Sistemas Inteligentes
Unidad de competencia III. Algoritmos de aprendizaje
Ing. Oscar Alonso Rosete Beas
Semana 26 Abril Rev:1 ciclo 2021-1
oscarrosete.com

oscarrosete.com

Agenda
3.1. Aprendizaje supervisado y no supervisado
3.2. Algoritmo “Backpropagation through time”
3.3. Aprendizaje en tiempo real
3.4. Algoritmo K-Means
3.4. Redes Neuronales
Unidad de competencia III. Algoritmos de aprendizaje
oscarrosete.com
Unidad 2
oscarrosete.com


oscarrosete.com
oscarrosete.com
Agenda
3.1. Aprendizaje supervisado y no supervisado
3.2. Algoritmo “Backpropagation through time”
3.3. Aprendizaje en tiempo real
3.4. Algoritmo K-Means
3.4. Redes Neuronales
Unidad de competencia III. Algoritmos de aprendizaje
oscarrosete.com
oscarrosete.com
Repaso metodologías IA
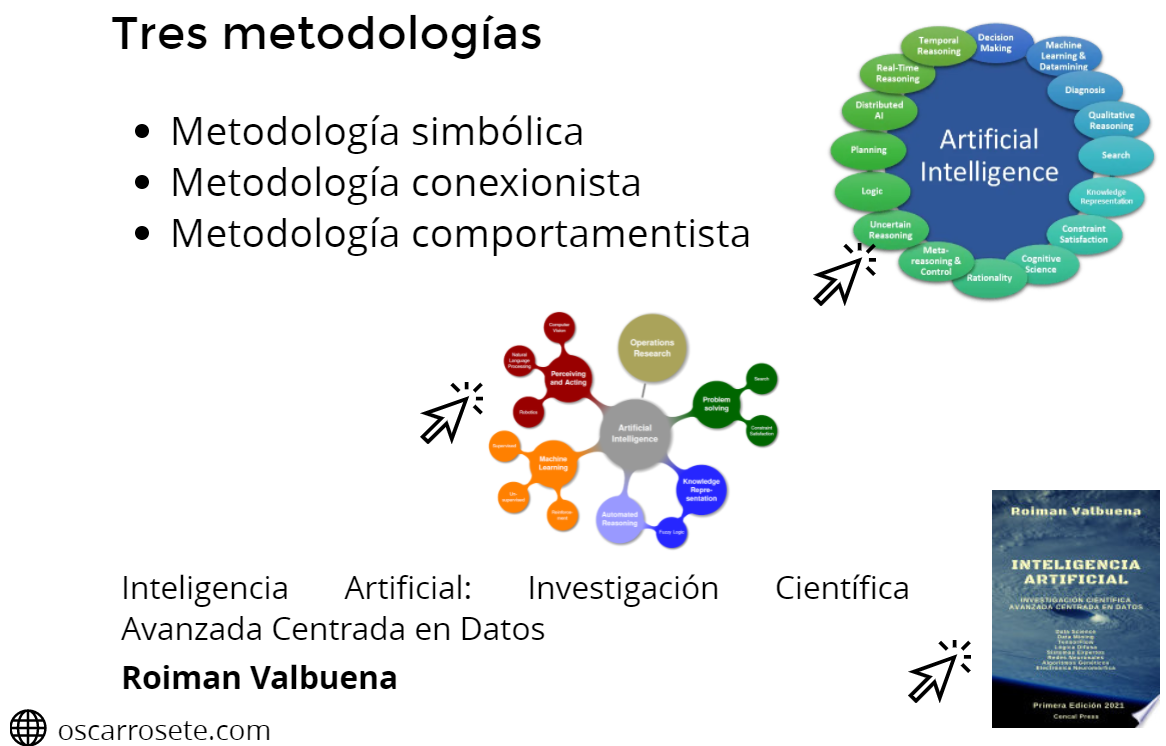
oscarrosete.com
oscarrosete.com
Repaso Agentes Inteligentes

oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Es la ciencia de enseñar a las computadoras a hacer predicciones basadas en datos.
En un nivel básico, el aprendizaje automático implica dar a una computadora un conjunto de datos y pedirle que haga una predicción.
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Al principio, la computadora tendrá muchas predicciones incorrectas. Sin embargo en el transcurso de miles de predicciones, la computadora actualizará su algoritmo para hacer mejores predicciones.
Este tipo de computación predictiva solía ser imposible. Las computadoras simplemente no podían almacenar suficientes datos o procesarlos lo suficientemente rápido como para aprender de manera efectiva.
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
En la siguiente figura se muestran tres subconjuntos del aprendizaje automático que pueden utilizarse:
Aprendizaje supervisado, no supervisado y de refuerzo
Aprendizaje automático

oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Imaginemos que hay que organizar 10,000 fotografías y los algoritmos tienen que identificar las fotos en las que aparece un gato.
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Los algoritmos usan datos que ya han sido etiquetados u organizados previamente para indicar como tendría que ser categorizada la nueva información. Con este método, se requiere la intervención humana para proporcionar retroalimentación.
Enseñaríamos previamente al algoritmo fotos donde apareciera un gato para que luego pudiera identificar imágenes similares.
Aprendizaje supervisado
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Los algoritmos no usan ningún dato etiquetado u organizado previamente para indicar como tendría que ser categorizada la nueva información, sino que tienen que encontrar la manera de clasificarlas ellos mismos.
Este método no requiere la intervención humana.
En el ejemplo, los algoritmos tendrían que clasificar ellos mismos todas las fotos en las que apareciera un gato en una categoría.
Aprendizaje no supervisado
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Supervised vs Unsupervised Learning
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Los algoritmos que aprenden de la experiencia.
En otras palabras, tenemos que darles un refuerzo positivo cada vez que aciertan.
La forma en que estos algoritmos aprenden se puede comparar con la de los perros cuando les damos recompensas al aprender a sentarse, por ejemplo.
Aprendizaje por refuerzo (reinforcement learning)
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Aprendizaje por refuerzo (reinforcement learning)
oscarrosete.com
oscarrosete.com
Inteligencia Artificial
Una de las aplicaciones más poderosas y de mayor crecimiento de la inteligencia artificial es el aprendizaje profundo.
Se trata de un subcampo del aprendizaje automático que se utiliza para resolver problemas muy complejos y que normalmente implican grandes cantidades de datos. el aprendizaje profundo se produce mediante el uso de redes neuronales organizadas en capas para reconocer relaciones y patrones complejos en los datos.
Aprendizaje profundo (Deep learning)
oscarrosete.com
oscarrosete.com
En una extensión no menor a dos cuartillas con sus respectivas referencias deberá investigar y desarrollar los siguientes temas:
-
Diferencia entre una tarea de clasificación y una de regresión lineal.
-
Gradiente Descendiente para aprendizaje automático (Gradient Descent)
-
Perceptron
-
Algoritmo “Backpropagation through time
Aprendizaje automático
Trabajo de investigación


oscarrosete.com
oscarrosete.com
Agenda
3.1. Aprendizaje supervisado y no supervisado
3.2. Algoritmo “Backpropagation through time”
3.3. Aprendizaje en tiempo real
3.4. Algoritmo K-Means
3.4. Redes Neuronales
Unidad de competencia III. Algoritmos de aprendizaje
oscarrosete.com
oscarrosete.com
Supongamos que estamos en la búsqueda de un apartamento
Hablamos con amigos, familiares y hacemos una búsqueda en línea por apartamentos en Mexicali y detectamos que los apartamentos en diferentes zonas tiene precios distintos.
Aprendizaje automático

oscarrosete.com
oscarrosete.com
- Un departamento de una cama céntrico cuesta 5000 al mes
- Departamento de dos camas céntrico 7,000
- Departamento de una cama con cochera cuesta 6,000
- Departamento de una cama orillas de la ciudad 3,000
- Departamento con 2 camas orillas de la ciudad 4,500
- Departamento de 1 cama orillas de la ciudad con cochera 4,800
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Empezamos a notar patrones:
- Los apartamentos céntricos son usualmente mas costosos y tienen un costo entre 5,000 y 7,000.
- Los de las afueras mas baratos
- Incrementar el numero de habitaciones agrega entre 1,500 y 2,000 al mes
- La cochera agrega entre 800 y 1000
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Este ejemplo muestra como utilizamos la información para encontrar patrones y tomar decisiones.
Si encuentras un departamento de 2 habitaciones céntrico con cochera, sería razonable asumir que el precio sería aproximadamente de 8,000 al mes.
Aprendizaje automático
oscarrosete.com
oscarrosete.com
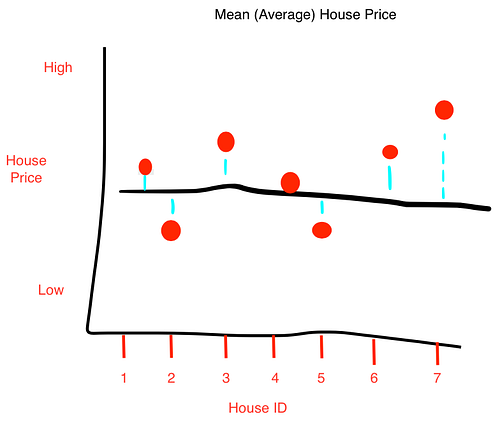
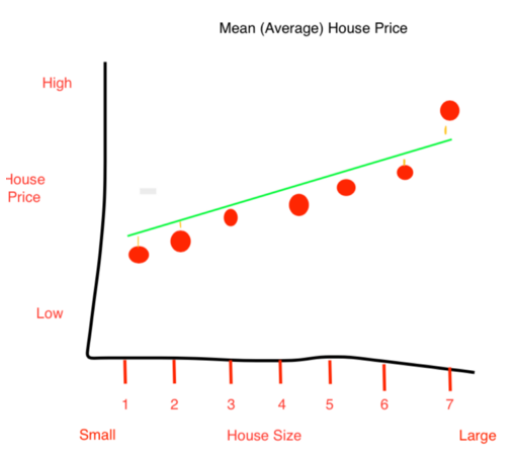
La figura muestra la relación entre distintos atributos de la información.
Los puntos se encuentran mas cercanos al centro de la ciudad y hay un patrón claro de relación con el precio, así como un decremento gradual al incrementar la distancia.
Aprendizaje automático

oscarrosete.com
oscarrosete.com
Tipícamente la información esta representada en tablas. Las columnas son referidas como los atributos de la información, los renglones como los ejemplos. Al comparar dos atributos, el atributo medido puede ser representado como y y el atributo cambiante como x.
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Aprendizaje de maquina es útil cuando tenemos información y cuestiones a investigar que la información podría resolver.
Diferentes categorías de algoritmos resuelven diferentes preguntas.
Aprendizaje automático
oscarrosete.com
oscarrosete.com
Aprendizaje automático

oscarrosete.com
oscarrosete.com
Una de las técnicas mas comunes es el aprendizaje supervisado. Al visualizar la información queremos comprender las relaciones y patrones en la información para predecir los resultados.
En el ejemplo de búsqueda de apartamentos podría utilizarse, así como al utilizar autocompletado en aplicaciones o al recibir preferencias musicales.
Aprendizaje supervisado
oscarrosete.com
oscarrosete.com
Aprendizaje automático tiene dos subcategorías, regresión y clasificación.
Regresión involucra trazar una linea para separar un conjunto de datos que sea acorde a la forma de la información.
Puede utilizarse para detectar tendencias entre iniciativas de marketing y ventas.
Aprendizaje supervisado
oscarrosete.com
oscarrosete.com
Clasificación busca predecir categorías de ejemplos basados en sus atributos.
Podemos determinar si es un carro o un camión basándonos en su cantidad de llantas, peso y velocidad máxima.
Aprendizaje supervisado
oscarrosete.com
oscarrosete.com
No se trata solamente de algoritmos. Realmente, en múltiples ocasiones se trata del contexto de la información, la preparación de la información y las preguntas que se están realizando.
Machine learning workflow
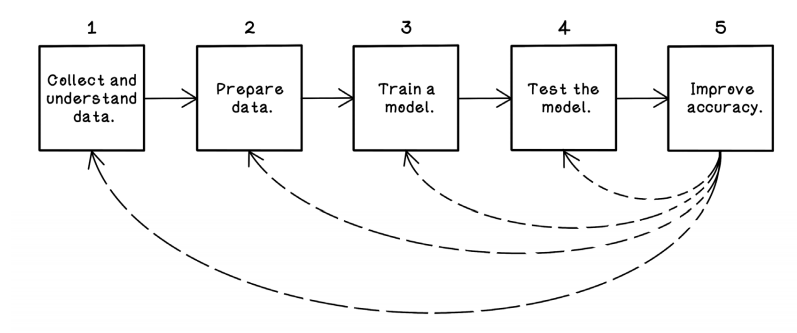
oscarrosete.com
oscarrosete.com
Para el exito del aprendizaje automatico es clave recolectar y entender la informacion.
Supongamos trabajaremos con análisis de diamantes
Machine learning workflow

oscarrosete.com
oscarrosete.com
La tabla describe múltiples diamantes y sus propiedades. X, Y, Z describen el tamaño del diamante en 3 dimensiones espaciales.
Machine learning workflow

oscarrosete.com
oscarrosete.com
El conjunto de datos consiste de 10 columnas, referidas como atributos y 50,000 renglones.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Preparación de datos
puede haber datos faltantes, inconsistencia, formatos difíciles de trabajar etc.
Machine learning workflow

oscarrosete.com
oscarrosete.com
Entrenar modelo
Como un paso preliminar debemos de asegurarnos de tener información suficiente para entrenar el modelo, así como información para probar que tan bien se están haciendo las predicciones con nuevos ejemplos.
Después de tener un entendimiento de como los atributos de los departamentos afectan el precio, podíamos hacer predicciones.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Información para entrenar, probar y validar
La validación cruzada o cross-validation es una técnica utilizada para evaluar los resultados de un análisis estadístico y garantizar que son independientes de la partición entre datos de entrenamiento y prueba.
Overfitting, Underfitting, Good fit
Machine learning workflow

oscarrosete.com
oscarrosete.com
Información para entrenar, probar y validar
La validación cruzada o cross-validation es una técnica utilizada para evaluar los resultados de un análisis estadístico y garantizar que son independientes de la partición entre datos de entrenamiento y prueba.
Sobreajuste, infrajuste
Machine learning workflow
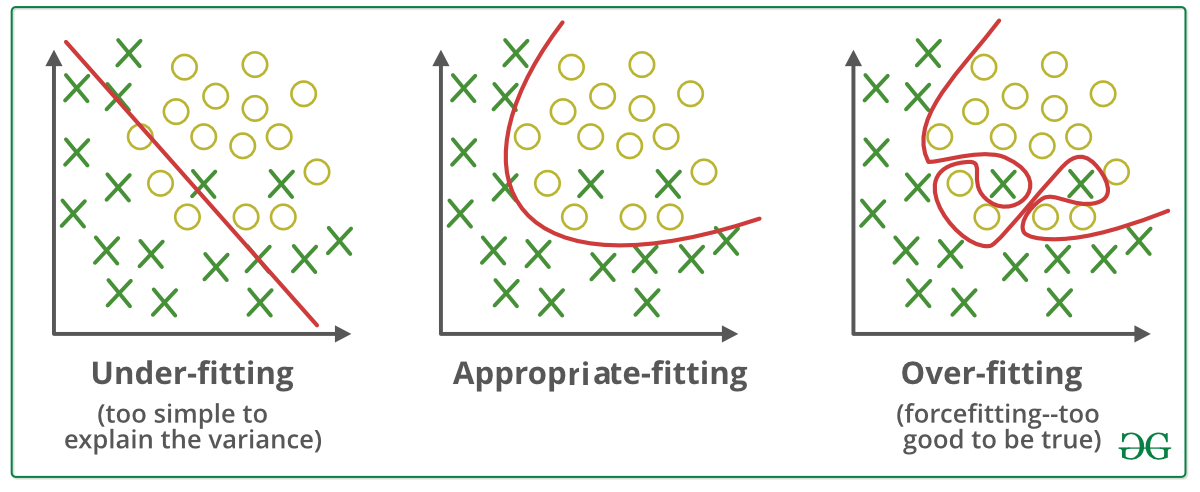
oscarrosete.com
oscarrosete.com
Entrenar modelo
La selección del algoritmo a utilizar se ve influenciada por múltiples factores entre los cuales se encuentra la pregunta de investigación y la naturaleza de la información disponible.
Si la pregunta tiene que ver con predicciones del precio de un diamante basado en el peso en quilates, los algoritmos de regresión pueden ser útiles.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Regresión
Significa predecir un valor continuo, tal como el precio de un diamante.
Al decir continuo nos referimos a que el valor predecido puede ser cualquier numero en un rango definido.
El precio de 2,271, por ejemplo, es un valor continuo entre 0 y el máximo valor que la regresión puede predecir.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Regresión lineal
La regresión lineal es uno de los algoritmos de aprendizaje más simples, nos ayuda a encontrar la relación entre dos variables y nos permite predecir una variable con relación a otra.
Por ejemplo el precio del diamante considerando cantidad de quilates.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Regresión lineal
Empecemos buscando encontrar una tendencia en la información para realizar predicciones.
Para explorar la regresión lineal, la pregunta de investigación sera:
¿Existe correlación entre los quilates de un diamante y su precio?, y en caso de existir, ¿podemos realizar predicciones precisas?
Machine learning workflow
oscarrosete.com
oscarrosete.com
Regresión lineal
Empezaremos por aislar los atributos de quilates y el precio y graficarlos.
Utilizaremos quilates como x y el precio como y
Machine learning workflow

oscarrosete.com
oscarrosete.com
Regresión lineal
El peso en quilates es una variable independiente (x). La variable independiente es la que cambia en un experimento para determinar el efecto en la variable dependiente (precio).
Machine learning workflow

oscarrosete.com
oscarrosete.com
Machine learning workflow
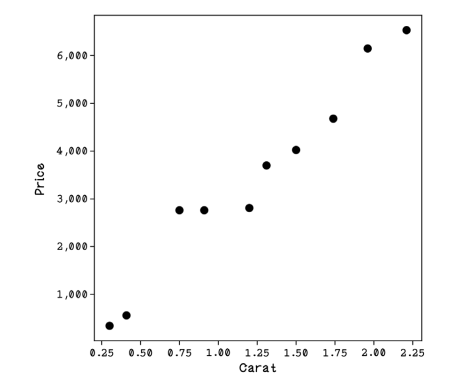
oscarrosete.com
oscarrosete.com
Regresión lineal
Debemos notar el peso en quilates son valores pequeños(decimales de gramo) comparados con el precio(miles). Se recomienda multiplicar por 1000 para que sean mas fáciles los cálculos.
Machine learning workflow

oscarrosete.com
oscarrosete.com
Machine learning workflow

oscarrosete.com
oscarrosete.com
Regresión lineal
Al escalar los renglones, no afectamos la relación en la información ya que se ha realizado la misma operación sobre cada ejemplo.
Machine learning workflow

oscarrosete.com
oscarrosete.com
Encontrar la media de los atributos
Para determinar la linea de regresión es necesario obtener la media de cada atributo.
La media es la suma de todos los valores dividida entre el numero de valores.1,229 para peso en quilates(linea vertical) y $3,431 para el precio(linea horizontal).
Machine learning workflow

oscarrosete.com
oscarrosete.com
Encontrar la media de los atributos
La media es importante porque matemáticamente cualquier linea de regresión deberá pasar a través de la intersección de la media en x y la media en y. Múltiples lineas pueden pasar por ese punto, algunas serán mejores para ajustarse a la información.
Machine learning workflow

oscarrosete.com
oscarrosete.com
Encontrar el promedio de los atributos
El método de mínimos cuadrados busca crear una linea que minimiza las distancias entre las lineas y todos los puntos.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Método mínimos cuadrados
¿Porque una linea?
Supongamos que queremos construir un subterráneo que pase lo mas cerca posible de la mayoría de las oficinas principales.
No sería factible que visite cada edificio habrían múltiples estaciones y un costo elevado derivado.
Machine learning workflow

oscarrosete.com
oscarrosete.com
La regresión lineal determinaría una linea recta que se ajuste a la información para minimizar distancia de puntos general.
Entender la ecuación de la recta es importante.
y = c + mx
Machine learning workflow
oscarrosete.com
oscarrosete.com
La ecuación de la recta se describe por la siguiente expresión:
y = c + mx
y: variable dependiente
x: variable independiente
m: pendiente de la recta
c: valor de y , donde la linea intersecta el eje y.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Machine learning workflow


oscarrosete.com
oscarrosete.com
Sabemos que la media de x es 1,229 y la media de y es 3,431,
Machine learning workflow

oscarrosete.com
oscarrosete.com
Calculamos la diferencia de cada valor de quilates y de precio con respecto a su media.
Machine learning workflow
oscarrosete.com
oscarrosete.com
Elevamos al cuadrado la diferencia del valor de quilates con respecto a la media y sumamos todos estos valores.
Machine learning workflow

oscarrosete.com
oscarrosete.com
Multiplicamos la diferencia de los valores de peso en quilates y precio con respecto a su media y realizamos su sumatoria (11,624,370)
Machine learning workflow

oscarrosete.com
oscarrosete.com
Utilizamos estos valores para calcular m:
Con el valor de m y las medias calculamos c:
Machine learning workflow


oscarrosete.com
oscarrosete.com
Por ultimo graficamos la línea resultante
Machine learning workflow


oscarrosete.com
oscarrosete.com
Determinar la precisión
La información se particiona en 80/20. 80% para entrenar y 20% para realizar pruebas del modelo. Se utilizan porcentajes ya que la cantidad de ejemplos necesarios para entrenar un modelo es difícil de saber.
De acuerdo al contexto y la pregunta de investigación puede requerirse más o menos información.
Machine learning workflow

oscarrosete.com
oscarrosete.com
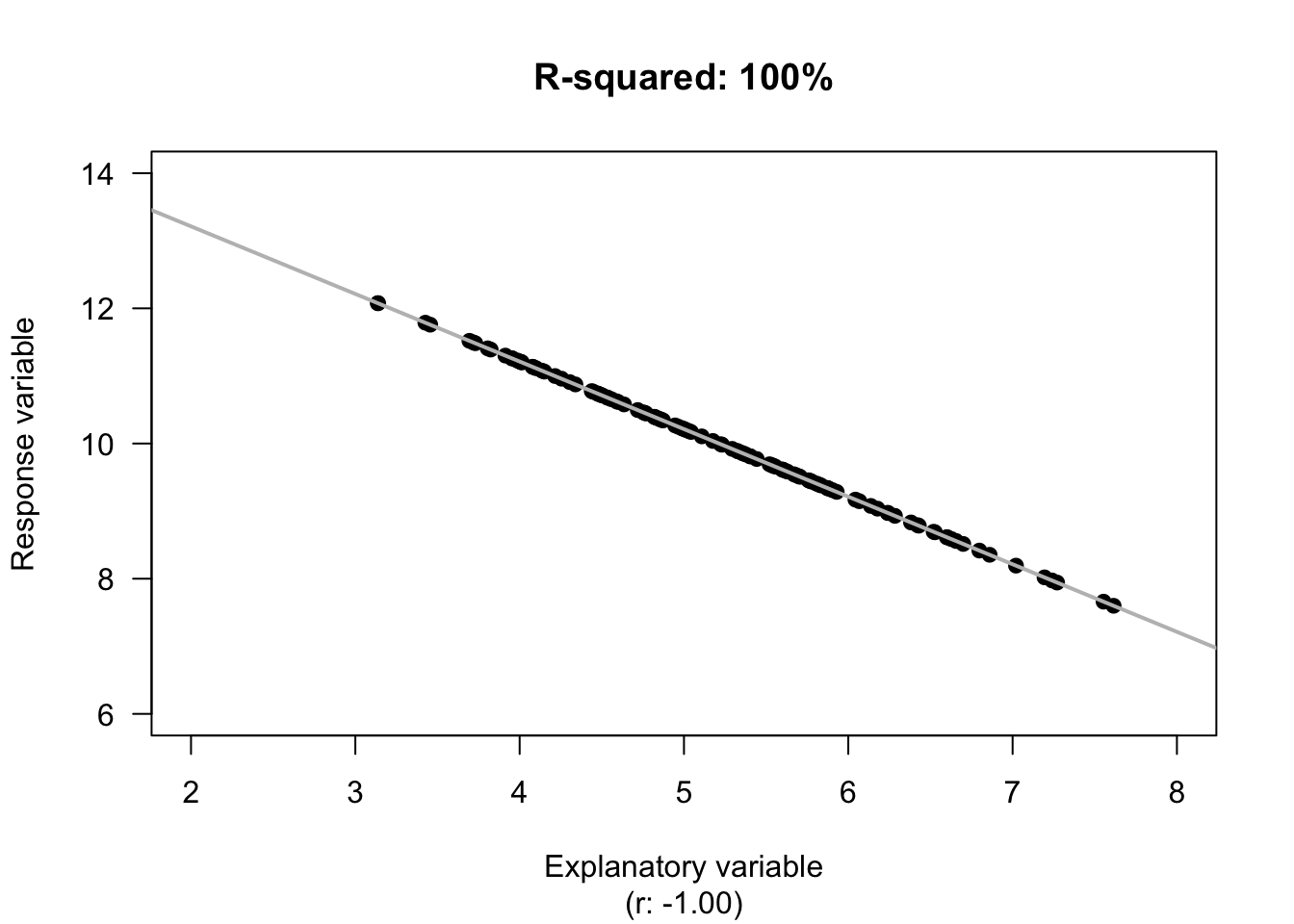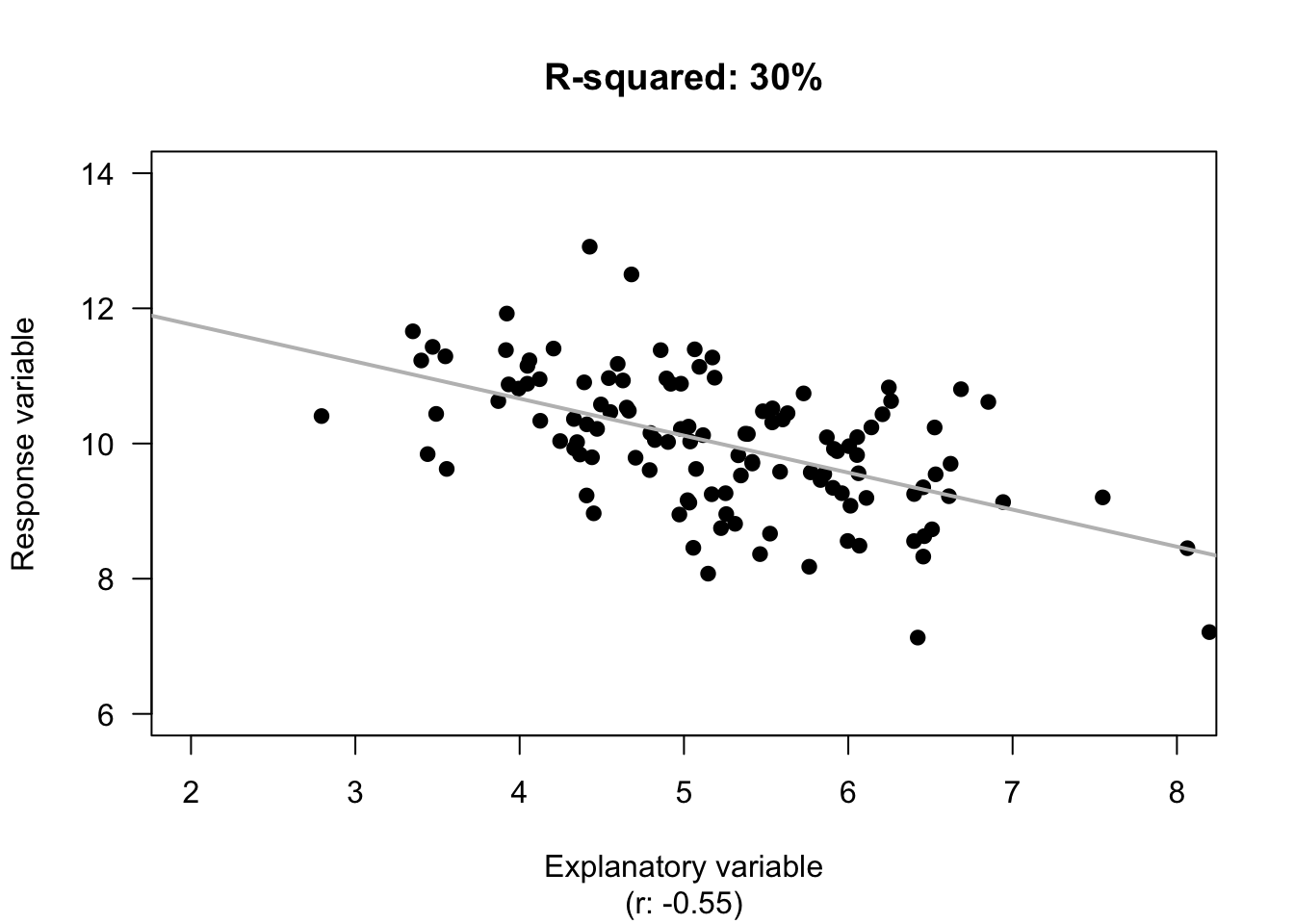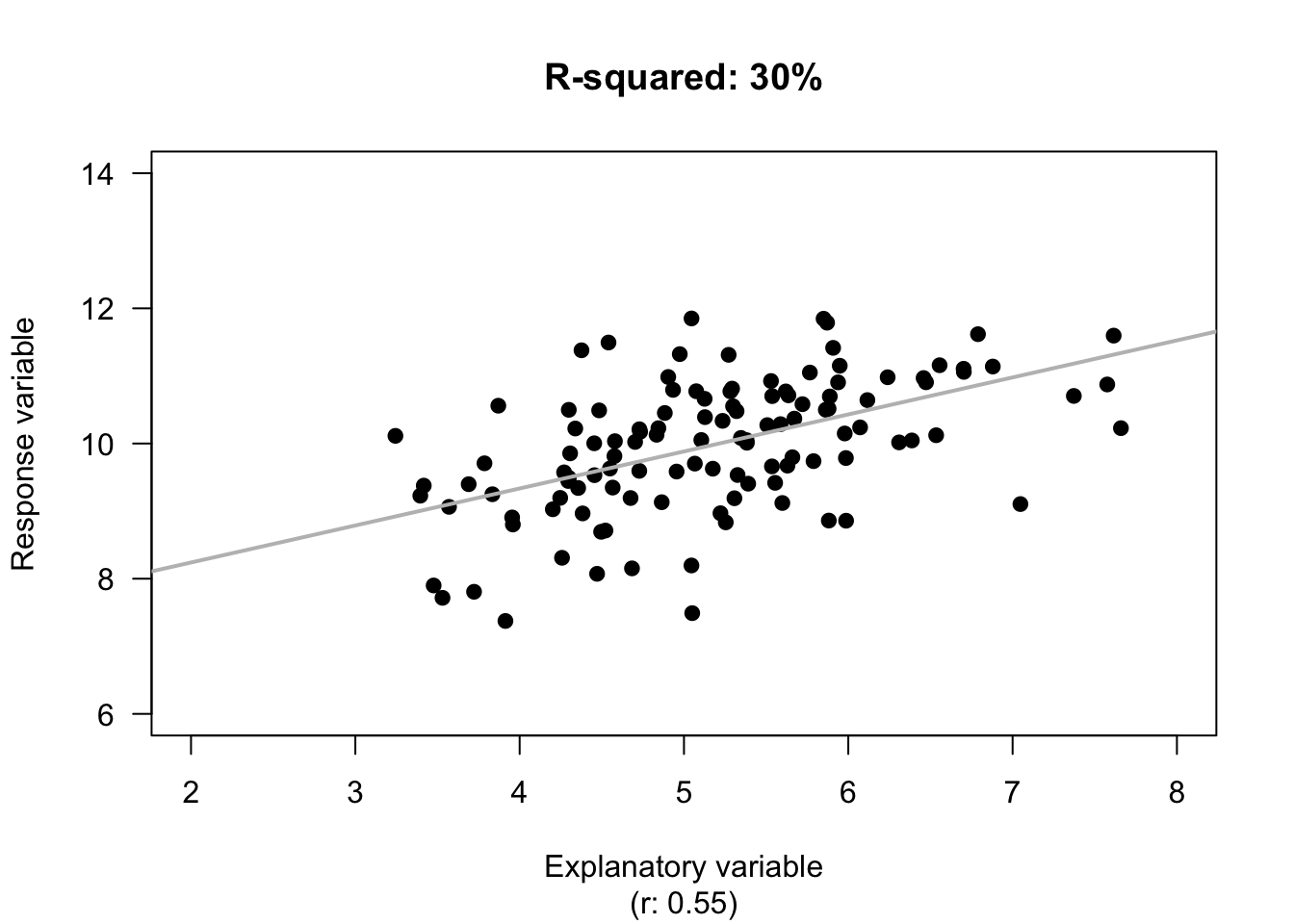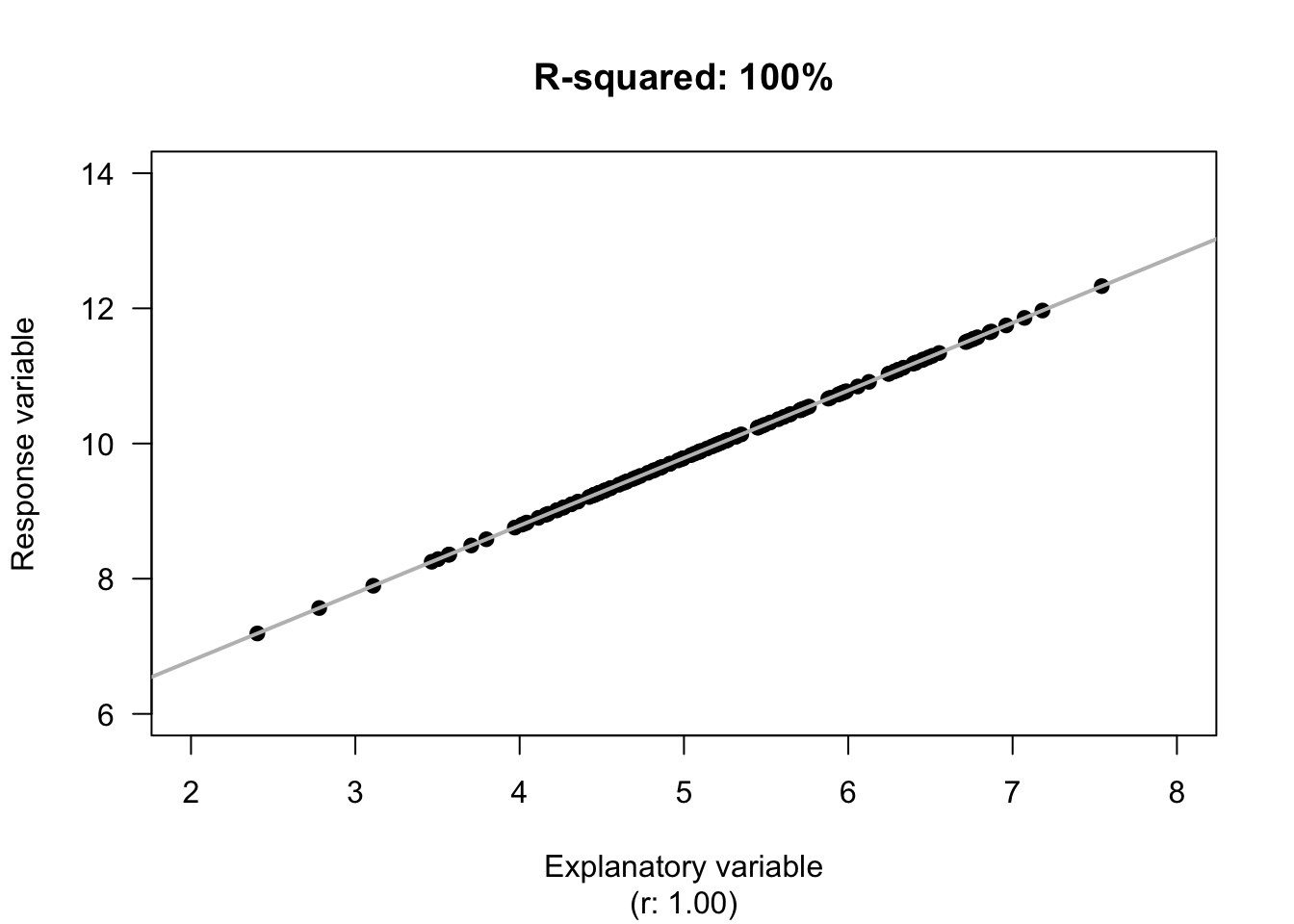
Determinar la precisión
En regresión lineal un método común para medir la precisión de un modelo es calcular R2 (R squared) para determinar la varianza entre el valor actual y el valor predecido.
Machine learning workflow

oscarrosete.com
oscarrosete.com
R²
Mean vs fitted line
Machine learning workflow
oscarrosete.com
oscarrosete.com
R²
Su valor nunca es negativo y usualmente expresado en porcentaje.
Machine learning workflow
oscarrosete.com
oscarrosete.com
El resultado—0.88—significa que el modelo es 88% preciso con información nueva.
El resultado es razonable, mostrando que la regresión lineal es precisa.
Machine learning workflow


oscarrosete.com
oscarrosete.com
Mejorar el desempeño
Entrenar y probar en información de prueba nos da una medida del desempeño del modelo. Cuando no se obtiene un resultado esperado debe realizarse trabajo adicional para mejorarlo lo que puede requerir iterar en los pasos previos.
Machine learning workflow

oscarrosete.com
oscarrosete.com
Recomendaciones para mejorar precisión
- Recolectar más información.
- Preparar la información distina
- Seleccionar atributos distintos.
- Seleccionar un algoritmo distinto para entrenar el modelo
- Realizar un tratamiento sobre los falsos positivos (overfitting)
Machine learning workflow
oscarrosete.com
oscarrosete.com
Referencia de clase
oscarrosete.com
oscarrosete.com
Regresión lineal
El escenario más sencillo con el que nos podemos encontrar es el de una variable dependiente y una única variable independiente, que siguen una relación aproximadamente lineal, salvo ruido (típicamente, normalmente distribuido):
En general, vamos a desconocer la relación de arriba, pero con un conjunto de datos y mediante cuadrados mínimos podemos estimar los coeficientes.
oscarrosete.com
oscarrosete.com
Si tenemos múltiples variables independientes, estamos en un problema de regresión lineal múltiple:
Ejemplo: Precio de un auto en términos de consumo de combustible, año de fabricación, etc.
Sin embargo, este modelo nos impone una relación lineal entre la variable dependiente y sus regresores.
Regresión lineal
oscarrosete.com
oscarrosete.com
¿Cómo sabemos que necesitamos relaciones no-lineales?
En el gráfico de los residuos (residual plot analysis) no deberíamos ver ningún patrón. Si lo hubiera significa que el ruido depende de alguna de las variables independientes.
Regresión lineal

y-y estimada
En función de los valores estimados
oscarrosete.com
oscarrosete.com
¿Cómo sabemos que necesitamos relaciones no-lineales?
En el gráfico de los residuos no deberíamos ver ningún patron. Si lo hubiera significa que el ruido depende de alguna de las variables independientes.
Regresión lineal
y-y estimada
En función de los valores estimados
Ordinary least squares(OLS)
Mínimos cuadrados ordinarios

oscarrosete.com
oscarrosete.com
Análisis de los residuos (Residual plot analysis)
El supuesto más importante de la regresión lineal es que los errores son independientes y normalmente distribuidos.
Características de una buena gráfica de residuos:
- Alta densidad de los puntos cercano al origen y baja densidad fuera del origen
- Simetría respecto al origen.
Regresión lineal
oscarrosete.com
oscarrosete.com
Análisis de los residuos (Residual plot analysis)
Regresión lineal

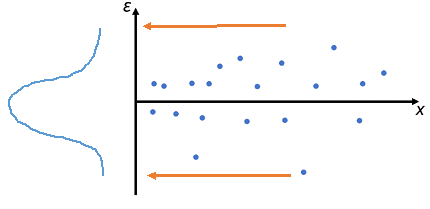
Buena gráfica de residuos
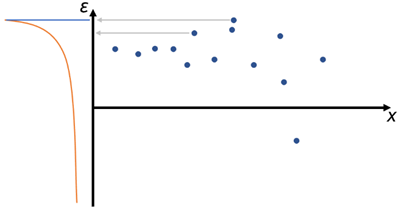
Mala gráfica de residuos

oscarrosete.com
oscarrosete.com
¿Cómo introducir no linealidad al modelo?
En ningun momento dijimos que son las x's, pueden ser cualquier cosa...
La regresión polinómica sigue siendo lineal, ya que es lineal respecto a los parámetros del modelo.
Regresión lineal
oscarrosete.com
oscarrosete.com
La regresión polinómica sigue siendo lineal, ya que es lineal respecto a los parámetros del modelo.
Los parámetros se encuentran minimizando la suma del cuadrado de los residuos al igual que antes (residual sum of square).
Grado del polinomio:
Hiper-parámetro del modelo
Regresión polinómica

oscarrosete.com
oscarrosete.com
Parámetros vs Hiperparámetros
Los parámetros son las variables que definimos y ajustamos. Los parámetros son variables aprendidas y actualizadas por la red durante el entrenamiento y que nosotros no ajustamos.
Regresión polinómica

oscarrosete.com
oscarrosete.com
Consideremos este conjunto de datos generados sinteticamente
Se están considerando los datos generados más un ruido normal.
Regresión polinómica

oscarrosete.com
oscarrosete.com
¿Cómo elegimos el grado del polinomio?
¿Qué pasa si probamos con un polinomio de grado m<N cualquiera?
Regresión polinómica

oscarrosete.com
oscarrosete.com
¿Cómo elegimos el grado del polinomio?
¿Qué pasa si probamos con un polinomio de grado m<N cualquiera?
Regresión polinómica

oscarrosete.com
oscarrosete.com
Sub-ajuste (underfitting)
El ajuste es bastante malo (tenemos muy pocos grados de libertad).
Los datos presentan una variablidad, más allá del ruido intrínseco, que un modelo simple no puede captar.
Regresión polinómica

oscarrosete.com
oscarrosete.com
Sobreajuste (overfitting)
El ajuste es perfecto (tengo tantos grados de libertad como datos en mi sistema). La curva pasa por todos los puntos (describe exactamente la variabilidad de los datos)
Regresión polinómica

oscarrosete.com
oscarrosete.com
¿Cuál es el problema de sub-ajustar o sobre-ajustar?
Hacemos una mala predicción
Underfitting: cometemos sistemáticamente el mismo error.
Regresión polinómica

oscarrosete.com
oscarrosete.com
¿Cuál es el problema de sub-ajustar o sobre-ajustar?
Hacemos una mala predicción
Overfitting: La estimación perfecta en los datos de entrenamiento se pierde cuando predecimos nuevos datos.
Regresión polinómica

oscarrosete.com
oscarrosete.com
¿Cuál es el problema de sub-ajustar o sobre-ajustar?
Cuando el modelo es identificado, generaliza bien (describe bien datos distintos a los que fue entrenado)
Regresión polinómica

oscarrosete.com
oscarrosete.com
¿Qué pasa al cambiar datos de nuestro modelo (provenientes de la misma población)?
Regresión polinómica

Grado 1: mucho sesgo
Grado 3: poco sesgo y poca varianza.
Grado 8 (valor -0.8): mucha varianza
Cross validation
oscarrosete.com
oscarrosete.com
Sesgo y Varianza
Regresión polinómica

oscarrosete.com
oscarrosete.com
Sesgo y Varianza
El error que comete un modelo proviene de dos fuentes, sesgo y varianza, que compiten entre si al variar la complejidad (grado del polinomio) del modelo.
Regresión polinómica

oscarrosete.com
oscarrosete.com
Modelo de juguete
Un modelo de juguete es un conjunto simplificado de objetos y las ecuaciones que los relacionan para que, sin embargo, puedan ser utilizados para entender un mecanismo que también es útil en la teoría completa, no simplificada.
Regresión polinómica
oscarrosete.com
oscarrosete.com
Modelo de juguete
Un modelo que tenga la suficiente complejidad para captar la variabilidad de los datos, pero suficientemente simple para abstraer de los datos , abstenerse o tapar de ruido que presentan los datos y poder señalizar o explicar bien otro conjunto de datos.
Regresión polinómica
oscarrosete.com
oscarrosete.com
K-fold Cross-validation for tuning hyper parameters
Regresión polinómica



oscarrosete.com
oscarrosete.com
K-fold Cross-validation for tuning hyper parameters
Regresión polinómica

oscarrosete.com
oscarrosete.com
Características del sobreajuste
- Cantidad de parámetros libres comparable con la cantidad de datos con la que ajustamos.
- Coeficientes muy altos
Regresión polinómica



oscarrosete.com
oscarrosete.com
Opciones contra sobreajuste (Regularización)
La idea de regularizar el polinomio es prevenir que los coeficientes no adopten valores absolutos muy altos, asociados a cambios bruscos en la curva ajustada.
Regresión polinómica

● q = 2 (ridge regression)
● q = 1 (lasso regression)
oscarrosete.com
oscarrosete.com
Regularización
Para atenuar el impacto de los problemas que aparecen al emplear modelos ajustados por minimos cuadrados ordinarios tales como el overfitting podemos utilizar regularización ridge, lasso o elastic net.
Estos métodos fuerzan a que los coeficientes del modelo tiendan a cero, minimizando así el riesgo de overfitting, reduciendo varianza, atenuado el efecto de la correlación entre predictores y reduciendo la influencia en el modelo de los predictores menos relevantes.
Regresión polinómica
oscarrosete.com
oscarrosete.com
Regularización
Ridge
Lasso
Regresión polinómica
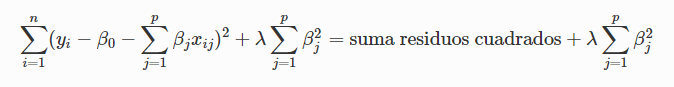
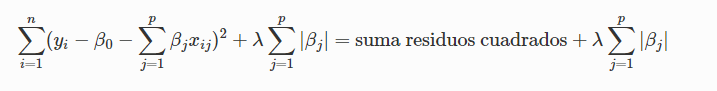
oscarrosete.com
oscarrosete.com
Regularización
La principal diferencia práctica entre lasso y ridge es que el primero consigue que algunos coeficientes sean exactamente cero, por lo que realiza selección de predictores, mientras que el segundo no llega a excluir ninguno.
Regresión polinómica
oscarrosete.com
oscarrosete.com
Regularización
● q = 2 (ridge regression): deja a la función a minimizar cuadrática, con lo cual el proceso de minimización es muy parecido al de cuadrados mínimos.
● q = 1 (lasso regression): para valores de alfa altos, fuerza a que muchos coeficientes se vayan a 0, lo cual hace que el modelo se vuelva “esparso” (sparse en inglés, con muchos ceros). Ayuda a interpretar mejor modelo ya
que actúa como un selector de las variables importantes (se queda con los términos dominantes y descarta los otros).
Regresión polinómica

oscarrosete.com
oscarrosete.com
Regularización
Gracias a esto podríamos incrementar la complejidad del modelo y con el termino de regularización mejorar las características de predicción de datos futuros.
Regresión polinómica

oscarrosete.com
oscarrosete.com
Opción para interpolación
Random forest regression (bosque aleatorio)
Regresión polinómica

oscarrosete.com
oscarrosete.com
Regresión polinómica

oscarrosete.com
oscarrosete.com
- Revisar la documentación existente en: https://github.com/iamaziz/PyDataset
- Seleccionar un dataset
- Seleccionar dos atributos
- Ajustar un modelo de regresión polinomial de acuerdo al material visto en clase que obtenga los mejores resultados en el conjunto de datos de entrenamiento así como el conjunto de datos de prueba.
Aprendizaje automático
Actividad individual
oscarrosete.com
oscarrosete.com
- Agregar visualizaciones donde se muestren los datos de entrenamiento, datos de prueba y la predicción de su modelo.
- Agregar alguna métrica de la precisión de su predicción.
- Justificar el ajuste propuesto de hiperparámetros
Aprendizaje automático
Actividad individual

oscarrosete.com
oscarrosete.com
Agenda
3.1. Aprendizaje supervisado y no supervisado
3.2. Algoritmo “Backpropagation through time”
3.3. Aprendizaje en tiempo real
3.4. Algoritmo K-Means
3.4. Redes Neuronales
Unidad de competencia III. Algoritmos de aprendizaje
oscarrosete.com
oscarrosete.com
Motivación
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Motivación
Regresión logística y clasificación
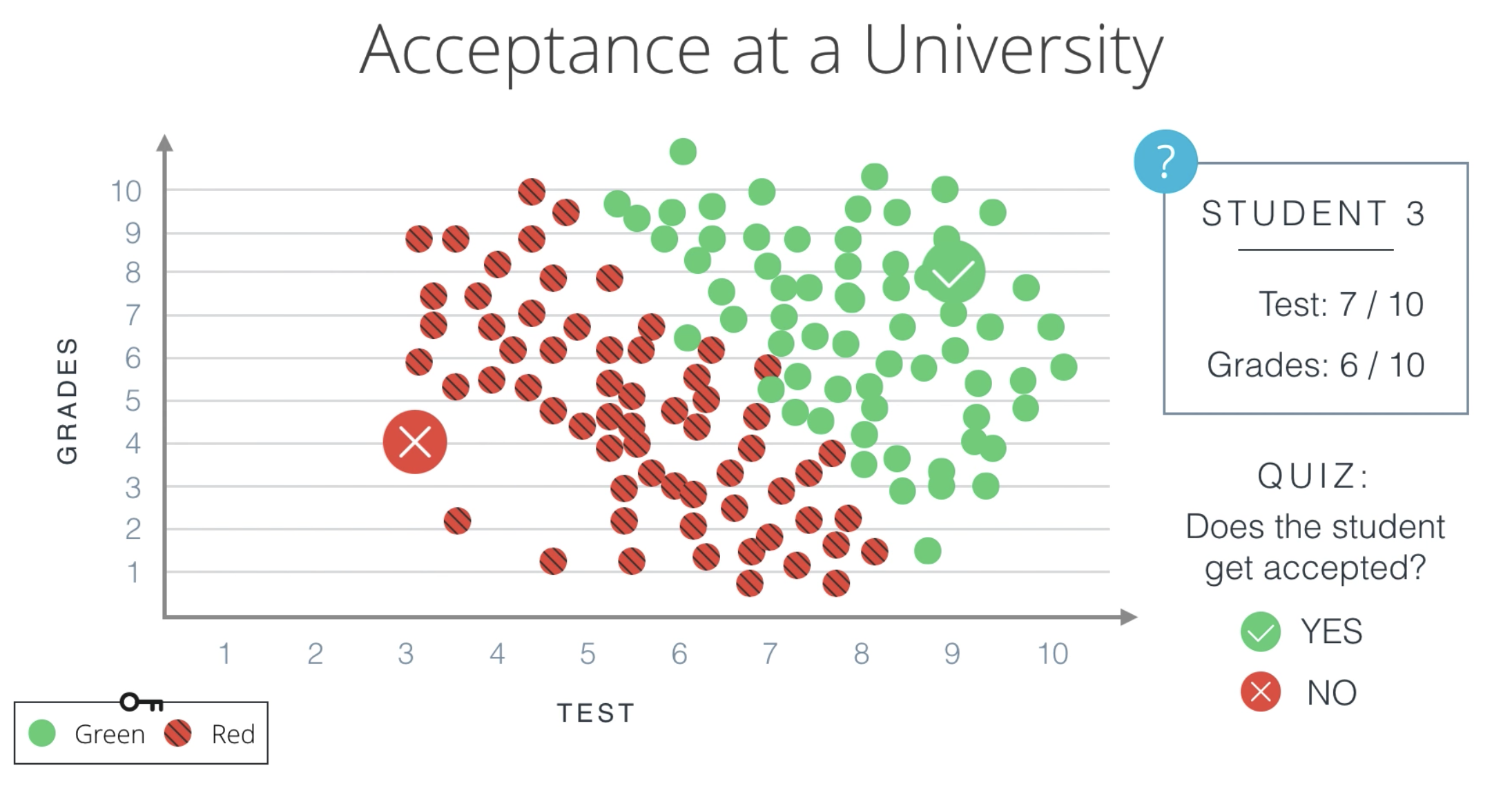
oscarrosete.com
oscarrosete.com
Solución
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Clasificación
Los problemas de clasificación involucran asignar una etiqueta a un ejemplo basado en sus atributos.
Estos problemas son diferentes a los de regresión, en los que un valor es estimado.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Clasificación
La clasificación busca predecir un valor basado en una o más atributos, pero a diferencia de la regresión se busca predecir una clase discreta en lugar de un valor continuo.
Ejemplos de valores discretos son atributos categóricos tales como el color en el conjunto de datos del diamante a diferencia de valores continuos como el precio.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Clasificación
Suponga que contamos con múltiples vehículos que son carros y camiones, de los cuales mediremos el peso de y contaremos su número de llantas de cada vehículo.
Podríamos buscar una relación entre el peso y el número de llantas de los vehículos para predecir si un vehículo es un carro o un camión.
Regresión logística y clasificación

oscarrosete.com
oscarrosete.com
Regresión vs Clasificación
Considere los siguientes escenarios y determine si es un problema de regresión o clasificación:
- Basado en la información de ratas, donde contamos con un atributo de la expectativa de vida y la obesidad, buscamos determinar la correlación entre los dos atributos.
- Basado en información de animales, donde contamos con el peso de cada animal y si cuenta o no con alas, buscamos determinar si esos animales son pájaros.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Regresión vs Clasificación
- Basado en información de dispositivos de cómputo, donde contamos con información de dimensiones de la pantalla, peso y sistema operativo y buscamos determinar si los dispositivos son tablets, laptops o teléfono.
- Basado en información del clima, donde contamos con información de la cantidad de lluvia y el valor de humedad y se busca determinar la humedad en diferentes temporadas de lluvia.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Regresión vs Clasificación
- Regresión: La relación entre las dos variables se explora. La expectativa de vida es la variable dependiente y la obesidad la variable independiente.
- Clasificación: Al asignar la etiqueta de si es un pájaro o no utilizando el peso y las características de los ejemplos.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Regresión vs Clasificación
- Clasificación: Se clasifica un ejemplo en tablet, laptop o teléfono utilizando sus características.
- Regresión: Se explora la relación entre cantidad de lluvia y humedad. La variable dependiente es la humedad y la independiente la cantidad de lluvia.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Diferentes algoritmos son utilizados para problemas de regresión y clasificación.
Algunos algoritmos de clasificación populares son regresión logística, análisis discriminante lineal (LDA), redes neuronales artificiales (ANN), máquinas de vectores de soporte (SVM), K-Nearest-Neighbor (k-NN), clasificador bayesiano ingenuo (NB) y arboles de decisión (DT), bosques aleatorios y técnicas de aprendizaje profundo.
Regresión logística y clasificación
oscarrosete.com
oscarrosete.com
Motivación
Predicción pago de los clientes
Información utilizada: Ingreso, antecedentes previos de clientes
Regresión logística y clasificación

oscarrosete.com
oscarrosete.com
Motivación
Decisiones médicas de urgencia:
Llega paciente a una guardia, luego de pocos estudios se decide si se lleva a intensivos o no.
Regresión logística y clasificación

oscarrosete.com
oscarrosete.com
Motivación
El clima:
Dadas las temperaturas y la humedad, determinar si lloverá o no lloverá
Regresión logística y clasificación

oscarrosete.com
oscarrosete.com
Regresión Logística
La regresión logística y la regresión lineal son distintas en cuanto a los problemas que resuelven.
La regresión lineal se enfoca en predicciones numéricas y la regresión logística es utilizada en algoritmos de clasificación para predecir clases discretas.
Regresión logística

oscarrosete.com
oscarrosete.com
Regresión Logística
Por ejemplo la regresión logística se utiliza frecuentemente para detección de fraudes o identificar correos spam.
La principal diferencia es añadir una función sigmoide para calcular y convertir el resultado numérico a una probabilidad entre 0 y 1.
Regresión logística
oscarrosete.com
oscarrosete.com
La hipótesis de representación
Tenemos entonces:
- x1, x2 características numéricas
- Una etiqueta categórica (inicialmente binaria)
¿Qué hacemos? clasificamos

Regresión logística
oscarrosete.com
oscarrosete.com
La hipótesis de representación
Supongamos el siguiente problema de clasificación


Llevamos las categorías a la representación binaria
Regresión logística
oscarrosete.com
oscarrosete.com
La hipótesis de representación
¿Qué pasa si tratamos de ajustar con una lineal?


Regresión logística
oscarrosete.com
oscarrosete.com
La hipótesis de representación
¿Qué pasa si tratamos de ajustar con una función lineal?
- Imagen no acotada a 0 y 1.
- Con nuevos datos de entrenamiento pueden cambiar abruptamente las predicciones del modelo, al agregar un registro al entrenamiento del modelo.


Regresión logística
oscarrosete.com
oscarrosete.com
La hipótesis de representación
Pensemos en una función como una probabilidad, no tiene sentido una probabilidad de 1.5
Utilizaremos una función con imagen acotada entre 0 y 1 (función sigmoidea), donde el parámetro de la exponencial son los coeficientes de la lineal

Regresión logística
oscarrosete.com
oscarrosete.com
Función sigmoidea
Utilizamos un poco del conocimiento previo de regresiones lineales para meterlo dentro del clasificador categórico.
La función sigmoidea también es llamada función logística, nos permite clasificar de forma binaria una categoría a partir de características numéricas.
Regresión logística
oscarrosete.com
oscarrosete.com
Función sigmoidea
- Monótonamente creciente
- Acotada entre 0 y 1
- x es la variable independiente, y es la variable dependiente

Regresión logística
oscarrosete.com
oscarrosete.com
Función sigmoidea
Nos otorga probabilidad de que un registro valga y, dado que tengo parámetros beta y atributos (features) x
En cierta medida, se puede identificar como una probabilidad condicional y el teorema de bayes.
Regresión logística
oscarrosete.com
oscarrosete.com
Probabilidad de corte/quiebre:
Valor a partir del cual asignaría la etiqueta.
En la imagen es 0.5.
Esto es un potencial hiperparámetro.

Regresión logística
oscarrosete.com
oscarrosete.com
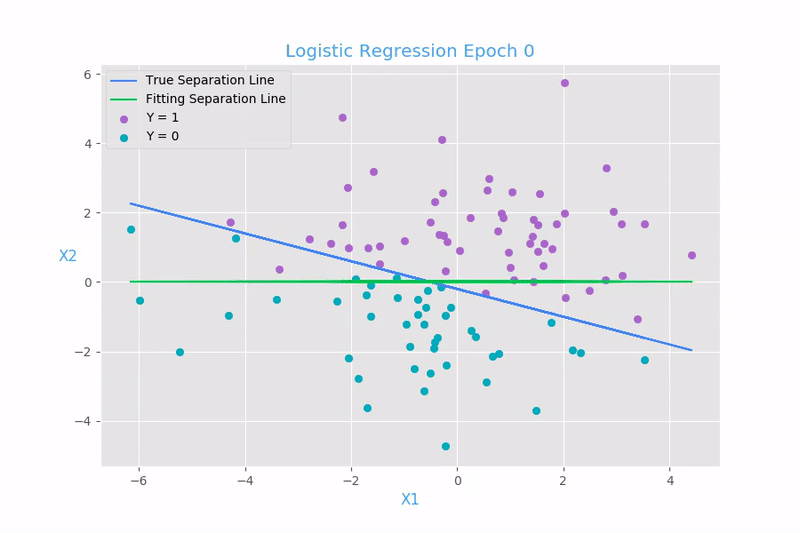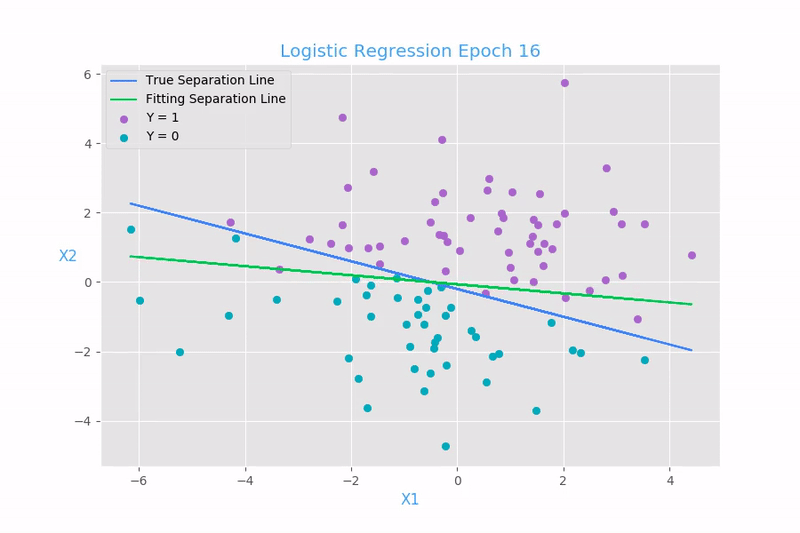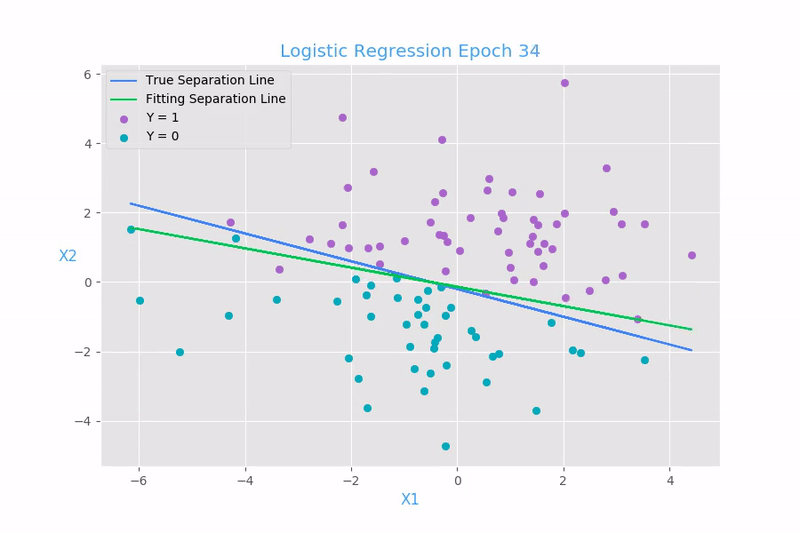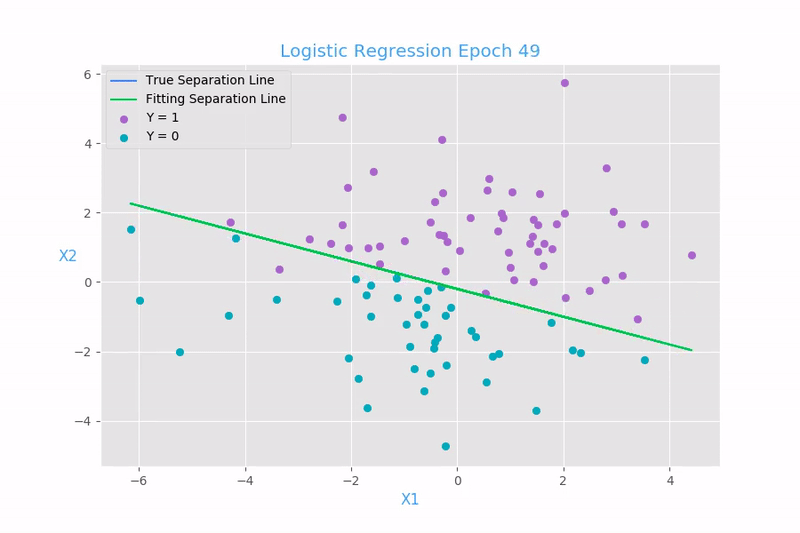
Frontera de decisión
Trabajando con la probabilidad de corte en 0.5, la cual determina los parámetros B.


Regresión logística
oscarrosete.com
oscarrosete.com
Frontera de decisión (más de una característica)
Trabajando con la probabilidad de corte en 0.5, la cual determina los parámetros B.


Regresión logística
oscarrosete.com
oscarrosete.com




Líneas encontradas con gradiente descendiente
Regresión logística
oscarrosete.com
oscarrosete.com
Frontera de decisión
Al igual que con la regresión lineal, podemos proponer polinomios:


Regresión logística
oscarrosete.com
oscarrosete.com
Búsqueda de coeficientes
A diferencia de lo que teníamos en el caso lineal, no utilizamos cuadrados mínimos.
Utilizamos conceptos de probabilidad (máxima verosimilitud), donde buscamos minimizar el producto de probabilidad de que a cada punto se le asigne la categoría correcta.

Regresión logística
oscarrosete.com
oscarrosete.com
Máxima verosimilitud y su relación con la función de costo del método de mínimos cuadrados
Máxima verosimilitud
Regresión logística
oscarrosete.com
oscarrosete.com
Búsqueda de coeficientes
La máxima verosimilitud(MLE, o Maximum Likelihood Estimation), no es un algoritmo, es un metodo de estimación. Usualmente se utiliza un algoritmo tal como gradiente descendiente para calcular la máxima verosimilitud.
Regresión logística

oscarrosete.com
oscarrosete.com
Gradiente descendiente
El método del gradiente descendiente nos permite automatizar de forma más eficiente el ir probando coeficientes de los modelos de machine learning.
Regresión logística
oscarrosete.com
oscarrosete.com
Gradiente descendiente
Es un algoritmo de optimización. Nos permite obtener un mínimo (o un máximo, gradient ascent) de nuestra función de costo J(w, b)
Regresión logística
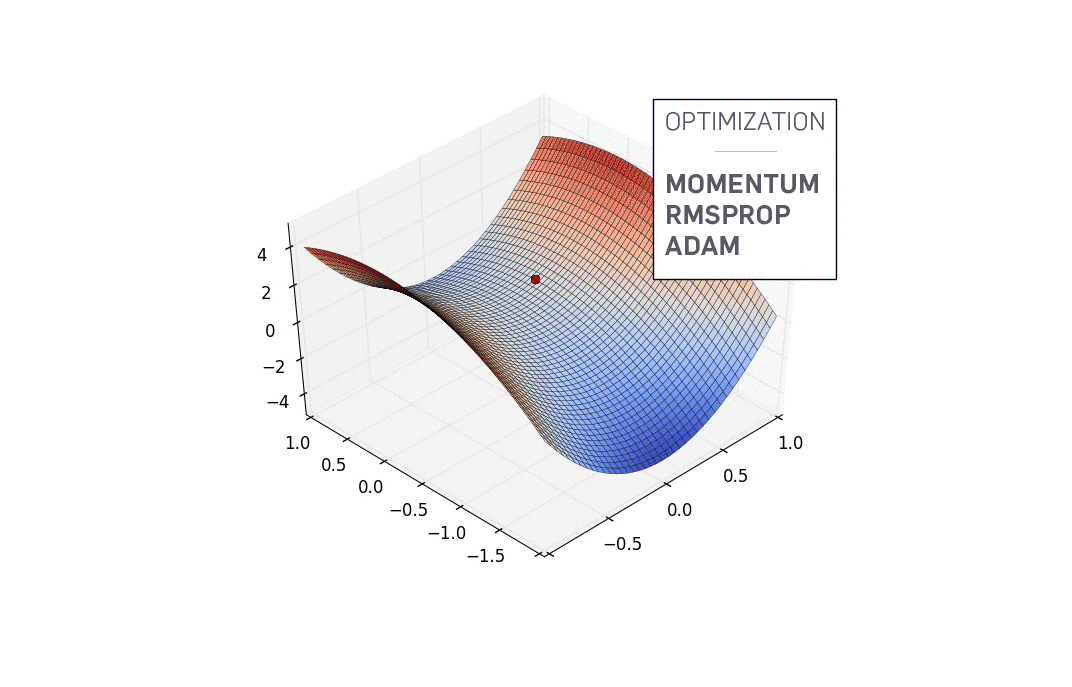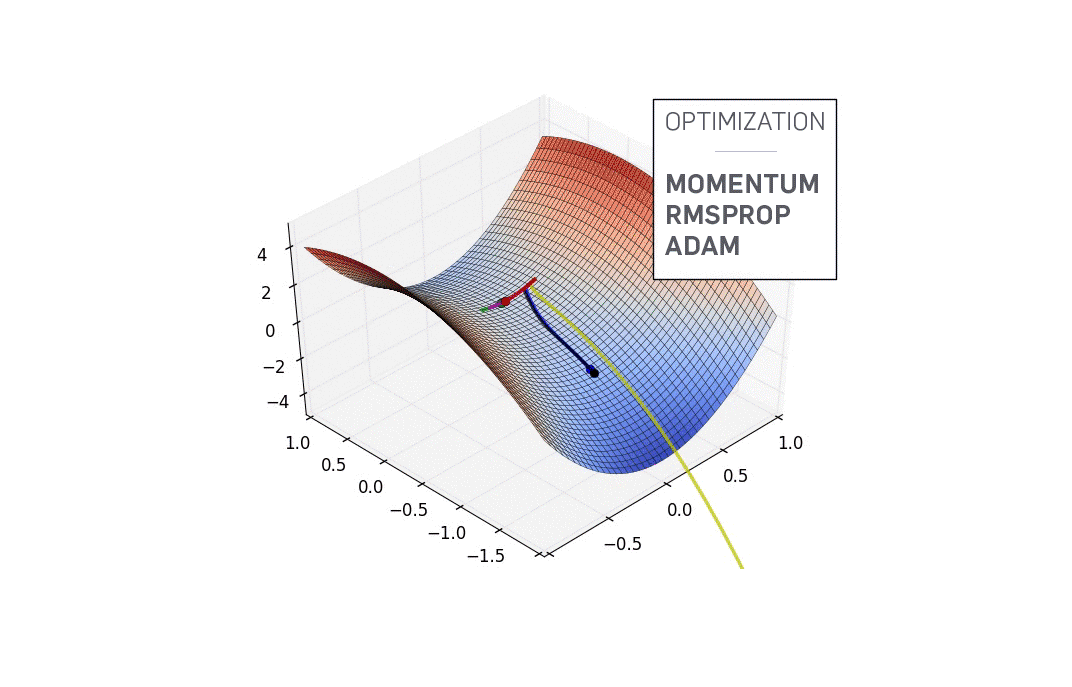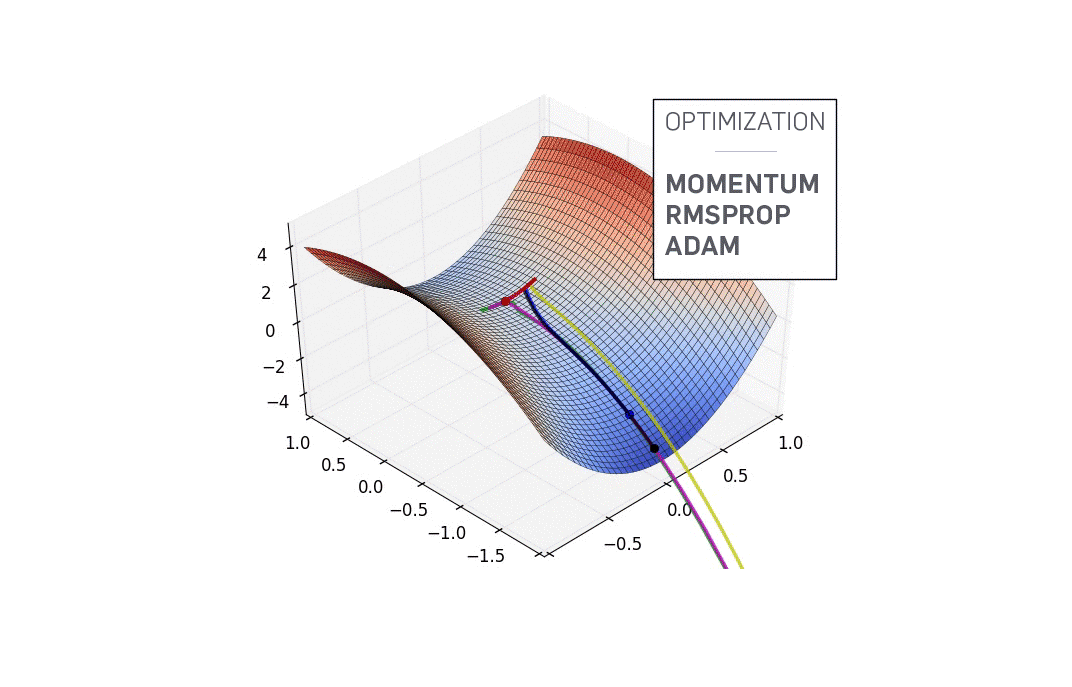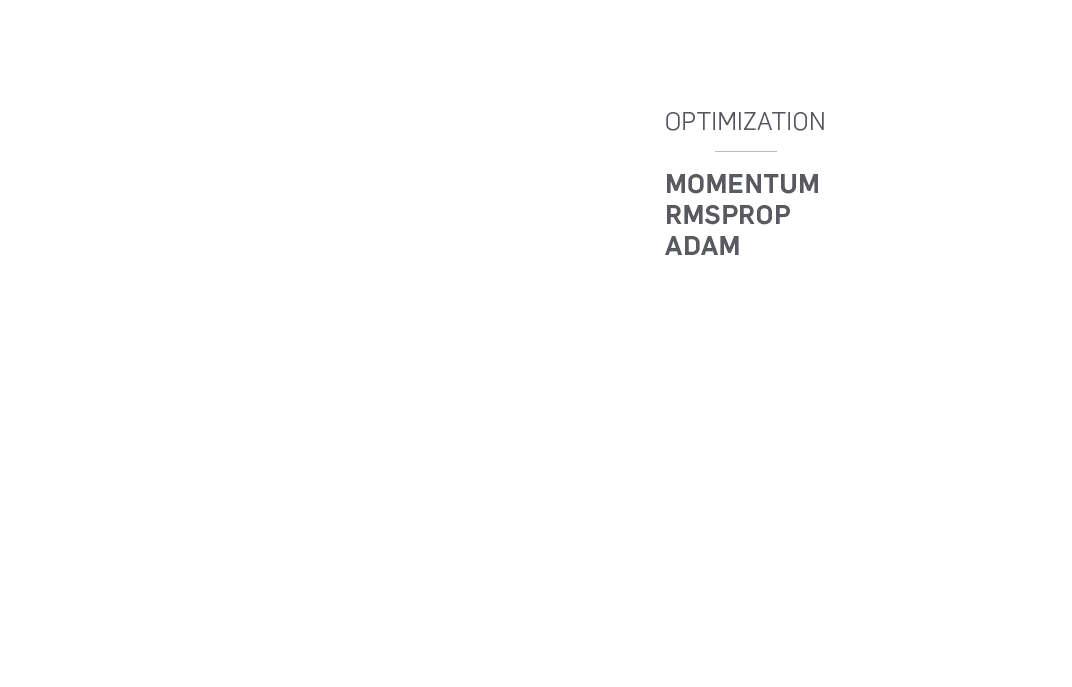
oscarrosete.com
oscarrosete.com
Función de coste
La función de coste J es la función de lo que queremos optimizar. En el caso más simple, es igual al error que queremos minimizar.
J = MSE
En algunos casos nos interesará introducir términos de regularización
Regresión logística
oscarrosete.com
oscarrosete.com
Gradiente descendiente
Hay tres tipos populares, los cuales difieren de la cantidad de datos a utilizar:
- Batch gradient descent
- Stochastic gradient descent
- Mini-batch gradient descent
Se puede usar tanto con modelos simples como en modelos complejos (por ejemplo, redes neuronales con muchas variables)
Regresión logística

oscarrosete.com
oscarrosete.com
Implementación de gradiente descendiente para regresión lineal y logística
Regresión logística
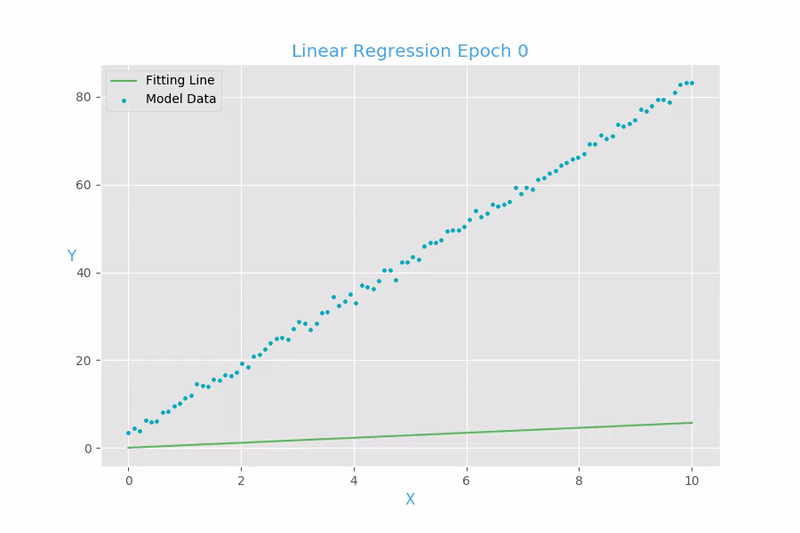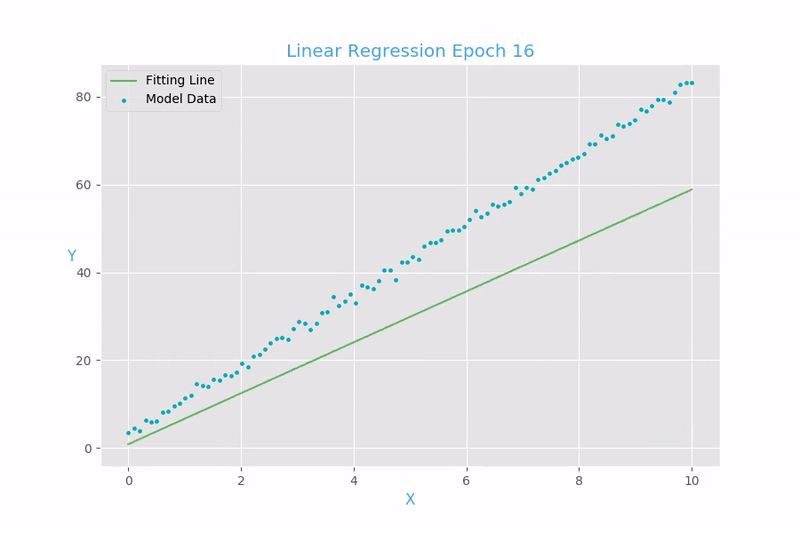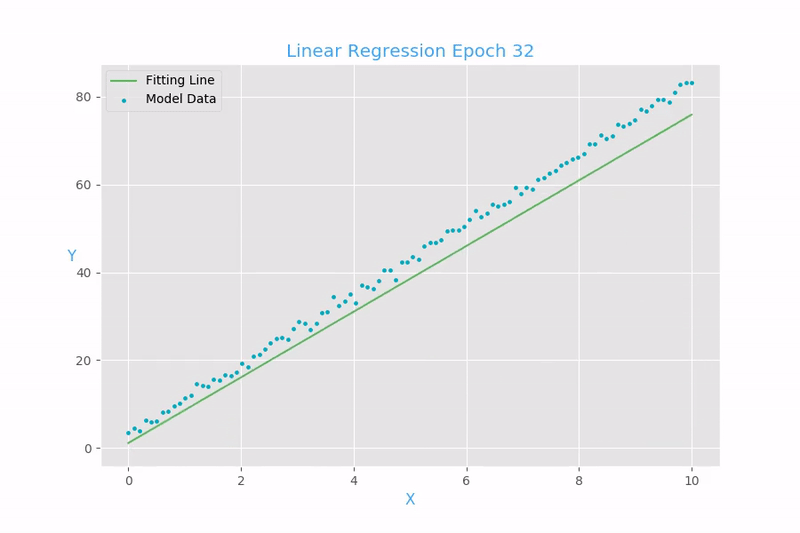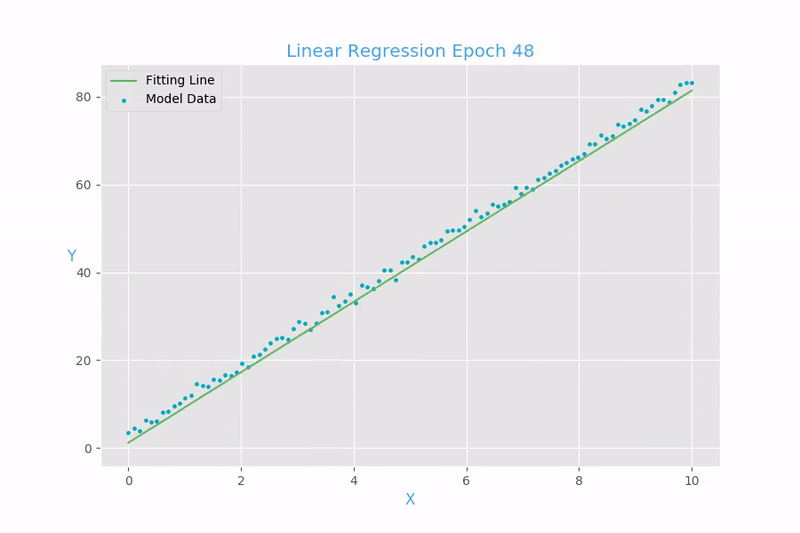
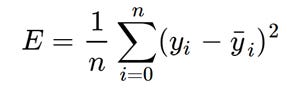
Función de costo para la regresión lineal:
Mean Square Error (MSE)

oscarrosete.com
oscarrosete.com
Clasificación múlitple
¿Que pasa si tenemos mas de dos posibles categorías?
Predicción pago de los clientes:
paga el total, paga una parte, paga el minimo
Decisiones médicas de urgencia:
puede esperar, terapia intermedia, terapia intensiva.

Regresión logística
oscarrosete.com
oscarrosete.com
Clasificación múltiple
Uno contra todos, vamos a pensar en una comparación binaria para cada categoría:
- Que pertenezca a A o no
- Que pertenezca a B o no
- Que pertenezca a C o no



Regresión logística
oscarrosete.com
oscarrosete.com
Clasificación múltiple
- Que pertenezca a A o no (0.7)
- Que pertenezca a B o no (0.5)
- Que pertenezca a C o no (0.8)
Nos quedamos con la categoría según cual sea el :

Regresión logística
oscarrosete.com
oscarrosete.com
Regresión logística
oscarrosete.com
oscarrosete.com
Agenda
3.1. Aprendizaje supervisado y no supervisado
3.2. Algoritmo “Backpropagation through time”
3.3. Aprendizaje en tiempo real
3.4. Algoritmo K-Means
3.4. Redes Neuronales
Unidad de competencia III. Algoritmos de aprendizaje
oscarrosete.com
oscarrosete.com
Redes neuronales
oscarrosete.com
oscarrosete.com
- Revisar la documentación existente en: https://github.com/iamaziz/PyDataset
- Seleccionar un dataset
- Ajustar un modelo de regresión logística de acuerdo al material visto en clase que obtenga los mejores resultados en el conjunto de datos de entrenamiento así como el conjunto de datos de prueba.
Aprendizaje automático
Actividad individual
oscarrosete.com
oscarrosete.com
- Agregar visualizaciones donde se muestren los datos de entrenamiento, datos de prueba y la predicción de su modelo, así como la frontera de decisión.
- Agregar alguna métrica de la precisión de su predicción.
- Justificar el ajuste propuesto de hiperparámetros
Aprendizaje automático
Actividad individual

oscarrosete.com
oscarrosete.com
Introducción
Las redes neuronales artificiales (ANNs) son herramientas fundamentales del machine learning, utilizadas en una variedad de de formas para el logro de objetivos tales como reconocimiento de imágenes, procesamiento natural de lenguaje, entre otros
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Introducción
Las ANNs aprenden de manera similar a otros algoritmos, su principio es el entrenamiento basado en datos.
Su utilización recomendada es en conjuntos de datos donde es difícil identificar la relación entre lo distintos atributos.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
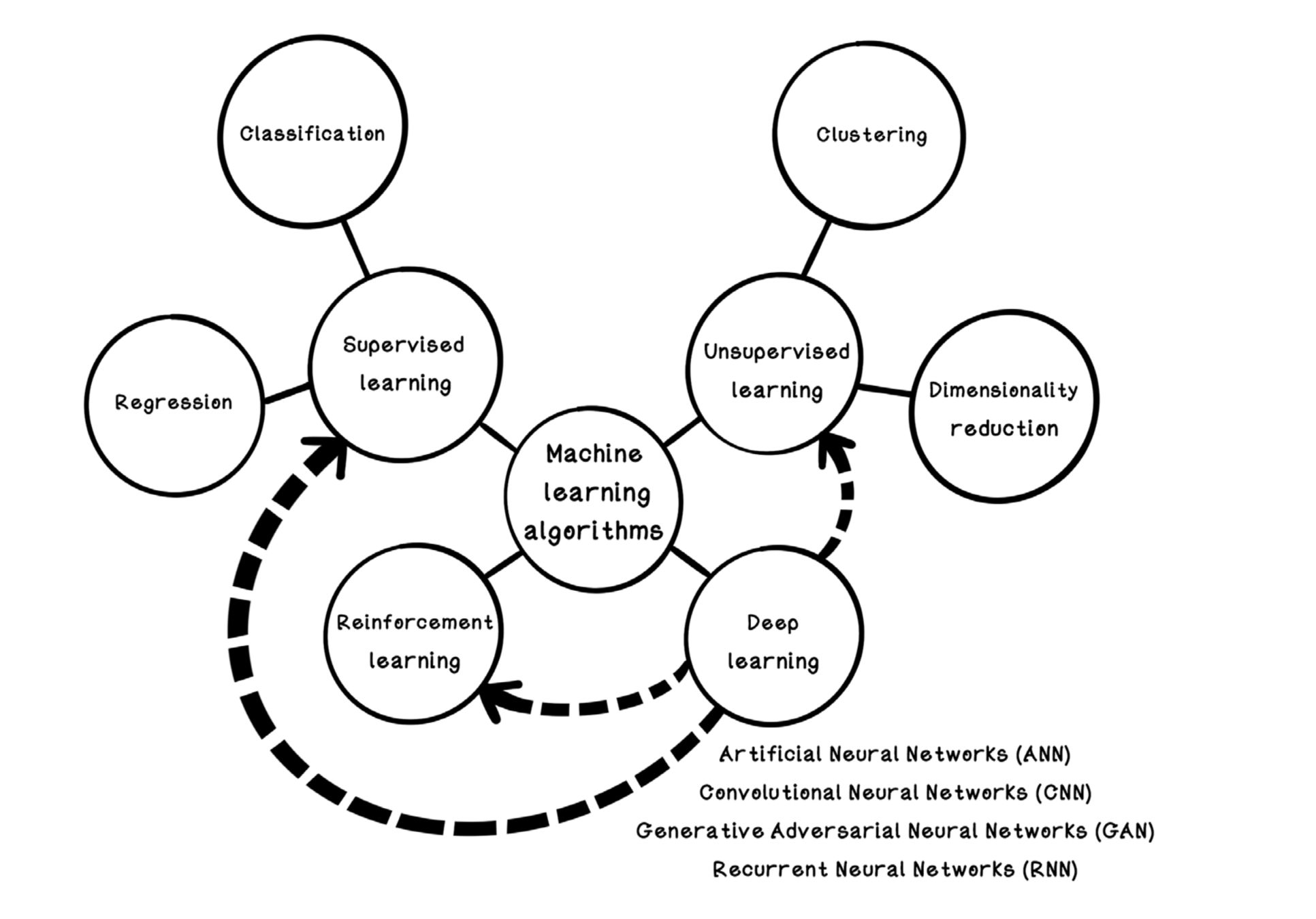
Introducción
Para tener un mejor entendimiento es recomendable ver el contexto general de composición y clasificación de algoritmos de aprendizaje automático.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Introducción
Deep learning es el nombre dado a algoritmos que utilizan AANs en distintas arquitecturas para alcanzar un objetivo.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Introducción
Para su estudio podemos recurrir al ciclo de vida del aprendizaje automático.
Un problema necesita identificarse, los datos deben de ser recolectados, entendidos y preparados, entonces el modelo de ANN sera probado y mejorado si es necesario.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Inspiración
Se encuentran inspiradas en fenómenos naturales, en este caso el cerebro y el sistema nervioso. El sistema nervioso es una estructura biológica que nos permite sentir sensaciones y es la base de la operación del cerebro.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Inspiración
Las redes neuronales consisten de neuronas interconectadas que comparten información utilizando señales eléctricas y químicas.
Las neuronas pasan información a otras neuronas y ajustan la información para cumplir una función.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Inspiración
Cuando tomas un vaso y tomas agua, millones de neuronas procesan la intención de lo que quieres realizar, la acción física para lograrlo e inclusive te retroalimentan de si fuiste exitoso.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Inspiración
Pensemos en los niños aprendiendo a beber del vaso. Empiezan con mucha dificultad, tirando el vaso. Posteriormente aprenden a sostenerlo con dos manos, gradualmente aprenden a sostenerlo con una sola mano y beber sin problemas.
El proceso dura meses, y es un ejemplo de aprendizaje basado en práctica o entrenamiento.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Inspiración
La figura muestra un modelo simplificado en el que se reciben entradas (estímulos), se procesan a través de la red neuronal y se provee una salida o respuesta.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Inspiración
Simplificado, una neurona consiste de dendritas que reciben señales de otras neuronas; un cuerpo de celda y un núcleo que activa y ajusta la señal; un axón que comparte la señal a otras neuronas; y sinapsis que ajusta la señal antes de pasarla a otras dendritas de neuronas.
Redes neuronales artificiales
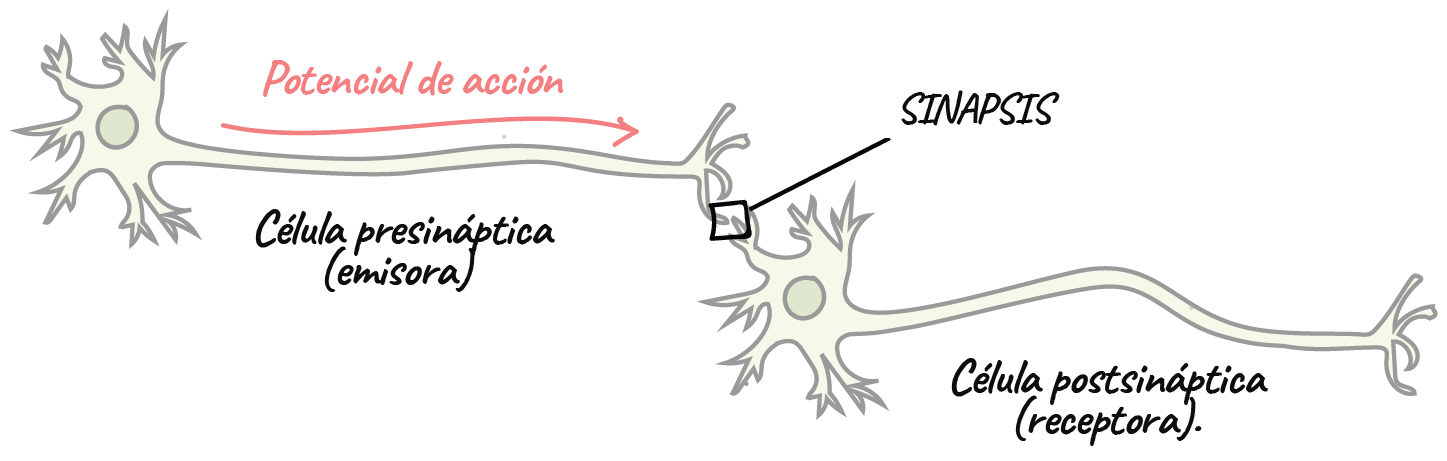
oscarrosete.com
oscarrosete.com
Clasificación
Aproximadamente 90 billones de neuronas trabajan juntas para obtener nuestro nivel de inteligencia.
Aunque las ANNS están inspiradas en las redes neuronales biológicas, no son representaciones idénticas ya que todavía se encuentra en investigación el sistema. nervioso.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Perceptron
La neurona es un elemento fundamental en el cerebro y sistema nervioso, acepta entradas de otras neuronas, procesa y transfiere los resultados a otras neuronas conectadas.
Las redes neuronales artificiales tienen como concepto fundamental el perceptron, la representación lógica de una neurona biológica.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Perceptron
Los perceptrones también reciben entradas (dendritas), modifican estas entradas con pesos (weights) como la sinapsis, procesan las entradas con pesos (como el núcleo y celda) y entregan una salida (axón).
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Componentes del perceptrón
- Entradas (inputs)—Describe los valores de entrada, en una neurona sería la señal de entrada.
- Pesos (weights)—Representan la sinapsis, influencian la intensidad de una entrada en la respuesta de la salida.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
- Nodo oculto (hidden node)—Suma los valores con sus respectivos pesos de entrada y aplica la función de activación al resultado.
- Salida—Describe la salida final del perceptrón
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Supongamos que somos agentes de bienes raíces intentando determinar si un departamento sera rentado el siguiente mes, utilizando su dimensión y precio.
Asumimos que un perceptrón ya fue entrenado, es decir, sus pesos fueron ajustados.
Los pesos representan las relaciones e influencia de las variables de entrada.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
La figura muestra un perceptrón entrenado para clasificar si un departamento sera rentado. Las entradas representan el precio y dimensiones del departamento. El precio y dimensiones máximas son de $8,000 y 80 metros cuadrados.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
La salida del perceptron es la probabilidad de que sea rentado el departamento.
Los pesos, la función de suma y la función de activación son clave para lograr la predicción.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Utilizando el conocimiento del funcionamiento del perceptron, calculemos la salida.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Redes neuronales artificiales

Utilizando el conocimiento del funcionamiento del perceptron, calculemos la salida.
oscarrosete.com
oscarrosete.com
Un ejemplo de implementación de una arquitectura ANN puede ser la clasificación de si sucederá una colisión o no utilizando los atributos con los que cuentan.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Los atributos en el conjunto de datos deben ser entradas y la clase que buscamos predecir la salida.
Los nodos de entrada serán la velocidad, calidad del terreno, rango de visión, experiencia total; el nodo de salida será si habrá colisión.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Redes neuronales artificiales


oscarrosete.com
oscarrosete.com
Como en otros algoritmos, la preparación de los datos es importante para lograr una clasificación exitosa.
El principal reto es representar datos de manera adecuada, por ejemplo representar velocidad y rango de visión, no se puede comparar 65 km/h y visión de 36 grados con una ANN.
Redes neuronales artificiales
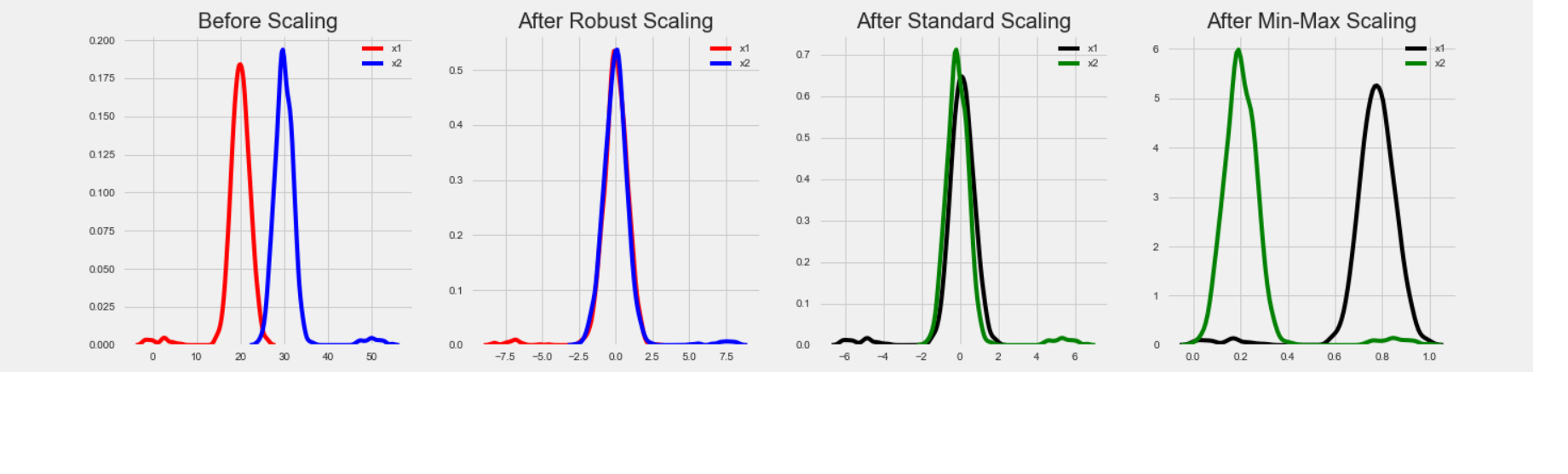
oscarrosete.com
oscarrosete.com
Como en otros algoritmos, la preparación de los datos es importante para lograr una clasificación exitosa.
Redes neuronales artificiales
Escalar vs Normalizar
oscarrosete.com
oscarrosete.com
¿Por qué escalamos los datos?
Imagina que estás viendo los precios de algunos productos tanto en yenes como en dólares estadounidenses. Un dólar estadounidense vale alrededor de 100 yenes, pero si no escala sus precios, los algoritmos como SVM o KNN (k-Nearest Neighbor) considerarán una diferencia de precio de 1 yenes tan importante como una diferencia de 1 dólar estadounidense.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Una manera de escalar datos para poder compararlos es utilizar el enfoque min-max, que busca escalar la totalidad de datos de 0 a 1.
También se reduce sesgo en datos de entrada grande, considerando los valores máximos y mínimos para cada atributo.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Los datos seleccionados son los siguientes:
- Velocidad—La velocidad mínima es 0 que significa que el carro no se mueve, la máxima 120, asumiendo limite legal promedio.
- Calidad del terreno—Valor mínimo 0 y valor máximo 10.
- Grado de visión—El valor máximo representaría visión total de 360, el valor mínimo es 0.
- Experiencia del conductor—Consideraremos un máximo de 400,00 km de experiencia y mínimo de 0.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
El escalamiento Min-max utiliza los valores mínimos y máximos para cada atributo y encuentra el porcentaje del valor actual para el atributo.
La formula es simple: resta el valor mínimo al valor actual y divide entre la diferencia del mínimo y el máximo.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
La figura muestra el escalamiento para el primer registro de datos:
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
En la figura se muestra la totalidad de los registros escalados, debe notarse que todos los valores se encuentran entre 0 y 1.
Asimismo, para la salida el valor 1 representa una colisión y el valor 0 representa que no hubo colisión.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Redes neuronales
oscarrosete.com
oscarrosete.com
Los aspectos de mayor relevancia de los modelos neuronales son, primeramente, sus arquitecturas, en segundo lugar, la tipología de las unidades de procesamiento, en tercer lugar, el tipo de conexiones de estas unidades o neuronas, en cuarto lugar, los paradigmas del aprendizaje, y para finalizar, la teoría de la información asociada a los algoritmos de aprendizaje.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
El primero de los aspectos nombrados son las arquitecturas, es decir, la forma de las conexiones entre las unidades neuronales.
Este aspecto se desarrollará en cursos posteriores enfatizando las similitudes entre las mismas y los modelos econométricos tradicionales. Su forma genera toda una familia de posibles modelos, cuya gran variedad obliga a la vertebración de los mismos mediante clasificaciones o taxonomías.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
En una primera aproximación, podemos encontrar una clasificación en función de la tipología del output que genera el modelo, divididos en:
modelos deterministas y modelos estocásticos
Redes neuronales artificiales


oscarrosete.com
oscarrosete.com
El segundo aspecto es la tipología existente en las unidades de procesamiento o neuronas. Existen neuronas visibles y neuronas ocultas (hidden).
Por neuronas visibles se entienden tanto los inputs (variables exógenas) como los outputs (variables endógenas).
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
En cambio las neuronas ocultas, poseen la función de capturar la representación interna de los datos.
Éstas pueden no estar conectadas directamente con las neuronas visibles.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
El tercer aspecto descansa en el tipo de conexiones que se establecen entre las unidades de procesamiento o neuronas.
Así tenemos, en primer lugar, los modelos que se propagan en una sola dirección, denominados feed-forward.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
En segundo lugar, los modelos recurrentes, cuyas conexiones se establecen en todas las direcciones incluso con procesos de realimentación, es decir, las propias neuronas consigo mismas.
Estas últimas son especialmente útiles para captar el comportamiento dinámico en presencia de retardos.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Una ANN entrenada es una red que ha aprendido de los ejemplos y ajustado sus pesos para predecir la clase de los nuevos ejemplos.
Para lograr el entrenamiento partimos de una red multicapa con una estructura dada y queremos encontrar los pesos de la red de manera que la función que calcula la red se ajuste lo mejor posible a los ejemplos.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Lo haremos mediante un proceso de actualizaciones sucesivas de los pesos, llamado algoritmo de retropropagación (backpropagation), basado en las mismas ideas de descenso por el gradiente que hemos visto con el perceptrón.
El procedimiento de entrenamiento y ajuste de pesos es parte del proceso de backpropagation, sin embargo comenzaremos con entender la propagación hacia delante.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
En la figura se muestra el procedimiento para utilizar o realizar una predicción con una red neuronal artificial entrenada.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Como se menciono previamente, los pasos involucrados en calcular los resultados para los nodos en una ANN son similares a los del perceptron.
Se ejecutan operaciones similares en múltiples nodos que trabajan en conjunto; esto resuelve posibles fallas en el perceptrón y permite resolver problemas de mayor complejidad.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
El flujo general de forward propagation incluye los siguientes pasos:
1. Ingresa un ejemplo—provee un ejemplo del conjunto de datos para el cual se quiera realizar la predicción.
2. Multiplica las entradas y los pesos—Multiplica cada entrada por cada peso de su conexión a los nodos ocultos.
3. Suma los resultados de las entradas con su respectivo peso para cada nodo oculto.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
El flujo general de forward propagation incluye los siguientes pasos:
4. Aplica la función de activación a las entradas con su peso aplicado.
5. Suma los resultados de los nodos ocultos.
6. Aplica la función de activación.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Con el propósito de explorar forward propagation, asumiremos que cada ANN ha sido entrenada y los pesos óptimos para cada red han sido encontrados.
La primer caja, tiene un peso de 3.35 relacionado al nodo de entrada de velocidad, -5.82 a calidad de terreno.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Las entradas de la ANN son definidas como X. Cada variable de entrada tendrá un numero identificador, la velocidad es X0, calidad del terreno X1, etc. La salida de la red sera Y, y los pesos W.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
El primer paso consiste en encontrar la sumatoria de las entradas por los pesos.
Redes neuronales artificiales
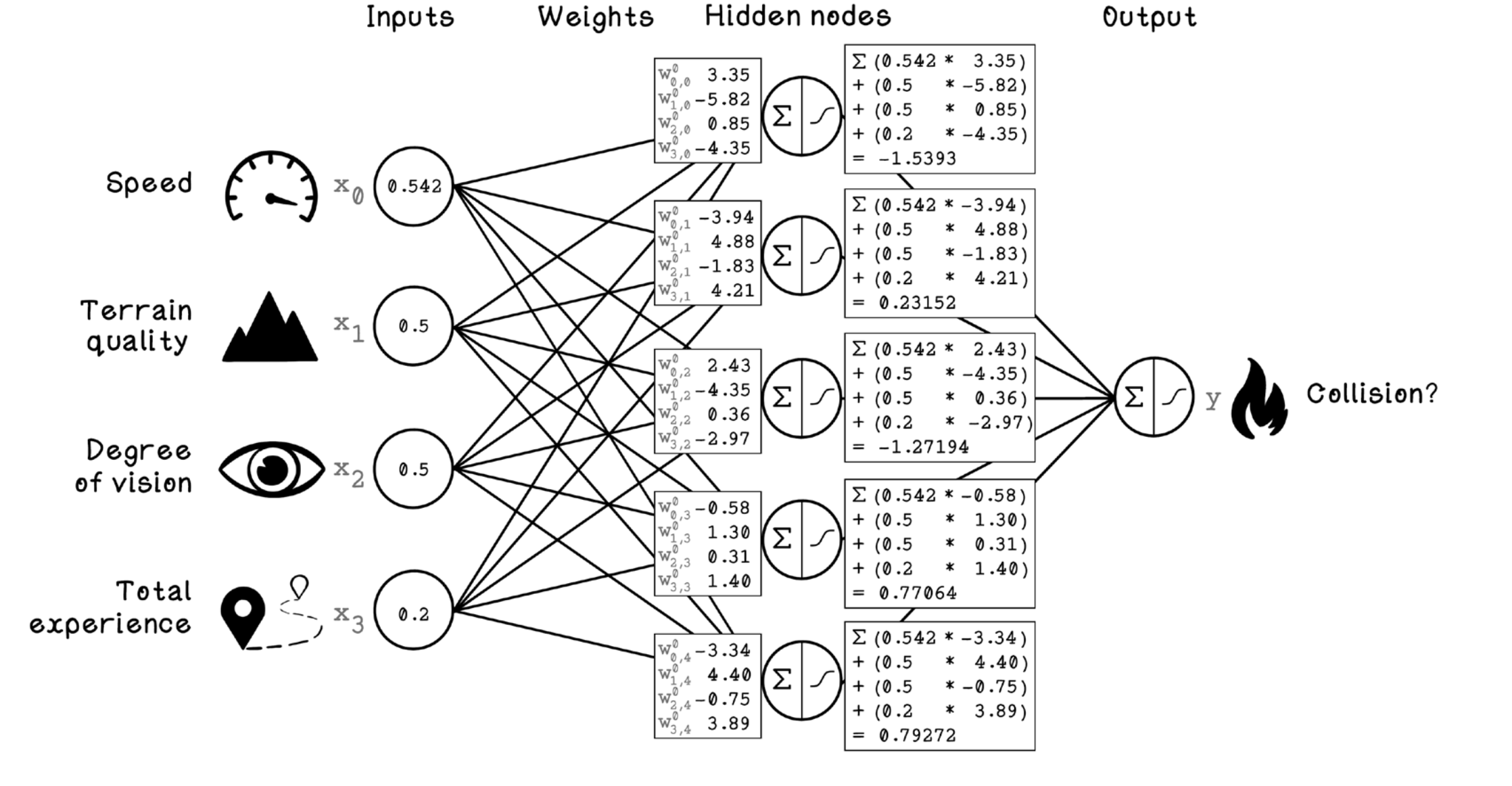
oscarrosete.com
oscarrosete.com
El siguiente paso es calcular el resultado de la función de activación para cada nodo oculto.
En el ejemplo se utiliza una función sigmoide.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
En la figura se muestran las activaciones de cada nodo oculto y los pesos de cada nodo oculto al nodo de salida, para calcular la salida final se suman los resultados de los nodos ocultos y se aplica la función sigmoidea de activación.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Nuestra predicción final para el ejemplo ha sido de 0.00214 (0.214%), la salida es un valor entre 0 y 1 que representa la probabilidad de que ocurra un choque.
Redes neuronales artificiales
oscarrosete.com
oscarrosete.com
Analicemos un segundo ejemplo
Redes neuronales artificiales


oscarrosete.com
oscarrosete.com
Calculo de función de suma en nodos de la capa oculta
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Al evaluar el ejemplo en nuestra red entrenada se obtiene un riesgo extremadamente alto de choque al ir a alta velocidad en mal terreno y mala visión.
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Redes Neuronales Artificiales
oscarrosete.com
oscarrosete.com
Clasificación
Guideline
diferencia rsquared meansquared
mediados siglo
complejo->\
union de partes pequeñas colaborando
redes neuronales-->pequeñas neuronas
neurona unidad basica de procesamiento
conexiones de entrada, estimulos externos o valores de entrada, calculo interno y genera valor de salido
Redes neuronales artificiales

oscarrosete.com
oscarrosete.com
Clasificación
la neurona es una funcion matematica
suma ponderada de los valores de entrada
peso de conexiones de entrada:de que manera cada variable de entrada afecta la neurona, como toggles para modificar postigvio o negativo las sumas
parametros del modelo
Redes neuronales


oscarrosete.com
oscarrosete.com
Clasificación
tenemos vr?
tenemos nachos?
prediccion
excelente dia o no
regresion lineal vs umbral -> 1 o 0
Redes neuronales



oscarrosete.com
oscarrosete.com
Clasificación
tenemos vr?
tenemos nachos?
prediccion
excelente dia o no
regresion lineal vs umbral -> 1 o 0
jugamos con params hasta encontrar la relacion adecuada
Redes neuronales


oscarrosete.com
oscarrosete.com
Clasificación
regresion lineal vs umbral -> 1 o 0
coompuerta and
Redes neuronales


oscarrosete.com
oscarrosete.com
Clasificación
regresion lineal vs umbral -> 1 o 0
coompuerta and
limitacion de una sola neurona cuando tenemos una operacion xor
Redes neuronales


oscarrosete.com
oscarrosete.com
Clasificación
multiples neuronas para resolver problemas mas complejos
un ultimo componente. la funcion de activacion para combinar neuronas y construir redes neuronales
Redes neuronales

oscarrosete.com
oscarrosete.com
La red neuronal
neuronas unidas, misma columna o misma capa
misma informacion de entrada de la capa anterior y lo que generne se va ala capa siguient
Redes neuronales

oscarrosete.com
oscarrosete.com
conocimiento jerarquizado.
dos variables de entrada, nachos y vr. una neurona si nos divertiremos o no
nota del siguiente examen?
Redes neuronales

oscarrosete.com
oscarrosete.com
conocimiento jerarquizado.
dos variables de entrada, nachos y vr. una neurona si nos divertiremos o no
nota del siguiente examen?
Redes neuronales

oscarrosete.com
oscarrosete.com
conocimiento jerarquizado.
motivacion baja, noche del viernes entretenida, estudies poco y salgas mal en el examen
mas capas , mas complejo conocimiento, aprendizaje profundo.
Redes neuronales

oscarrosete.com
oscarrosete.com
conocimiento jerarquizado.
conexiones secuenciales, problema de regresion lineal
concatenar lineas rectas son iguales a una sola operacion de una linea recta, colapsaria a una unica neurona. manipulacion no lineal que las distorisione(activacion)
Redes neuronales



