@ IIT Madras
The AI4Bharat Initiative

Mission statement of the Initiative
Bring parity in AI technology for Indian languages with English
Make fundamental contributions to state-of-the-art across language technologies - NLP, Speech, Sign language, OCR
Open source all datasets and AI models with permissible licenses
Build a coalition of partners to collect datasets and deploy models


Associate Professor, IIT Madras
PhD, IIT Bombay
Areas - NLP, Deep Learning
Mitesh M. Khapra
Pratyush Kumar
Our Team
Anoop Kunchukuttan

Assistant Professor, IIT Madras
PhD, ETH Zürich
Areas - Deep Learning, Systems
Researcher, Microsoft
PhD, IIT Bombay
Areas - NLP
+ many hard-working students and volunteers
What have we done so far (last 18 months)
IndicNLPSuite
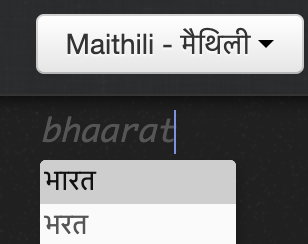
Input Tools
INCLUDE
Samanantar
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ

E
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
Corpora, benchmarks, models for 11 Indic languages
Romanized keyboards for under-represented languages
Datasets and efficient models for isolated Indian Sign Language
Parallel corpus, translation models between English & 11 Indic languages

9 Billion Tokens, 10000 downloads
3 languages, 75000 words
263 signs, 4000 videos
33M parallel sentences, 12 languages
IndicTrans
AI model for translating between English and 12 Indic languages
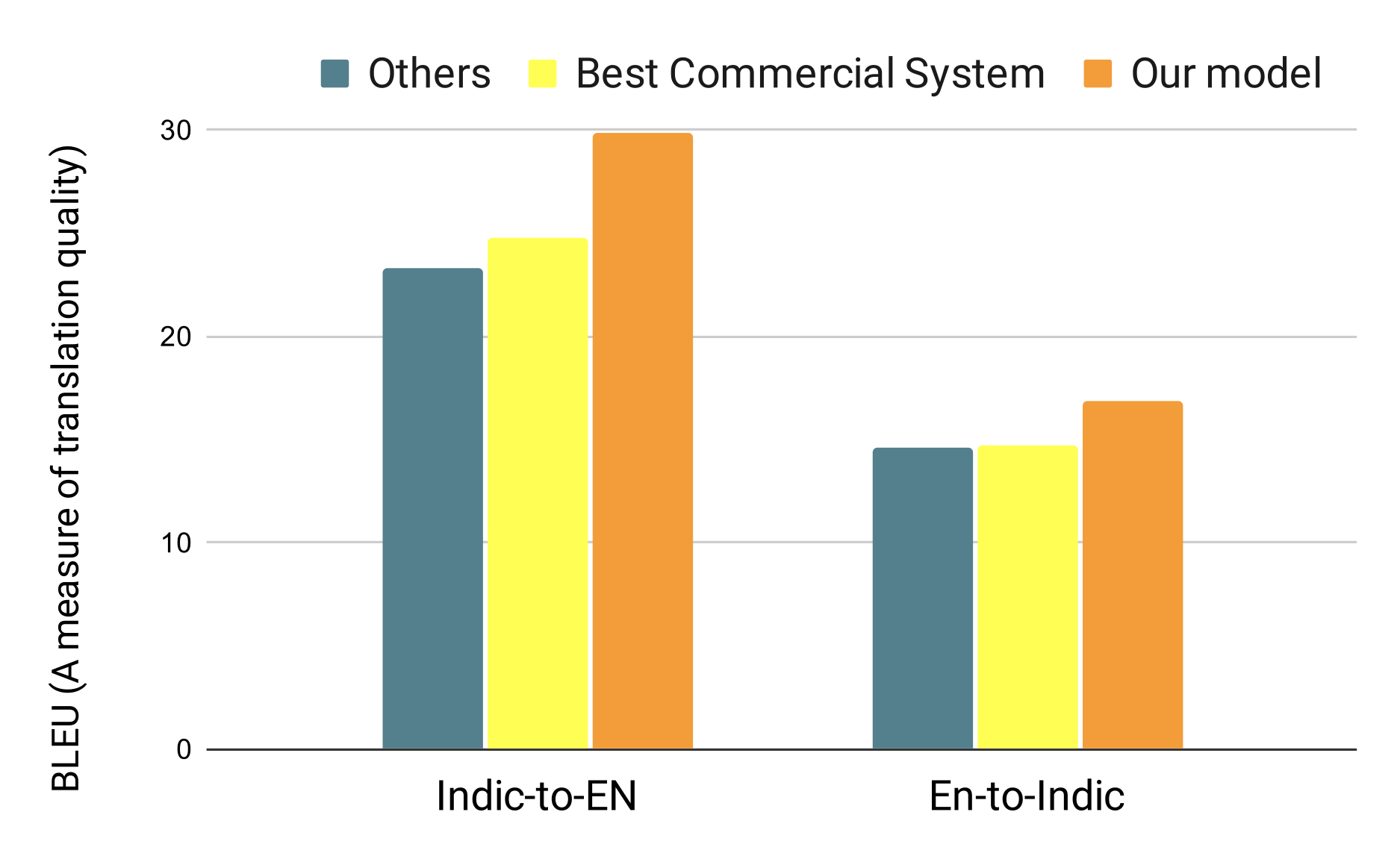
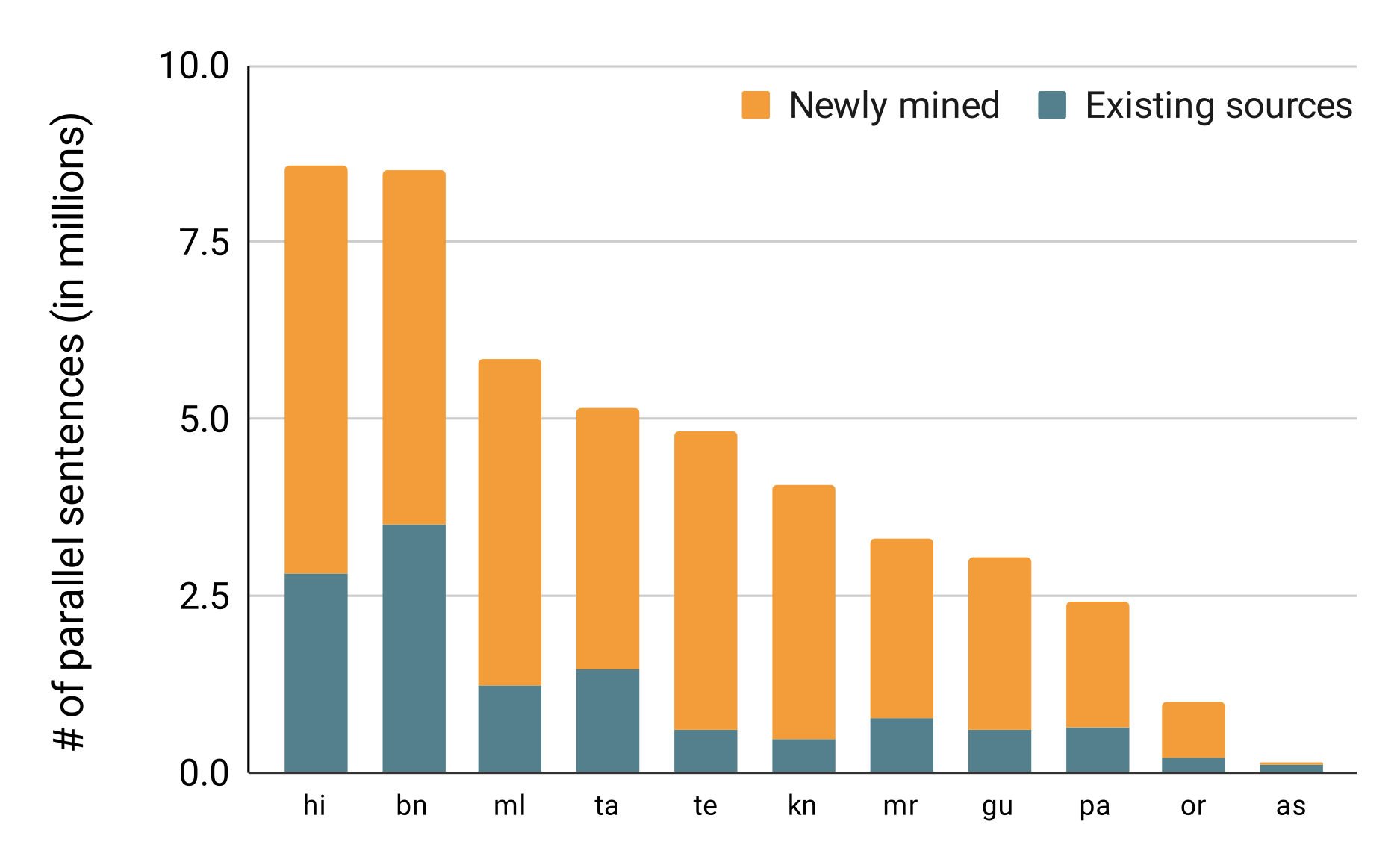
33M parallel sentences mined from the web (3X improvement)
Impact: The translation models (which are shown to be more accurate than commercial APIs) are being used to assist human translators in translating supreme court judgements with a significant increase in efficiency
Host on CDAC machines as apart of NLTM
Follow the proven modern AI recipe


+
+
Huge amounts of data
Deep neural networks
Lot of compute power

+
Tools


+
Human Annotators
What is the recipe
Methodology
Follow the proven modern AI recipe
+
+
Huge amounts of data
Deep neural networks
Lot of compute power
+
Tools
+


Human Annotators
Data
What are the different types of data?


Mined from the web
Crowd-sourced

Expert curated
(High volume, noisy)
(Moderate volume, may be noisy)
(Low volume, high quality)
Pre-Training
Training
Benchmarking
Data
What are the tasks involved?
Define metrics of data quality
Define rules and licenses of fair data use
Define methods for automated validation
Define rules for fair benchmarks
Define metrics for comparing models
Tools
What are the different types of tools?
Input Tools
Annotation Tools
User Experience Tools
(keyboards)
(Karya)
(Anuvaad)



What are the tasks involved?
Build/Discover smart and efficient annotation tools
Define workflows for different annotation tasks with semi-automated validation
Define metrics for measuring annotation quality & efficiency
Tools


What are the different types of annotators
Annotators
Volunteers
Crowdsourced workers
Experts
(work for language pride and social impact)
(Part-time semi-professionals)
(Professionals)



What are the tasks involved?
Work with a marketplace for annotators
Design incentives and price models for different annotation tasks
Define metrics for rating annotators
Annotators


Phase 1
Phase 3

MT
ASR


OCR


Dialog
Summarisation

QA
NLI

Paraphrase


Named Entity Recognition
Sentiment Analysis
Topic Classification
Content Filters
Phase 2
What are the tasks of interest?
...
...
Build swipe based keyboards for all 22 languages
2021
2022
2023
2020
Dataset
Benchmark
Model
Tools



green = eco-friendly = efficient
v 1.0, 46M sentences, 12 languages
v 1.0, 9B tokens, 12 languages
v 1.0, 2 languages
v 2.0, 20B tokens, 15 languages
v 1.0, 22 languages
v 1.0, 22 languages
v 2.0, 75M sentences, 15 languages
v 1.0, 22 languages
v 1.0, 2000 hours, 22 languages
v 3.0, 15 languages, green translation
v 3.0, 25B tokens, 22 languages
green language model
v 2.0, 4000 hours, 22 languages, green ASR Models
263 signs, 4000+ videos
swipe keyboards - 22 languages
sign language
crowdsourcing tool
sign language recognition in video calls
Guiding Principle
Maximizing utility of the data while minimizing cost of procurement
the Samanantar example
Putting it all together
1. Curate data from the web
Collect a large corpus of monolingual data in many languages (eg. IndicCorp)
Insert this into the data store with
ULCA compliance*
*data partner's role

2. Mine parallel sentences from corpora
Egress data with ULCA compliance
Engineer system to mine parallel sentences (eg. Samanantar)

Insert parallel sentences with
ULCA compliance
3. Evaluate quality of parallel dataset
Sample data from the parallel corpus data with ULCA compliance
Standardise a tool (eg. Karya) and metrics (eg. SemEval) for evaluating semantic similarity
Collect annotations from human effort
Insert data back into the data repository with ULCA compliance
4. Train AI models
Access training data with ULCA compliance
Train AI models (eg. IndicTrans)
Insert model card and API access to repository under ULCA compliance
5. Create benchmarks for MT
Sample data from the parallel corpus data with ULCA compliance
Standardise tool (eg. Karya) and rules (eg. no NMT tool to be used)
Collect benchmarks from human effort
Insert data back into the data repository with ULCA compliance
Discussion
Data
They have different characteristics
High volume, noisy
Moderate volume, may be noisy
Low volume, high quality
Data
They have different challenges
At-scale engineering, automated denoising
Best-in-class tool, quality-check
Community building, training, management
Data
They have different use-cases
Pre-training data, noisy training
Diverse training data, validate model output