演算法與資料結構
by oToToT
演算法和資料結構是死的,但是人是活的
What is Algorithm
Algorithm is an unambiguous specification of how to solve a class of problems. Algorithms can perform calculation, data processing and automated reasoning tasks.
An algorithm is an effective method that can be expressed within a finite amount of space and time and in a well-defined formal language for calculating a function.
from Wikipedia
What is Data Structure
In computer science, a data structure is a particular way of organizing and storing data in a computer so that it can be accessed and modified efficiently.
from Wikipedia
複雜度
Big-O 的定義
Big-Omega 的定義
Big-Theta 的定義
閒聊:主定理
若是有一條如 \( T(n)=aT({\frac {n}{b}})+f(n) \) 形式的遞迴式(其中 \( a \geq 1, b>1 \) )
Case 1: \( \exists \epsilon > 0, f(n)=O(n^{{\log _{b}(a)-\epsilon }}) \) ,則 \( T(n)=\Theta (n^{{\log _{b}a}}) \)
Case 2: \( \exists k \geq 0, f(n)=\Theta(n^{{\log _{b}a}}\log ^{{k}}n) \) ,則 \( T(n)=\Theta (n^{{\log _{b}a}}\log ^{{k+1}}n) \)
Case 3: \( \exists \epsilon > 0, f(n)=\Omega(n^{{\log _{b}(a)+\epsilon }}) \land \exists c < 1, af({\frac {n}{b}})\leq cf(n) \) ,則 \( T(n)=\Theta (f(n)) \)
來聊聊排序吧
\( O(n^2) \)的那些演算法們
- Selection sort:每次從沒排序的序列中把最小值找出來,並將他加至排序好的序列尾端
- Insertion sort:把序列每個元素依序插入至對的位置
- Bubble sort:每次都把相鄰兩個數中比較小的往後移,會發現最後就會把整個序列排完
\( O(n \log n) \)的那些演算法們
- Merge Sort:若你有兩個排序好的序列,那我們可以每次把最小值拿出來放到結果序列裡,那我們就完成合併兩個已排序的序列了。接著對於給定的序列,我們就先把它拆成兩半,分別對這兩半再做排序即可
- Quick sort:
- Heap sort:每次都把相鄰兩個數中比較小的往後移,會發現最後就會把整個序列排完
待補完
基於比較的排序演算法下界
- Merge Sort:若你有兩個排序好的序列,那我們可以每次把最小值拿出來放到結果序列裡,那我們就完成合併兩個已排序的序列了。接著對於給定的序列,我們就先把它拆成兩半,分別對這兩半再做排序即可
- Quick sort:
- Heap sort:每次都把相鄰兩個數中比較小的往後移,會發現最後就會把整個序列排完
待補完
與值域相關的排序演算法
- Counting Sort:若你有兩個排序好的序列,那我們可以每次把最小值拿出來放到結果序列裡,那我們就完成合併兩個已排序的序列了。接著對於給定的序列,我們就先把它拆成兩半,分別對這兩半再做排序即可
- Radix sort:
待補完
基礎資料結構
Stack
Stack支援兩種操作push跟pop,其中push代表把資料放進去,pop則是把最後放進去的資料拿出來。
class Stack{
private:
int container[MAXN];
int pos;
public:
Stack(){pos=0;}
void push(int x){
container[pos++]=x;
}
int pop(){
return container[--pos];
}
};#include <stack>
using std::stack;
int main(){
stack<int> sk;
sk.push(5);
sk.top();
sk.pop();
return 0;
}Queue
Queue支援兩種操作push跟pop,其中push代表把資料放進去,pop則是把最先放進去的資料拿出來。
class Queue{
private:
int container[MAXN];
int front, back;
public:
Queue(){front=0;back=0;}
void enqueue(int x){
container[back]=x;
back=(back+1)%MAXN;
}
int dequeue(){
int ret = container[front];
front = (front-1+MAXN)%MAXN;
return ret;
}
};#include <queue>
using std::queue;
int main(){
queue<int> qu;
qu.push(5);
qu.front();
qu.pop();
return 0;
}題外話:Dynamic Array
有時候我們不會預先資到資料筆數,那只能動態開記憶體,但是要怎樣才能有效的平衡時間與空間呢?
class DynamicArray{
private:
int* arr;
int back, size;
public:
DynamicArray(){
arr=new int[1];
back=0;
size=1;
}
void push_back(int x){
if(back == size){
int* nxt = new int[2*size];
for(int i=0;i<size;i++) nxt[i]=arr[i];
delete[] arr;
arr = nxt;
}
arr[back++]=x;
}
int operator[](int pos){
return arr[pos];
}
};#include <vector>
using std::vector;
int main(){
vector<int> vr;
vr.push_back(5);
vr[0];
return 0;
}Linked-List
我想要快速的插入某個東東怎麼辦?
class Linked_List{
private:
Node* head;
public:
struct Node{
int data;
Node* next;
Node(){next=nullptr;}
}
Linked_List(){head=new Node;}
Node* find(int v){
Node* cur = head;
while(cur != nullptr){
if(cur->data == v) break;
cur = cur->next;
}
return cur;
}
Node* insert(Node* ptr, int v){
Node* nw = new Node;
nw->data = v;
nw->next = ptr->next;
ptr->next = nw;
}
};#include <list>
using std::list;
int main(){
list<int> lt;
for (int i=1; i<=5; ++i) lt.push_back(i);
list<int>::iterator it = lt.begin();
it++;
lt.insert(it, 10);
return 0;
}樹
樹?

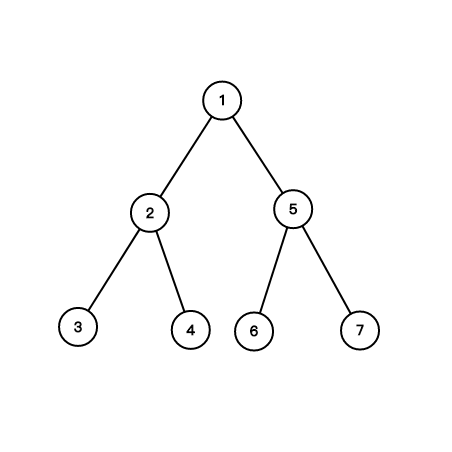
樹?
簡單定義:沒有環的連通圖
圖?
環?
連通?

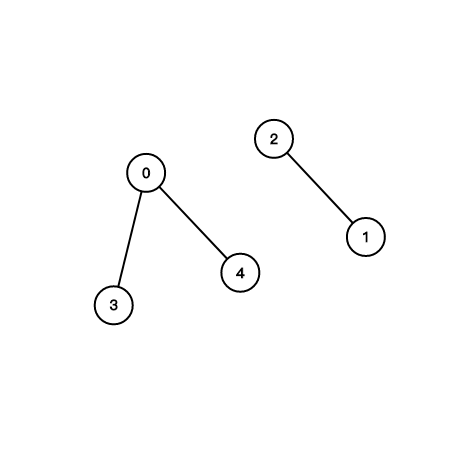
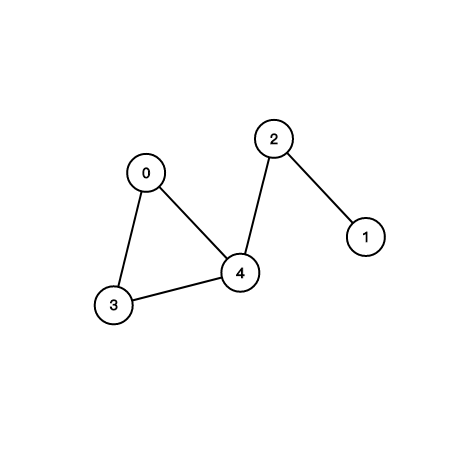
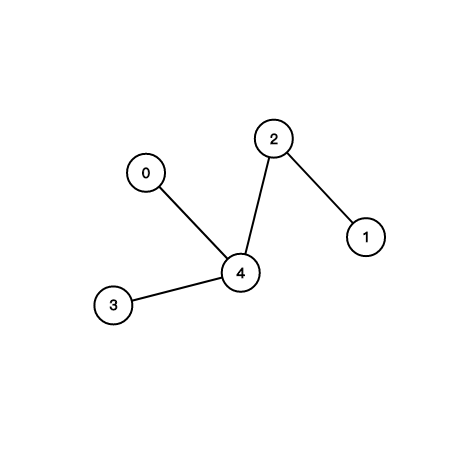
一些專有名詞
- 節點(node)
- 邊(edge)
- 根節點(root)
- 葉節點(leaf)
- 父節點(parent)
- 子結點(child)
- 祖先(ancestor)
- 子代(descendant)
- 子樹(subtree)
- 高度(height)
- 深度(depth)
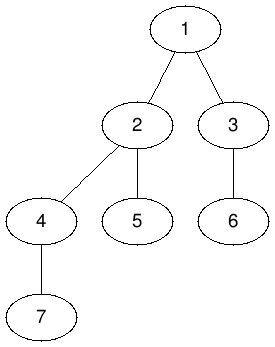
樹的小性質
- 任一點都可以當根(?
- 樹上任意兩點必定只存在一條最短路徑
- 一個 \( N \) 個節點的樹,其邊數恰好為 \( N-1 \)
把樹存起來
#include <vector>
using namespace std;
struct Node{
int data;
vector<Node*> cld;
};
int main(){
Node* root = new Node();
return 0;
}#include <vector>
const int MAXN = 1000;
int data[MAXN];
vector<int> chd[MAXN];
int main(){
return 0;
}樹與資料結構 - 二元樹
如果我們要找某個東西在不在一堆資料裡面該怎麼做?
若資料有大小關係,則我們可以透過他們的大小關係來見出一棵二元樹
不過要注意若沒有做某種調整,查詢的時間複雜度有可能會變得很大,未來的課程可能會提到一些平衡二元樹的資料結構。
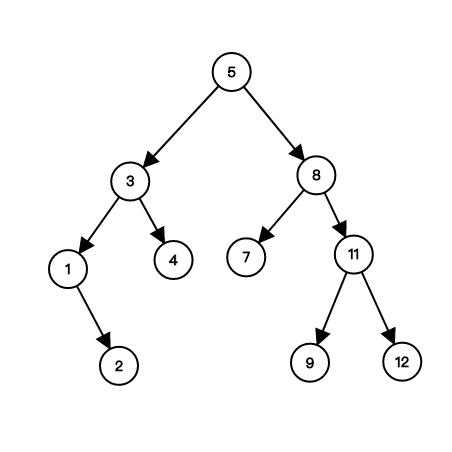
樹與資料結構 - 二元堆
如果我們有一堆資料,而他們每個都有優先度,我們想每次都取出具有最高優先度的資料,並且可能還會動態新增資料的時候該怎麼辦呢?
不妨維護一棵二元樹,並且任意節點的父節點都比他大,那根節點必定會是最大值。
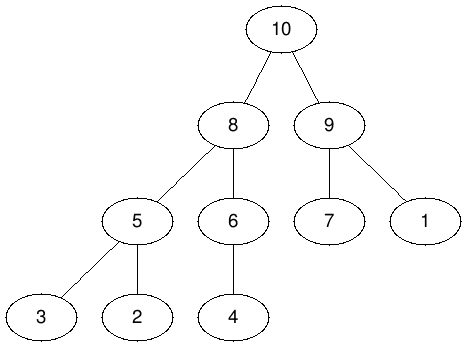
二元堆好麻煩 - 分塊
有時候當資料數量不多的時候我們會有點懶惰,不太想寫一棵樹,那我們這時候可以考慮分塊的想法。
分塊取最大值的想法是我們先將整個序列分成\( k \)塊,每一塊都是由大到小排序好的,那要查最大值就只要看看每塊的開頭就好,刪除也一樣,把最大的刪掉後,再從最後一塊拿一個元素過來填好就好了。
通常找最大值跟移除最大值操作次數差不多時會取 \( k = \sqrt{n} \)
| 2 | 1 | 8 | 3 | 7 | 4 | 6 | 5 |
|---|
基礎圖論
那些專有名詞們
- 圖:由點和邊所組成的一個集合(?
- 邊:連接兩個點的一個關係
- 點:一個物件,現實生活中許多事物都可以當作點(?
- 有向邊:若兩點間的關係是有限定方向的,那哪組關係會視為有向的
- 無向邊:若兩點間有關係,且無限定方向
- 重邊:兩個點之間有多個一樣的關係
- 自環:自己跟自己有某種關係
- 度:和某個點相接的邊的數量
- 入度:以某個點作為結尾的邊的數量
- 出度:以某個點作為起點的邊的數量
那些專有名詞們
- 權重:有時候點或邊上會有某種數值,例如邊上可能會有距離
- 路徑:由一組頭尾相鄰的邊所組成的集合
- 路徑長:一個路徑上所有邊的權重和
- 環:起點終點相同的路徑
- 有向圖:圖上的邊是具有方向性的
- 無向涂:圖上的邊不具有方向性
- 連通圖:圖上任一兩點都有路徑相連
- 完全圖:圖上任一兩點都有邊相連
- 有向無環圖(DAG):一個不具有環的有向圖
來把圖存下來吧
方法一:鄰接矩陣
假設有一個\( V \)個點的圖,我們不妨開一個\( V \times V \)的二維陣列\( gph[V][V] \),而其中若 \( i, j \)有相接,則\( gph[i][j]=1 \),若是有權重\( w \) 的話,則變成 \( gph[i][j]=w \)
新增邊、刪除邊、詢問邊、的複雜度都是\( O(1) \)
空間複雜度則為\( O(V^2) \)
遍歷所有與\( v \)相鄰的邊的複雜度:\( O(V) \)
| 0 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 1 |
來把圖存下來吧
方法二:鄰接串列
直接紀錄每個點連接到那些其他的點,可以採用linked list或是大部分時候會直接使用vector。
查詢有邊無邊的複雜度退化為\( O(deg(v)) \)
新增邊複雜度還是 \( O(1) \)
空間複雜度 \( O(V+E) \)
遍歷所有與\( v \)相鄰的邊的複雜度:\( O(deg(V)) \)
| 0 | 1 | 2 | |
| 1 | 3 | 2 | |
| 2 | |||
| 3 | 1 | 0 |
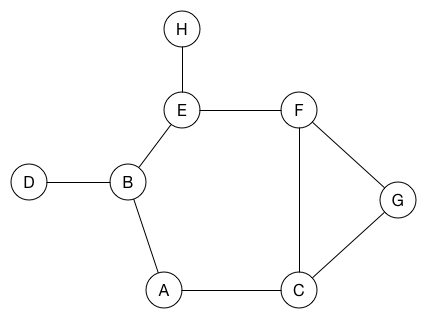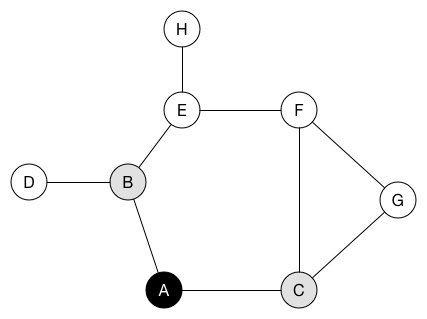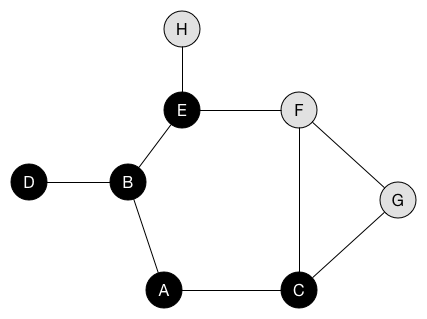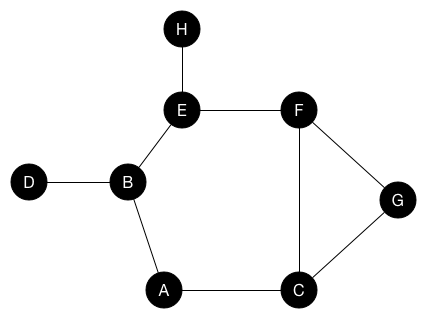
深度優先搜索(DFS)
選定一個點當作起點,不斷的往與他相鄰的點走下去,直到所有點都不能走為止
動畫示意:https://www.cs.usfca.edu/~galles/visualization/DFS.html
實作上通常利用遞迴的特性實作,或是使用stack
vector<int> gph[N]
bool vis[N];
void dfs(int u){
if(vis[u]) return;
vis[u] = true;
for(int v : gph[u]) dfs(v);
}
void dfs2(int u){
stack<int> stk;
stk.push(u);
while(!stk.empty()){
int u = stk.top(); stk.pop();
if(vis[u]) continue;
vis[u] = true;
for(int v: gph[u]) stk.push(v);
}
}廣度優先搜索(BFS)
選定一個點當作起點,先將其相鄰的點皆遍歷完後再繼續遍歷其他點,實作上通常使用queue
vector<int> gph[N]
bool inq[N];
void bfs(int x){
queue<int> qq;
qq.push(x);
while(!qq.empty()){
int u = qq.front(); qq.pop();
for(int v: gph[u]){
if(!inq[v]) qq.push(v);
inq[v] = true;
}
}
}
連通塊判定
給你一張無向圖,要怎麼看他有幾個連通塊,或是是否全部連通呢?
採用BFS或DFS,將所有點遍歷過,在一次遍歷中可以遍歷到的那群點就會是一個連通塊。
bool vis[N];
int count = 0;
for(int i=0;i<N;i++){
if(!vis[i]){
count++;
dfs(i);
}
}經典問題:二分圖判定
先來定義二分圖:一個無向圖中的點可以被分成兩個集合,使得同 集合內的點互不相鄰
那其實發現對於一條邊,他連接的兩個頂點必不在同個集合內,所以不妨枚舉隨意一個點,把它放在集合一,他相鄰的必在集合二,他相鄰相鄰的又必在集合一,用BFS或DFS都可做到,而若過程中出現矛盾的情形,則該圖必不為二分圖。
int id[N];
vector<int> G[N];
bool check(int u, int cur){
int nxt = (cur+2)%2 + 1;
id[u] = cur;
for(int v: G[u]){
if(id[v] == nxt) continue;
if(id[v] == cur or !check(v, nxt)) return false;
}
return true;
}枚舉
枚舉的用途
- 知道的越多,能做的越多
- 如果只有有限個關鍵,那麼不妨一一枚舉!
- 優點:絕無遺漏、不求他人
- 缺點:錯殺一百、難敵無限
待補完
分治
來想想一個經典(?的問題
你有一個缺一個點的\( 2^ 3 \times 2^ 3 \)的棋盤,你想用多個大小為三的L型方塊填滿,問你可否填滿?並且請給出填滿之方式。

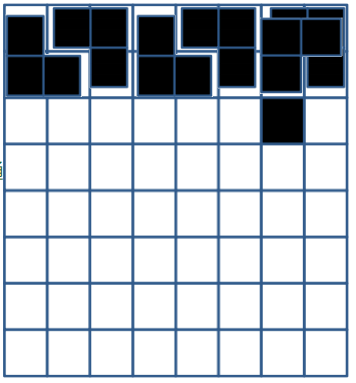
看起來不能枚舉
稍微想想會發現似乎無法使用枚舉的方法,因為方法可能會太多
那這時不妨先想想比較小的問題,一個\( 2^1 \times 2^1 \)的問題應該會做吧

會做\( 2^1 \times 2^1 \)的情況了,那能否把它推廣到大一點的情況呢?

我們是否有某種解法可以讓他與\( 2^1 \times 2^1 \)的方法長得很像呢?
分治
故名思義:分而治之,對於一個太大的問題,我們不妨把它切割後,變成由許多小問題組合而成,直到問題小到我們能輕鬆解決。
實作通常採用遞迴,因為遞迴的時候會保存好每個時期的變數與其狀態,但還是需注意要避免遞迴過深或記憶體沒控管好。
會使用的時機通常是其問題本身就是遞迴定義的,或是小問題很好解決並且小問題有某種方式可以讓我們組合起來湊出大問題。
注意,若是我們可以發現某部分的問題可以捨去掉,而並不需要處理掉他(不需要治)通常就並不會特別叫他分治(例如二分搜)
一個分治的問題
請你構造出一個長度為N且包含1~N的數列,並且任意長度為三的子序列都不會是一個等差數列。
我們在講分治,不如就來想想看N=3的情況,我們會不會構造?
那如果N=K會做,有沒有什麼好的方式可以使得N=2K也可以做完呢?
如果把N=K的解同乘某個數或同加某個數會不會也同樣符合條件呢?
一個分治的問題
可以觀察到對於一個長度為三的序列,若要無法產生等差數列,其必定長得像是[奇、奇、偶]或[偶、偶、奇]或[偶、奇、奇]或[奇、偶、偶],那有沒有什麼構造方法可以使得我們不管如何取都會是上面的情況呢?
發現沒有辦法,因為總是會產生[奇、奇、奇]或[偶、偶、偶],哪有沒有辦法使得就算產生[奇、奇、奇]或[偶、偶、偶]他們也都還是好的呢?
一個分治的問題
發現先前提到的問題:『同乘某個數字之後還會是好的嗎?』同乘某個數字後也必定會是好的。
那不妨把N=K的答案同乘以二,那這樣我們就有了一個就算拿到[偶、偶、偶]也會是好的情況了,那在來構造[奇、奇、奇]也會是好的情況吧。
同樣可以發現同減一個數後也還是好的,那不如把N=K的情況同乘以二再減一,這樣我們又構出[奇、奇、奇]的情況了,這時只要把兩組一前一後擺就可以了
一個分治的經典應用
請你計算\( a^n \mod m \),其中\( m \leq 10^9, n \leq 10^62, a \leq 2^{31} - 1 \)
首先我們可以知道\( a \cdot b \mod m = (a \mod m) \cdot (b \mod m) \mod m \),所以我們只要在每次乘法後再取模即可避免溢位問題。
直覺的想法,跑個for迴圈慢慢乘慢慢算,但是n這麼大顯然會花費太久的時間。
那不如把問題切成一半,變成計算\( a^{\lfloor \frac{n}{2} \rfloor } \cdot a^{\lfloor\frac{n}{2} \rfloor} \cdot a^{n \mod 2} \mod m \),那這時就會發現我們每次都可以把冪次砍半,直到冪次變成1為止,複雜度改進到了\( O(\log_2{n}) \)
其他分治的經典應用
Karatsuba
Faster Matrix Multiplation
Fun Multiplation
動態規劃
動態規劃
(Dynamic Programming)
- 動態規劃常常適用於有重疊子問題(與D&C不同)和最優子結構性質的問題,動態規劃方法所耗時間往往遠少於樸素解法。
- 動態規劃背後的基本思想非常簡單。大致上,若要解一個給定問題,我們需要解其不同部分(即子問題),再合併子問題的解以得出原問題的解。(與D&C類似)
- 將子問題的答案記錄起來
- 避免對相同的問題再遞迴一次
- 用空間換取時間
優雅的暴力
簡單的例題
- 給你一個\( 2 \times N \)的格子,請問用\( 1 \times 2 \)大小的方塊將其填滿有幾種填法。



簡單的例題
- 假設令\( f(x) \)代表填滿 \( 2 \times x \)的方法數
- 觀察最後幾格的擺放方式,得到 \( f(x) = f(x-1)+f(x-2) \)
- 最前面的情況:\( f(1) = 1, f(2) = 2 \)
- (費式數列)
簡單的例題
照著實作:複雜度 \( O(\phi^n) = O(f(n)) \approx O(1.6^n) \)
int f(int x){
if(x==1) return 1;
if(x==2) return 2;
return f(x-1) + f(x-2);
}採用動態規劃:複雜度\( O(N) \)
int fib[MAX_N]
bool calced[MAX_N];
int f(int x){
if(x==1) return 1;
if(x==2) return 2;
if(calced[x]) return fib[x];
fib[x] = f(x-1) + f(x-2);
calced[x] = true;
return fib[x];
}簡單的例題
另一種版本的動態規劃:複雜度\( O(N) \)
int fib[MAX_N]
void build(){
fib[1] = 1;
fib[2] = 2;
for(int i=3;i<MAX_N;i++) fib[i] = fib[i-1]+fib[i-2];
}
int f(int x){
return fib[x];
}Top-Down v.s. Bottom-Up
Top-Down:一般只要知道遞迴式都可以採用此作法,使用一個陣列紀錄是否已經被計算過,再使用一個陣列紀錄算好的值,若已經被算過,則直接回傳該值,否則就按照遞迴式遞迴計算。(一樣要注意地回過深的問題)
Bottom-Up:若是對於一個問題有顯而易見的順序可以來遞迴,那其實可以考慮直接計算好每個子問題,再一起合併進入大問題,通常採用for迴圈即可。
另一個簡單的例題
將n個排成一列的格子塗上紅、綠、藍三種顏色,且藍綠不可相鄰,問有幾種塗法?
如果像前一題一樣,定義\( f(N) \)為排滿N個的方法數,那轉移似乎不能轉移。
其實f也可以是二維的,所以不妨定義\( f(N, color) \)代表排滿N個,且最後一個為COLOR色的方法數
狀態與轉移
在採用動態規劃的時候我們通常會要完成兩件事情
1. 狀態:表示我們要將怎樣的子問題記錄下來
2. 轉移:對於一個大問題我們要用哪些小問題合併起來
定義狀態的時候要注意
1. 狀態是否太多(記憶體可能會不夠用)
2. 狀態是真的可以轉移到大問題
看似可以解問題之後
1. 注意時間複雜度是否合理
2. 若不合理是否可以優化
3. 是不是狀態定的不好
如何知道狀態該如何定
靠經驗、靠靈感
再一個類似的問題
- 給你一個\( 2 \times N \)的格子,請問用\( 1 \times 2 \)的長條方塊與\( 1 \times 3 \) 的L型方塊將其填滿有幾種填法。
- 定義狀態:\( f(n) \)表示填滿\( 2 \times n \)格子的方法數
檢查一下狀態數,不會太多 - 狀態轉移:
最後一個放\( 1 \times 2\)的情況討論過了,那來看最後一個L型的情況。
稍微觀察一下可以得到\( f(n) = f(n-1)+f(n-2) + 2(\sum_{i=0}^{n-3} f(i)) \) - 狀態\( N \)個,每個狀態要花\( O(N) \)時間轉移,總時間複雜度\( O(N^2) \)
再一個類似的問題
\( O(N^2) \)好像太慢了,那我們應該要優化\( f(n) = f(n-1)+f(n-2) + 2(\sum_{i=0}^{n-3} f(i)) \)
採用buttom-up的時候我們可以用個變數記錄前綴和(\(\sum_{i=0}^{n-3} f(i) \))
而採用top-down時我們則可能需要優化一下式子
\( f(n) = f(n-1)+f(n-2) + 2(\sum_{i=0}^{n-3} f(i)) \)
\( f(n-1) = f(n-2)+f(n-3)+2(\sum_{i=0}^{n-4} f(i)) \)
相減得到
\( f(n) - f(n-1) = f(n-1) + f(n-3) \rightarrow f(n) = 2f(n-1)+f(n-3) \)
這樣也可以使複雜度降低回\( O(N) \)
經典問題:最長遞增子序列
- 問題描述:給你一個序列,請你找到一個最長的子序列使得他的數字遞增
- 子序列:在原序列中刪除一些元素後所得到的序列
e.g. {1, 2, 7, 3, 9, 6 ,5} → {1, 3, 5} or {2, 7, 9, 6} - 遞增子序列:{1, 2, 7, 3, 9, 6 ,5} → {1} or {1, 2, 3} or {2, 7, 9}
- 最長遞增子序列:{1, 2, 7, 3, 9, 6 ,5} → {1, 2, 3, 5}
- 先給出一個找出長度的作法即可
經典問題:最長遞增子序列
一樣來DP吧!
先定個狀態:\( f(n) \)代表以\( arr[n] \)作為結尾時,最長的遞增子序列長度為多少,確認狀態沒有太多後
那來想想看轉移吧:發現前面可以接所有比\( arr[n] \)小的數,所以可以枚舉前面是誰,轉移就是 \(f(n) = \displaystyle{ \max_{\forall i<n \land arr[i] \leq arr[n]} f(i) + 1} \),而答案就是\( \displaystyle{\max_{i \leq n}f(i)} \)
複雜度:\( N \)個狀態每次轉移\(O(N)\),總複雜度\( O(N^2) \)
經典問題:最長遞增子序列
那如果我想要找到我是選出哪些序列怎麼辦呢?
每個狀態變成記錄整個序列?如果是的話那空間會變成 \(O(N^2) \),而且轉移都會複製一遍序列非常花時間
想要更好的話,可以發現我們其實不需要每次轉移的時候都複製,因為他們的前綴都長得一樣,所以我們其實可以記錄每個狀態是從哪裡轉移過來的,再採用遞迴的方式把解求回來,這樣的話空間複雜度還是\( O(N) \),比起原本的作法省了不少空間,而這也是DP後要找解的常用技巧
經典問題:最長遞增子序列
我還是覺得\( O(N^2) \)還是不夠快耶,一起優化他吧
再觀察一下!
發現對於第\( i \)項元素,若是存在一個元素\( j (j>i) \)使得\(arr[j] < arr[i] \land dp[j] > dp[i] \),那第\( i \)元素就不可能再被看到了。
所以我們可以再開一個陣列tmp記錄可能會取道的\( f(i), arr[i] \),不過發現\( f(i) \)最多只有\( N \) 而且若存在\( f(i) \),那也必定有某個\( j \)使得\( f(i) = f(j)+1 \),因此我們甚至可以把\( f(i) \)當做陣列的索引值來用。這時會發現tmp第\( i \)格存的就是\( \displaystyle{\min_{f(j)=i}arr[j]} \)。
那我們來改寫一下轉移式,\( f(i) = j+1, \text{where }tmp[j] < arr[i]\text{ and }tmp[j+1] \geq arr[i] \)
再發現tmp必定遞增後,我們就可以使用二分搜來找到\( j \),進而讓複雜度降低至\( O(n \log n) \)
壓完了時間我們來壓壓看空間吧
另一個問題:在一個\( N \times M \)的網格內,每個格子內都有一個數字現在要從左上角走到右上角,每次只能往右走一格或往下走一格,每到一格就會把數字加到自己的身上,問數字和最大可以是多少?
簡單的採用DP的話,我們可以得到這樣的關係式\( f(i, j) = \max(f(i-1,j), f(i, j-1)) + a[i][j] \)
時間複雜度跟空間複雜度都是\( O(NM) \),如果記憶體限制有點嚴格的話可能會開不下,而且其實能不要浪費就不要浪費
壓完了時間我們來壓壓看空間吧
怎麼壓呢?發現對於\( f(n, ?) \)他只會需要看\(f(n, ?), f(n-1, ?) \),而\(f(n-2), f(n-3).... \) 都不會再被看到了,所以我們若是按照第一為的順序採用buttom-up的方法DP,那我們將會只需要兩條長度為\( M \)的陣列就好了?
那怎麼只用兩個陣列呢?每次做完一條的時候都複製一遍嗎?還是每次陣列都用new的new出來,用完就delete掉?
這兩個作法其實都不會影響複雜度,但是他實際運作起來效率有點低。
其實我們還可以就每次就記錄上次是誰跟這次要寫在哪裡就好了,或是直接使用一點數學運算
dp[i%2][j]=max(dp[(i+1)%2][j],dp[i%2][j])+a[i][j]
壓完了時間我們來壓壓看空間吧
怎麼壓呢?發現對於\( f(n, ?) \)他只會需要看\(f(n, ?), f(n-1, ?) \),而\(f(n-2), f(n-3).... \) 都不會再被看到了,所以我們若是按照第一為的順序採用buttom-up的方法DP,那我們將會只需要兩條長度為\( M \)的陣列就好了?
那怎麼只用兩個陣列呢?每次做完一條的時候都複製一遍嗎?還是每次陣列都用new的new出來,用完就delete掉?
這兩個作法其實都不會影響複雜度,但是他實際運作起來效率有點低。
其實我們還可以就每次就記錄上次是誰跟這次要寫在哪裡就好了,或是直接使用一點數學運算
dp[i%2][j]=max(dp[(i+1)%2][j],dp[i%2][j])+a[i][j]
矩陣快速冪優化
矩陣在乘法上擁有結合律,所以其實矩陣冪次也可以使用快速冪來做到\( N^3 log K \)的複雜度,但是這跟DP有什麼關係呢?
矩陣乘法
void matrix_multiply(int A[N][N], int B[N][N], int C[N][N]){
// C = A*B
for(int i=0;i<N;i++){
for(int j=0;j<N;j++){
C[i][j] = 0;
for(int k=0;k<N;k++) C[i][j] += A[i][k]*B[k][j];
}
}
}矩陣快速冪優化
回到最初的題目:給你一個\( 2 \times N \)的格子,請問用\( 1 \times 2 \)大小的方塊將其填滿有幾種填法。
我們有\( f(n) = f(n-1) + f(n-2) \)
可以稍微改寫一下後得到
\( f(n) = f(n-1) + f(n-2) \)
\( f(n-1) = f(n-1) \)
高二下數學第三章轉移矩陣:
http://highscope.ch.ntu.edu.tw/wordpress/?p=51085
矩陣快速冪優化
發現矩陣的應用
$$\begin{pmatrix} f(n) \\ f(n-1) \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} f(n-1) \\ f(n-2) \end{pmatrix}$$
$$\begin{pmatrix} f(n-1) \\ f(n-2) \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} f(n-2) \\ f(n-3) \end{pmatrix}$$
$$\begin{pmatrix} f(n) \\ f(n-1) \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} f(n-2) \\ f(n-3) \end{pmatrix}$$
$$\begin{pmatrix} f(n) \\ f(n-1) \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix}^{n-1} \begin{pmatrix} f(1) \\ f(0) \end{pmatrix}$$
求 $$\begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix}^{n-1}$$可以採用快速冪,這樣我們就可以在\( O(\log N) \)的時間內求出答案了