@ IIT Madras
The AI4Bharat Initiative

Mission statement of the Initiative
Bring parity in AI technology for Indian languages with English
Make fundamental contributions to state-of-the-art across language technologies - NLP, Speech, Sign language, OCR
Open source all datasets and AI models with permissible licenses
Build a coalition of partners to collect datasets and deploy models


Associate Professor, IIT Madras
PhD, IIT Bombay
Areas - NLP, Deep Learning
Mitesh M. Khapra
Pratyush Kumar
Our Team
Anoop Kunchukuttan

Assistant Professor, IIT Madras
PhD, ETH Zürich
Areas - Deep Learning, Systems
Researcher, Microsoft
PhD, IIT Bombay
Areas - NLP
+ many hard-working students and volunteers
What have we done so far (last 18 months)
IndicNLPSuite
Input Tools
INCLUDE
Samanantar
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ

E
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
Corpora, benchmarks, models for 11 Indic languages
Romanized keyboards for under-represented languages
Datasets and efficient models for isolated Indian Sign Language
Parallel corpus, translation models between English & 11 Indic languages

What have we done so far?
IndicNLPSuite
Input Tools
INCLUDE
Samanantar



Largest task-agnostic monolingual corpus
Pre-trained
language models
Benchmark set on NLU tasks
9 billion tokens
14 tasks
10,000 downloads
Impact: Indian startups and academia can now use large pre-trained models to support downstream tasks such as sentiment analysis, question answering, semantic matching, etc in 11 Indic languages
Across 11 Indian languages:
বা
ગુ
हि
ಕ
म
ਪੰ
த
తె
ଓ
മ
অ
\dots
\dots
C
T_1
T_N
T_{[SEP]}
T_1'
T_M'
\dots
\dots
[CLS]
E_1
E_N
E_{[SEP]}
E_1'
E_M'
\dots
\dots
[CLS]
Tok1
Tok N
[SEP]
Tok 1
TokM
Masked Sentence 1
Masked Sentence 2
What have we done so far?

User types using English script
Automatically converted to Maithili script

IndicNLPSuite
Input Tools
INCLUDE
Samanantar
Impact: Input tools become significantly more efficient for a long list of Indian languages. Impacts all content creation including writing storybooks for children
Deployed to write storybooks at
What have we done so far?
IndicNLPSuite
Input Tools
INCLUDE
Samanantar
Impact: The first large-scale AI work on Indian Sign Language. Won the first AI4Accessibility global challenge run by Microsoft for scaling up data collection to continuous sign language through 2021-22
Largest public dataset on Indian Sign Language
263 signs, 4000+ videos
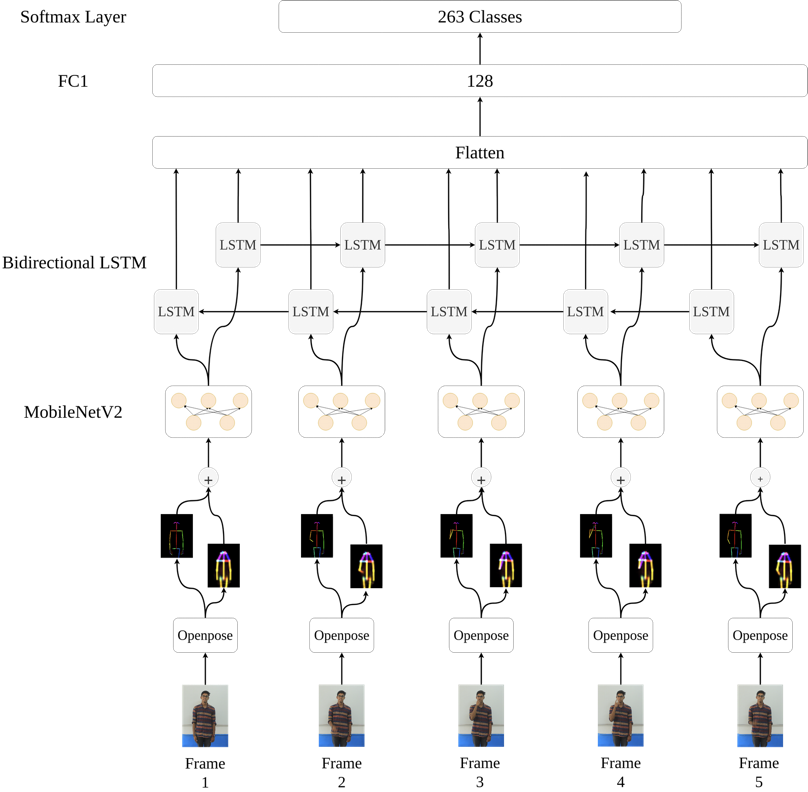
Efficient AI models for recognising signs
>90% accuracy
What have we done so far?
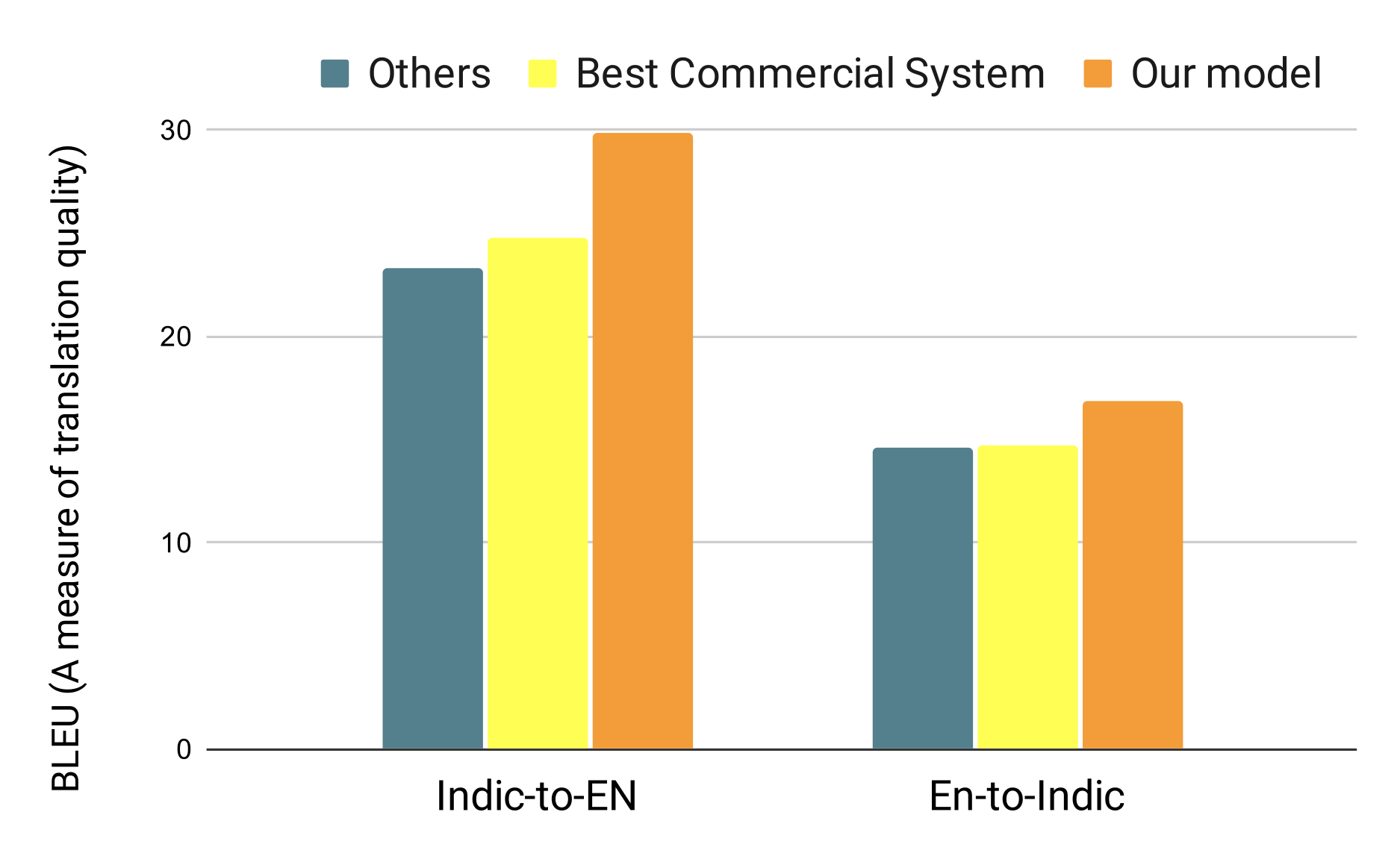
AI model for translating between English and 12 Indic languages
IndicNLPSuite
Input Tools
INCLUDE
Samanantar
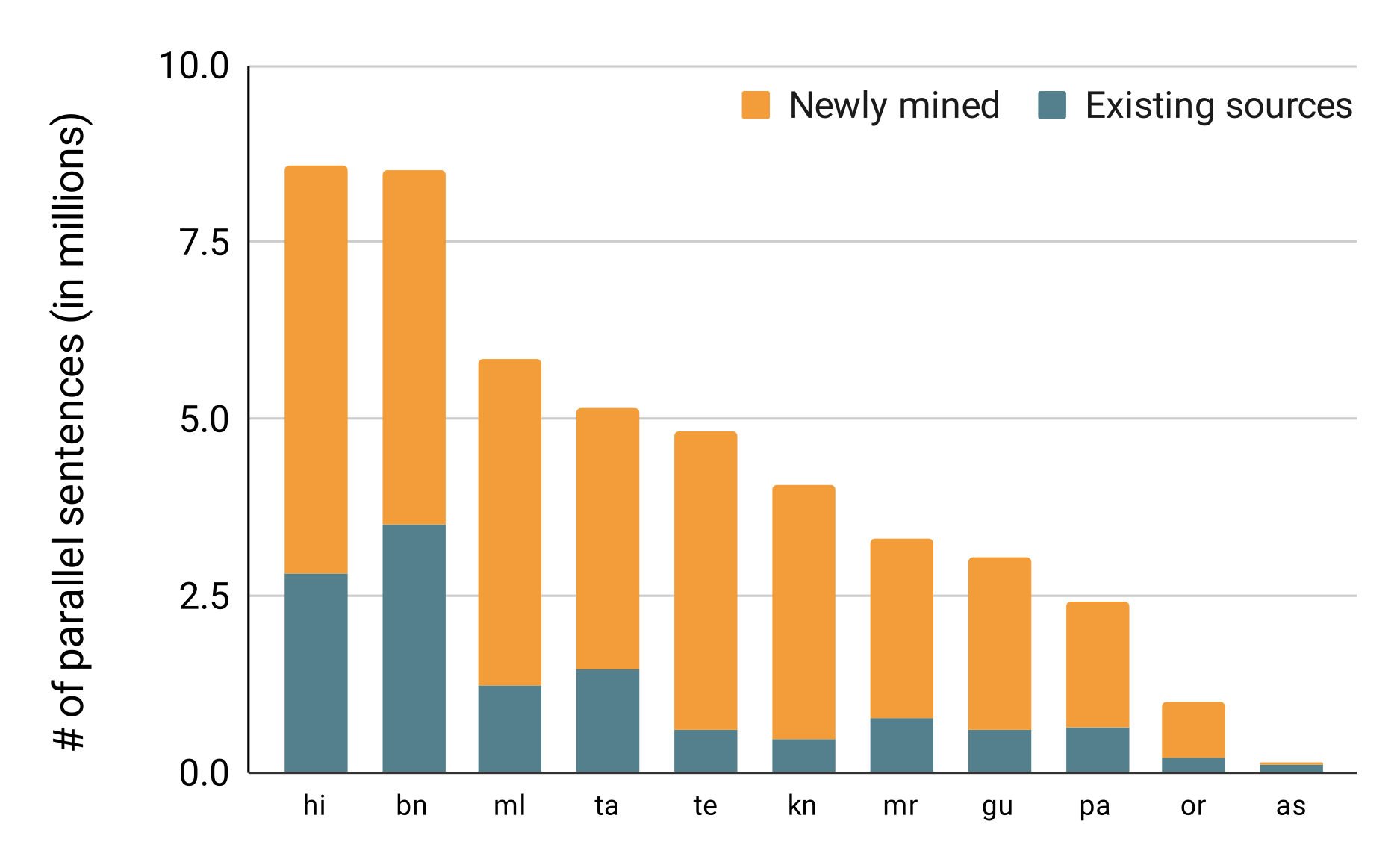
46M parallel sentences mined from the web (3X improvement)
Impact: The translation models (which are shown to be more accurate than commercial APIs) are being used to assist human translators in translating supreme court judgements with a significant increase in efficiency
What are some of our ongoing activities?
Creating a robust, standardised benchmark for Machine Translation
Mining high quality text to speech data for building ASR models
Building models for continuous signs in video call apps








What next? (A long tail of NLP tasks)
What does it take to build a typical NLP application?
Full NLP stack

A chatbot for Aaarogya Setu

Input Tools
Keyboards
Spell checkers
.... ....

Text Analysers

.... ....
Sentiment Analysis
Content Filters

Inference Engines
QA
Natural Language Inference
.... ....

Text Generators
.... ....
Dialog
Build this full stack for each Indic language


Text Generators
.... ....
Translation
Dialog
Summarisation
Inference Engines
QA
NLI

Paraphrase Detection
.... ....
Text Analysers
.... ....
Named Entity Recognition
Sentiment Analysis
Topic Classification
Content Filters
Input Tools
Keyboards
Spell checkers
.... ....
What do we need?
Set up "The AI4Bharat Initiative" @
Yearly budget
1M USD
House a best-in-class team of researchers, engineers and developers




Build capacity by conducting workshops for startups, industry and academia

Rent/set up world class compute infrastructure for building cutting edge AI models
Build datasets and benchmarks by partnering with annotation service providers



What have we learnt from these efforts?
We identified the pillars to solve problems at scale for Indic languages with fast-evolving AI technologies
These pillars are an uncommon mix of skills
engineering
research
human annotation
cutting-edge hardware
What have we learnt from these efforts?
Benchmarks - Collect high quality benchmarks through human annotation
Models - Build state-of-the-art deep learning architectures through research
D M B S
Open source
Deployable use-cases
Systems - Have access to & optimise model training on cutting-edge hardware
Data - At-scale engineering to mine Indian language data from the public web
engineering
research
human annotation
cutting-edge hardware

What have we learnt from these efforts?
NLP
Speech
Sign Language
OCR
Over the next 3 years,
we will replicate these structures across different language technologies with
at the AI4Bharat initiative