Death by flat analysis
an undelicate and hopefully thoughtful story about hard procrastination while looking for a flat for rent
Hi, this is me
!
I'm looking for a flat
?!
But there's too many
?!
Could it be easier?
I'm a big data dude
I want to find *nice* flats with data pipeline magic, so...
- Create a beefy distributed computation cluster
- Crawl through several hundred places
- Aggregate, refine, crunch, munch, knaw...
- Make a jolly shiny and glittering dashboard where I can find a
damncozy flat - ???
- Profit?
BUT, and maybe some big BUTS
There are some potential issues:
- Creating a cluster requires some $$$
- Maybe it's ilegal (site usage terms, GDPR, etc)
- Implementing this stuff takes some time
- Haven't you heard me? It takes some serious time
- It's not for profit, and maybe, it's *FUN*

"flatnalyzing"
There are different sources to extract the same information, but each has its ups and downs.
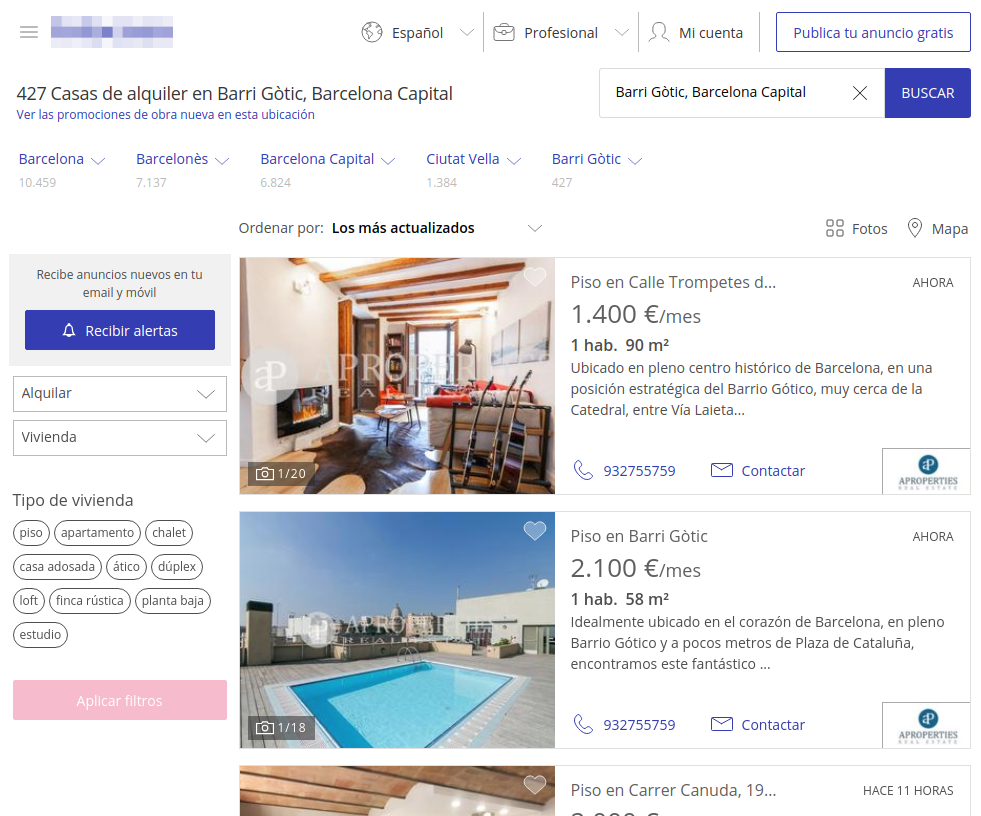
"flatsite"
"flatpoint"
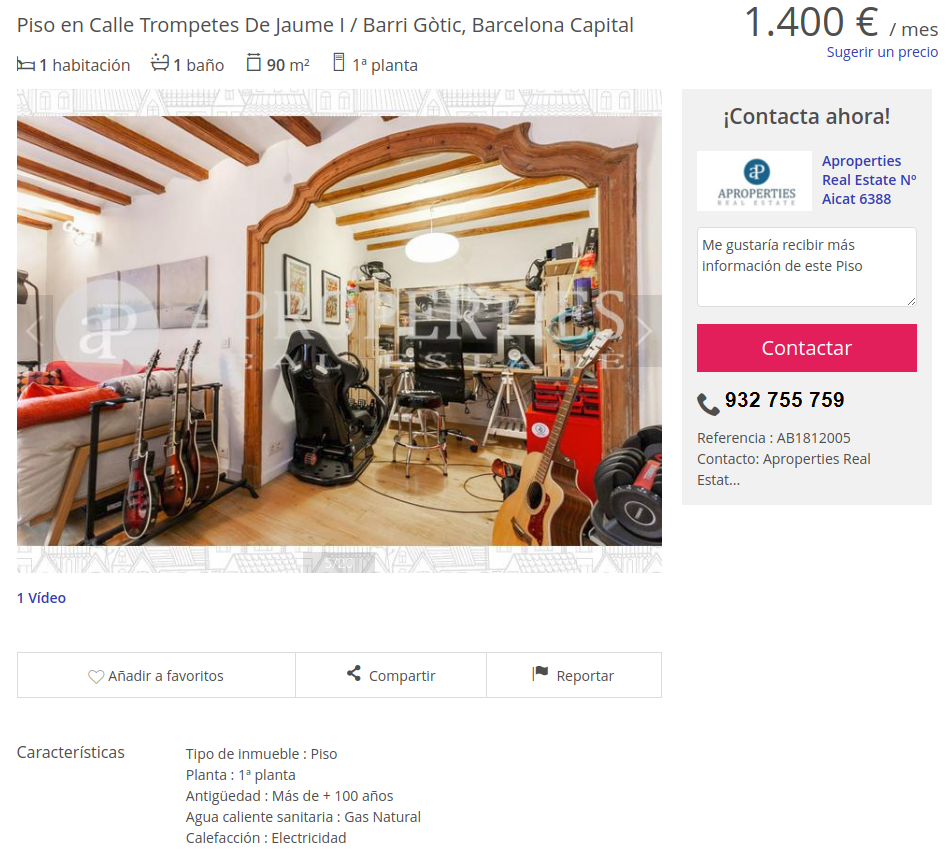
a website containing information about a flat
a website containing a list of flats to buy or rent
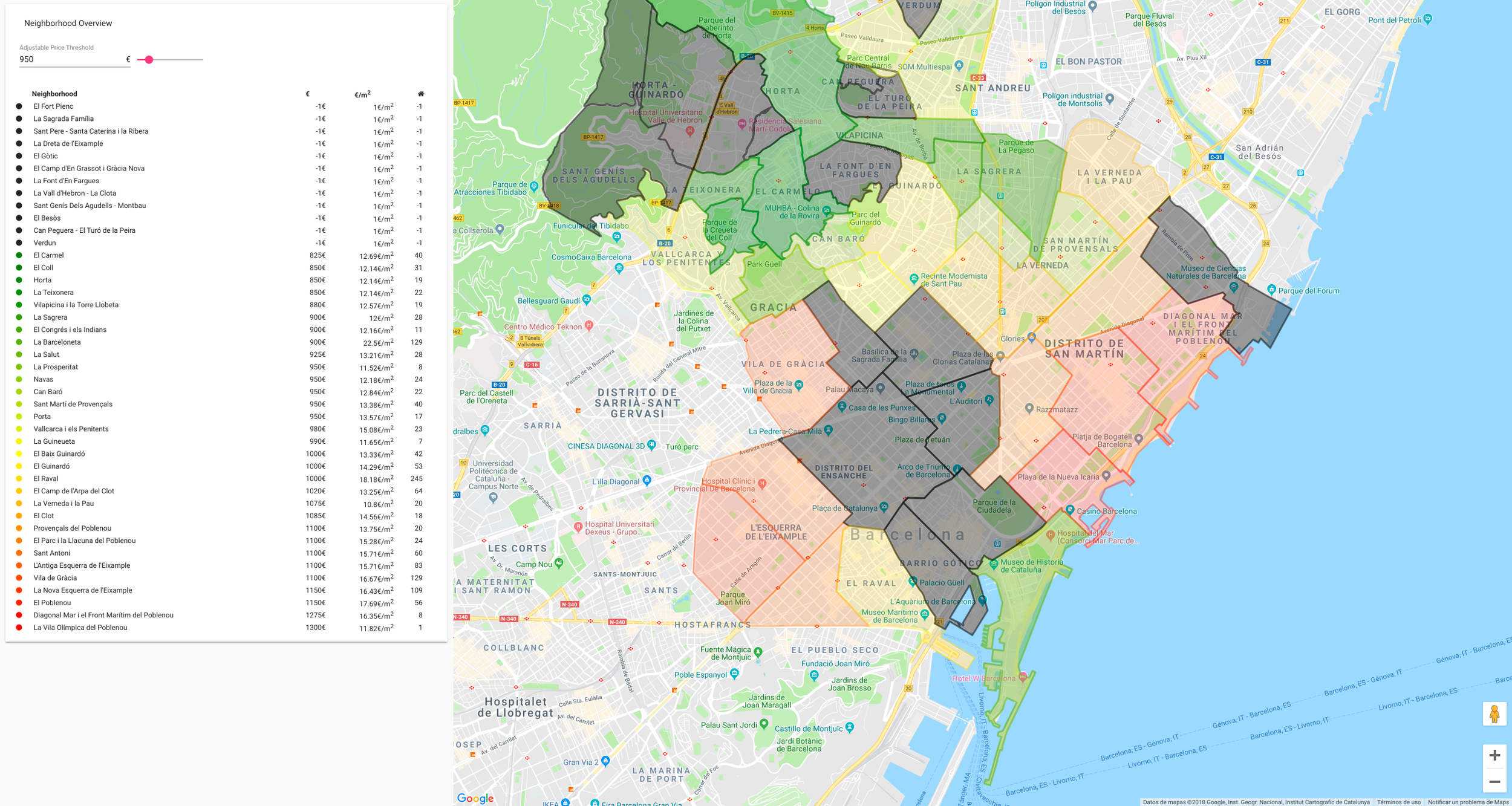
flatsite (feature rich)
Price
geolocation
Rooms
Surface
parseable
data
flatpoint (feature poor)
Price
geolocation
Rooms
Surface
crawling data seems not easy
Separating what to crawl allows:
- To focus more in which content you require and not fetching unnecessary information.
- You don't need ALL data.
- You need redundancy, and not relying on a single source of data.
- Distribute the computation and make it more scalable on the long run
crawling data is hard
Web sites protect themselves against intensive crawling
Tor seems an alternative to anonymize oneselve, but it's usually actively banned by website providers.

"headless chrome" might be a feasible alternative to programatic APIs to simulate a browser.
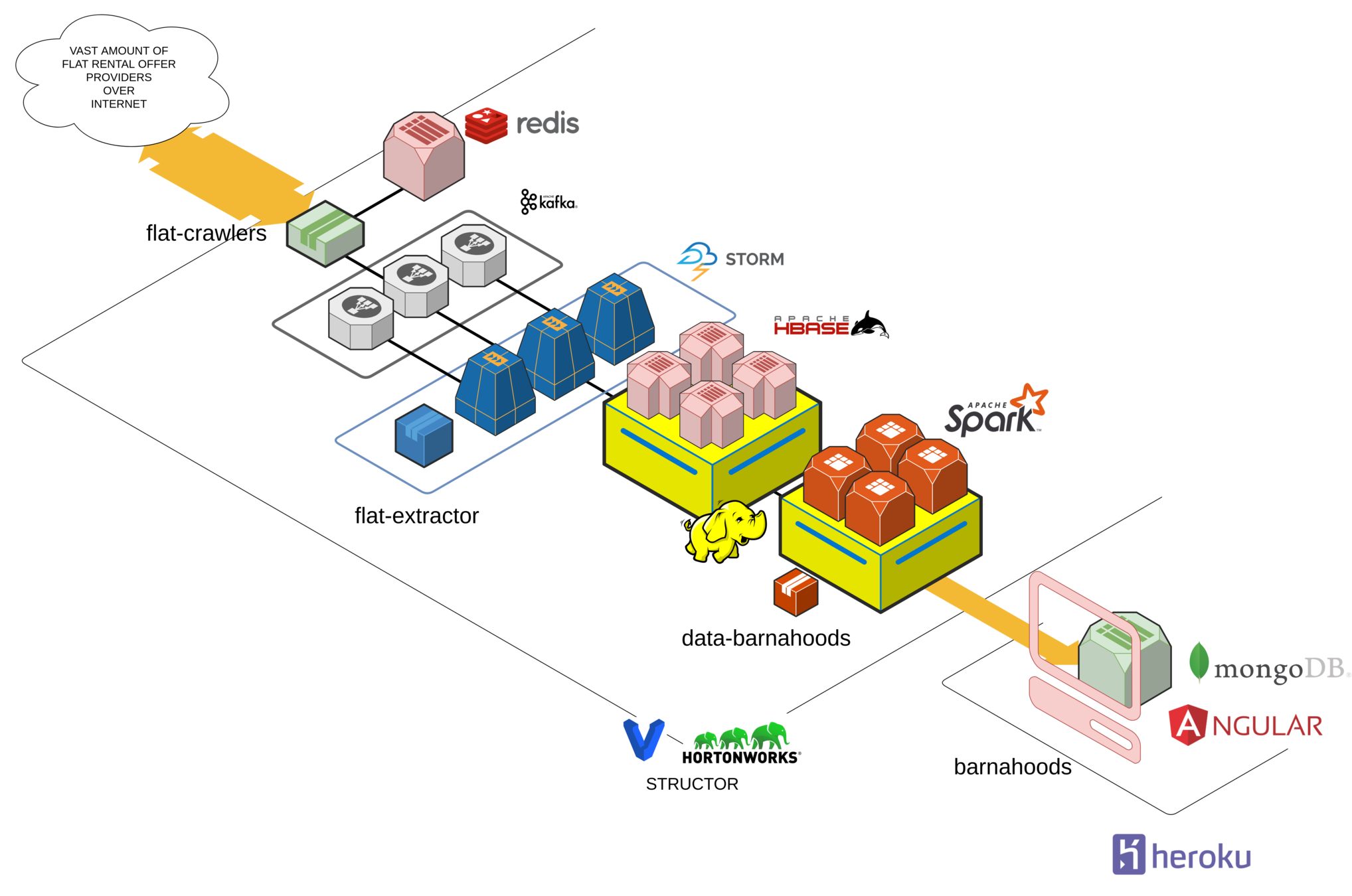
the cluster (v1)
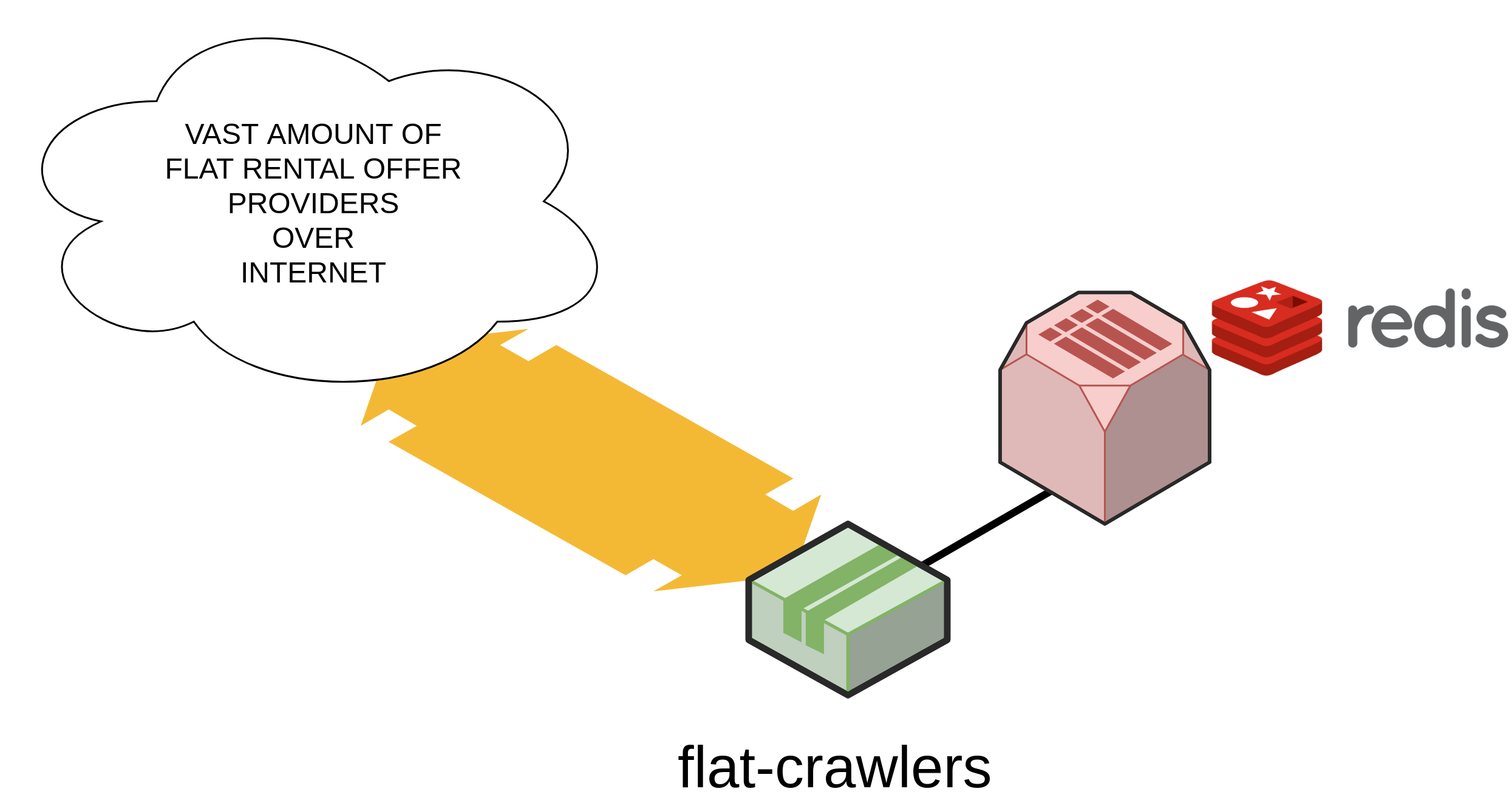
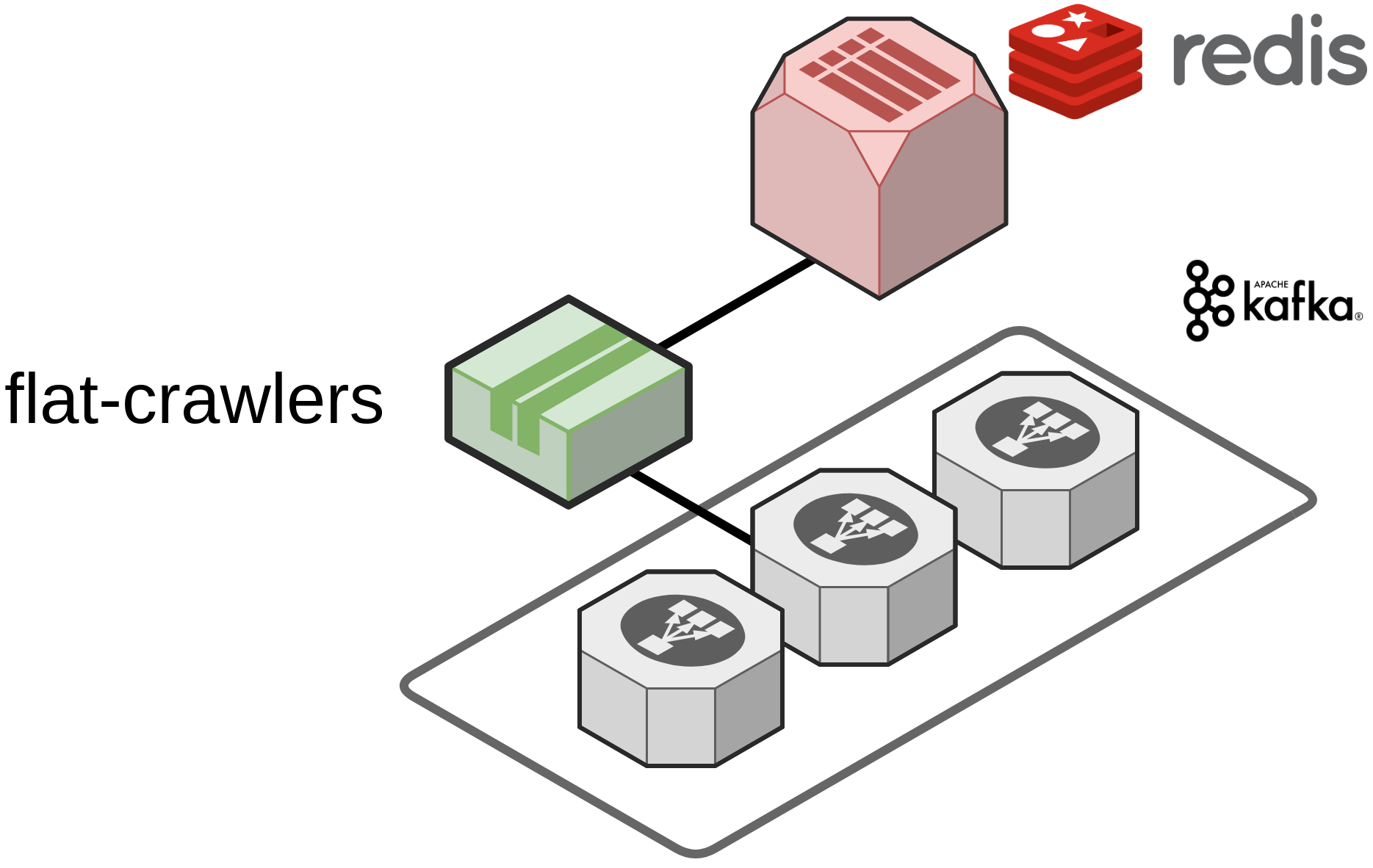
It all begins with someone sending data over the wire...
Redis stores visited flatpoints and flatsites
the cluster (v1)
then this raw data is sent to a hardened, back-pressured, *distributed* temporal storage...
the cluster (v1)
and wait for data being consumed by a Storm topology that will perform the feature extraction from raw data...
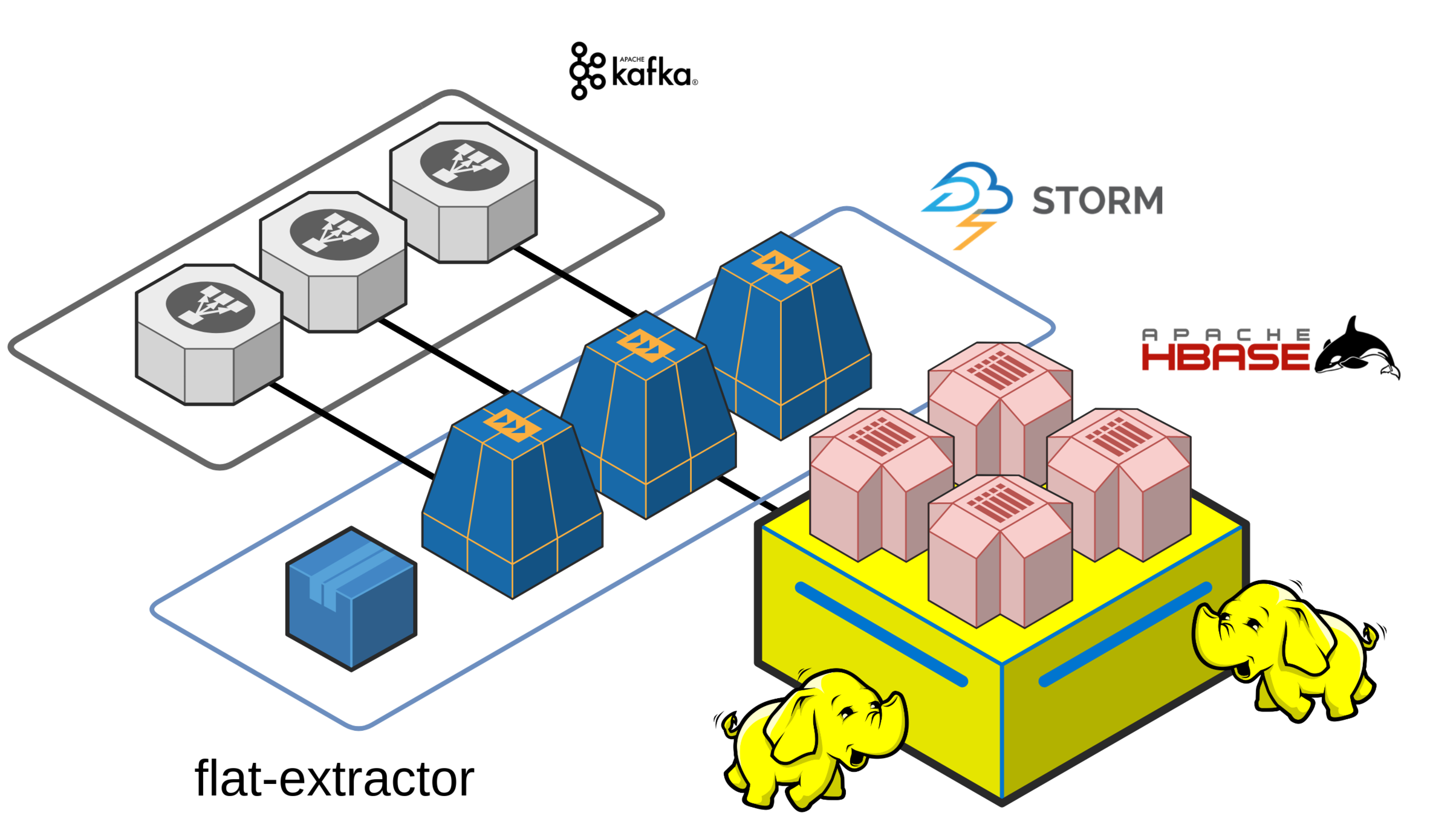
the cluster (v1)
to be heavily munched by a Spark job that will aggregate all data by different dimensions and criterias...
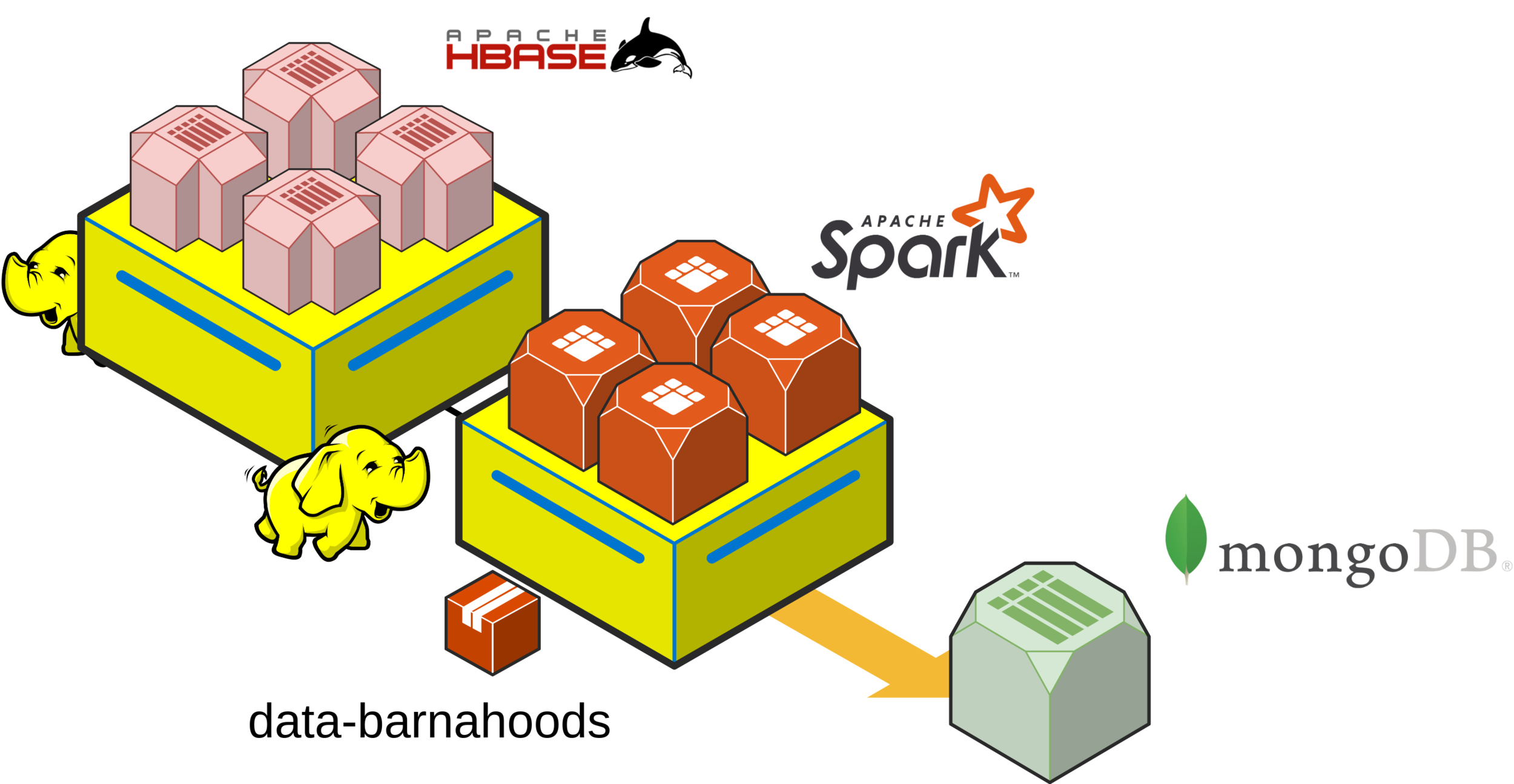
the cluster (v1)
to finally visualize it in a nice Angular-based SPA,
backed by a MongoDB

the cluster (v1)
All of this backed by a single physical machine, some Vagrant-powered VMs with Structor
the cluster (v2)
After some catastrophic failure due to disk space outage, I have to rethink the whole architecture
- Spark jobs ended up taking too much time, due to the HBase connector being used.
- HBase is not easy to manage, and analyze its content, as I require an Apache Zeppelin to interact with it.
- Storm spends a lot of CPU time. A LOT.
- VirtualBox VMs add a significant overhead on contention.
- Structor forces me to use HDP and Puppet. It constraints me and adds time when adding other services.
the cluster (v2)
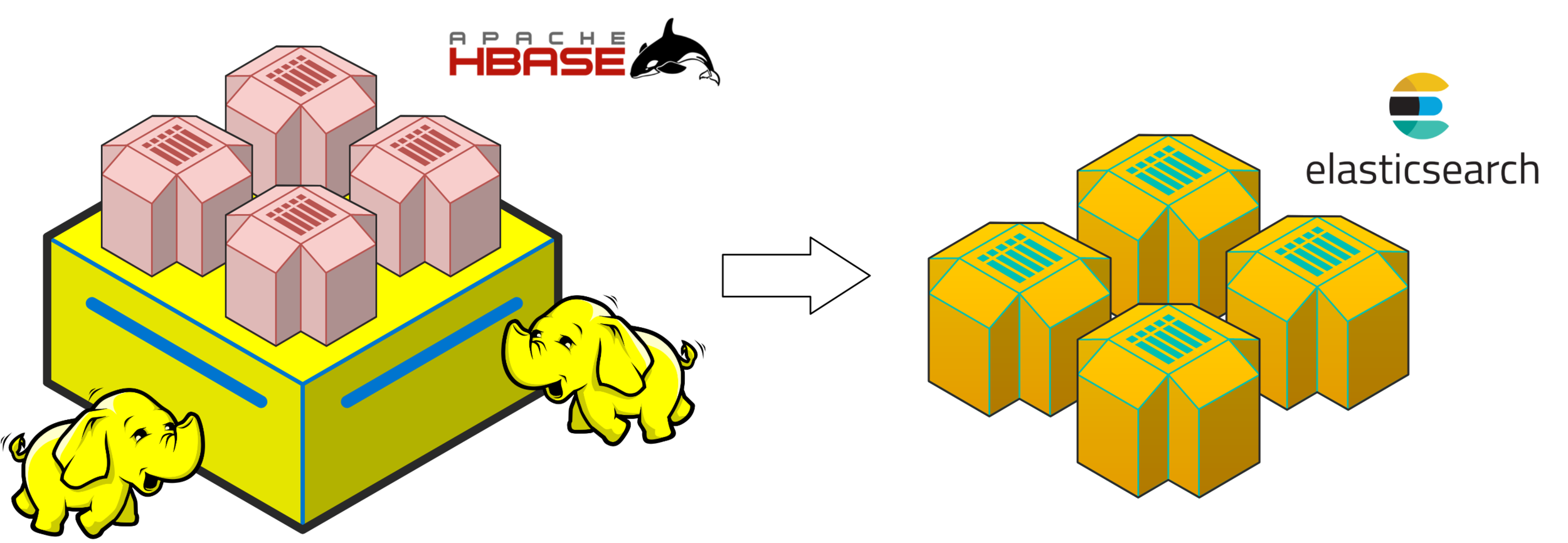
Change HBase to Elasticsearch
the cluster (v2)
Change Storm to Flink

the cluster (v2)
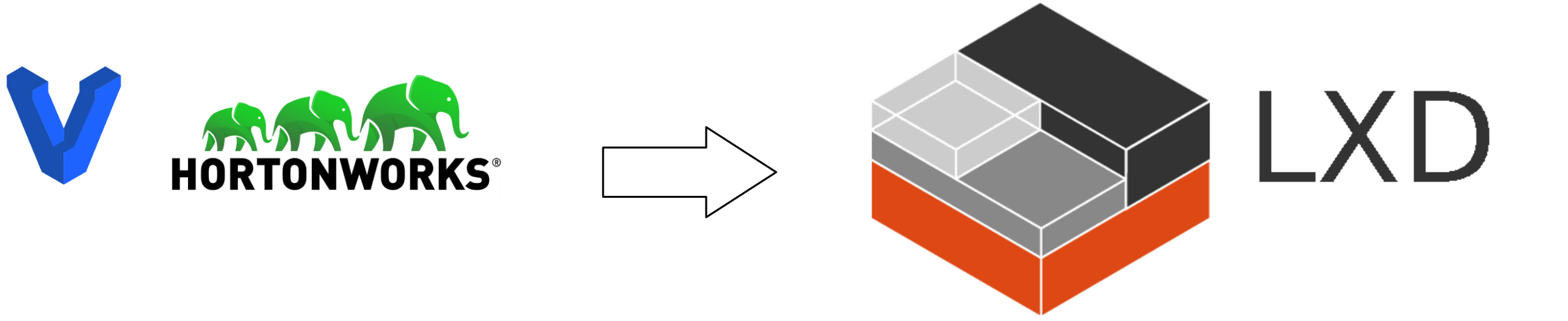
Change Structor to Construct
DEMO