Learning Human Activities and Object Affordances from RGB-D Videos
Hema Swetha Koppula, Rudhir Gupta, Ashutosh Saxena
Okan Yıldıran - 2015700153
Introduction
In this work, they presented learning algorithms to detect human activities and label them over long time scales. They also detected affordances of the objects in the view.

Idea
- 1. Track human skeleton for each frame in the video
- 2. Detect objects for each frame
- 3. Segment the video by sub-activities
- 4. Calculate features for each segment
- 5. Model it by Markov Random Field(MRF)
- 6. Train it with Structured Support Vector Machine(SSVM)
- 7. Infer by Mixed Integer Programming Solver(MIP)

Idea

Idea
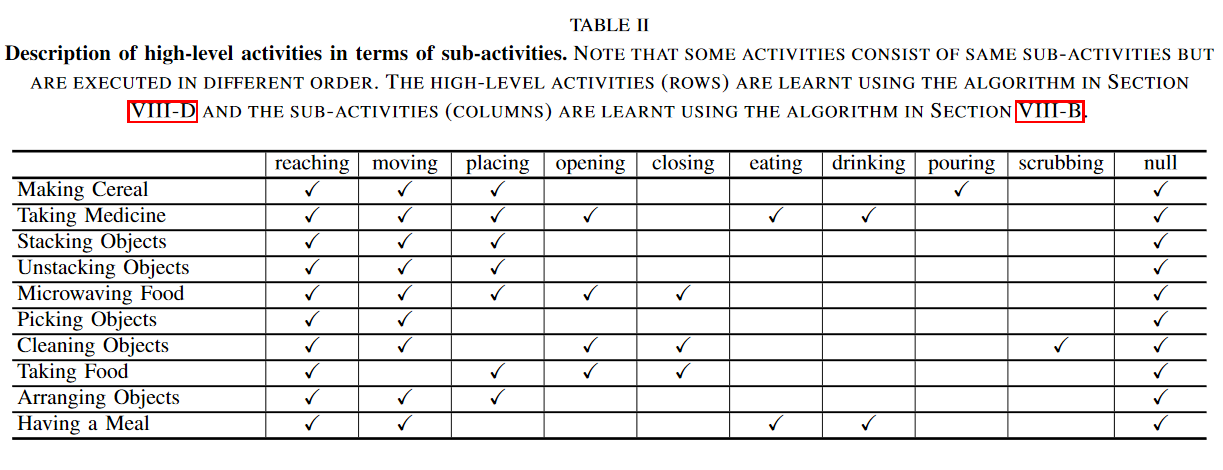
Model
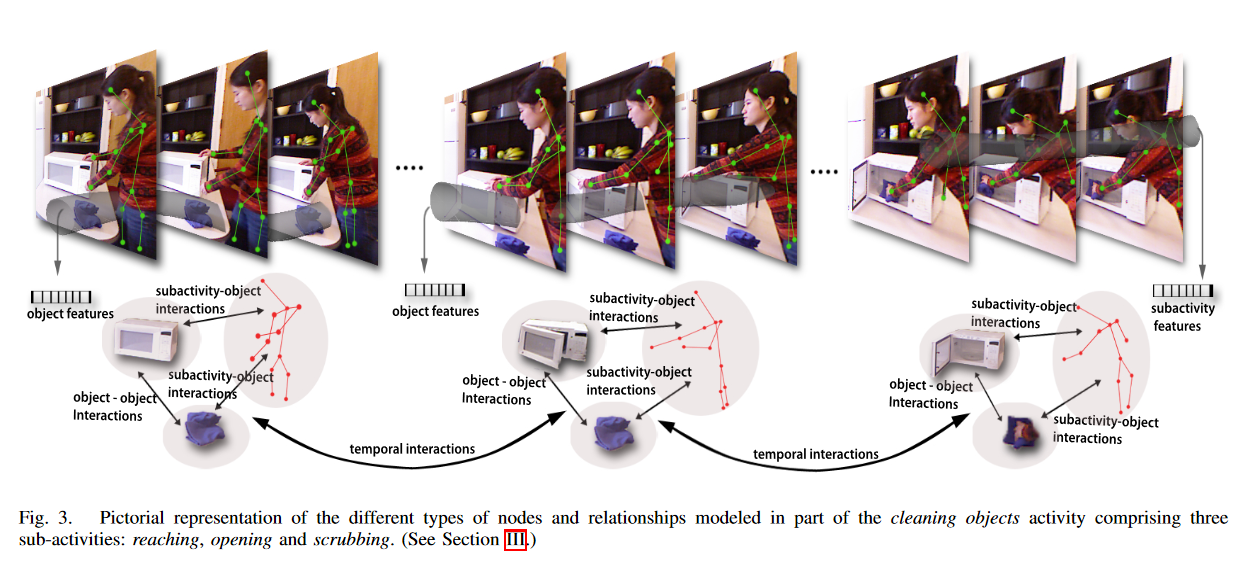
Segment
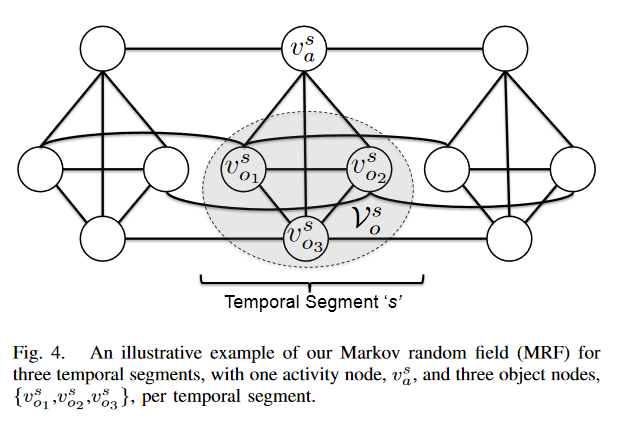
Model - MRF
Sub-activity
Objects
Model - MRF
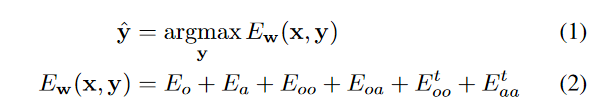
object nodes
subactivity nodes
object to object interactions
object to sub-activity interactions
object to object between segments
sub-activity to sub-activity between segments
Any MRF can be written as log-linear model
Model - MRF
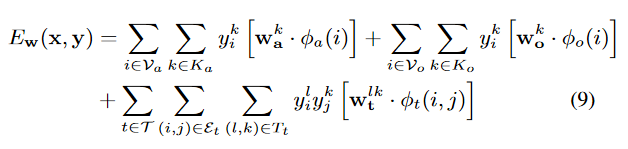
label
weight
features
Training: We know labels and features, find best weights (SSVM)
Inference: We know weights and features, find best labels (MIP Solver)
Training - Inference
Training:
- We know labels and features, find best weights (SSVM)
- Quadratic programming
- Cutting plane algorithm
Inference:
- We know weights and features, find best labels (MIP Solver)
- Quadratic optimization problem
- Graph cut algorithm
Object Detection and Tracking
- Skeleton tracking using depth data and OpenNI tracker
- For objects, they trained SVM classifier with RGB-D dataset of common objects.
- Reduced set of bounding boxes by only considering those close to hands of skeleton.
- Object tracking done by particle filter tracker in PCL library.
- They only consider tabletop objects.
- Detection algorithm run in every fixed number of frames.


Temporal Segmentation
They performed temporal segmentation in order to represent atomic movements of human skeleton in an activity.
They used three methods
- Uniform segmentation
- Sum of the euclidean distances between joints
- Rate of change in euclidean distance between joints
Begin with every frame corresponds to a node, iteratively merge them by one of those methods.
Features
Cumulative binning into 10 bins.
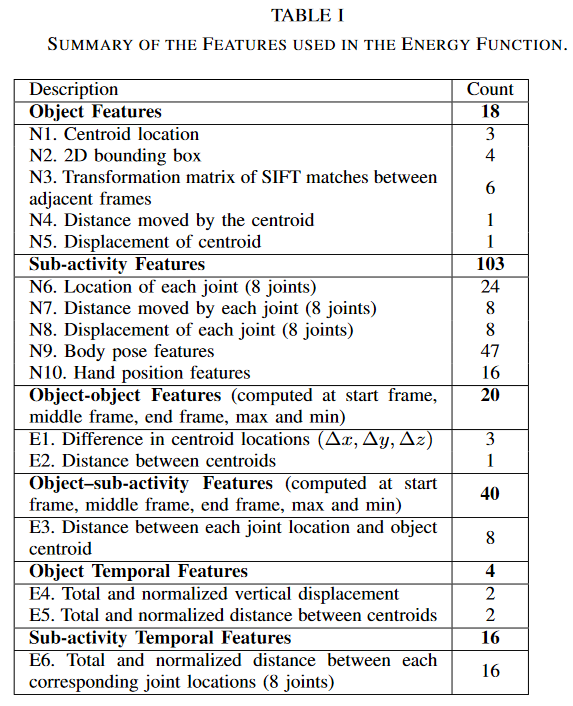
Total 2010 features for each segment
High level activity
They computed histograms of sub-activities and affordance labels, use them as features.
They trained multi-class SVM classifier over training data.
Data
Cornell Activity Dataset - 60
- 60 RGB-D videos of four subjects performing 12 high level activities
- However those activities only contain one sub-activity and do not contain object interactions
Cornell Activity Dataset - 120
- They collected and published
- 120 activity videos of four subjects performing 10 high level activities
- Each high level activity performed three times
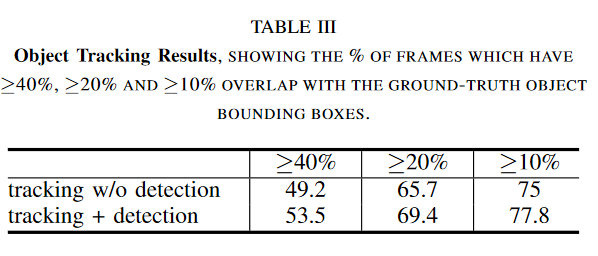
Object tracking results

Labeling results
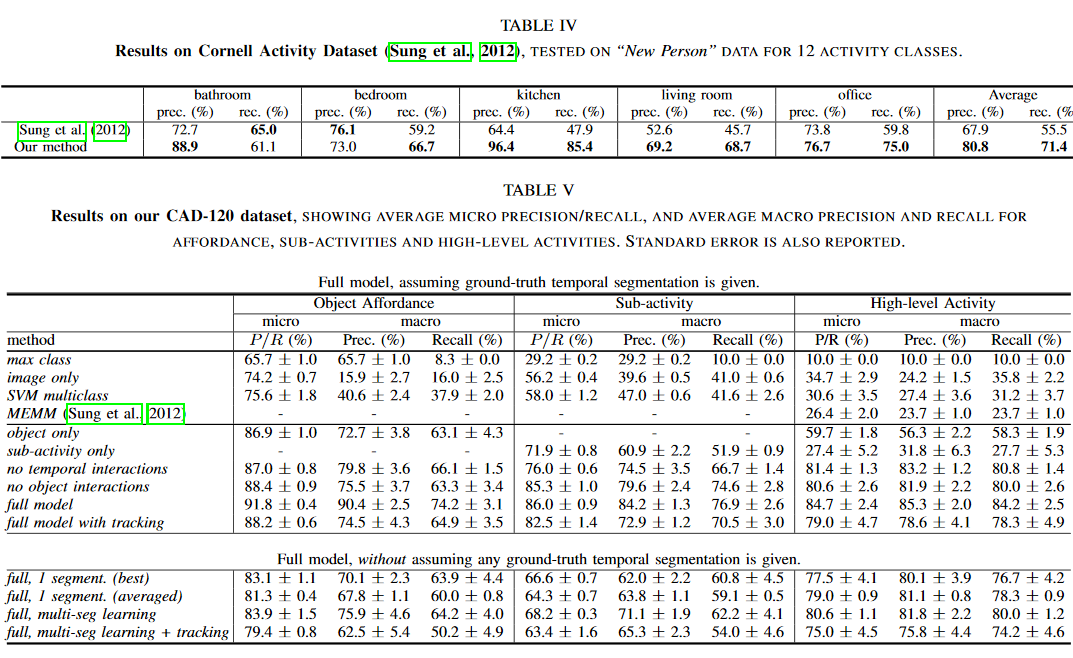
Labeling results
With object context, activity detection precisions increased.
With sub-activity context, affordance detection precisions increased.
With object-object interactions modeled, affordance detection improved.
With temporal interactions modeled, affordance and sub-activity precisions increased.
With their object tracking algorithm, precisions lower than using ground-truth tracks.
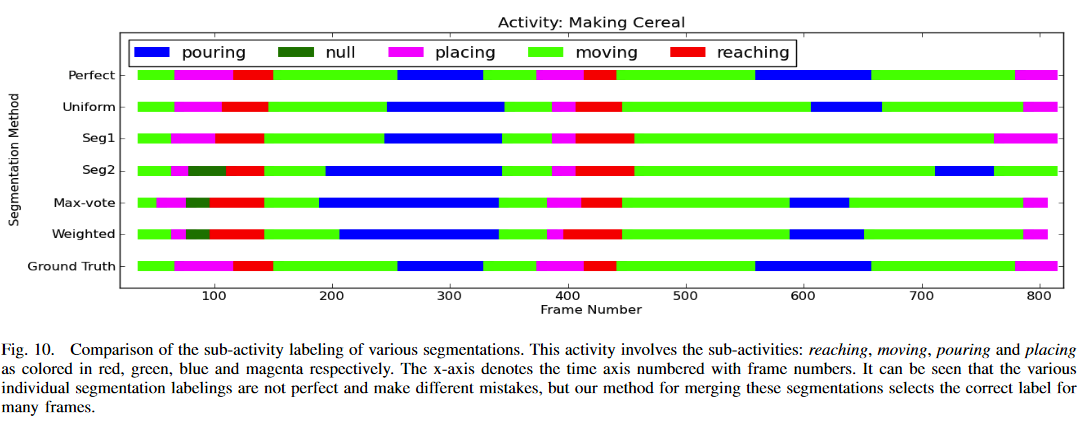
Segmentation results
With object context, activity detection precisions increased.
Applications
Assisting humans
- Depending on the task, perform complimentary sub-task.
- When person attempts to take medicine, bring glass of water
- Clear table when person having meal
- When making cereal, take milk and put to refrigerator
Using affordances
- Clear table by moving bowl not microwave
- Generalizing affordance detection
Conclusion
Labeling activities in RGB-D videos over long time
Formulated model with MRF, learned parameters with SSVM
Affordance labeling by using activities