An AI4BHARAT INITIATIVE
indicnlp.ai4bharat.org
A HUB FOR INDIC NLP RESOURCES, DATASETS AND TOOLS



Assistant Professor, IIT Madras
BTech from IIT Bombay, PhD from ETH Zurich
Worked at IBM research
DL consultant for startups
35 research papers, 18 patents
Assistant Professor, IIT Madras
PhD from IIT Bombay
Exp in teaching DL to industry and academia,
5 years exp at IBM research,
40+ research papers
Google Faculty Award, Young Faculty Recognition Award
Dr. Mitesh M. Khapra
Dr. Pratyush Kumar
Launched in Jul 2019: Working on several open-source projects of social importance in AI
Who are we?
About Us
Senior Applied Researcher, Microsoft India,
PhD from IIT Bombay
Exp. in Machine Translation, Multilingual NLP, Building tools and resources for Indian NLP
2+ years experience at Microsoft Translator group
35+ research papers
Dr. Anoop Kunchukuttan

Build open-source datasets and models for Indian languages. Today!

If we are serious about succeeding, this is the only way forward!
What do we want to do?
Mission Statement
Bring parity in AI technology for Indian languages with English
Why should we care about IndicNLP?




















বা ગુ हि ಕ മ म ने ਪੰ த తె ار
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
The social view
Touch Points: Digital
Users: Multlingual
Language technology is absolutely essential to magnify reach and impact in the social sector
The commercial view




















Multilingual chatbots
Sentiment Analysis
Content Moderation
Code mixed song search
Speech
QA
Multilingual Authoring Tools
... And the demand for these tools is increasing
*Source Google-KPMG report https://assets.kpmg/content/dam/kpmg/in/pdf/2017/04/Indian-languages-Defining-Indias-Internet.pdf

કેમ છો
कैसे हैं

Chat applications
Digital entertainment
Social media platforms
Digital
news
Digital write-ups
Digital payments
e-governance services
e-commerce services
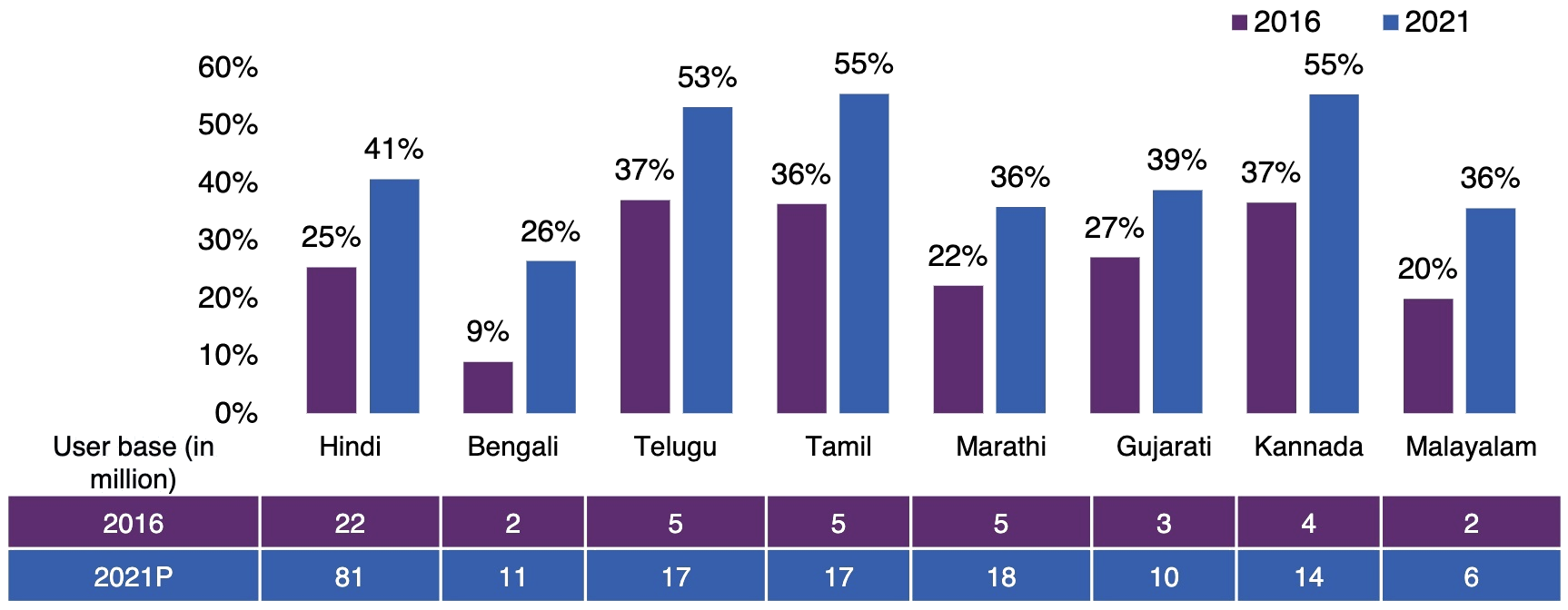
22 official languages 1.3 billion speakers
By 2025, 75% of Indian internet users will use Indian languages
Demand for speech and text technology
Rich diversity
, growth
and demand
What is the current state of IndicNLP?
(Spoiler alert: we are far far behind)
Poor in resources
, tools
and technology
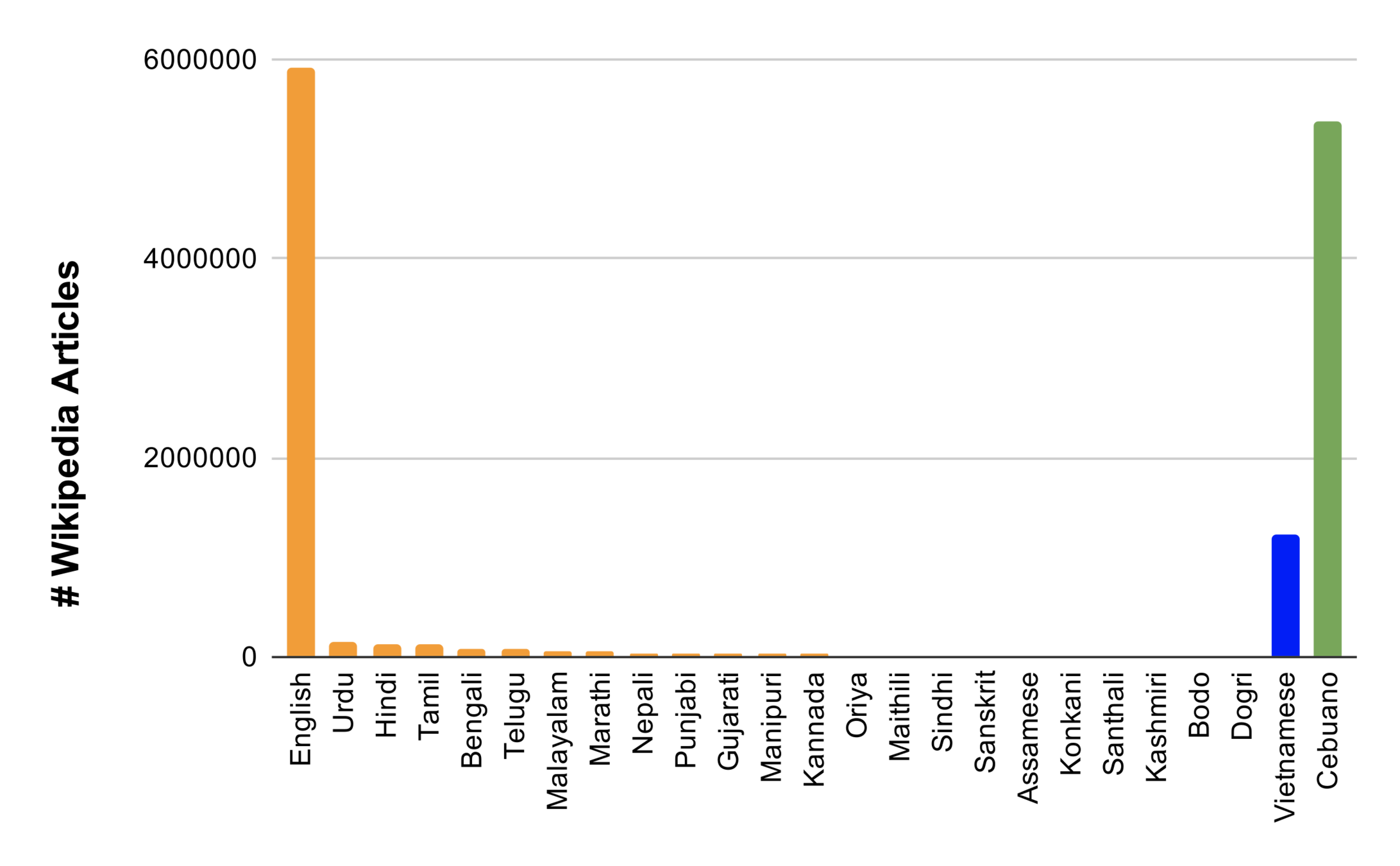
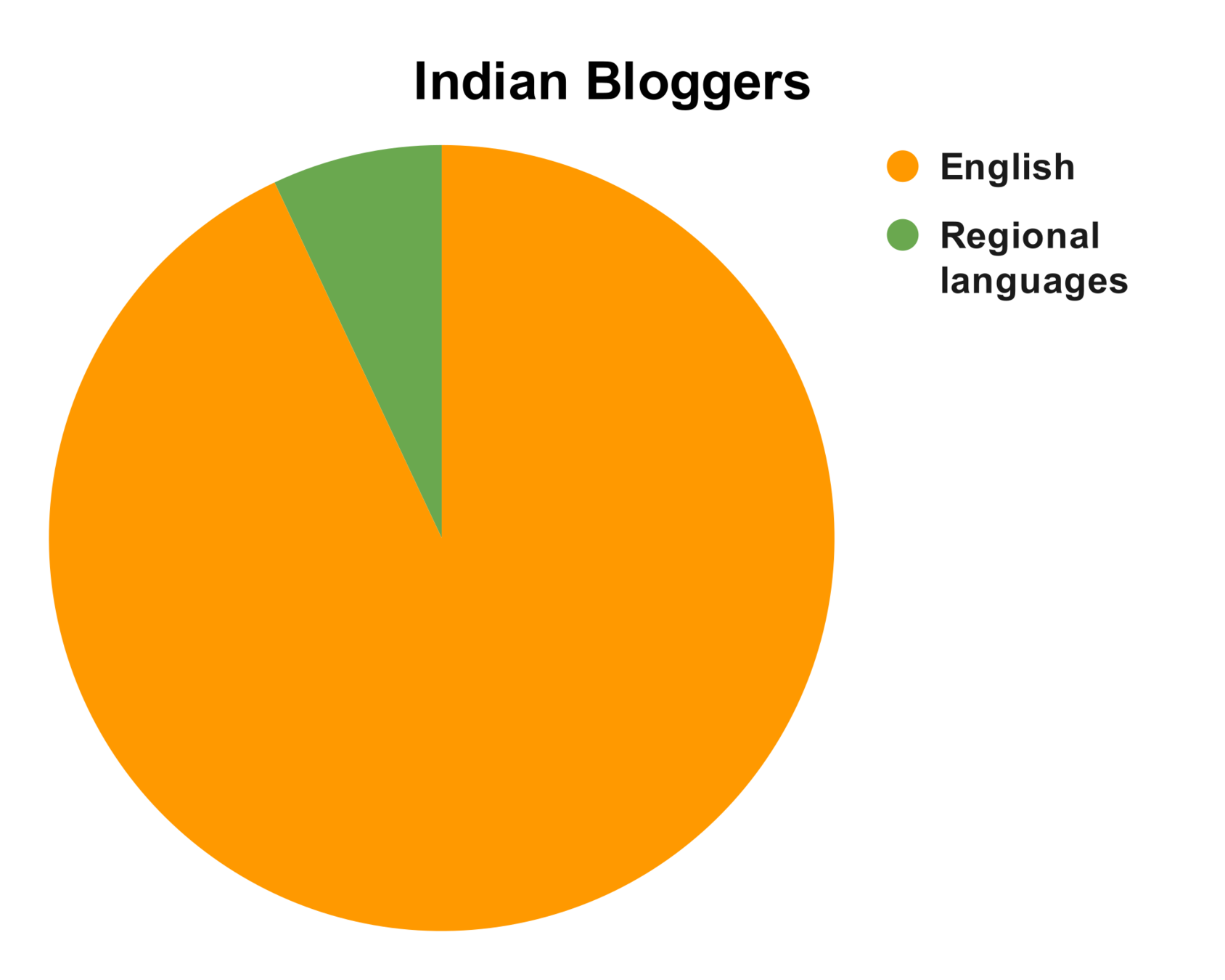



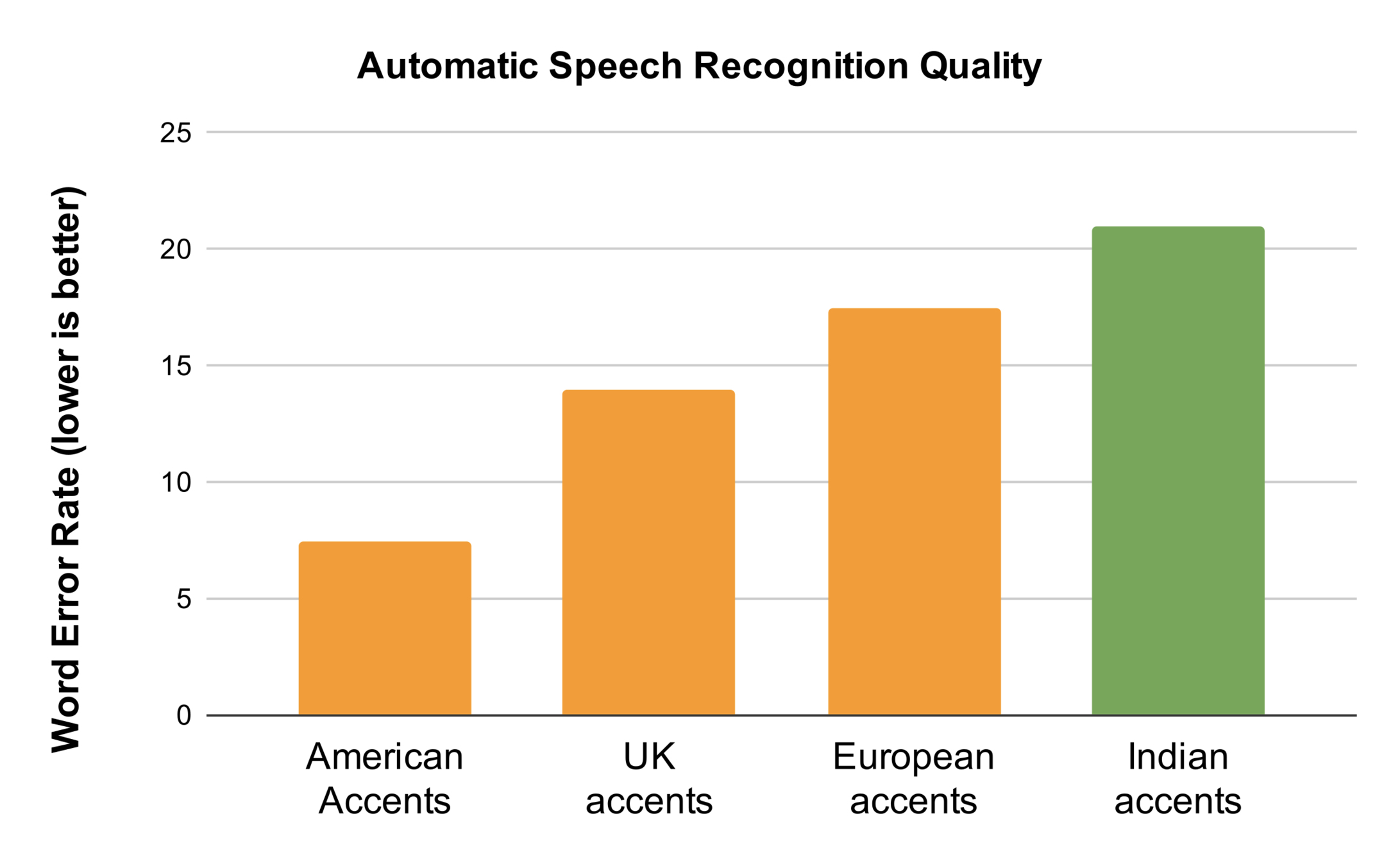
Very few Wikipedia articles
Poor indigenous input tools
Poor speech and lang. technology
The need for Indian NLP is clear!
The fact that we have not fully succeeded yet is also clear!
How do we find the secret of success?
The Indian NLP story
What is the proven recipe of success?
The (not-so-secret) recipe of English NLP



Collect huge amount of task agnostic unsupervised data
Pre-train a model
Create a benchmark of NLU tasks
Fine-tune and track progress



This is where IndicNLP is lagging
Curate: Curate datasets for Indian languages
Innovate: Create a common evaluation platform for tracking progress across multiple tasks in multiple languages
Build: Create an ecosystem of stakeholders to create and deploy solutions for the country at large
The way forward
What have we done so far?
IndicNLPSuite: Monolingual Corpora, Evaluation Benchmarks and Pre-trained Multilingual Language Models for Indian Languages.
The first step
Largest task agnostic monolingual corpus
A pre-trained language model (a.k.a. ALBERT)
A benchmark of NLU tasks

বা
हि
ಕ
म
ଓ
த
മ
অ
9 Billion tokens
labeled data for 14 tasks
10000 downloads

Serving under represented languages
Let's not forget them!



How do we plan to scale this?
Sentiment Analysis
En
Benchmark
हि
Automatic Translation



+
* Automatic Translation
* Manual Correction
* Smart Annotation Tools
हि
...
TRAIN
...
TEST
...
...
Sentiment Analysis
हि
Benchmark
TRAIN
TEST
Build semi-automated tools for data collection
Translation is the key piece!
What is the state of translation?
If translation is the key piece ...
Recent/Ongoing work
+

WMT
WAT'21
WAT'20
Legal
TICO
SAP
All
31.5
36.9
22.2
31.9
49.9
49.7
34.2
+
Benchmark: News, Legal, Health, Technical
29.0
42.3
22.8
37.2
47.4
44.1
36.1
Typically, at a score of 40 the output is good for post-editing
(as opposed to translating from scratch)
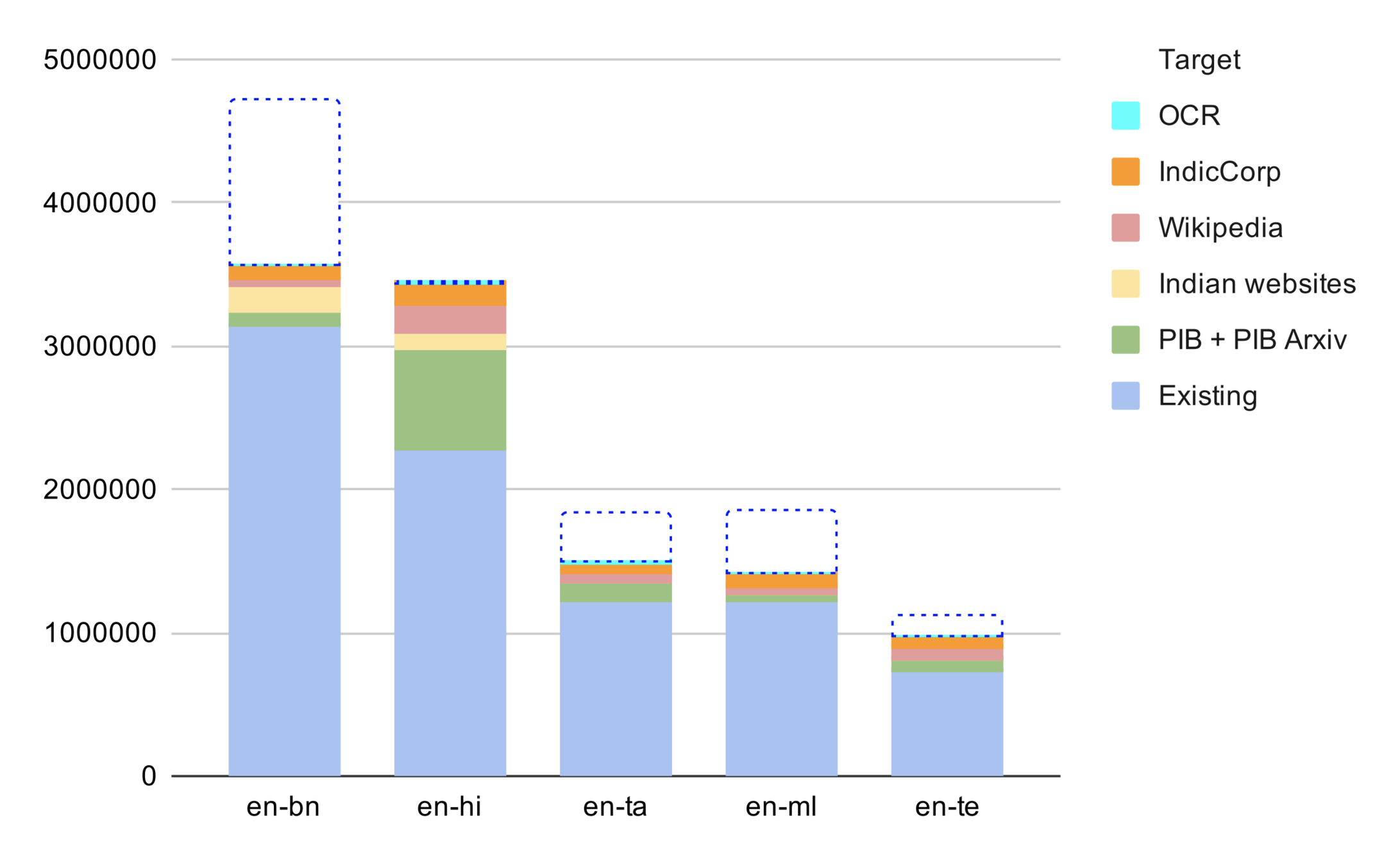
Where are we today? (Hi-En)
# sentences
+13%
+49%
+23%
+15%
+33%
Overall:+26.5%, +2.3M sentences

How did we get here?
(by mining data from the web)
Govt. docs, News websites, Wikipedia
Curated (free) data from the web for training translation systems
Recall: The recipe for success is data!
Key focus area for next 2 years
Beyond translation: What is our wish list of datasets/models?
Full NLP stack for Indian languages

Input Tools
Keyboards
Spell checkers
.... ....
Text Analysers
.... ....
Named Entity Recognition
Sentiment Analysis
Topic Classification
Content Filters
Inference Engines
QA
NLI

Paraphrase Detection
.... ....



Text Generators
.... ....
Translation
Dialog
Summarisation
Tools
Datasets
Basic Building Blocks
Models
Solutions

Task Agnostic (crawls)
Task Specific (annotated data)
Word embeddings
Tokenizers
, ' ' " ? ! . ; ( ) [ ]




Confidential
Open source datasets, models, solutions
How would we like to contribute to the NLTM?
Define clear goals
What is the performance that we should aim for?
en-fr
en-hi
1 year target
2 year target
How much data is required to get there?
data size
en-hi
en-bn
en-ta
Target (2 years)
Target (1 year)
2.3M
3.1M
1.2M
en-ml
1.2M
performance
Which tasks, tools, solutions to prioritise?
Y1
Y2
Y3
Set up a clear agenda/process for data collection

A standardised pipeline for crawling, cleaning, deduping and mining parallel sentences
Live, public database
User interface
125k


Sentences
Contributors
Code
Download (x MB)
Sample sentences
Report issues
\(\leftarrow\) "Data card"
Set up a clear agenda/process for model building
Standardised benchmark
বা
हि
ಕ
म
ଓ
த
മ
অ
Standardised metrics for tracking performance
Standardised API contracts for models

27.7
Avg. BLEU
Contributors
Download (x MB)
Code
Try the translator
Report issues
\(\leftarrow\) "Model card"
🤗
What is the organisation structure that we need?
Dev Partner (empanelment)
Scalable, automated systems
AI4Bharat
Academic Partner (IIT Madras)
Research, outreach
Industrial Research Partner
(Cloud resources, Adjunct researchers)
Annotation Partner (Desicrew)
Labelling quality data and scale
Startup and NGO Partners
Data collection, tool development grants


... ... ... ... ...

+


Yearly cost
Yearly budget: ~900K USD
2 Phd (fresh graduates)
5 MS (fresh graduates)
6 Post Baccalaureates
RnD
1 Principal Data Architect
2 ML engineers
4 Full stack developers
Deployment
20 Annotators
Labelling
884000
*
*
*
*
* (~600K USD)
96000
USD
180000
72000
48000
48000
60000
120000
60000
200000
Total
Physical Infrastructure
Space
Cloud Infrastructure
Equipment
AI4Bharat
*
What are our milestones?

*Indic-11
2021 (Ongoing)
2020 (Delivered)
2022 (Planned)
Open-sourced largest
mono-lingual corpora on Indic-11*
Open-sourced word embeddings, multilingual language models, benchmark datasets

Supported by
Supported by
Outputs: Peer reviewed paper,
AI models and datasets, Input tool
Looking for partners
Looking for partners