A Deep Reinforcement Learning
Approach to Traffic Management
By Osvaldo Castellanos

Motivation
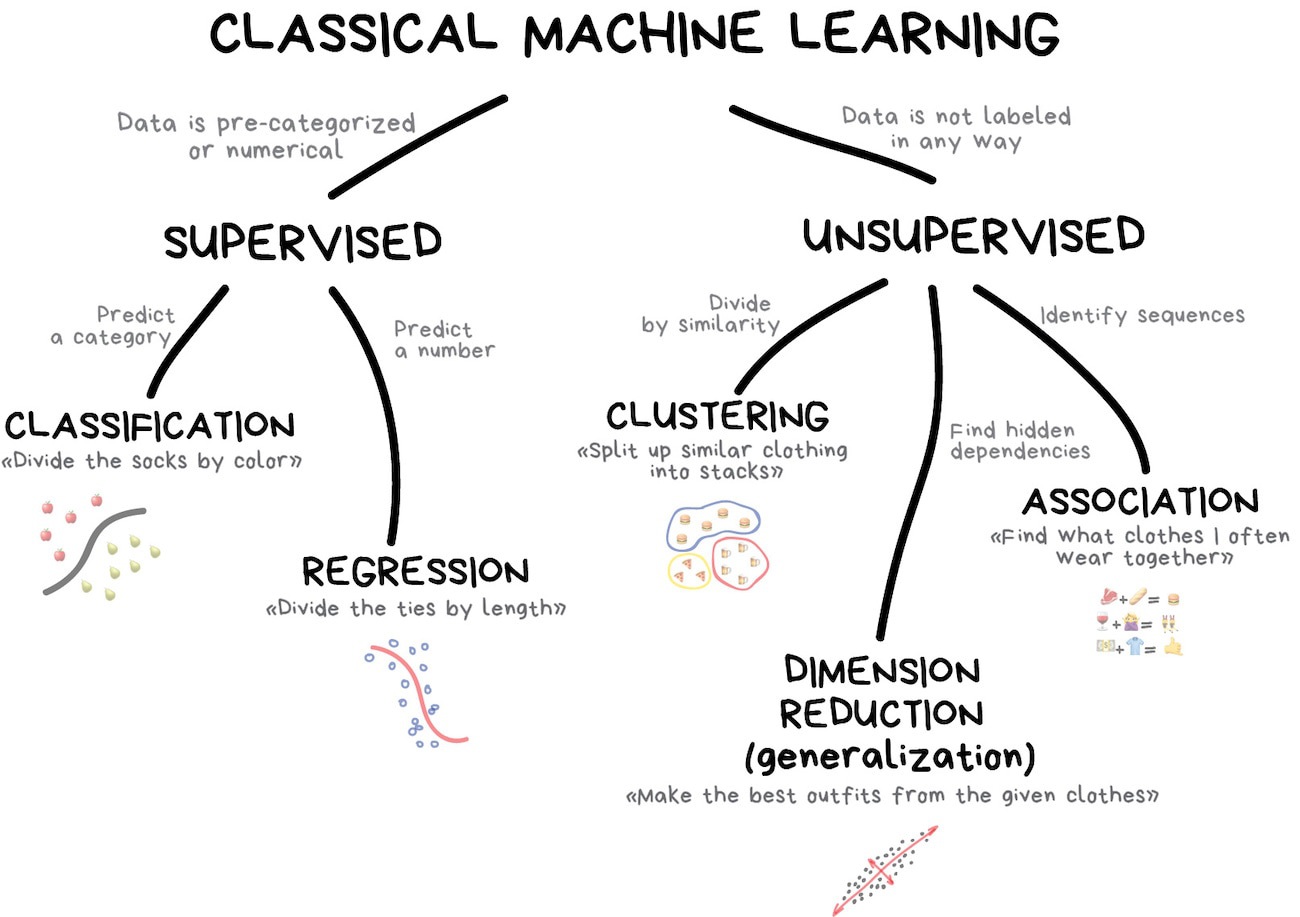
Ref: Machine Learning for Everyone

Ref: https://xkcd.com/1838/
RL Model
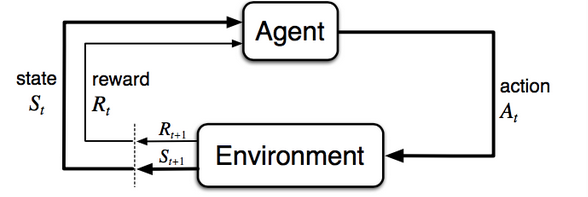
Ref: https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#what-is-reinforcement-learning
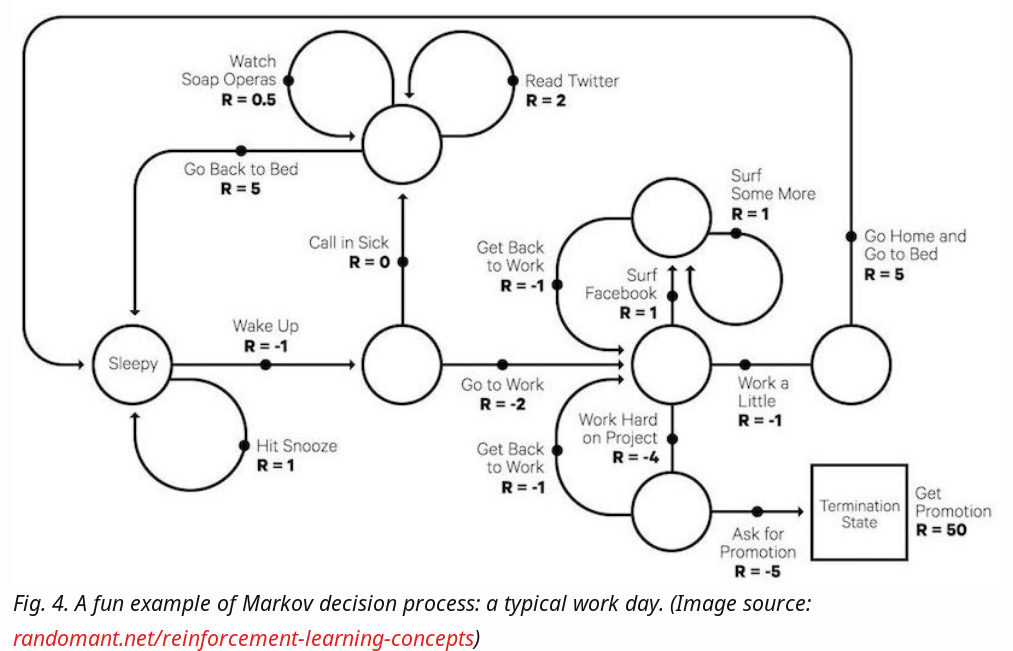
Markov Decision Processes
Ref: https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#what-is-reinforcement-learning
Important Concepts:


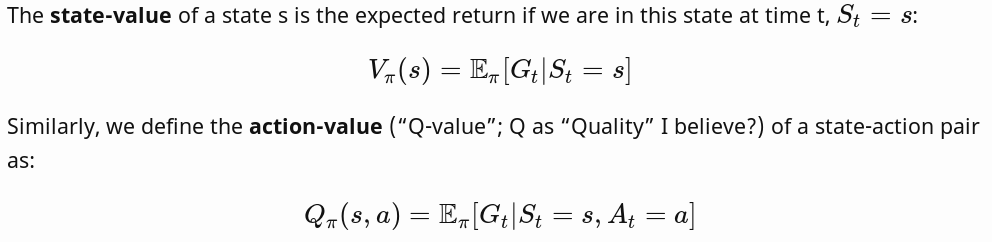
Ref: https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#what-is-reinforcement-learning

Ref: https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#what-is-reinforcement-learning
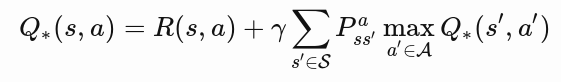
Ref: https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#what-is-reinforcement-learning
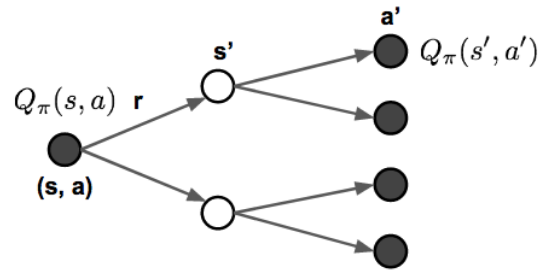
Backup Diagram
Ref: https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
A Taxonomy of RL Algorithms

Ref: Spinning up RL
Approaches:
- Dynamic Programming
- Policy Evaluation
- Policy Improvement
- Policy Iteration
- Monte-Carlo Methods
-
Temporal-Difference Learning
- SARSA: On-Policy TD
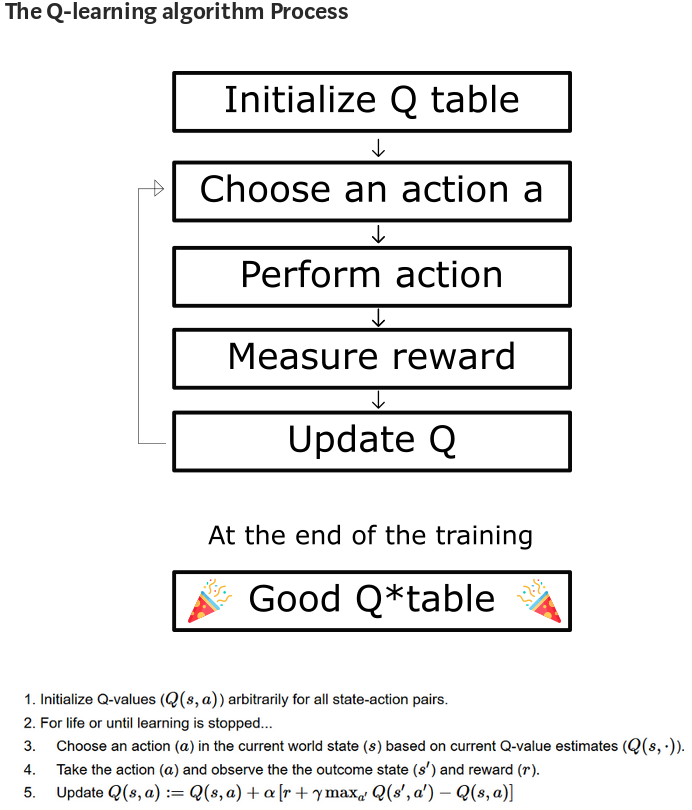
- Q-Learning: Off-Policy TD
- Deep Q-Network
Deep Q-Network
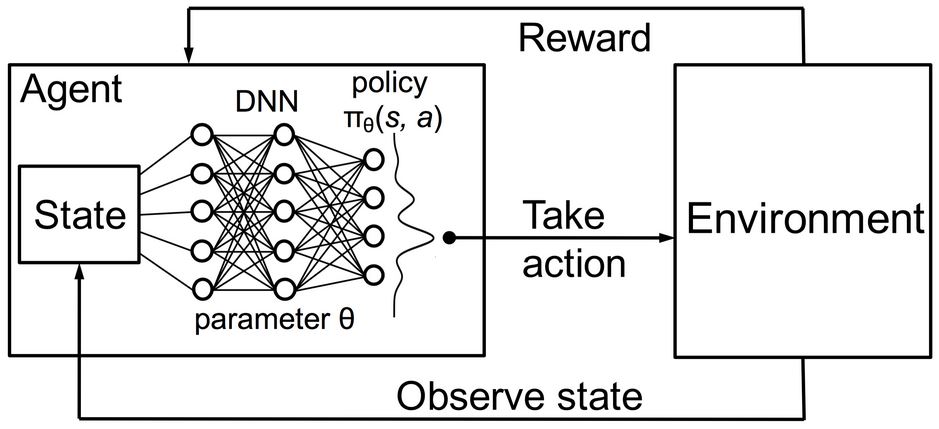
Ref: URL: https://2.bp.blogspot.com/-bZERYUNyjao/Wa98yt7GjhI/AAAAAAAACt8/SYQjUNrbe1YDtKTMKR6LPt68C0pPqkoowCLcBGAs/s1600/DRL.JPG
import gym
env = gym.make("CartPole-v1")
env = gym.wrappers.Monitor(env, "cart-pole")
observation = env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample() # your agent here (this takes random actions)
observation, reward, done, info = env.step(action)
if done:
observation = env.reset()
env.close()OpenAI Gym
Main Functions Needed in a Custom Environment to Interface with Gym:
- Reset
- Step
- Render
Step returns:
- next state
- reward
- done
- info
import numpy as np
import os
import gym
from gym import error, spaces
from gym import utils
from gym.utils import seeding
from gym_traffic.envs import traffic_simulator
import pygame
class TrEnv(gym.Env):
metadata = {'render.modes': ['human', 'rgb_array']}
def __init__(self):
self.sim = traffic_simulator.TrafficSim()
self.action_space = spaces.Discrete(n=2)
self.observation_space = spaces.Box(low=0, high=1, shape=(4,7), dtype=np.uint8)
def step(self, action):
ob, reward, done, signal = self.sim.step(action)
return ob, reward, done, signal
def _get_obs(self):
return self.sim.getGameState()
def reset(self):
self.sim.reset()
return self.sim.getGameState()https://github.com/oscastellanos/gym-traffic/blob/master/gym_traffic/envs/TrEnv.py

Ref: https://www.pygame.org/wiki/about
- Does not require OpenGL
Multi core CPUs can be used easily-
Uses optimized
C, and Assembly code for core functions.
traffic_simulator.py
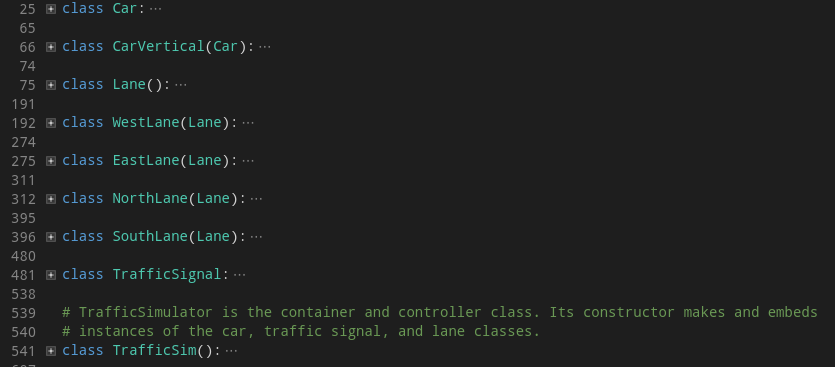
https://github.com/oscastellanos/gym-traffic/blob/master/gym_traffic/envs/traffic_simulator.py
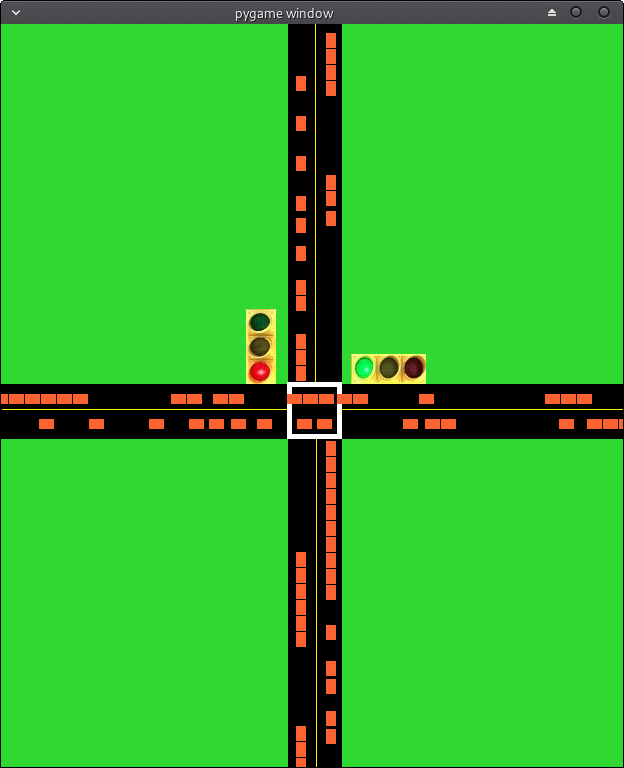

"Deep Reinforcement Learning for Traffic Light Control in Vehicular Networks," Liang et al., (2018), arxiv.org/abs/1803.11115
Ref: https://openai.com/blog/faulty-reward-functions/
| State | Action | Reward |
|---|---|---|
| Position of cars per lane. Up to 7 cars, bumper-to-bumper |
0 - Horizontal Lane is green, Vertical is Red 1 - Horizontal is Red, Vertical is Green |
r = W(t) - W(t+1) |
- Intersections consist of different statuses.
- Complex behavior such as "Left turn on green," etc. require their own status
- The time duration at one status is called a phase. The number of phases is decided by the number of legal statuses.
- In the Liang et al. paper, a cycle consists of phases with fixed sequences, but the duration of every phase is adaptive.
"Deep Reinforcement Learning for Traffic Light Control in Vehicular Networks," Liang et al., (2018), arxiv.org/abs/1803.11115
# Position Matrix Velocity Matrix
# Vehicles Heading East
([(array([[0., 0., 0., 0., 0., 0., 0.]]), array([[0., 0., 0., 0., 0., 0., 0.]])),
# Vehicles Heading West
(array([[0., 0., 0., 0., 0., 0., 0.]]), array([[0., 0., 0., 0., 0., 0., 0.]])),
# Vehicles Heading North
(array([[0., 0., 0., 0., 0., 0., 0.]]), array([[0., 0., 0., 0., 0., 0., 0.]])),
# Vehicles Heading South
(array([[0., 0., 0., 0., 0., 0., 0.]]), array([[0., 0., 0., 0., 0., 0., 0.]]))],
# Current Total Reward of Episode
0,
# Is the episode done?
False)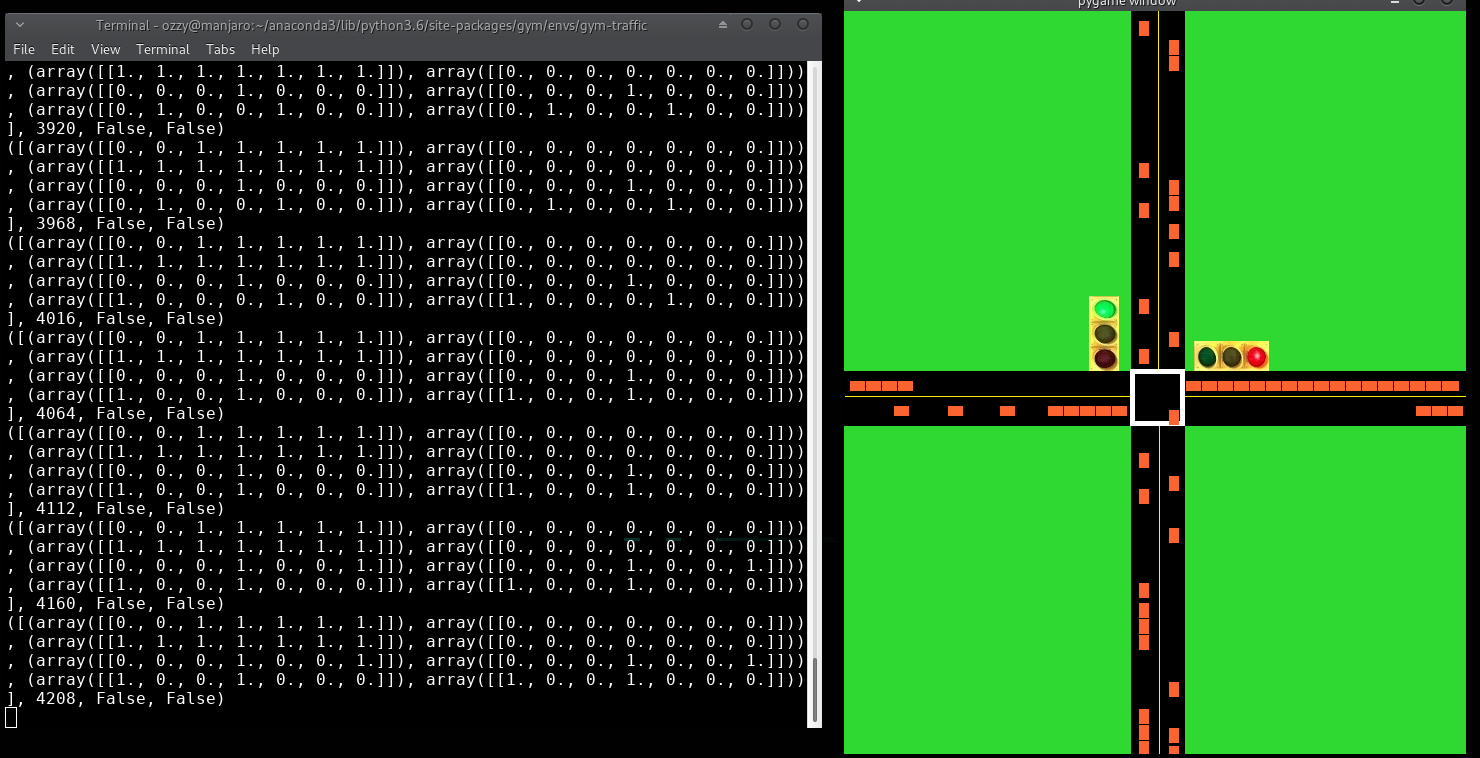

Ref: https://github.com/sarcturus00/Tidy-Reinforcement-learning/blob/master/Pseudo_code/DQN.png
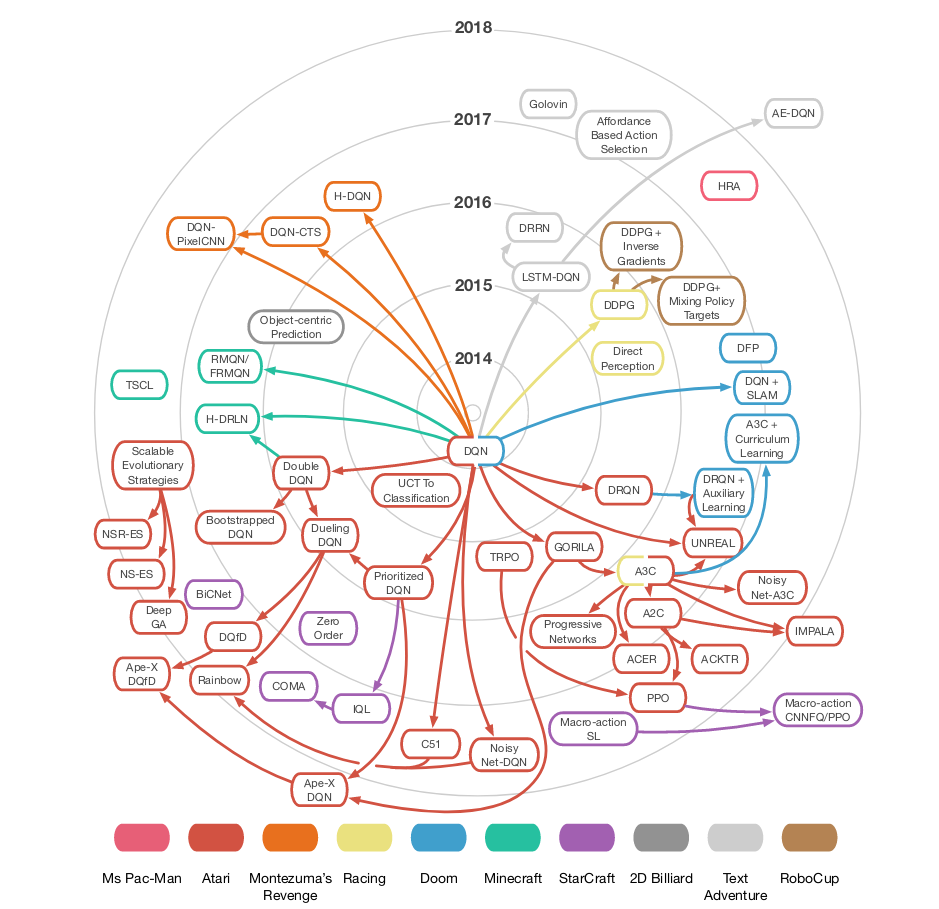
"Deep Learning for Video Game Playing," Justesen et al. (2019), arxiv.org/pdf/1708.07902.pdf
"Deep Reinforcement Learning for Traffic Light Control in Vehicular Networks," Liang et al., (2018), arxiv.org/abs/1803.11115
A To-Do list of upcoming changes to simulator/environment:
- Refactor traffic-simulator.py
- Add docstrings to methods
- Include more statuses at an intersection
- Extend to multiple lanes
- Implement render in environment, add compatibility to monitor class of gym
- Add tensorboard summaries for variables
For the Poster:
- Finish implementing DQN
- Adaptive phase duration
- Implement DDQN
- Add more graphs/results comparing random, fixed-timer, DQN, and DDQN
Final report:
- Implement multi-agent reinforcement learning for multiple intersections
- Add randomness to the environment by closing lanes for a period of time.
References:
- "Deep Reinforcement Learning for Traffic Light Control in Vehicular Networks," Liang et al., (2018), arxiv.org/abs/1803.11115
- Machine Learning for Everyone : https://vas3k.com/blog/machine_learning/
- A (Long) Peek into Reinforcement Learning by Lilian Weng : https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#what-is-reinforcement-learning
- OpenAI Spinning Up : https://spinningup.openai.com/en/latest/spinningup/rl_intro.html
- Understanding RL: The Bellman Equations by Josh Greaves : https://joshgreaves.com/reinforcement-learning/understanding-rl-the-bellman-equations/
- OpenAI Gym basics: https://katefvision.github.io/10703_openai_gym_recitation.pdf
- Diving Deeper into Reinforcement Learning with Q-Learning : https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
Recommendations:
-
UCL Course on RL by David Silver : http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
THANK YOU!