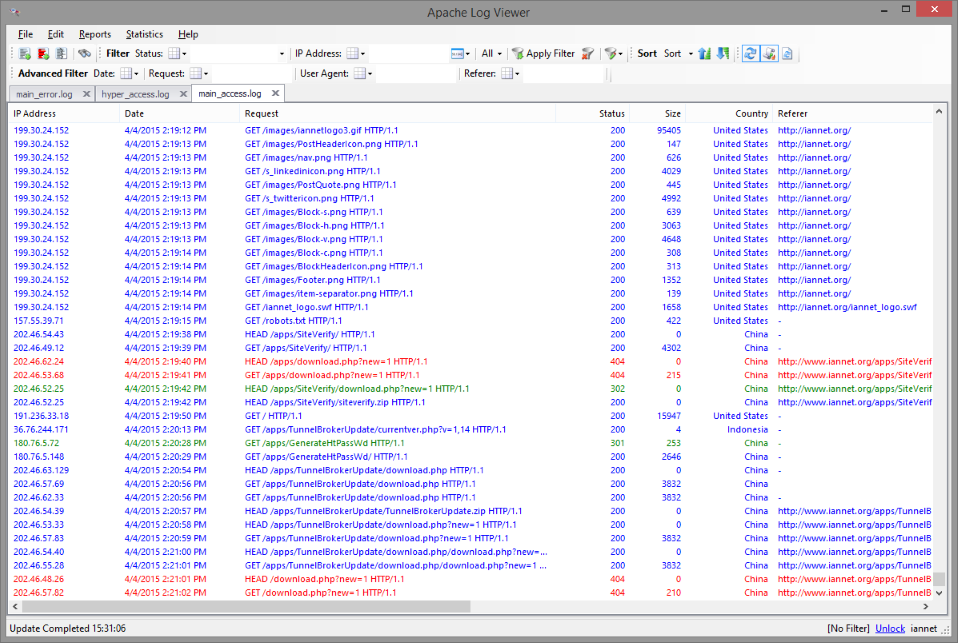
Web Server
From HTTP 완벽 가이드
With Google
Contents
- What is Web server
- How is web server working?
What is Web server?
What is Web server?
HTTP 및 그와 관련된 TCP처리를 구현한 것
(Hardware, software 둘 다를 칭함)
하는일!
- HTTP 프로토콜을 구현
- 웹 리소스 관리
- 웹 서버 관리 기능 제공
- TCP 관리 권한 가짐 (With OS)
- 하드웨어 관리 (support by OS)
- TCP/IP 네트워크 지원 (support by OS)
- 파일 시스템 관리 (support by OS)
- 프로세스 관리 (support by OS)
What is Web server?
웹 서버의 종류!
- 다목적 소프트웨어 웹 서버
- apache
- nginx
- tomcat
- iis(microsoft web server)
- 임베디드 웹 서버
- 공유기
- wifi 프린터 등등
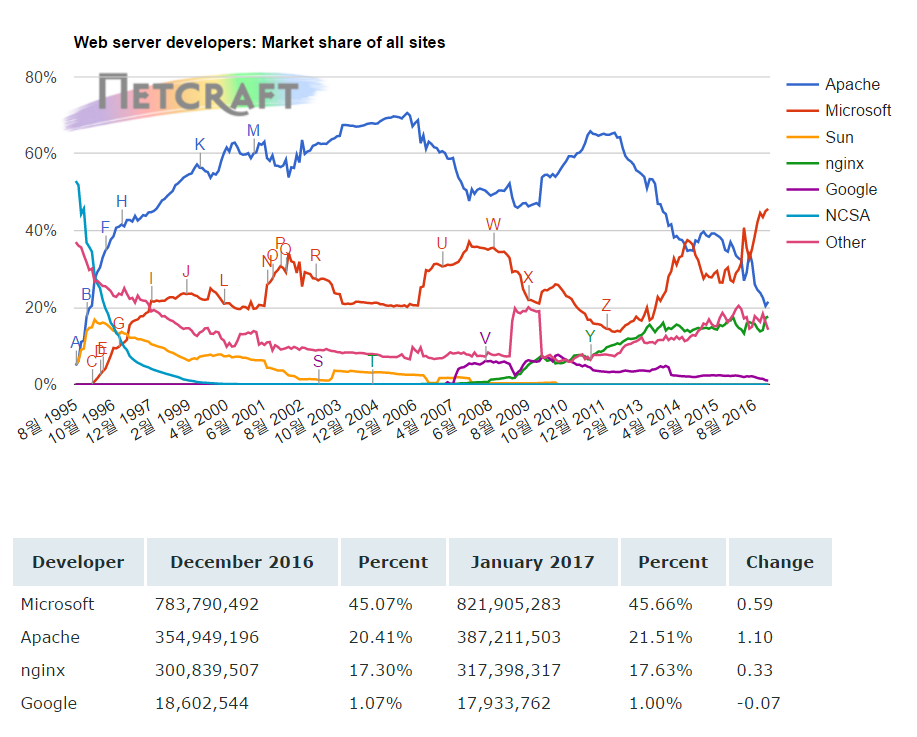
How is web server working?
Process
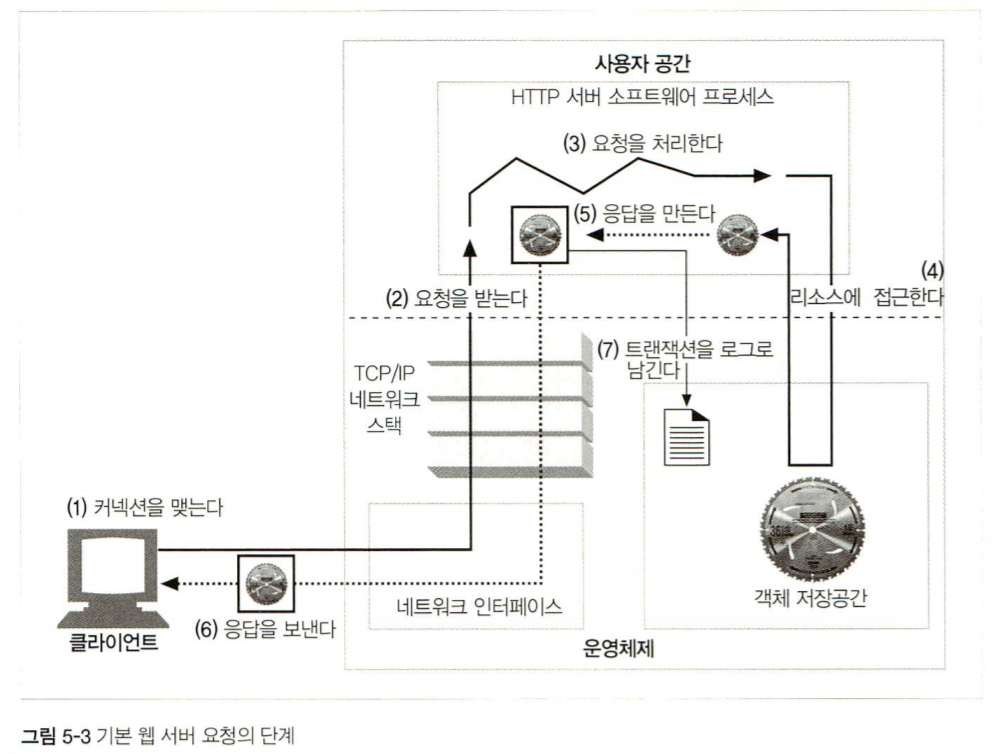
from HTTP 완벽가이드
자세히 알아봅시다
1. 커넥션을 맺는다.
클라이언트의 접속을 받아들이거나,
원치 않는 클라이언트라면 닫는다.
from HTTP 완벽가이드
클라이언트: 클라이언트가 커넥션을 요청
↓
서버: 클라이언트를 확인 ? 연결 : 연결안함
↓
클라이언트: 서버와 연결
서버: 커넥션 리스트 등록 후 주는 데이터 확인
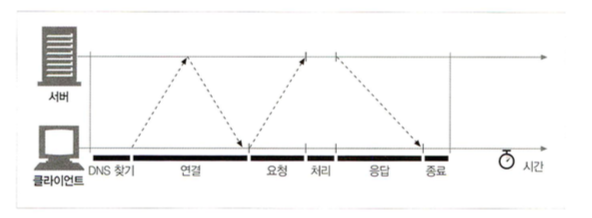
클라이언트 확인은 어떻게 하는걸까?(연결안함의 이유)
- IP주소 파악 후 결정.(IP ban)
- 악의적 transfer data 전송(해킹, 악성코드)
- Reverse DNS이용하여 hostname 확인
- 트렌젝션을 한번에 많이 사용하기 때문에 과부하 발생
- ident
- 서버가 HTTP 컨넥션을 초기화한 클라이언트에게 사용자 정보를 요청하는 프로토콜
- 클라이언트가 안사용 / HTTP통신방해 / 방화벽 / 보안 등의 문제로 잘 사용하지 않음

2. 요청 메시지 수신
HTTP 요청 메시지를
네트워크로 부터 읽어 들인다.
from HTTP 완벽가이드
클라이언트의 data를 읽어 파싱후 요청메시지를 구상한다.
↓
구상된 메시지를 웹서버가 만든 자료구조에 넣어 저장한다.
파싱 후 저장!
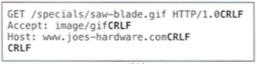
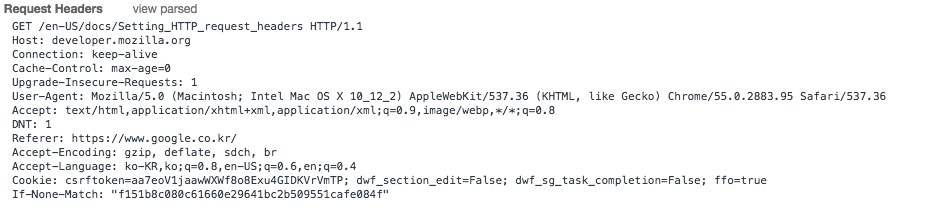
GET /specials/saw-blade.gif HTTP/1.0
Accept: image/gif
Host: www.joes-hardware.com
CRLF
Data (JSON)
{
method: "1",
version: "1.0",
uri: "/specials/saw-blade.gif",
header_count: ,
headers: {
Host:"www.joes-hardware.com",
Accept:"image/gif"
},
body: "-"
}
HTTP message
커넥션 입출력 처리 구조
- 단일 스레드 웹 서버
- 멀티프로세스와 멀티스레드 웹 서버
- 다중 I/O 웹 서버
- 다중 멀티스레드 웹 서버
단일 스레드
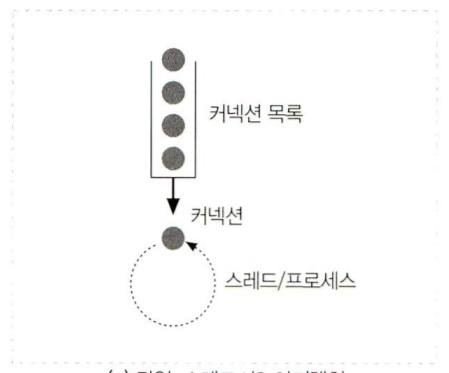
한번에 하나의 요청(커넥션)을 처리
트렌잭션(2-6과정)을 마치면 다음 과정을 처리함.
처리되는 도중 기다리는 커넥션은 처리중인 커넥션을 기다려야함.
멀티 프로세스&스레드
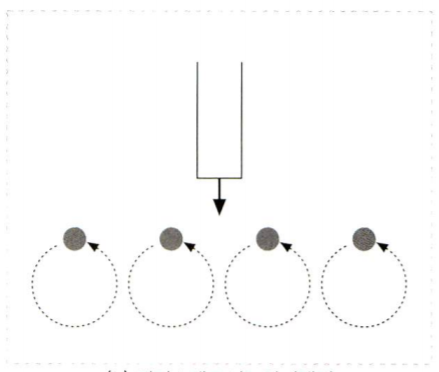
한번에 한개이상의 커넥션 처리
커넥션을 여러개의 프로세스 혹은 고요율 스레드에 넣는다.
스레드는 필요할때 생성되거나 미리 만들어 놓는다.
너무 많은 프로세스나 스레드가 생기면 과부하가 걸리니 최대겟수를 정한다.
다중 I/O

연결된 모든 커넥션을 순차적으로 돌며 감시
감시하는 커넥션의 상태변경이 있을때 변경사항을 조금씩 처리
참고: 링크
다중 멀티스레드
다중 I/O를 멀티로 처리함.
3. 요청을 처리한다
요청 메시지를 해석하고 행동을 취한다.
from HTTP 완벽가이드
요청 메시지의 메서드/리소스/헤더/본문을 얻어 처리함.
너무 뿔뿔히 흩어져 있어요... ㅠㅠ (3장, 4장, 7장, 12장 등등)
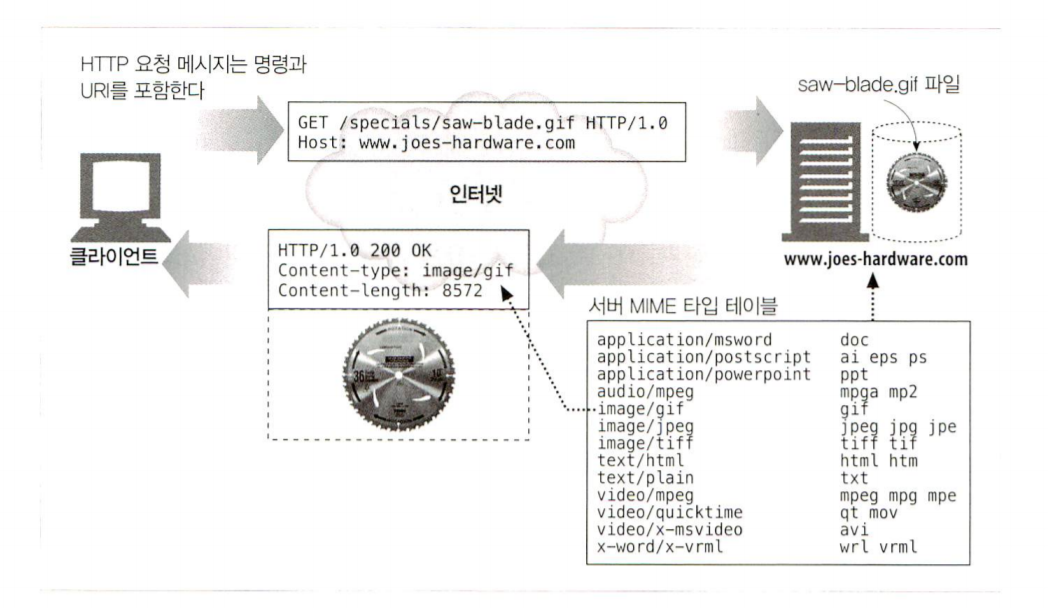
4. 리소스에 접근한다.
메시지에서 지정한 리소스에 접근한다.
from HTTP 완벽가이드
URL(URI)를 통해서 저장되거나 만들어질 리소스를 전달함.
리소스의 매핑과 접근방법
- Docroot
- 디렉터리 목록
- 동적 콘텐츠 리소스 매핑

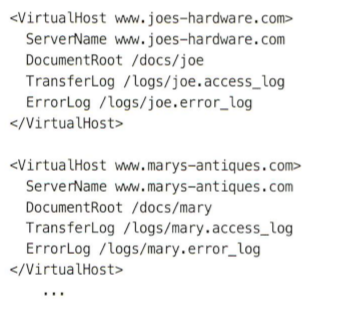
docroot == 웹 서버가 root로 지정한 디렉토리
웹 서버가 받은 URL정보로 리소스를 찾는 방법 ==> docroot + URL = Resource 경로
docroot를 2개 이상 지정하여 하나의 웹서버에서 서로 다른 사이트를 운영할 수 있다.
웹 서버의 사용자의 홈 디렉토리를 docroot로 지정하여 웹 서버를 운영할 수 있다.



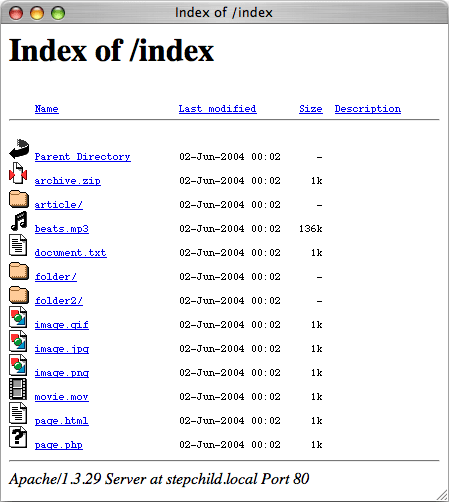
디렉터리(/.../.../ 처럼 파일이름이 아닌 '/'로 끝나는 경로)를 URL로 주는 경우 웹서버의 반응
- 에러 반환 (404 not found)
- 디렉터리 대신 특별한 '색인(index) 파일'을 반환한다.
(웹 서버 config에서 설정가능) - 디렉터리를 탐색해서 그 내용을 담은
HTML 페이지를 반환한다. ( on/off 가능 )
미리 만들어진 리소스가 아닌 요청시 만드는 리소스(동적 리소스)도 반환 가능!
- cgi (common gateway interface) program
- ASP (Active Server Page)
- Java Servlet

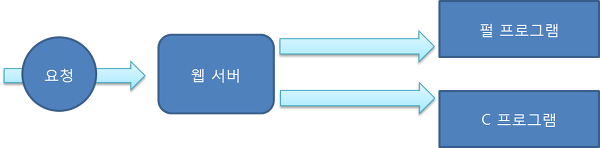
CGI Program
웹 브라우저가 웹서버에 실행을 요청하면, 웹 서버는 펄이나 C로 작성된 CGI프로그램을 직접 실행, 생성한 결과를 웹 브라우저에 전송
웹 어플리케이션 서버 (ASP, JSP, PHP 등등)
웹 어플리케이션 서버를 통해서 간접적으로 웹 어플리케이션 프로그램 실행
자료 출처 : 링크
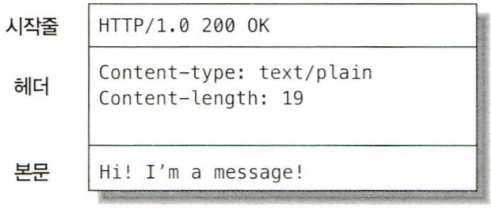
5. 응답을 만든다.
올바른 헤더를 포함한
HTTP 응답 메시지를 생성한다.
from HTTP 완벽가이드
응답 메시지 생성: 주로 다음 내용를 포함한다
- 응답 본문의 MIME 타입을 서술하는 Content-Type Header
- 응답 본문의 길이를 서술하는 Content-Length Header
- 실제 응답 본문의 내용

리다이렉션 코드 (3XX code)을 메시지에 담아서 전송.
- 리소스 없음
- 영원히 (301 Moved Permanently)
- 임시로 (303 See Other / 307 Temporary Redirect)
- URL 증강 (303 See Other / 307 Temporary Redirect)
- 부하 균형 (303 See Other / 307 Temporary Redirect)
- 친밀한 다른 서버가 있을 때 (303 See Other / 307 Temporary Redirect)
- 디렉터리 이름 정규화( 빼먹은 '/'를 붙여 다시 로드 )
6. 응답을 보낸다.
응답을 클라이언트에게 돌려준다.
from HTTP 완벽가이드
처리(생성)된 메시지를 클라이언트에게 전달한다.
↓
메시지를 전달 받은 클라이언트는 커넥션을 닫는다.
만약 keep-alive 신호가 있었다면 커넥션을 닫지 않고 대기한다.
7. 트랜잭션을 로그로
남긴다.
로그파일에 트랜잭션 완료에 대한
기록을 남긴다.
from HTTP 완벽가이드
TCP컨넥션이 끝나고 연결되었던 기록을 파일에 기록한다.
"로그 기록에 대한 자세한 정보는 21장에 설명되어있습니다"라고 책은 설명하지만....
궁금해서 (일부) 찾아봤습니다.

apache 2.2
log format