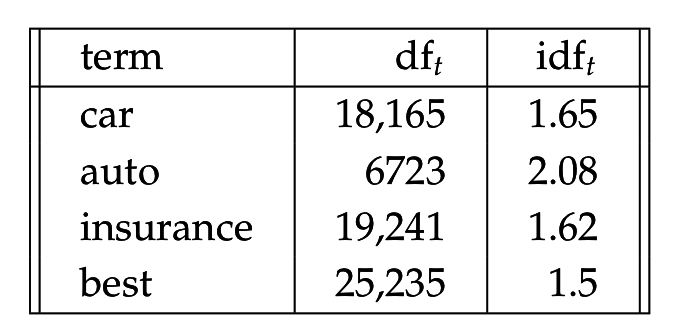
idf оценивает спефичность термина
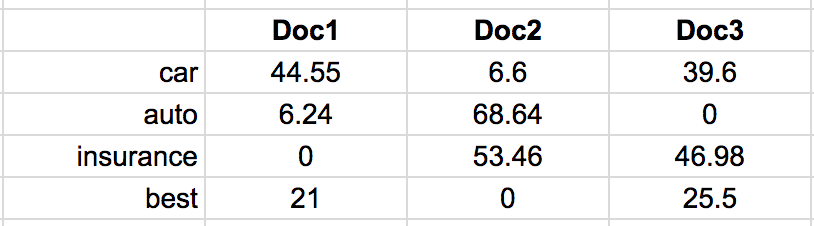
Взвешивание по tf-idf
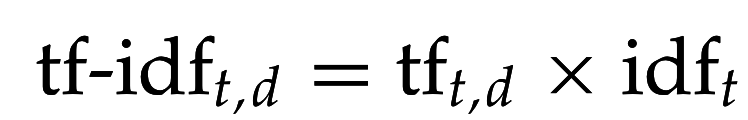
- Значение tf-idf велико, для термина t, который часто встречается в документе d и в небольшом количестве других документов
- Значение tf-idf мало, если t встречается редко в d или в слишком большом количестве документов
- Профиль документа d - вектор значений tf-idf (t, d) для всех t из словаря
Векторная модель документа
- Документы - векторы терминов, взвешенные по TF-IDF
- Близость между 2 документами = косинусная мера для их векторов:
- Косинусная мера компенсирует эффект разных длин документов (по сравнению с Евклидовым расстоянием)
- нормализация по длинам векторов => единичные векторы
- мера близости = косинус угла между единичными векторами
sim(d_1, d_2) = \frac{\vec{V}(d_1) \cdot \vec{V}(d_2)}{|\vec{V}(d_1) ||\vec{V}(d_2) |}
sim(d1,d2)=∣V⃗(d1)∣∣V⃗(d2)∣V⃗(d1)⋅V⃗(d2)
\vec{x} \cdot \vec{y} = \sum_{i=1}^M x_i y_i
x⃗⋅y⃗=∑i=1Mxiyi
|\vec{x}|=\sqrt{\sum_{i=1}^M x_i^2}
∣x⃗∣=√∑i=1Mxi2
\vec{v}=\frac{\vec{V}}{|\vec{V}|}
v⃗=∣V⃗∣V⃗
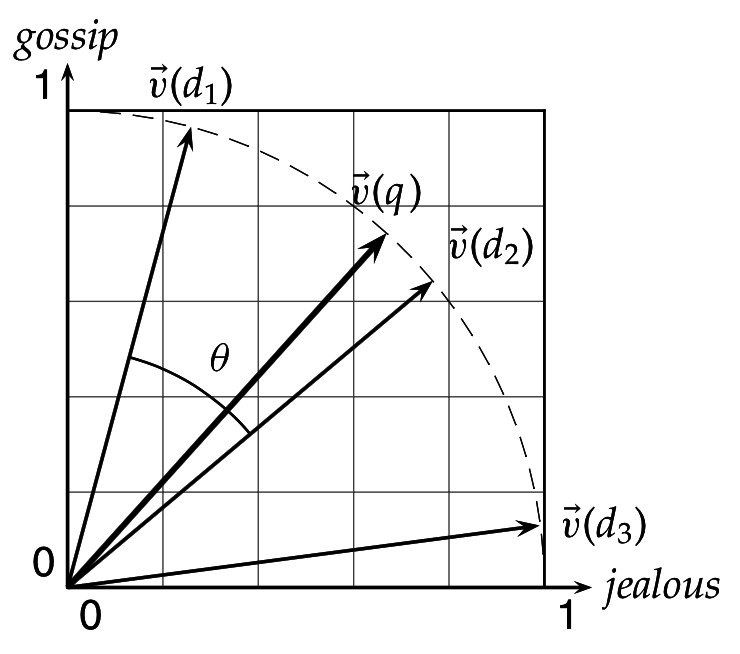
Ранжирование в векторной модели документа
Ранжирование в векторной модели документа
- Поисковый запрос q = вектор в том же пространстве векторов терминов, взвешенных по TF-IDF
- Релевантность документа запросу = косинусная мера между их векторами:
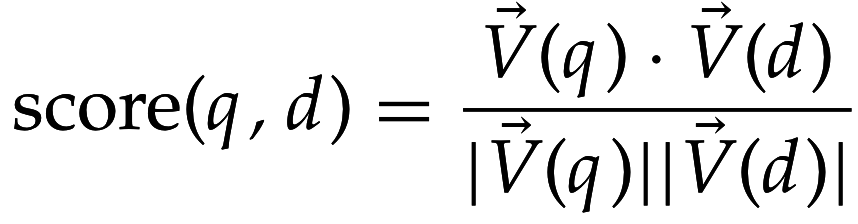
- Ранжирование по убыванию косинусной меры
- Как организовать эффективный подсчет для top-K результатов?
Базовый алгоритм

Вычислительная сложность 10 шага по N? Какую структуру данных использовать?
Двоичная куча
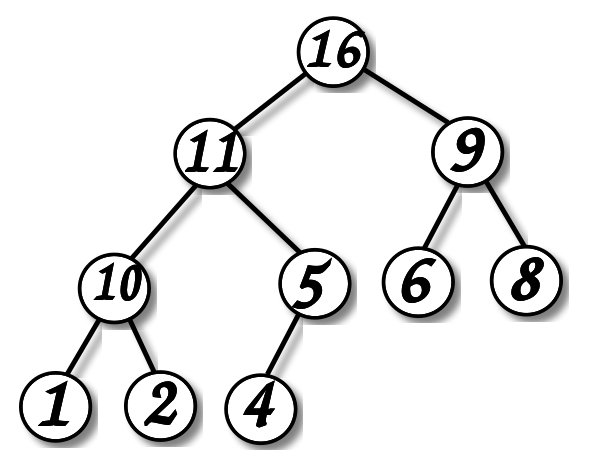
- Построение:
- Найти максимум:
- Удалить максимум:
\Theta(1)
Θ(1)
\Theta(\log N)
Θ(logN)
O(N)
O(N)
Базовый алгоритм
- Для шага 10 используется "куча" (heap): строится за 2N сравнений, поиск элементов -
O(\log N)
O(logN)
Более быстрый алгоритм

- Заменим на
- Вычисляем:
- Куча строится за 2J сравнений и поиск за log J, где J - число документов с ненулевыми scores
\vec{v}(q)
v⃗(q)
\vec{V}(q) \in \{0,1\}^M
V⃗(q)∈{0,1}M
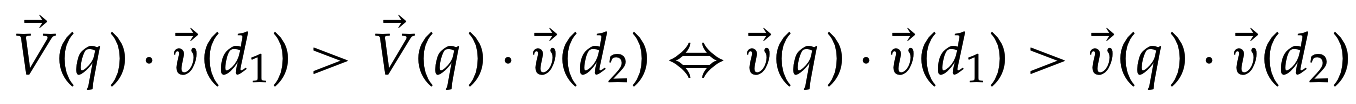
Эвристики для ускорения подсчета
- Уменьшение индекса
- Списки документов-лидеров
- Статические качественные характеристики документов
- Упорядочивание списков словопозиций
- Кластеризация документов
Уменьшение индекса
- Во время подсчета игнорировать термины с низким idf (< некоторого порога)
- Считать значения только для тех документов, которые содержат все термины или большинство терминов из запроса
- вероятное снижение полноты
Списки лидеров
- Champion lists, fancy lists or top docs
- На стадии индексирования:
- Для каждого термина из словаря, предопределить r документов с наивысшими значениями tf
- Во время обработки запроса:
- Объединить champion lists для всех терминов из запроса
- Вычислять значения только для этого множества документов
Качественные характеристики документов
- Показатели g(d) качества документов безотносительно поискового запроса
- Показатель достоверности источника документа
- Меры центральности для графов (PageRank, HITS)
- Свежесть документа
- Идеи ускорения:
- Рассматривать пересечение списков словопозиций в порядке этих значений
- В качестве champion lists брать r документов с наивысшими g(d) + tf-idf(t,d)
- Рассматривать champion lists и только потом оставшиеся документы, если результатов < K
Упорядочивание списков словопозиций
- Упорядочиваем по убыванию tf(t,d) => порядок документов не будет единым во всех списках
- Идеи ускорения:
- Останавливаемся после некоторого числа документов
- Останавливаемся после падения tf(t,d) < порога
- Начинаем считать с терминов из запроса с наивысшими idf (term-at-a-time scoring)
- В общем случае упорядочивание может происходить как по статическим, так и по динамическим факторам документов
Кластеризация
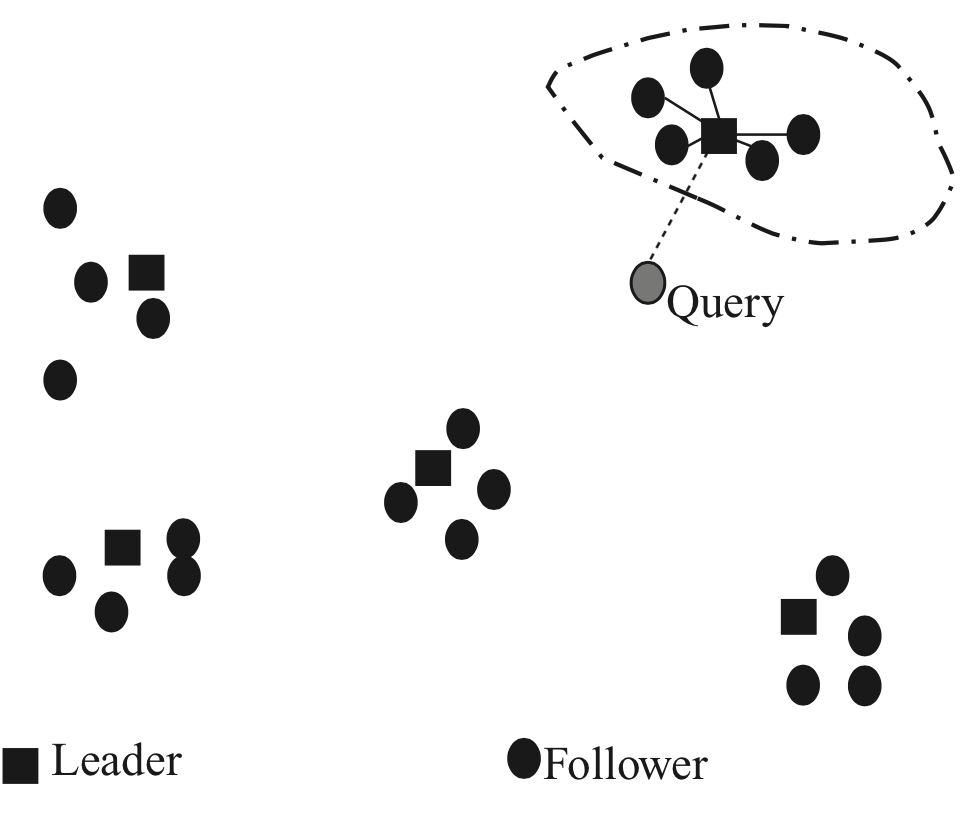
- "Лидеры" - случайно выбранные документы
- Кластеризуем по схожести документов ("фолловеров") по отношению к "лидеру"
- По данному запросу находим ближайшего "лидера"
- Считаем значения ranking scores только для его "фолловеров" (документов из его кластера)
- Вариант - рассматривать для запроса X лидеров и для фолловеров Y лидеров
Варианты TF-IDF
Масштабирование tf
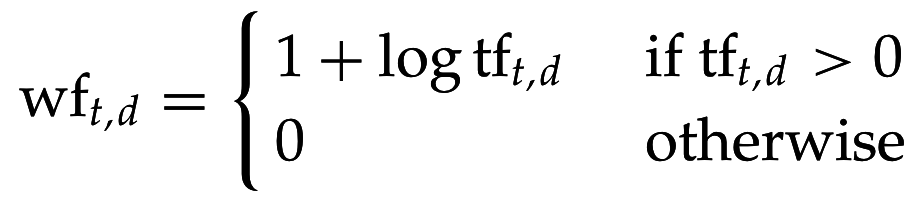
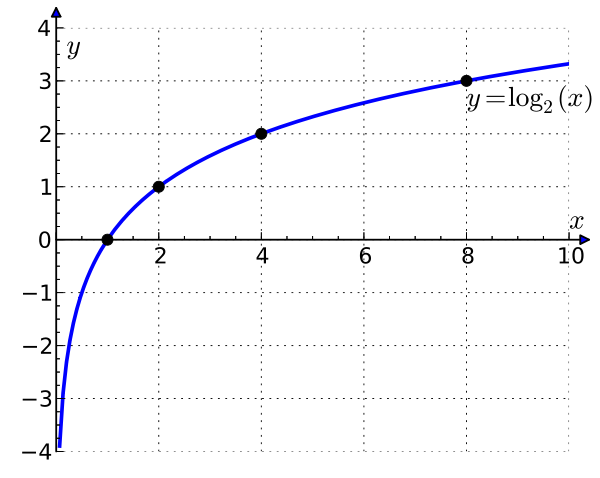
- Логарифм делаем влияние tf на ranking score менее сильным (сублинейным)
- Остается проблема с длинными документами
Text
Нормализация по max tf
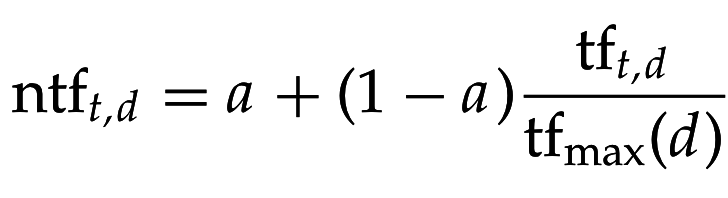
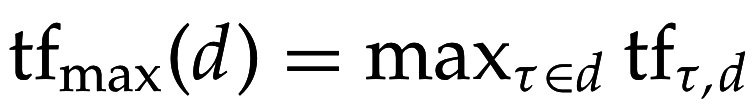
a \in [0,1], (a=0.4)
a∈[0,1],(a=0.4)
- Аналогично позволяет сделать более гладким рост tf
- Метод не очень стабилен к терминам-выбросам
Опорная нормировка по длине документа
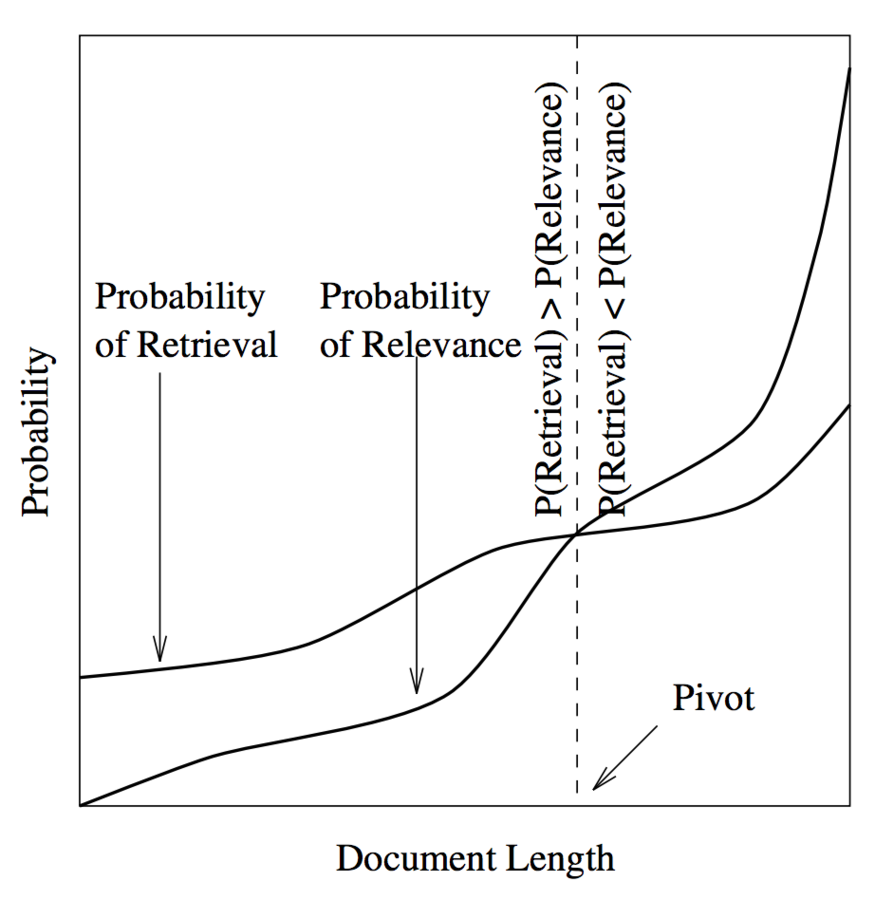
- График вероятности релевантности как функции от длины документа
- График ранжирования тех же документов по косинусной мере
=> косинусное ранжирование искажает оценку релевантности за счет длинных документов
- p - опорная длина
- идея - "повернуть" график вокруг p
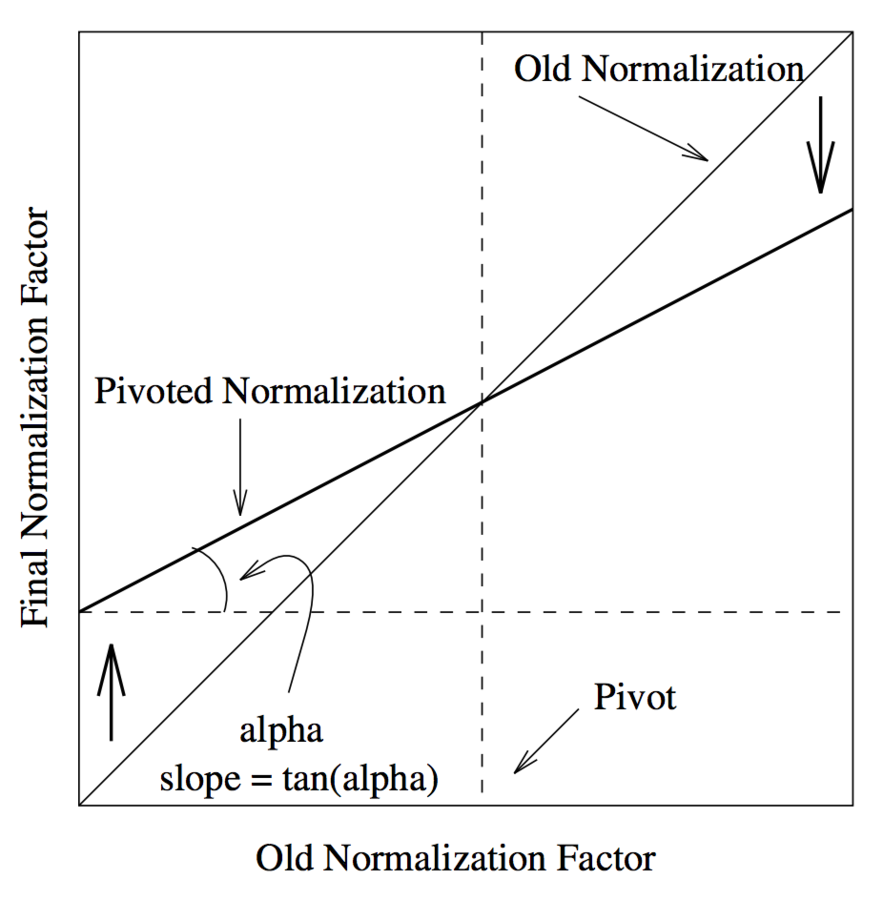
Опорная нормировка по длине документа
- Нормализация принимает вид:
- Угловой коэффициент (slope) s < 1
- piv - точка пересечения с графиком косинусной нормализации
- На практике приближают как:
- количество уникальных терминов в d
u_d
ud
(1-s)pivot + s|\vec{V}(d)|
(1−s)pivot+s∣V⃗(d)∣
(1-s)pivot + su_d
(1−s)pivot+sud
Необходимо оптизимизировать 2 параметра: pivot и s
Опорная нормировка по длине документа
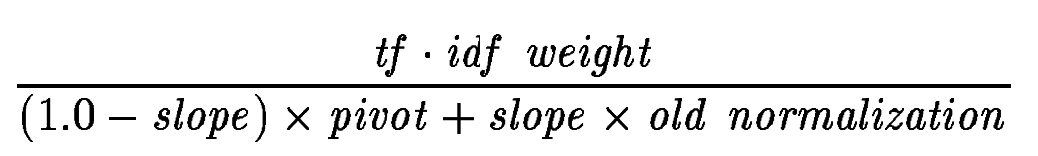
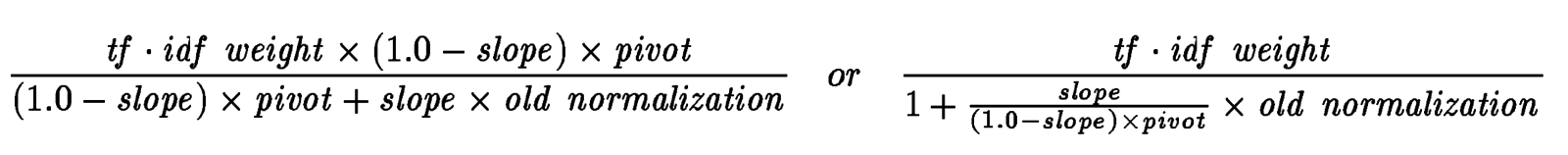
=> можно просто зафиксировать pivot как среднее значение (по всей коллекции) при старой нормализации и свести к оптимизации 1 параметра (slope)
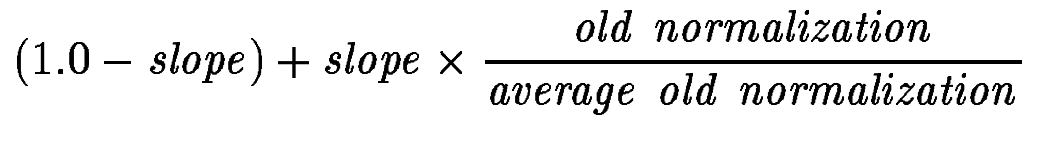
изменения в pivot можно компенсировать изменением в slope
Модель с опорной нормировкой*
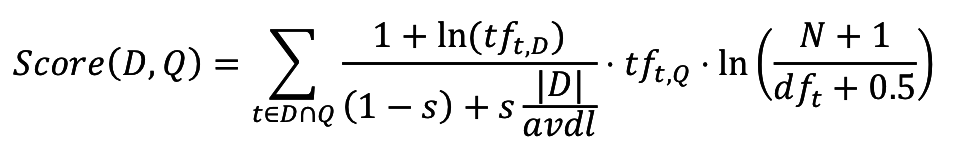
*вариант модели, см. практическое задание 5
Варианты TF-IDF

- Могут применяться разные взвешивания и нормировки для векторов
- SMART нотация (ddd.qqq): например, lnc.ltc
- Moffat A., Zobel J. Exploring the similarity space (1998)
\vec{V}(d), \vec{V}(q)
V⃗(d),V⃗(q)