An AI4BHARAT INITIATIVE
indicnlp.ai4bharat.org
A HUB FOR INDIC NLP RESOURCES, DATASETS AND TOOLS


Assistant Professor, IIT Madras
BTech from IIT Bombay, PhD from ETH Zurich
Worked at IBM research
DL consultant for startups
35 research papers, 18 patents
Assistant Professor, IIT Madras
PhD from IIT Bombay
Exp in teaching DL to industry and academia,
5 years exp at IBM research,
40+ research papers
Google Faculty Award, Young Faculty Recognition Award
Dr. Mitesh M. Khapra
Dr. Pratyush Kumar

Launched in Jul 2019: Working on several open-source projects of social importance in AI
Founding team (indicnlp.ai4bharat.org)
About Us
Senior Applied Researcher, Microsoft India,
PhD from IIT Bombay
Exp. in Machine Translation, Multilingual NLP, Building tools and resources for Indian NLP
2+ years experience at Microsoft Translator group
35+ research papers
Dr. Anoop Kunchukuttan

Philosophy
About Us
Harness AI for serving Bharat!
Invest in Indian language technology today to amplify the impact of social outreach programs in India as well as to drive commercial success in an increasingly multilingual digital world





















বা ગુ हि ಕ മ म ने ਪੰ த తె ار
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
The social view
Touch Points: Digital
Users: Multlingual
Language technology is absolutely essential to magnify reach and impact in the social sector
The commercial view




















Multilingual chatbots
Sentiment Analysis
Content Moderation
Code mixed song search
Speech
QA
Multilingual Authoring Tools

... And the demand for these tools is increasing
*Source Google-KPMG report https://assets.kpmg/content/dam/kpmg/in/pdf/2017/04/Indian-languages-Defining-Indias-Internet.pdf

કેમ છો
कैसे हैं

Chat applications
Digital entertainment
Social media platforms
Digital
news
Digital write-ups
Digital payments
e-governance services
e-commerce services
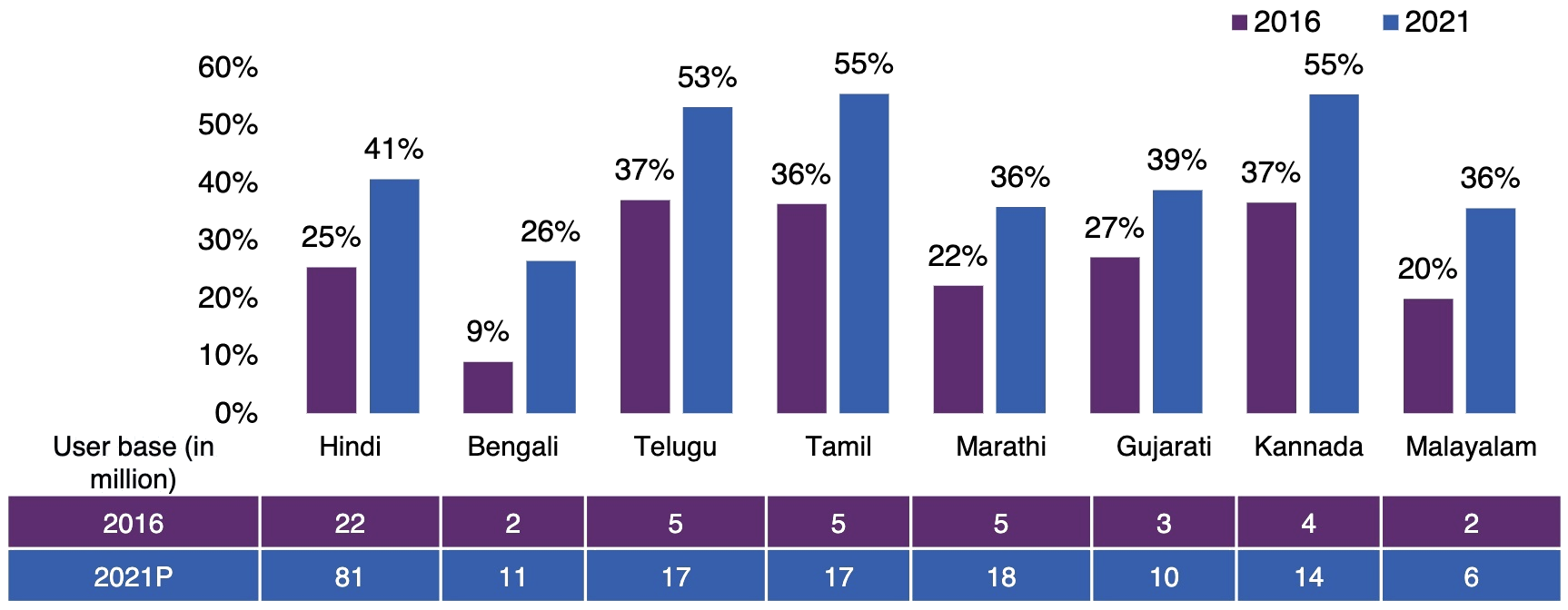
22 official languages 1.3 billion speakers
By 2025, 75% of Indian internet users will use Indian languages
Demand for speech and text technology
Rich diversity
, growth
and demand
... But we are far behind
Poor in resources
, tools
and technology
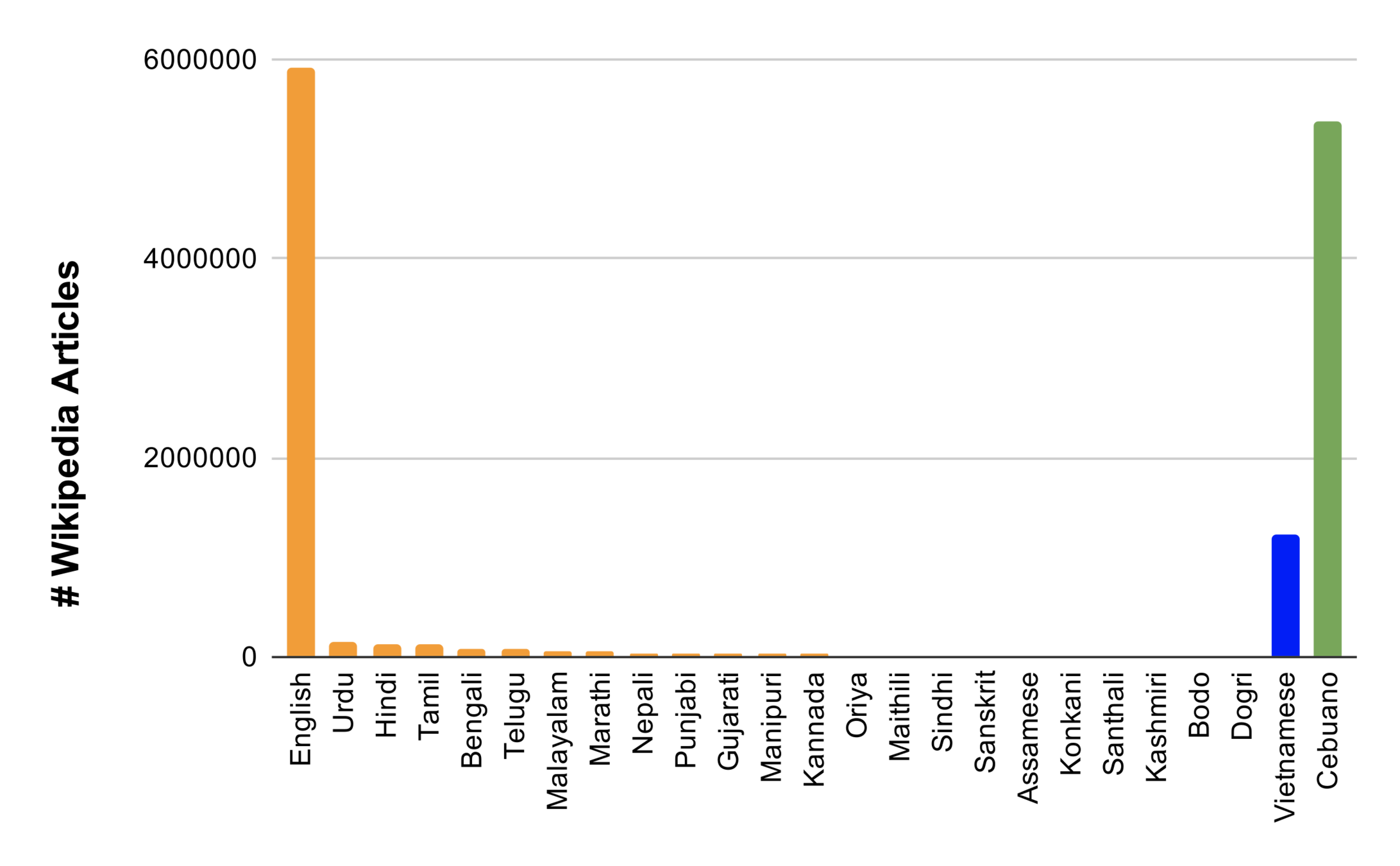
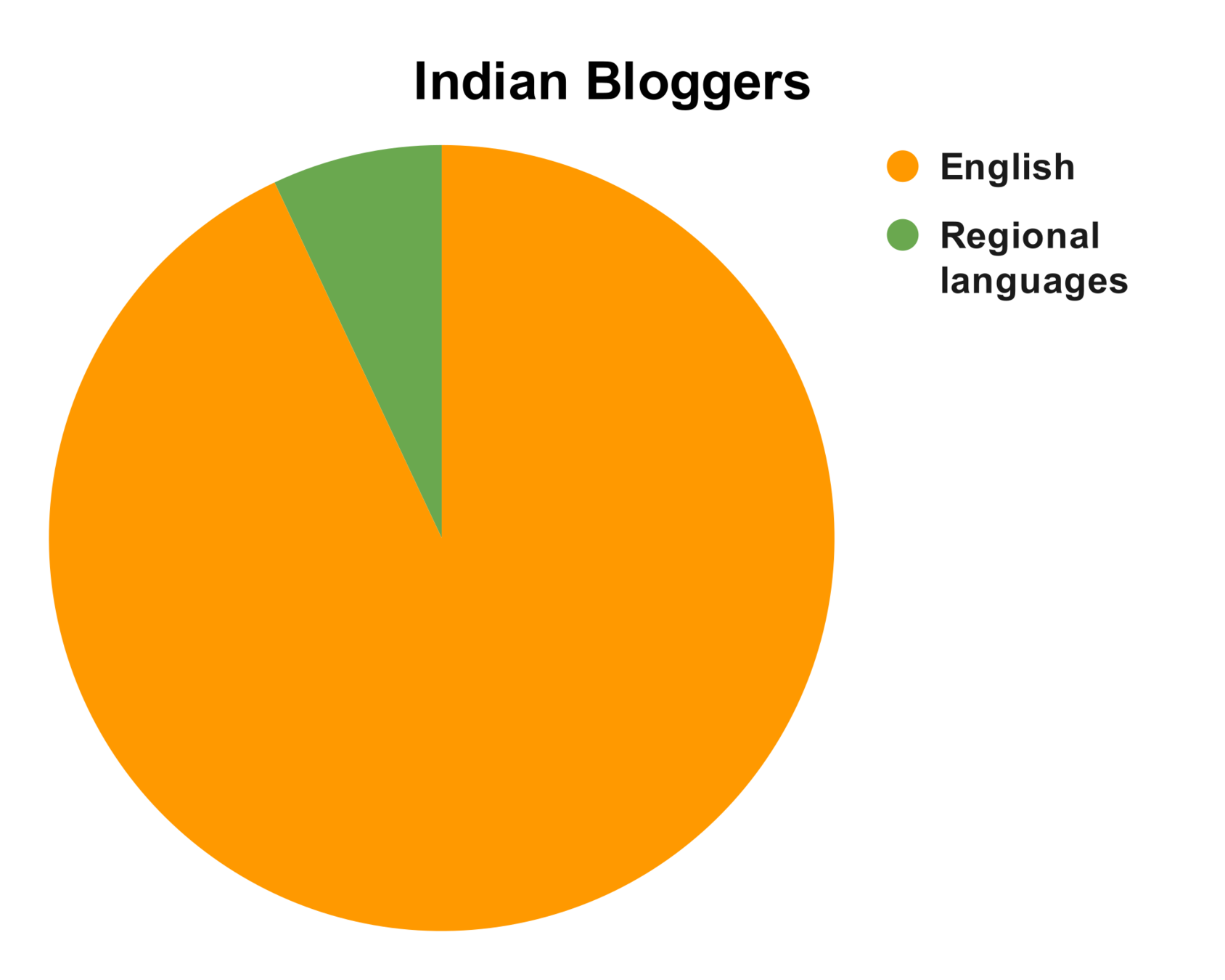



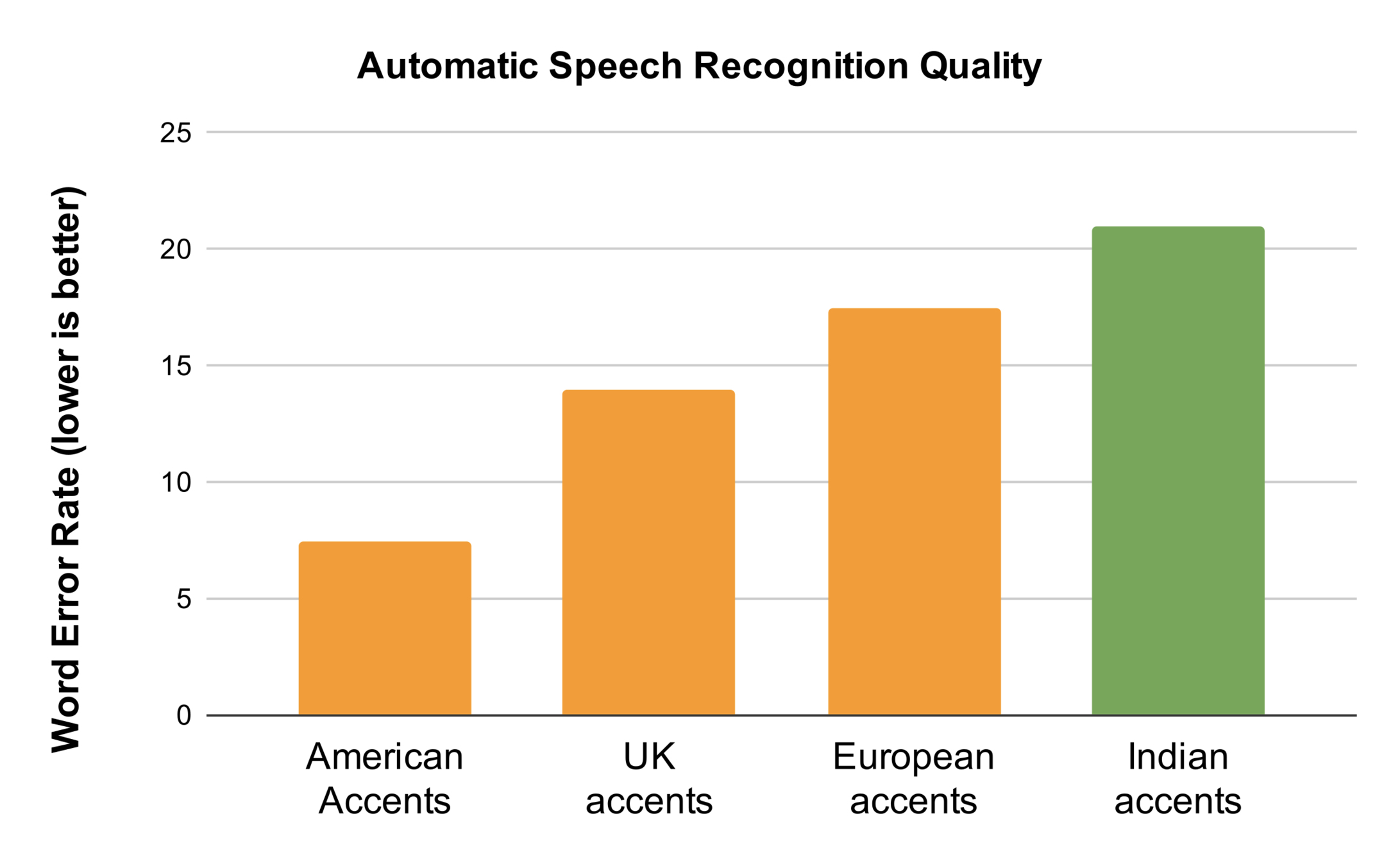
Very few Wikipedia articles
No indigenous input tools
Poor speech and lang. technology
The need for Indian NLP is clear!
The fact that we have not succeeded so far is also clear!
How do we find the secret of success?
The Indian NLP story
The (not-so-secret) recipe of English NLP



Collect huge amount of task agnostic unsupervised data
Pre-train a planet warmer (a.k.a. BERT)
Create a benchmark of NLU tasks
Fine-tune and track progress



This is where IndicNLP is lagging
Curate: Curate datasets for Indian languages
Innovate: Create a common evaluation platform for tracking progress across multiple tasks in multiple languages
Build: Create an ecosystem of stakeholders to create and deploy solutions for the country at large
The way forward
Authors: Divyanshu Kakwani, Anoop Kunchukuttan, Satish Golla, Gokul N.C., Avik Bhattacharyya, Mitesh M. Khapra, Pratyush Kumar
IndicNLPSuite: Monolingual Corpora, Evaluation Benchmarks and Pre-trained Multiple Language Models for Indian Languages. Findings of EMNLP (EMNL-Findings), 2020
A small step
IndicCorp
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
Punjabi
Hindi
Bengali
Odia
Assamese
Gujarati
Marathi
Kannada
Telugu
Malayalam
Tamil
#Sentences
#Tokens
#Types
IndicCorp:Oscar/CC
(millions)
(millions)
(millions)


Highlights
2 to 22 times larger than OSCAR
~107M to 1.8B tokens per language
1 to 11 times larger than the data used to train XLM-R (+cleaner)
*
*
*

canonicalised, tokenised using Indic NLP library+
*
https://github.com/anoopkunchukuttan/indic_nlp_library
+
29.2
773
3.0
22
63.1
1860
6.5
2
39.9
836
6.6
2
6.94
107
1.4
9
1.39
32.6
0.8
8
41.1
719
5.7
14
34.0
551
5.8
7
53.3
713
11.9
14
47.9
674
9.4
8
50.2
721
17.7
8
31.5
582
11.4
2
11
1
1.6
3
6.5
5.1
5.1
3.2
2.7
2.3
0.98
IndicGLUE
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
News classification
Sentiment Analysis
Discourse Mode classification
Wiki Section Title Selection
News Headline Selection
Named Entity Recognition
Highlights
semantic similarity (two sequences) tasks
single sequence classification tasks
sequence labelling task
*
*
*
inference/two sequence classification tasks
*
zero shot learning tasks
*
Cloze Style QA
Winograd NLI
Plausible Alternatives
Paraphrase Detection
Cross language Retrieval
Translated from En
Existing datasets
New datasets
IndicFastText
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
Wikipedia
IndicCorp
Highlights
word similarity tasks
FT-IC outperforms FT-W and FT-WC on
bilingual lexicon induction tasks
*
*
text classification tasks
*
Wikipedia +CommonCrawl
(FT-W)
(FT-WC)
(FT-IC)
IndicBERT
Highlights
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
lighter ALBERT based model, easy to deploy
both ALBERT_base and ALBERT_large available
*
*
Outperforms m-BERT & XLM-R on most tasks (despite being smaller)
*
Fine-tuning per language per task
m-BERT performs better on Wiki tasks
*
Cloze QA and cross language retrieval are challenging
*
Corpus size influences performance (Assamese and Odia)
*
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
Joint Pre-training
ALBERT
MASK LM
MASK LM
Sentence 1
Sentence 2
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
WNLI
NER
COPA
ਪੰ
ALBERT
MASK LM
MASK LM
Sentence 1
Sentence 2
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
WNLI
NER
COPA
हि
ALBERT
MASK LM
MASK LM
Sentence 1
Sentence 2
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
ALBERT
MASK LM
MASK LM
Masked Sentence 1
Masked Sentence 2
WNLI
NER
COPA
த

What next?
Crawl more articles to grow the monolingual corpus size
*
Create more challenging datasets\(^{+}\): QA, NLI, Paraphrase
*
Cover the 22 official languages
*
Run AI4Bharat challenges\(^{+}\): collaboratively create datasets & models
*
Create input/annotation tools for Indian languages
*
https://transliterate.ai4bharat.org/
https://ezannotate.ai4bharat.org/




NLU
Input Tools
Create OCR tools for Indian languages
*
NLG
Build a multilingual translation model
*
Build a pre-trained multilingual generation model
*
https://ocr.ai4bharat.org/

A costly affair
Create more challenging datasets\(^{+}\): QA, NLI, Paraphrase
*
A cross lingual evaluation benchmark on the lines of XTREME
\(^+\) Possible only with industry/government support
manually translate the evaluation sets

IndicXTREME
Cost: 15K USD per language
And then there is NLG ...
Needs much more investment and collaboration!
Important Links
https://indicnlp.ai4bharat.org/indic-glue/
https://indicnlp.ai4bharat.org/corpora/
https://indicnlp.ai4bharat.org/indicft/
https://indicnlp.ai4bharat.org/indic-bert/
https://indicnlp.ai4bharat.org/explorer/
A large scale task agnostic monolingual corpus
A pre-trained planet warmer (a.k.a. ALBERT)
A benchmark of NLU tasks
Contribute and track progress
.... .... and Repeat!
Summary
Contact Us
Let's make India ready for the AI age
Anoop Kunchukuttan
Mitesh M. Khapra
Pratyush Kumar
miteshk@cse.iitm.ac.in
pratyush@cse.iitm.ac.in