SEO & Web Client Side Performance optimization
Kyle Mo
預防針
Agenda
-
SEO
-
Web Client Side Performance
SEO
-
Basic Knowledge
-
Basic Factors
-
Meta Tag
-
Robots Index
-
Other Key Factors
SEO Basic Knowledge
搜尋引擎最佳化 (search engine optimization)
分數越高,出現在搜尋結果的越前面
根據統計顯示,90 % 使用者只會瀏覽前三頁
So important !


SEO Basic Factors
- 網址
- HTML Semantic Element
- 標準網址
- Sitemap
(預防針:以上方法沒有證明對 SEO 有絕對正向幫助,畢竟演算法不停改變)
SEO Basic Factors - 網址
-
ㄧ定要用 https
-
HTTP -> HTTPS 轉址請用 301 永久性轉址:相較於 「302 暫時性轉址」,搜尋引擎會將新地址記下來, 如果是暫時性,會再走一次舊地址再導到新地址。
-
網站上不要有 Mixed Content : some HTTP, others HTTPS.
SEO Basic Factors - 網址
其他小提醒

SEO Basic Factors - HTML Semantic Elements
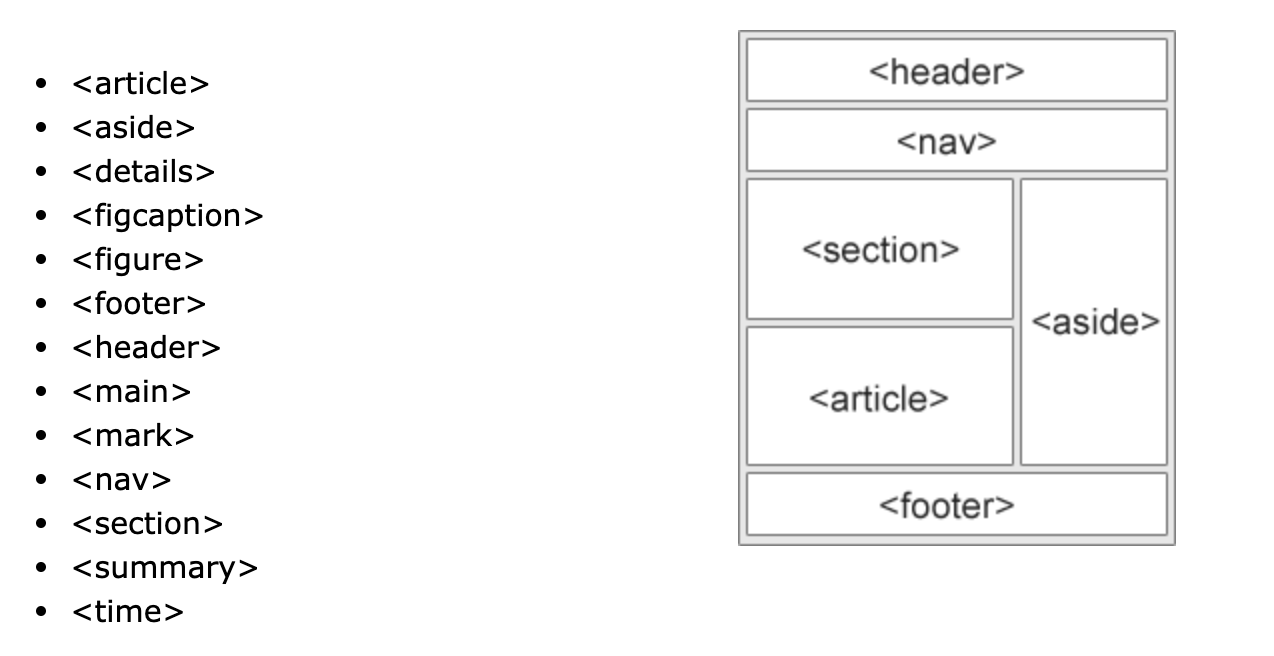
文字最好按照階層排:<h1> -> <h3> -> <p>
SEO Basic Factors - 標準網址 (Canonical)
如果你有某個網頁,但有許多不同的連結,或者不同的網頁間內容有高度的相似度。這時候搜尋引擎會將這些網頁視為相同網頁的「重複版本」,從中「隨機」選出一個網址做為「標準版本」進行檢索,而其他網址則會被視為「重複網址」,檢索頻率會比較低。
什麼情況會發生相似或重複的網頁?
支援多種裝置的網站
https://taobao.com
https://m.taobao.com
搜尋參數等動態網址
https://taobao.com/items?類別=上衣
https://taobao.com/items/秋冬長袖
伺服器針對 www/http/https 提供相同內容
https://example.com
http://example.com
https://www.example.com
為了避免讓搜尋引擎選到一個不是我們想要的網址做為「標準版本」,這時候,我們就可以在網頁中加上一個「標準網址」(Canonical Tag)的資訊。
<link rel=”canonical” href=”PREFERRED URL” />
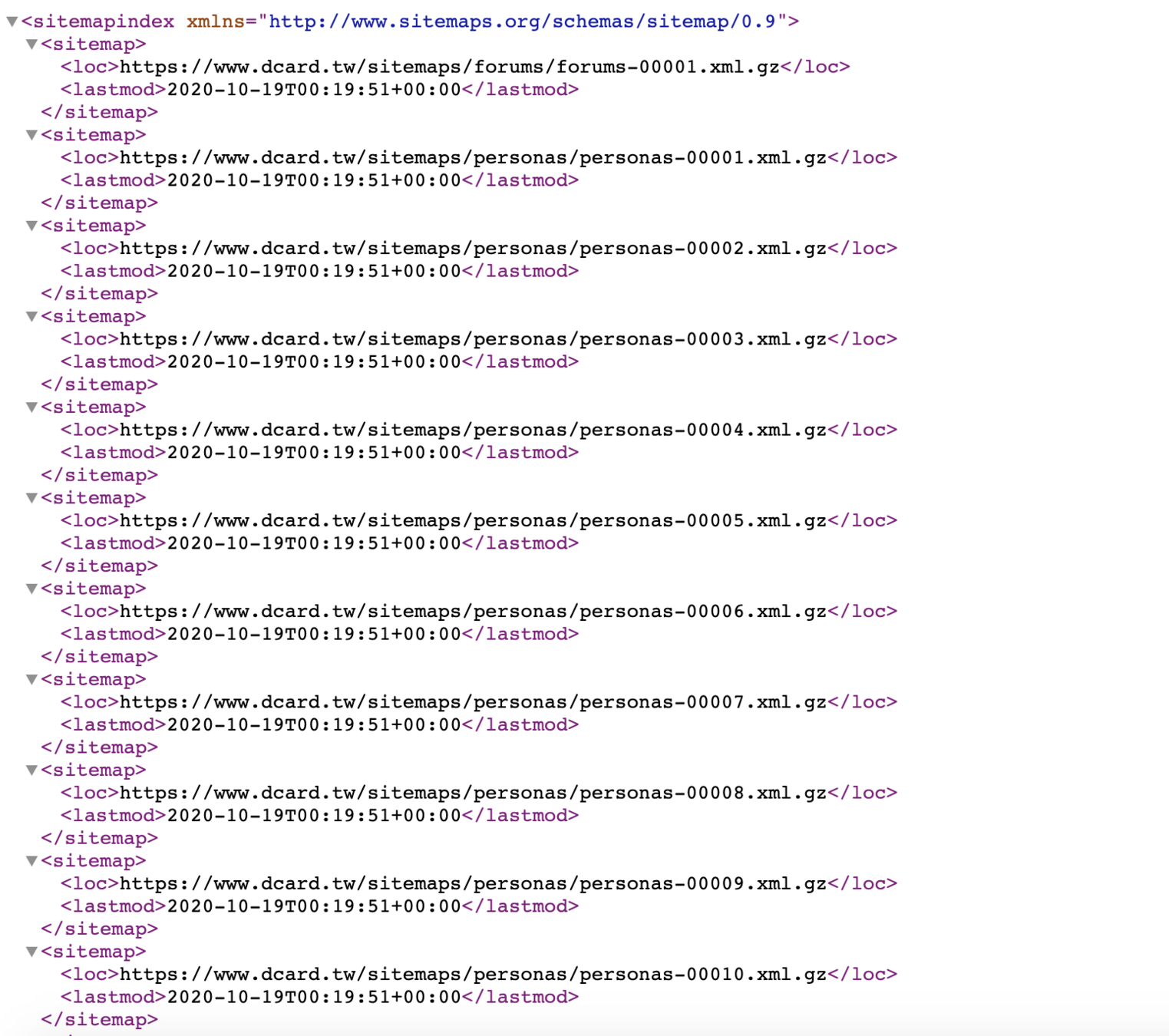
SEO Basic Factors - Sitemap
搜尋引擎透過網路爬蟲對頁面進行分析與索引,但可能因為效率或 timeout 的因素,部分頁面一直無法被爬取,這時候我們可以提供 sitemap,將網頁全局資訊提供給搜尋引擎。
SEO Meta Tags
縮圖
標題
描述
Open Graph Protocol
Facebook 在 2010 年提出,定義了的 HTML Meta Tag 中如何描述網頁的標題、縮圖、描述等資訊,不僅僅 Facebook 使用,現在越來越多的網站都支援 Open Graph Protocol。

常見的 Meta Tag
- 網頁標題:<meta property=”og:title” content=”網頁標題”/>
- 網頁描述:<meta property=”og:description” content=”網頁描述”/>
- 網頁類型:<meta property=”og:type” content=”網頁類型”/>
- 網頁縮圖:<meta property=”og:image” content=”網頁縮圖放這裡”/>

Robots index
robots.txt 檔案可協助您控制搜尋引擎如何抓取/索引可公開存取的網站。
https://www.dcard.tw/f
http://stage.dcard.io/f
Production
Stage
需要避免測試環境影響到 production 的 SEO
然而這樣還是有可能被搜尋引擎列出來
爬蟲的運作模式為對每個網站進行「檢索(Crawl)」,檢索主要是分析網站的關鍵字、內容品質、外部連結...等面向,計算網站的權重。
而在檢索後,爬蟲程式會在網頁間的連結進行移動,藉以串接整個網路,並把資料放進Google資料庫,這個過程則稱為「索引(index)」。
Noindex
網站中,有部分的網頁可能對 SEO 有幫助,但是不需被搜尋引擎找到的,網站管理者便可針對這些網頁設下Meta-Noindex 指令。當爬蟲程式檢索網頁時,Noindex 將告訴爬蟲程式不要替此網頁建立索引,如此一來,此頁面便不會呈現在搜尋結果頁面。

Nofollow
當網站擁有較佳的權域值及搜尋排名時,難免會有其他排名較低的網站,來排名佳的網站留言區留下垃圾連結,甚至寫惡意程式產生大量外部網址,企圖將好網站的權域值傳給自己的網站,以提升網站排名,俗話說就是來「蹭」好網站的權重。
透過 nofollow tag,爬蟲不會將這些外部連結的品質納入檢索的評分,換句話說,即是聲明「這些連結與本站無關」。通常會加在:
評論區、社群媒體或論壇...等頁面
Other Key Factors
Web Client Side Performance optimization
-
Performance in frontend
-
Define the problem: performance analyzer
-
PageSpeed
-
Lighthouse (CI)
-
-
Core web vitals
-
Other Skills
-
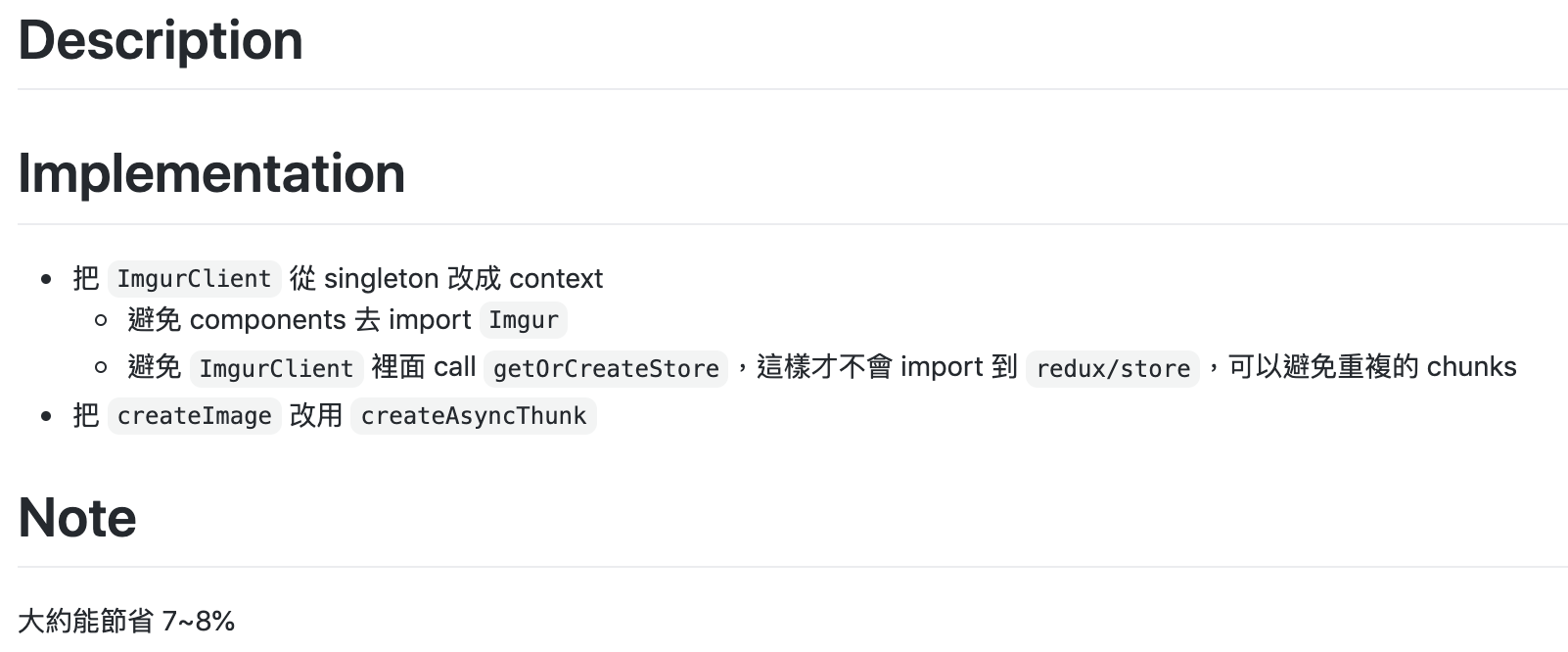
Code splitting / Dynamic import
-
Webpack bundle analyzer
-
Tree shaking
-
Cache
-
Performance In Frontend, Why?
- SEO
- 使⽤者體驗
- 影響營收的重要指標

Define The Problem: Performance Analyzer
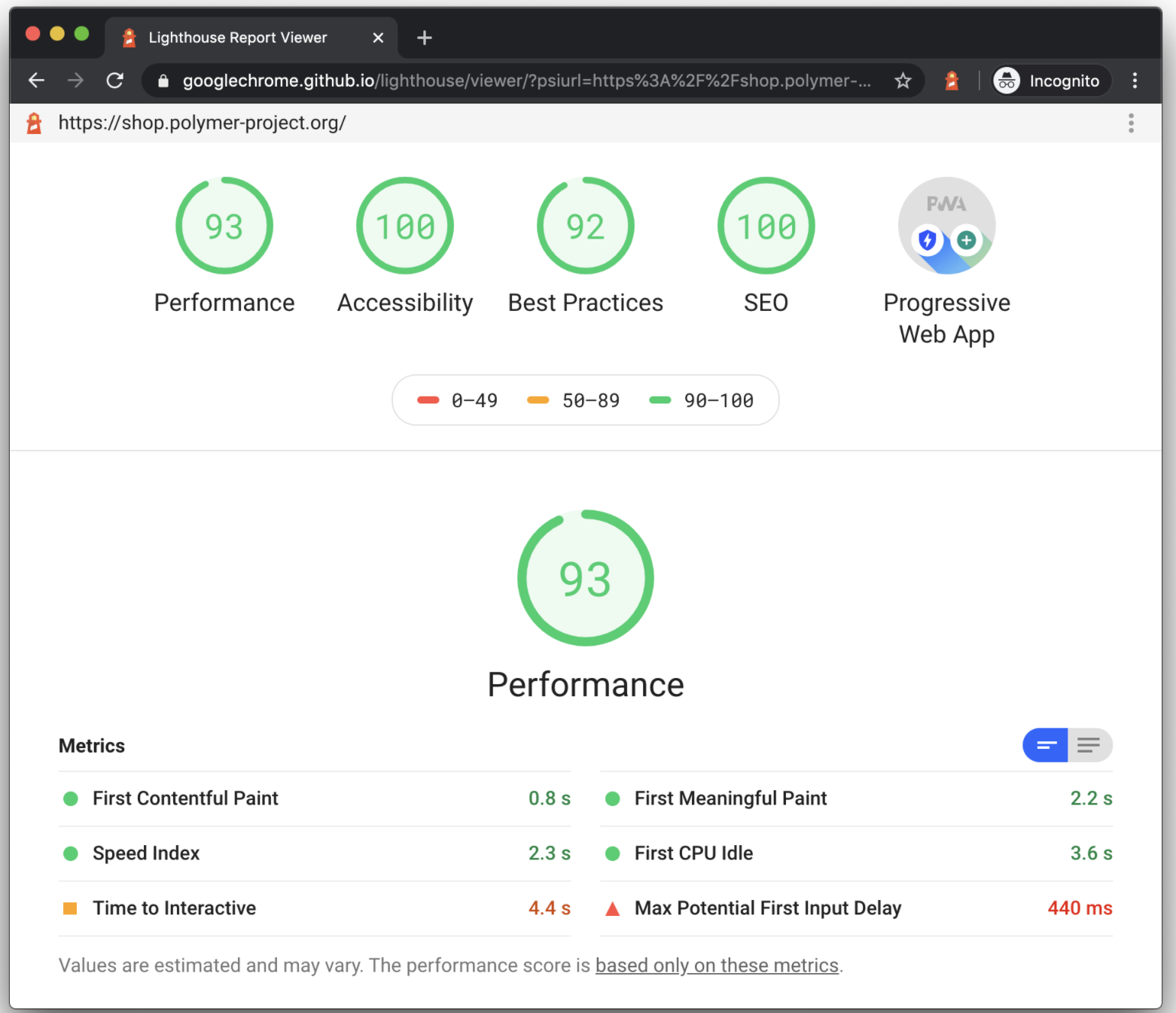
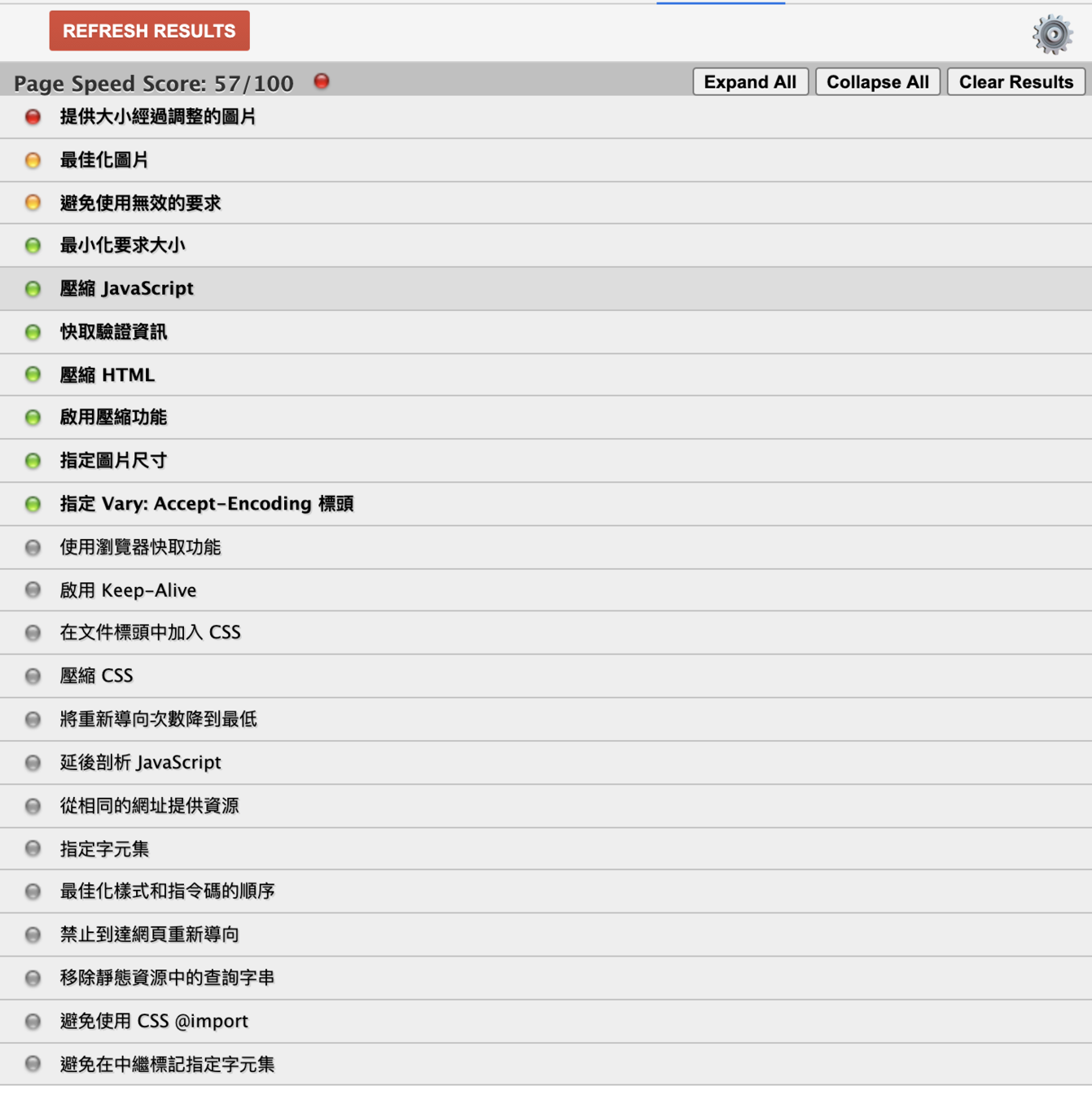
Lighthouse CI Demo
https://github.com/GoogleChrome/lighthouse-ci
Core Web Vitals

https://web.dev/vitals/
https://github.com/GoogleChrome/web-vitals
What is Core Web Vitals ?
Core web vitals 是長期下來根據大量使用者體驗所制定的指標。直到這次的更新為止,Google 已針對使用者體驗設置過多種評分機制,但都未真正的搔到使用者的癢處。而在推出全新的 core web vitals 後 Google 甚至提到,若 75% 以上的使用者在網站中的瀏覽體驗都能夠通過以上 3 種指標,就能夠大幅的提升使用者的搜尋體驗,甚至能夠讓原本因等待而離開的使用者減少 24%!
LCP
Largest Contentful Paint 顯示最大內容元素所需時間 - 載入速度
LCP 是計算網頁可視區 (viewport) 中最大元件的載入時間,也就是頁面的主要內容被使用者看到的時間,是速度的指標。
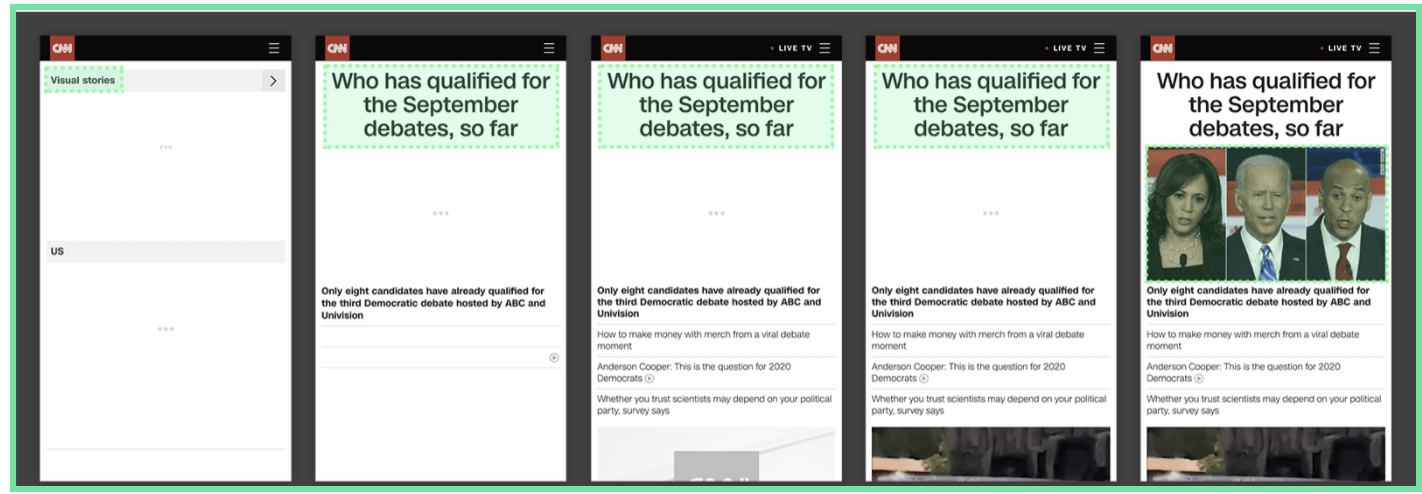
上圖的頁面在載入時一開始可視區的最大元素是左上角的文字,接下來隨著頁面載入變成了標題,最後變成了圖片,因為圖片是可視區最大的元素了,因此 LCP 就會以該圖片所需要載入的時間做計算。
不過可視區內最大的元素並不是固定不變的
如何優化 LCP
減少伺服器回應時間
- 針對主機效能優化
- 使用較近的 CDN
- Cache
- 提早載入第三方(後面會提到)
如何優化 LCP
盡量避免 blocking time
- 降低 JavaScript blocking time
- 降低 CSS blocking time
如何優化 LCP
加快資源載入的時間
- 圖片大小優化
- 預先載入重要資源
- 將文字檔案進行壓縮
- 根據使用者的網路狀態提供不同的內容
- 使用 service worker
如何優化 LCP
避免使用客戶端渲染(CSR)
- 若必須使用 CSR ,建議優化 JavaScript ,避免渲染時使用太多資源
- 盡量在伺服器端完成頁面渲染,讓用戶端取得已渲染好的內容
FID
First Input Delay 首次輸入延遲/封鎖時間總計 (FID) – 可開始互動的時間
輸入延遲 (Input Delay) 通常發生於瀏覽器的主執行序過度繁忙,而導致頁面內容無法正確地與使用者進行互動。舉例來說,可能瀏覽器正在載入一支相當肥大的 JavaScript 檔案,導致其他元素不能被載入而延遲可互動的時間。
如何優化 FID
- 減少 JavaScript 運作的時間
- 降低網站的 request 數並降低檔案大小
- 減少主執行序的工作
- 降低第三方程式碼的影響
CLS
Cumulative Layout Shift 累計版面配置轉移 (CLS) – 頁面穩定性
Minimize Text - Uglify
有時候你會想看看一些網頁的原始碼是怎麼運作的,不過當點選「檢查網頁原始碼」後,顯示出來的 code 有時卻讓你不知道這到底是哪個星球的程式語言,例如檢查臉書原始碼會看到
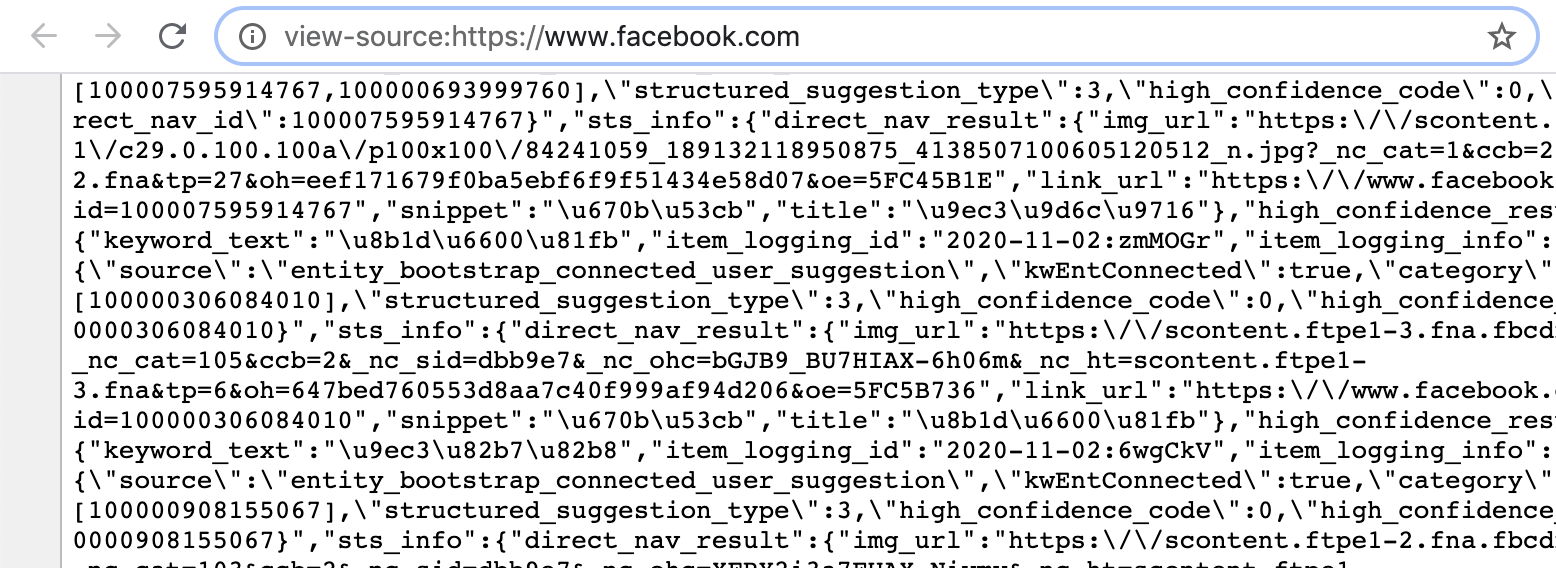
Minimize Text - Uglify
不過其實這些看起來混亂的代碼其實就是我們寫出來的程式,雖然變數名稱跟邏輯似乎都跟我們原本開發時寫的不一樣,但它其實只是經過轉譯罷了。而這麼做主要的原因有兩個:
- 變數跟 code 寫的越短,或是刪除不必要的空白,可以省掉不少瀏覽器 Parse 的時間,也就是提升前端程式的效能 — Minimize
- 通常會打亂程式的邏輯,避免自家產品的 code 輕鬆的被別人拿去研究或抄襲 — Uglify
如果要試試看效果,可以參考如 JavaScript Minifier 或 Uglify JS 等網頁服務,但通常在開發時我們不會笨拙的手動貼 code 去 Minimize 或 Uglify,而是會利用如 webpack 、gulp 等打包工具替我們做這些事情。
Minimize Image
現今的網站免不了會需要載入大量的圖片,圖片也因此成為網站載入資源的很大一部分,換句話說就是對網站效能有著直接的影響。在考慮 Image Lazy Load 等技巧以前,我們可以先將圖片壓縮,透過減少檔案大小來加快載入時間,而壓縮又分為兩種狀況:
- 有損壓縮:如 JPG,使用只取部分像素資料的方式來壓縮圖片大小,並且壓縮後是不可逆的。
- 無損壓縮:如 PNG,壓縮後不影響圖片品質。
三種圖片類型各自比較有名的圖片壓縮服務有 tiny-png、svgomg、jpeg-optimizer。
Minimize Image
而其實不同的圖片類型也有各自適合使用的時機,學會將不同類型圖片應用在適合的地方不僅可以提升使用者體驗或 UI 品質,某些狀況下也可以控制載入資源的大小而提升一點效能。這裡推薦一篇文章,說明得十分完整,除了有介紹各種圖片類型的適當使用時機外,也有介紹如響應式圖片、webp、Image CDN 等其他技巧,非常值得一讀。
Critical Render Path 關鍵渲染路徑
提到網頁前端的效能最佳化,我們得先了解網頁是如何渲染到頁面上的,從收到 HTML、CSS 和 JavaScript,再對程式碼進行必需的處理,到最後轉變為顯示像素的過程中還有許多中間步驟。將效能最佳化其實就是瞭解這些步驟中所有的活動,再經過最佳化,這就是所謂的關鍵渲染路徑 Critical Render Path 。
Critical Render Path 關鍵渲染路徑
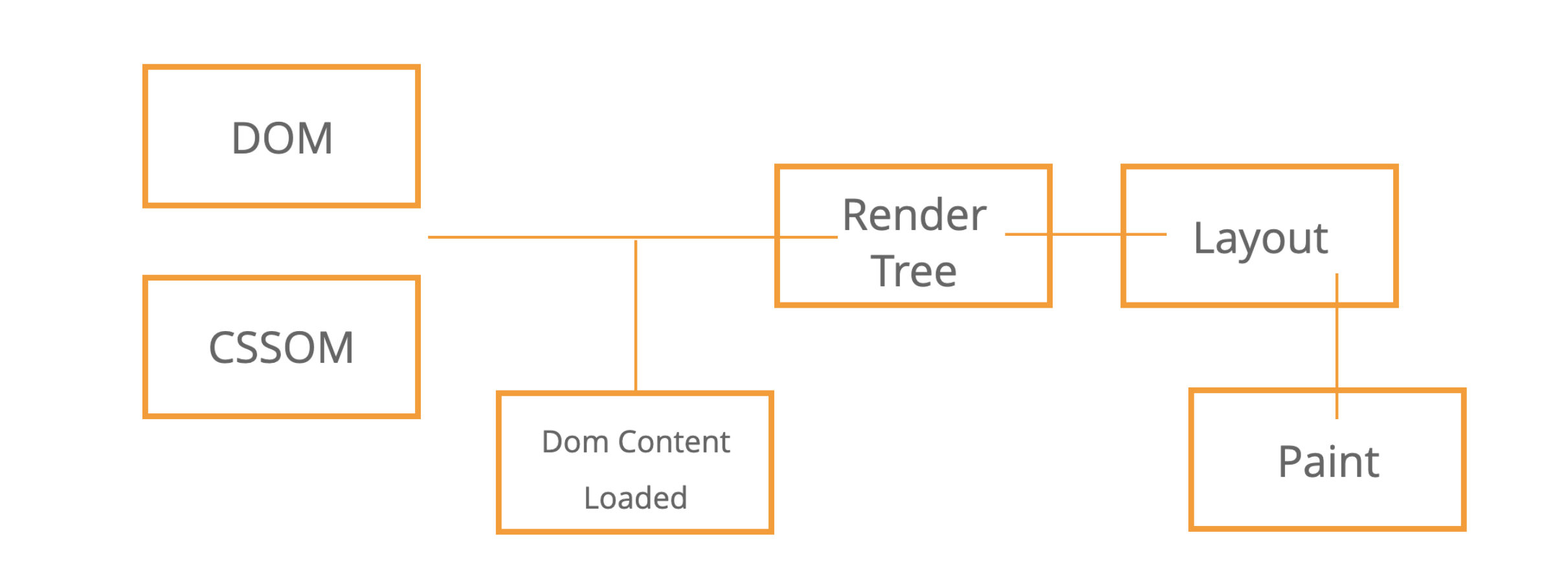
- 讀取 HTML 後生成 DOM Tree
- 讀取 HTML 中的 CSS Link Tag 生成 CSSOM Tree
- DOM Tree 與 CSSOM Tree 共同生成 Render Tree
- 根據 Render Tree 生成 Layout
- 最後 Paint 畫面
Critical Render Path 關鍵渲染路徑
當然,現今的 web app 不太可能只靠 HTML 跟 CSS 就完成,還是得靠 JavaScript 來修改網頁的內容、樣式、與使用者互動的行為。JavaScript 可以查詢及修改 DOM 和 CSSOM,在 CSSOM 執行完畢後,JavaScript 才會執行 。這邊給一個小 tip:如果可以的話,CSS file 盡快引入,JS 在 CSS 後引入,因為 JS的執行會導致網頁載入的暫停(不過有例外的非同步功能,很快就會講到了)。
Critical Render Path 關鍵渲染路徑
一般我們要載入 JavaScript 檔案,通常會透過 <script> 這個 Tag 來達成,不過它的執行是同步的,也就是會導致網頁載入的暫停,如下圖:

Critical Render Path 關鍵渲染路徑
但其實 script tag 的引入還有 async 跟 defer 這兩種方式:
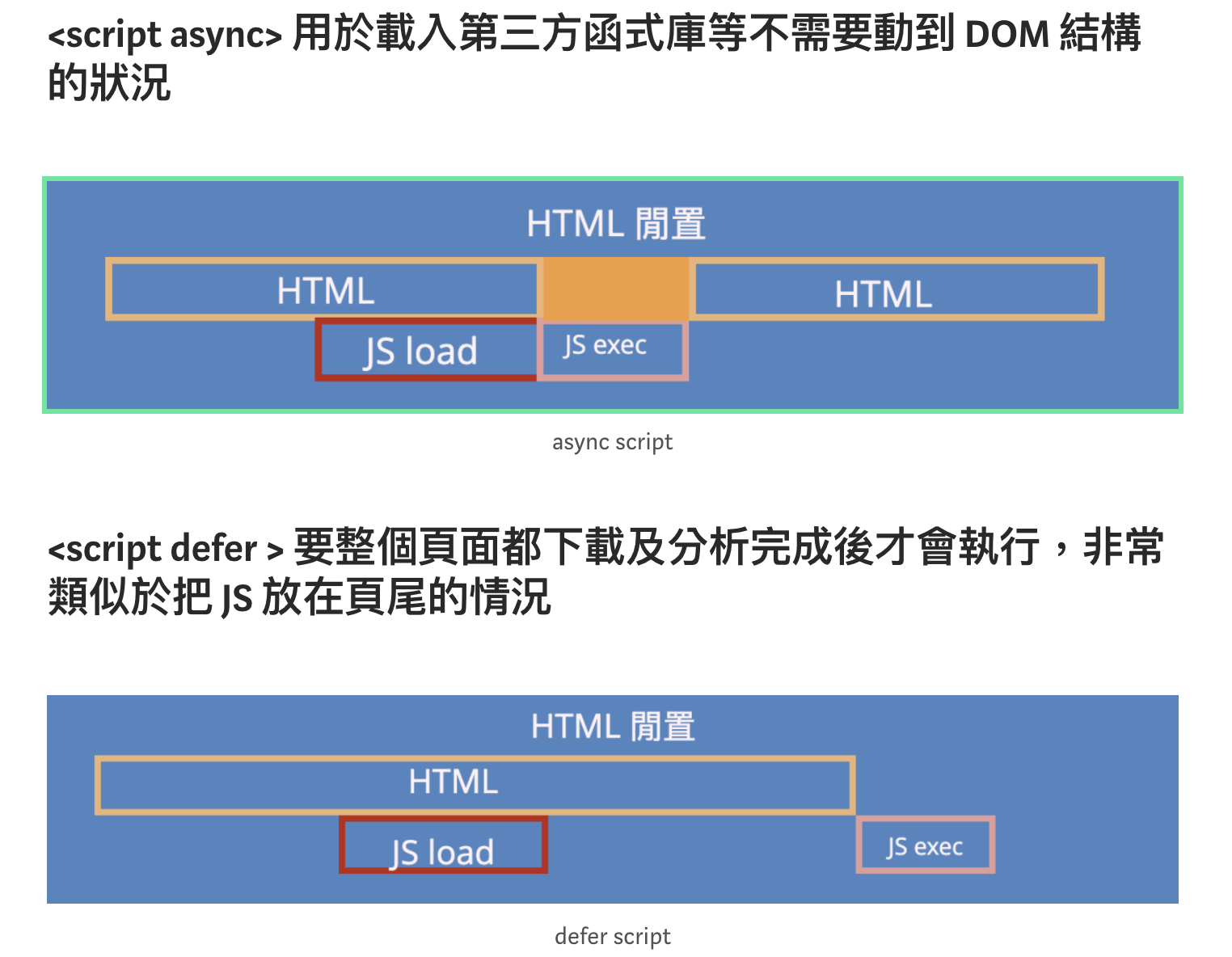
Other Skills
Code Splitting
現代網頁會透過打包工具產生 JS bundle,但當專案變大,bundle 如果過肥大會影響使用者的載入速度,code splitting 解決單一 JS 肥大的問題,將單一 JS 拆成許多小 Chunks,可搭配平行載入,或有需要時才載入,甚至各自可以被快取。
今天將介紹兩種 code splitting 技巧:
1. 抽離第三方套件
2. 動態載入功能模組 Dynamic Import
Webpack Bundle Analyzer
Text
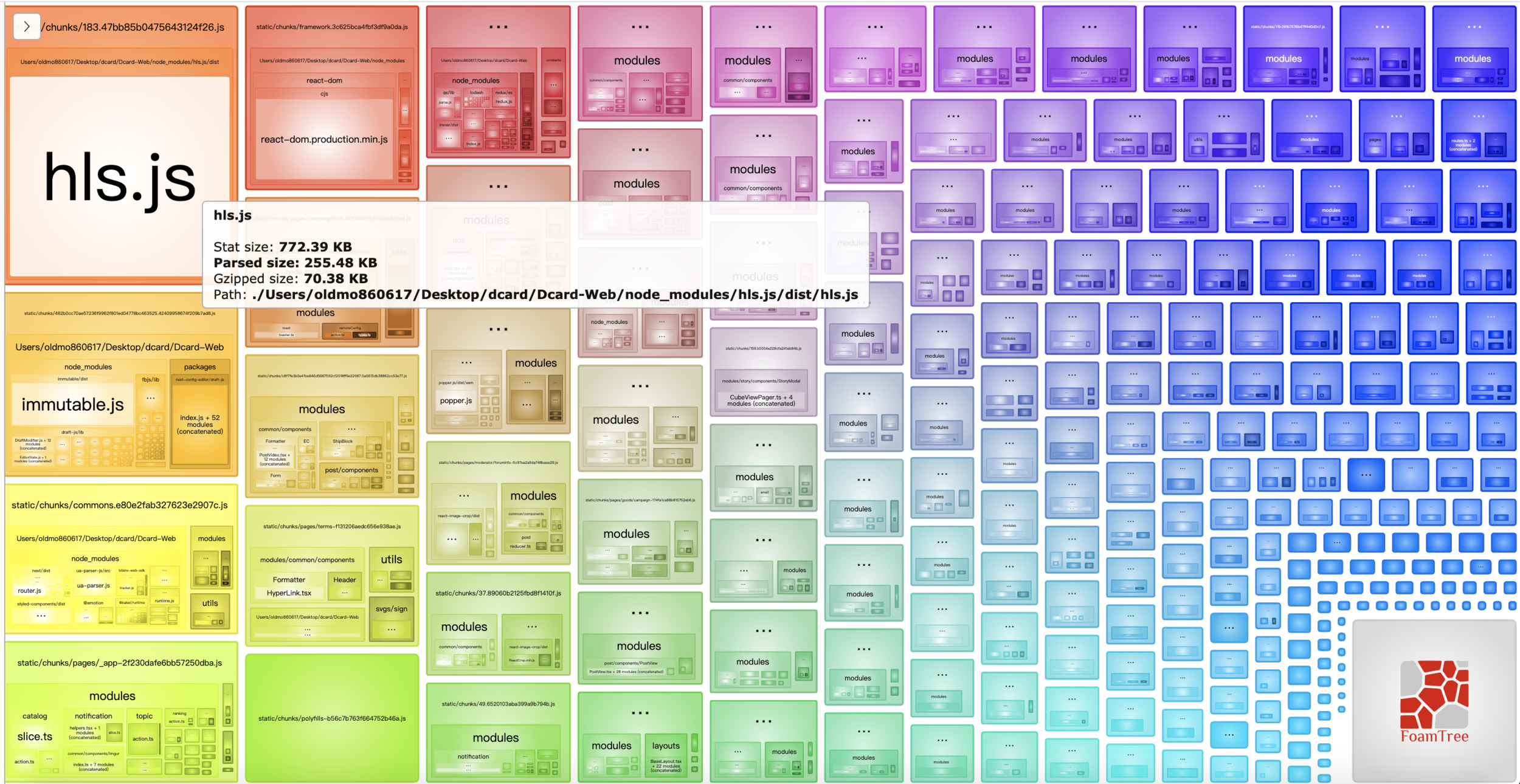
抽離第三方套件
又可以細分為兩個方法:
1. 將所有第三方套件打包為單一檔案
2. 將第三方套件打包為多個檔案
將所有第三方套件打包為單一檔案
分析 Vendor Bundle
Webpack runtime and manifest: 負責模組之間互動,一般可忽略(體積很小)
Application Bundle: UI/data login,基本上就是你寫的 code
Vendor bundle: 第三方套件 / node_modules,不太變動
Vendor bundle 因為變動不頻繁,可被快取,加快再訪載入速度,因此 node_modules 基本上都該被移到這裏。
分析 Vendor Bundle

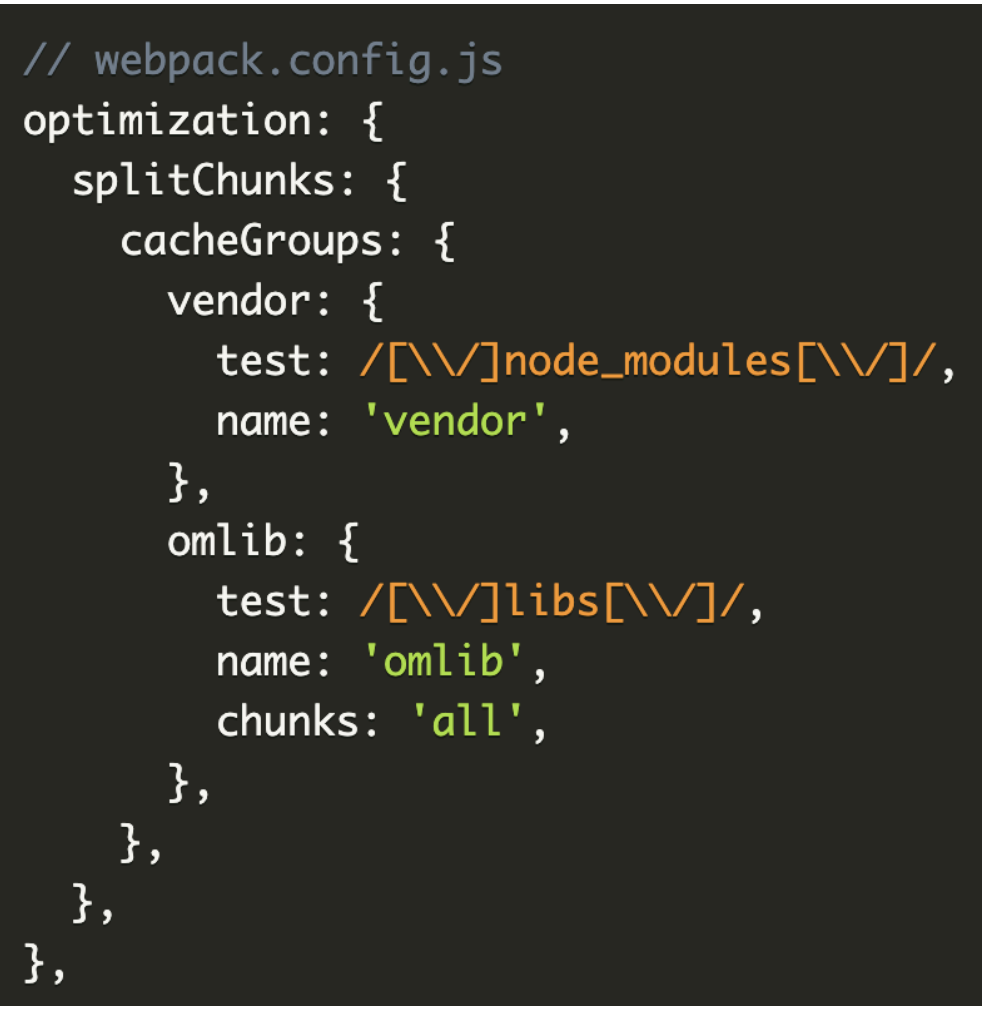
減少 application bundle 的⼤⼩,加快再訪者載入速度
效果
- 優點:邏輯簡單明瞭。
- 缺點:更新任何第三方套件都會使快取失效。
- 優點:可以根據套件關聯性打包,減少套件更新時造成的延遲。
- 缺點:需要人工處理相關邏輯。
將第三方套件打包為多個檔案
const plugins = [
title: 'React',
}),
new WebpackVisualizerPlugin(),
new webpack.NamedModulesPlugin(),
new webpack.optimize.CommonsChunkPlugin({
names: [
'ramda',
'react',
'redux',
'router',
],
minChunks: Infinity,
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
minChunks: Infinity,
}),
];
if (DEBUG) {
module.exports = {
entry: {
app,
ramda: 'ramda',
react: ['react', 'react-dom', 'styled-components'],
redux: ['react-redux', 'redux'],
router: ['history', 'react-router', 'react-router-dom', 'react-router-redux'],
},
output: {
filename: 'js/[name].bundle.js',
filename: 'js/[name].[chunkhash].bundle.js',
path: path.resolve(__dirname, 'dist'),
},需要⽤到某段程式碼的時候才透過網路下載 JS bundle
Dynamic Import
Dynamic Import
Webpack ⽀援 ESM import() 語法實現 dynamic import
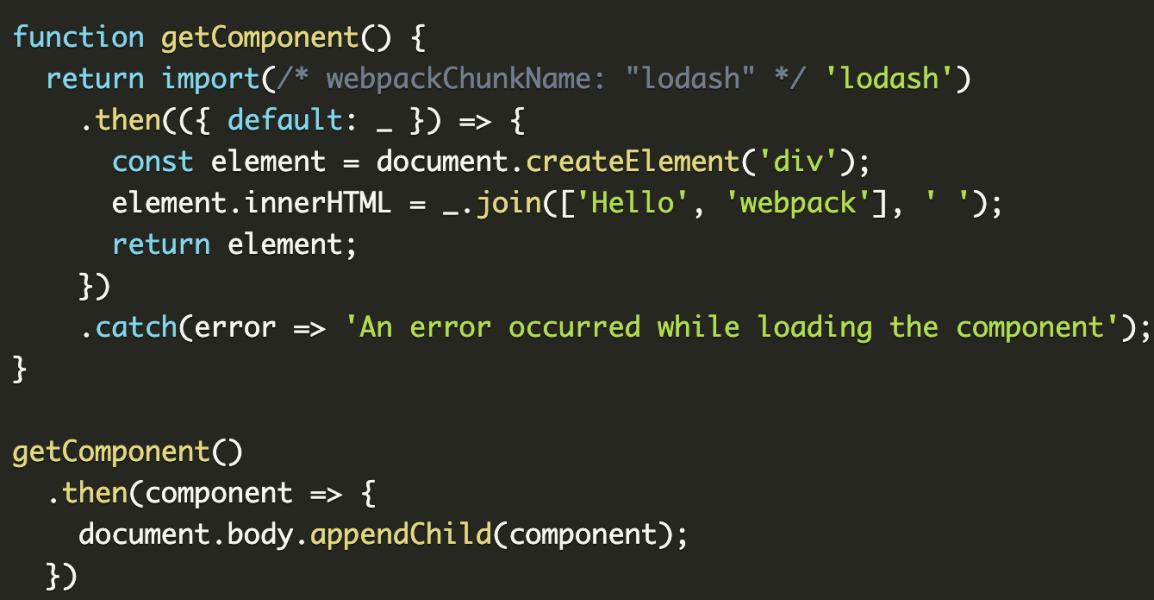

function getComponent() {
return import('lodash').then(({ default: _ }) => {
const element = document.createElement('div');
element.innerHTML = _.join(['Hello', 'webpack'], ' ');
return element;
}).catch(error => 'An error occurred while loading the component');
}
getComponent().then(component => {
document.body.appendChild(component);
})Dynamic Import
- 根據路徑做 Dynamic Import
- 針對肥大套件做 Dynamic Import
根據路徑做 Dynamic Import
透過 GA 等追蹤工具顯示大多數使用者只會停留在熱門頁面 -> 代表其他不常被觀看的頁面載入的資源浪費了流量
React-router 支援 dynamic import,另外 Server-Side-Rendering 更是不用擔心這件事
根據肥大套件做 Dynamic Import
還記得前幾頁的 webpack bundle analyzer 嗎?
你是不是過胖了?
Tree Shaking
專案初期也許你引入的套件都有用到,但當專案規模擴大,有些舊的套件早就被淘汰,但仍舊被放在專案的一角,雖然沒被用到仍被 bundle 進去,佔用了空間,阻礙效能。

Tree Shaking

把用不到的 code 搖下來
Tree Shaking
For application bundle
Use ES6 import/export
// Import all the array utilities!
import arrayUtils from "array-utils";// Import only some of the utilities!
import { unique, implode, explode } from "array-utils";不過 build 的話還是整個 module 會被 import,因此需要救星來幫忙....Webpack
Tree Shaking
請參考:
https://webpack.js.org/guides/tree-shaking/
https://developers.google.com/web/fundamentals/performance/optimizing-javascript/tree-shaking

Resource Prefetch
<link rel="prefetch" href="/style.css" as="style" />
<link rel="preload" href="/style.css" as="style" />
<link rel="preconnect" href="https://example.com" />
<link rel="dns-prefetch" href="https://example.com" />
<link rel="prerender" href="https://example.com/about.html" />There’re lots of ways to improve web performance . One of those ways is to preload content you’ll need later in advance. Prefetch a CSS file, prerender a full page, or resolve a domain ahead of time – and you won’t have to wait for it when it’s actually needed!
Preload vs Prefetch
兩者都是在提早取得...
Preload:當前頁面的資源。(常見如 font)
Prefetch:未來會用到的資源 (跨 navigation)
Resource Prefetch
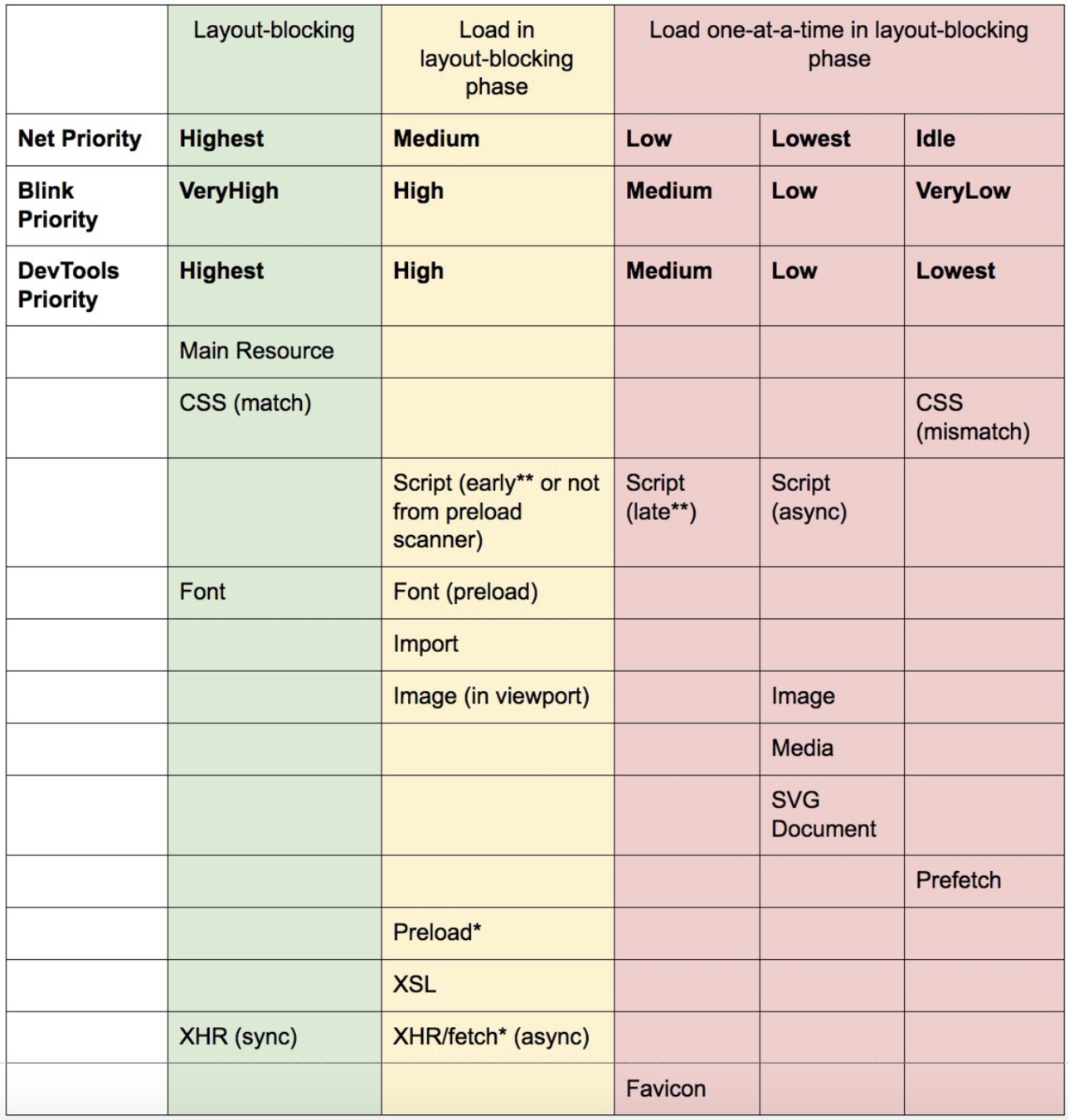
瀏覽器對資源的載入是有優先順序的,以檔案類型決定下載的優先順序。
style /font / XHR (sync) > 位於可視區域的圖片 / Preload without as/ XHR (async) > favicon、script async / defer / block、不在可視區域的圖片、媒體檔、SVG 等
Preload 以 as 屬性分辨檔案類型,而 Prefetch 以 type 屬性分辨檔案類型。
<link rel=preload as=image href="sprite.symbol.svg">使用 Preload 前
使用 Preload 後


Preconnect
告訴瀏覽器:「這個網頁將會在不久的將來下載某個 domain 的資源,請先幫我建立好連線。」
<link rel="preconnect" href="https://example.com">在這之前,得了解瀏覽器在實際傳輸資源前,有哪些步驟要做
- 向DNS請求解析域名
- TCP Handshake
- (HTTPS連線) SSL Negotiation
- 連線建立完成,等待拿到資料的第一個byte

上頁中四個步驟,每一步都會需要一個 RTT (Round Trip Time) 的來回時間。
所以在實際傳輸資料之前,已經花了3個RTT的時間。
如果是在 latency 很高的情況下(例如手機網路),會大大拖慢取得資源的速度。
利用 preconnect 提早建立好與特定 domain 之間的連線,省去了一次完整的 (DNS Lookup + TCP Handshake + SSL Negotiation) ,共三個 RTT 的時間。
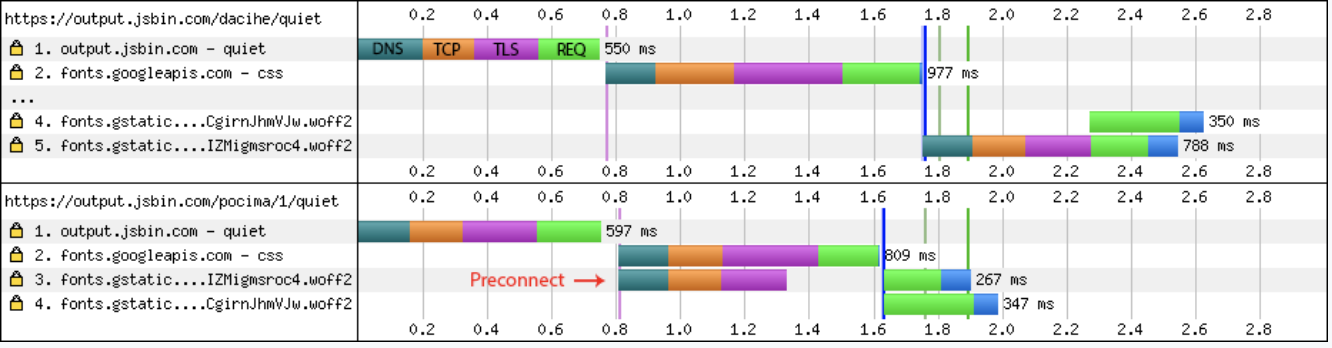
某網站引用了 Google Fonts 的 CSS 檔,而 CSS 檔又引用到另外兩個字形檔。
無 preconnect
-
和 font.googleapis.com 建立連線
-
下載 CSS
-
和 fonts.gstatic.com 建立連線
- 下載字體 (over HTTP/2 multiplexing)
preconnect
- 和 font.googleapis.com 與 fonts.gstatic.com 建立連線
- 下載 CSS
- 下載字體 (over HTTP/2 multiplexing)
(省去了一次完整的 (DNS Lookup + TCP Handshake + SSL Negotiation) ,共三個 RTT 的時間。)
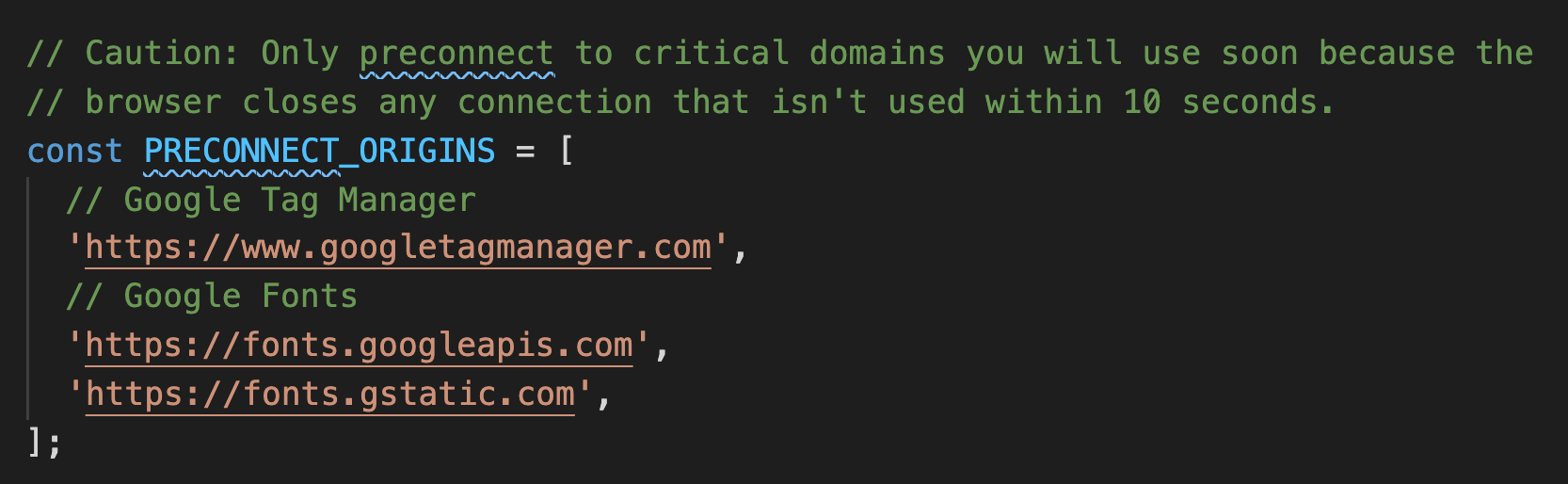
Use Cases
1. CDN :
如果你有很多資源要從某個CDN去拿,你可以提示 preconnect CDN的域名。
特別是你不太能預先知道有哪些資源要下載的情況,只需要給定域名這點滿方便的。
2. Streaming (待會看例子)
DNS Preconnect
跟 preconnect 類似,差別在於只提示瀏覽器預先處理 DNS lookup 而已。
Prerender
prerender 比 prefetch更進一步。不僅僅會下載對應的資源,還會對資源進行解析。解析過程中,如果需要其他的資源,可能會直接下載這些資源。這樣,用戶在從當前頁面跳轉到目標頁面時,瀏覽器可以更快的響應。
<link rel="prerender" href="//example.com/next-page.html">Example
Lazy Load
import React, { lazy, Suspense } from 'react';
const AvatarComponent = lazy(() => import('./AvatarComponent'));
const renderLoader = () => <p>Loading</p>;
const DetailsComponent = () => (
<Suspense fallback={renderLoader()}>
<AvatarComponent />
</Suspense>
)SSR ? loadable-component
Lazy Load Image
Lazy Load Image
自己實作:搭配 Intersection Observer web API
瀏覽器原生支援:<img loading='lazy'>
CDN Cache
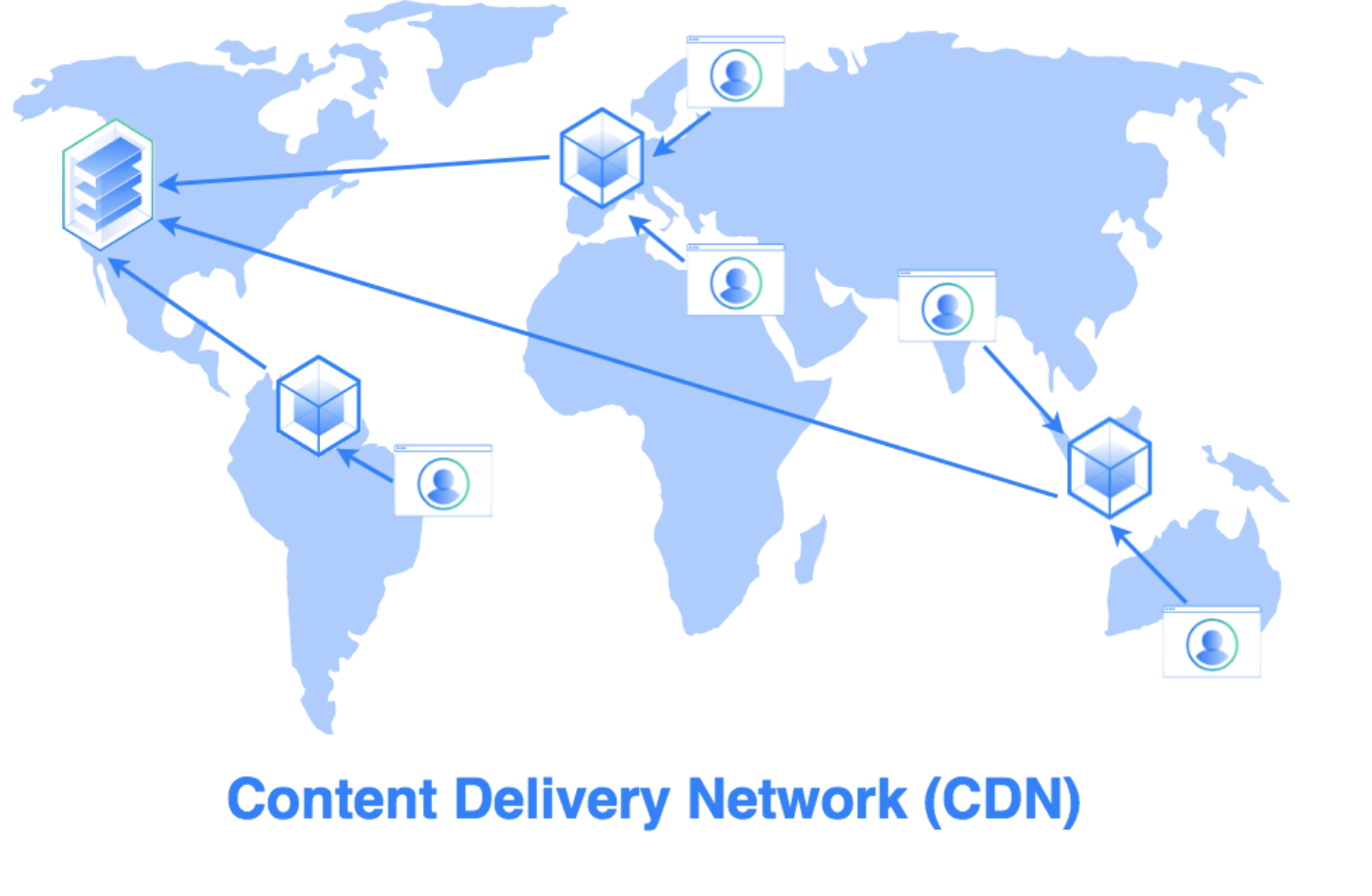
CDN Cache
- 阻擋惡意流量
- 代管 DNS
- CDN
- Cache
PWA Service Worker Cache
寫好程式很重要
- 減少 rerender 次數
- Event Listener 是否移除
- 注意時間複雜度、空間複雜度
- Design Pattern