by Oscar Ivarsson
MongoDB

What is MongoDB?
Document-oriented
Design as scalable (humongous)
Open source
Released: 2009
What is MongoDB?

Commit count for Github repository
Why use NoSQL?

Why use NoSQL?
Cloud computing
Unstructured data
Agile development
Why use MongoDB?
Scalability?
Why use MongoDB?
Documents?
Why use MongoDB?
Ease of rapid application development
Data Model
{
name: "Egon",
age: 26,
status: "A",
groups: ["news", "sports"]
}JSON
5100 0000 0273 7461 7475 7300 0200 0000
4100 1061 6765 001a 0000 0002 6e61 6d65
0004 0000 0053 7565 0004 6772 6f75 7073
001f 0000 0002 3000 0500 0000 6e65 7773
0002 3100 0700 0000 7370 6f72 7473 0000
00BSON
Data Model
[
{
"_id" : ObjectId("55ee924b34ec1a858b481962"),
name: "Egon",
age: 26,
status: "A",
groups: ["news", "sports"]
},
{
"_id" : ObjectId("55ee924b34ec1a858b481963"),
name: "Orvar",
age: 23,
status: "B",
groups: ["education", "sports"]
},
{
"_id" : ObjectId("55ee924b34ec1a858b481964"),
name: "Alf",
age: 34,
status: "A",
groups: ["news"]
}
]Collection
CRUD Operations
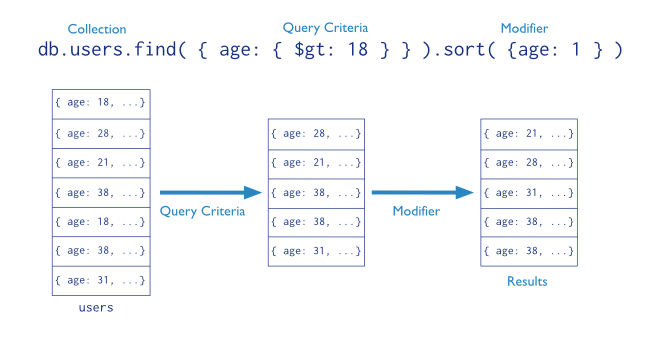
Query
CRUD Operations
HTTP REST API
curl -X GET "http://127.0.0.1:8080/my_database/my_collection/"var Cat = mongoose.model('Cat', { name: String });
var kitty = new Cat({ name: 'Zildjian' });
kitty.save();ODM
Scaling
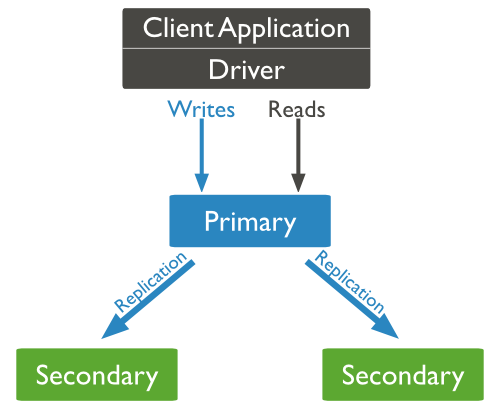
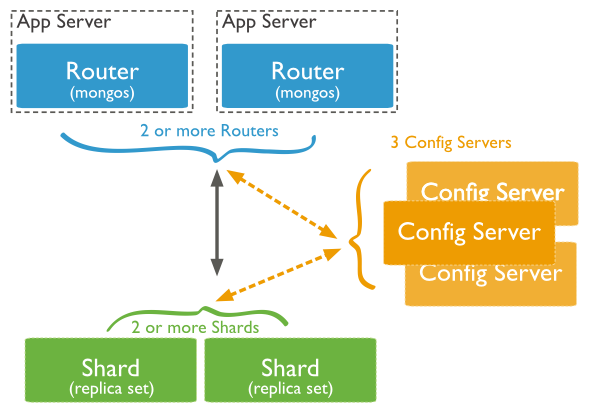
Replication
Sharding
Twitter Example
+ PyMongo
Twitter Example
Stream Listener
Streaming Time: 6 hours
Filtered with world coordinates:
- Longitude Southwest Corner: -180
- Latitude Soutwest Corner: -90
- Longitude Northeast Corner: 180
- Latitude Northeast Corner: 90
Twitter Example
Stream Listener
# Function listening to twitter messages
def on_data(data):
# Connect to Mongo instance, database, collection
client = MongoClient("localhost", 27017)
database = client["twitter_database"]
collection = database["twitter_collection"]
# Decoding string of twitter messages to JSON
tweets = json.loads(data)
collection.insert(tweets)Twitter Example
Twitter Data
{
"contributors": null,
"truncated": false,
"text": "@KristianBrodal what about now?!",
"is_quote_status": false,
"in_reply_to_status_id": 656758043300925440,
"id": 656762185281097732,
"favorite_count": 0,
"retweeted": false,
"coordinates": null,
"timestamp_ms": "1445419281679",
"lang": "en",
"created_at": "Wed Oct 21 09:21:21 +0000 2015",
"place": {
"country_code": "SE",
"country": "Sverige",
"place_type": "city",
"bounding_box": {
"type": "Polygon",
"coordinates": [
[
[
13.621107,
58.24702
],
[
13.621107,
58.595865
],
[
14.152948,
58.595865
],
[
14.152948,
58.24702
]
]
]
},
"full_name": "Skövde, Sverige",
"attributes": {},
"id": "8f7b18e7e397d055",
"name": "Skövde"
}
Twitter Example
We want to see where people tweet in Sweden!
Twitter Example
Looking at the collection
# Get collection stats
collection_stats = client["twitter_database"].command("collstats", "twitter_collection")Count: 1 106 789
Size: 4 616 MB
Avg document size: 4 065 KB
GPS coordinate distribution: 19.51%
Twitter Example
Creating a new collection
# Create new collection based on query criteria
client["twitter_db"]["twitter_collection_geo"].insert(
client["twitter_db"]["twitter_collection"].find({"coordinates":{"$ne": None}})
)
# Get collection stats
collection_stats = client["twitter_database"].command("collstats", "twitter_collection_geo")Count: 215 943
Size: 1 021 MB
Avg document size: 4 158 KB
GPS coordinate distribution: 100.0%
Twitter Example
How to know if a tweet is made in Sweden?
[
[ 22.18317345550193, 65.723740546320172 ], [ 21.21351687997722, 65.026005357515274 ],
[ 21.369631381930958, 64.413587958424287 ], [ 19.77887576669022, 63.609554348395037 ],
[ 17.847779168375212, 62.74940013289681 ], [ 17.119554884518124, 61.341165676510968 ],
[ 17.831346062906391, 60.636583360427409 ], [ 18.787721795332089, 60.081914374422595 ],
[ 17.86922488777634, 58.953766181058697 ], [ 16.829185011470088, 58.719826972073392 ],
[ 16.447709588291474, 57.041118069071885 ], [ 15.879785597403783, 56.104301866268663 ],
[ 14.666681349352075, 56.200885118222175 ], [ 14.100721062891465, 55.407781073622651 ],
[ 12.942910597392057, 55.361737372450577 ], [ 12.625100538797028, 56.30708018658197 ],
[ 11.787942335668674, 57.441817125063068 ], [ 11.027368605196868, 58.856149400459358 ],
[ 11.468271925511146, 59.432393296946039 ], [ 12.300365838274899, 60.117932847730032 ],
[ 12.631146681375185, 61.293571682370136 ], [ 11.992064243221563, 61.80036245385655 ],
[ 11.930569288794231, 63.128317572676977 ], [ 12.579935336973934, 64.066218980558332 ],
[ 13.571916131248713, 64.04911408146971 ], [ 13.919905226302204, 64.44542064071608 ],
[ 13.555689731509091, 64.787027696381514 ], [ 15.108411492583002, 66.193866889095474 ],
[ 16.108712192456778, 67.302455552836889 ], [ 16.768878614985482, 68.013936672631402 ],
[ 17.729181756265348, 68.010551866316277 ], [ 17.993868442464333, 68.567391262477358 ],
[ 19.878559604581255, 68.407194322372575 ], [ 20.025268995857886, 69.065138658312705 ],
[ 20.645592889089528, 69.106247260200874 ], [ 21.978534783626117, 68.616845608180697 ],
[ 23.539473097434438, 67.93600861273525 ], [ 23.565879754335583, 66.396050930437426 ],
[ 23.903378533633802, 66.006927395279618 ], [ 22.18317345550193, 65.723740546320172 ]
]Polygon
[
[10.634765625, 54.9776136707],
[24.4775390625, 69.115611065]
]Box
Twitter Example
Find tweets
# Find all tweets within Sweden polygon
tweets = client["twitter_db"]["twitter_collection_geo"].find(
{"coordinates": {"$geoWithin": {"$geometry": SWEDEN_POLYGON}}}
)Count: 470
Time: 481 MS
Twitter Example
Indexing
# Create geospatial indexing in the collection
client["twitter_db"]["twitter_collection_geo"].ensure_index([("coordinates", GEOSPHERE)])
# Find all tweets within Sweden polygon
tweets = client["twitter_db"]["twitter_collection_geo"].find(
{"coordinates": {"$geoWithin": {"$geometry": SWEDEN_POLYGON}}}
)Count: 470
Time: 3 MS
Twitter Example
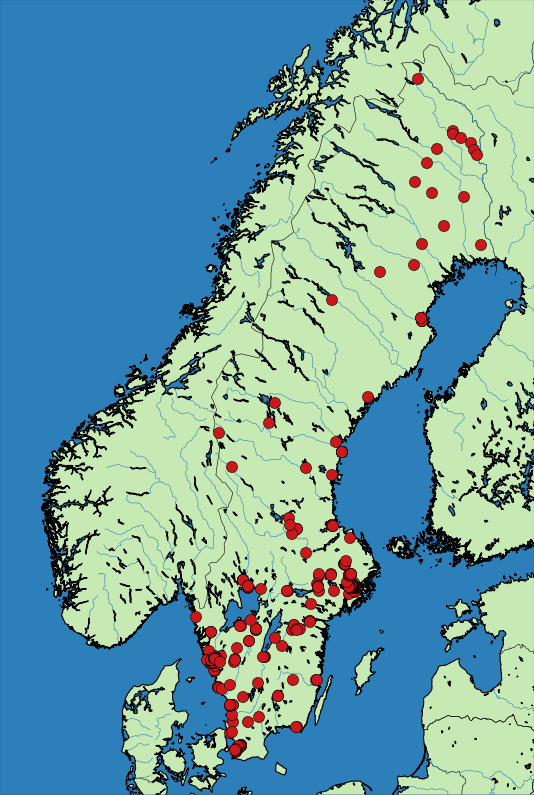
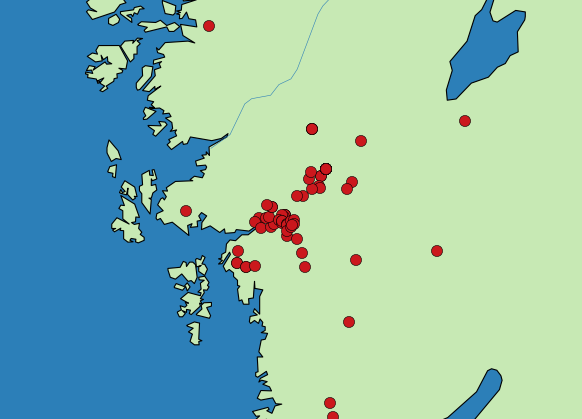
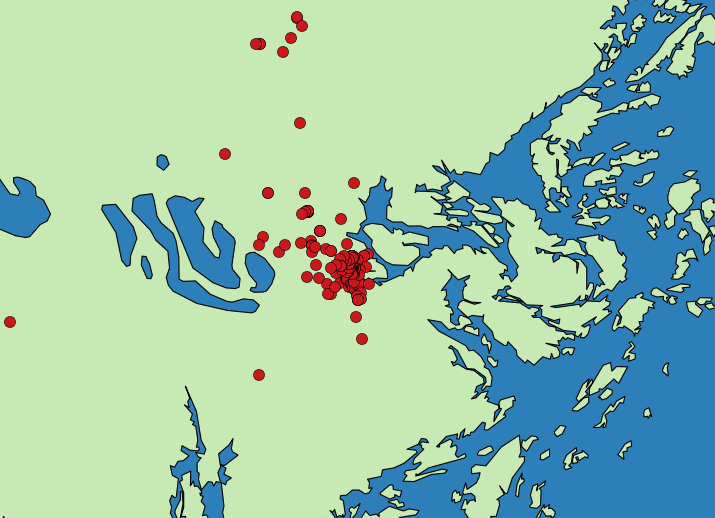
Stockholm
Gothenburg
Twitter Example
We want to know the places where people tweet most!
Twitter Example
MapReduce
{
"place": {
"place_type": "city",
"country": "Sweden",
"name": "Stockholm"
}
}Map
{
"place": {
"place_type": "city",
"country": "Sweden",
"name": "Gothenburg"
}
}{
"place": {
"place_type": "city",
"country": "Norway",
"name": "Oslo"
}
}{
"Sweden": {
"count": 1
}
}Reduce
{
"Sweden": {
"count": 1
}
}{
"Norway": {
"count": 1
}
}{
"Norway": {
"count": 1
}
}{
"Sweden": {
"count": 2
}
}Twitter Example
map_func = '''
function() {
emit(this.place.country, {
count: 1,
});
}
'''Map
reduce_func = '''
function(key, values) {
var result = {
count: 0,
};
values.forEach(function(value) {
result.count += value.count;
});
return result;
}
'''Reduce
# Perform MapReduce for calculating aggregated values for countries
country_count = client['twitter_db']['twitter_collection'].map_reduce(
map_func,
reduce_func,
out = "countries",
query = {"place": {"$ne": None}},
)
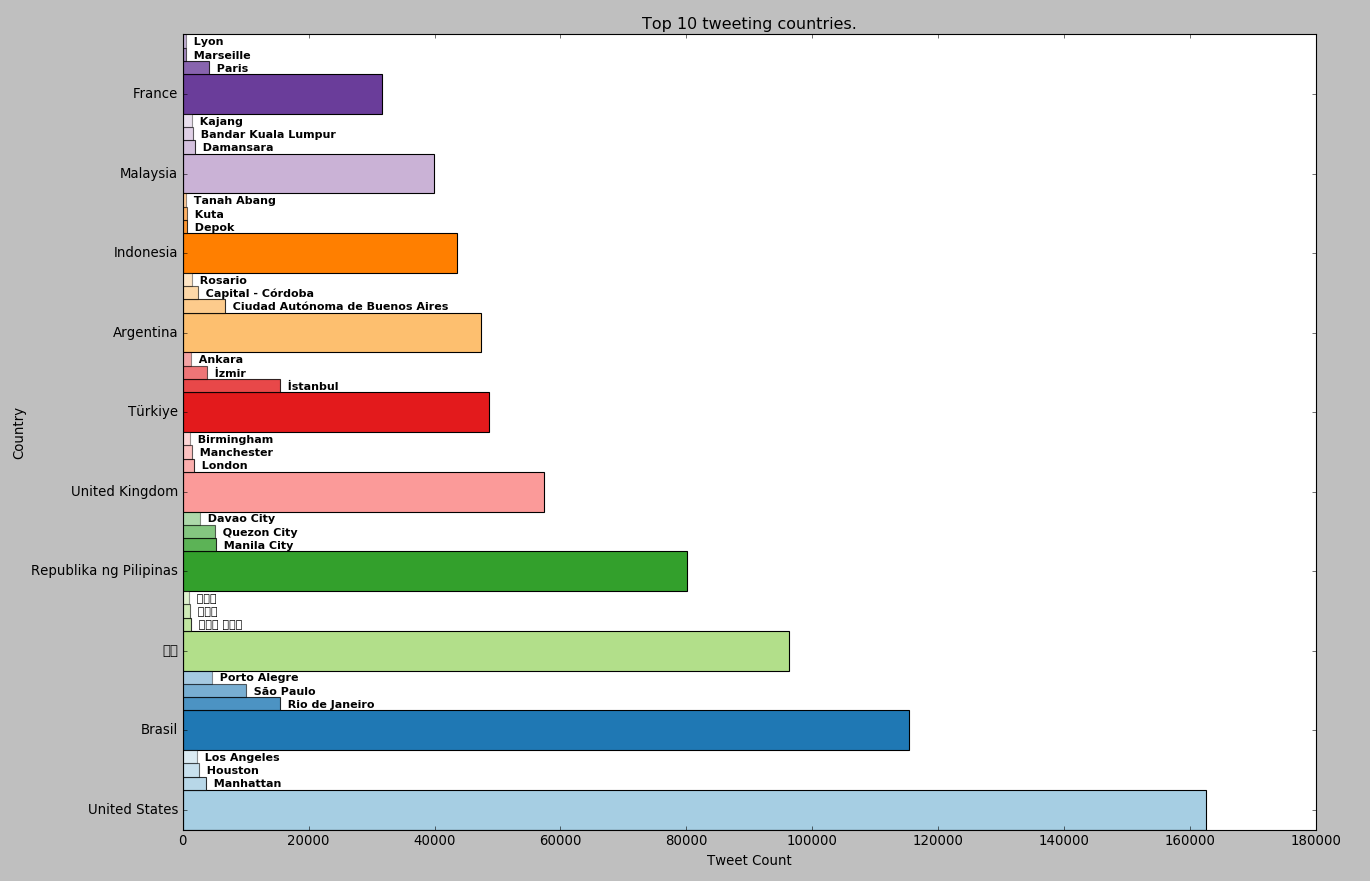
# Get top 10 most tweeting countries
result = country_count.find().sort("value.count", DESCENDING).limit(10)MapReduce
Twitter Example
Questions
?