A Brief Introduction To Apache Kafka
Pan Chuan
2016-04-22

Outlines
- What is Kafka
- Kafka's feature and design philosophy
- Comparison with other MQ
- Kafka use case
What is Kafka

- Kafka is a distributed, high-throughput messaging system
- LinkedIn original motivation: have a unified platform for handling all the real-time data feeds a large company might have
why create Kafka
Message Queues
Log aggregators
Kafka
- RabbitMQ
- ActiveMQ
- Flume
- Scribe
- LinkedIn did not satisfied existed MQ or Log aggregators systems
LinkedIn's opinion: flaw of existed system
- Often focus on offering a rich set of delivery gurantees like IBM Websphere MQ which increase complexity and may not needed.
- Do not focus on throughput as design constraint (no batching consume) like JMS.
- Weak in distributed support.
- they assume near immediate consumption of messages which makes unconsumed messages is very small, not good to offline consumers.
- or only good to offline using like Scribe
- most of them using a push model instead of pull model.
- More...
- Topic: Kafka maintains feeds of message in categories
- Producer: the process publish messages to a kafka topic
- Consumer: the process subscribe to topics
- Broker: Kafka always runs as a cluster each server is called a broker
Some Concepts
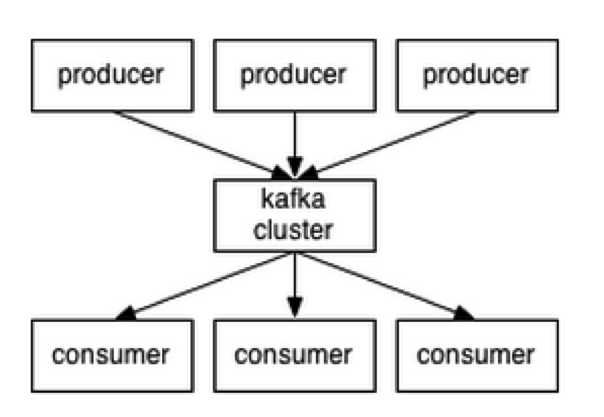
push
pull
broker is quite lazy
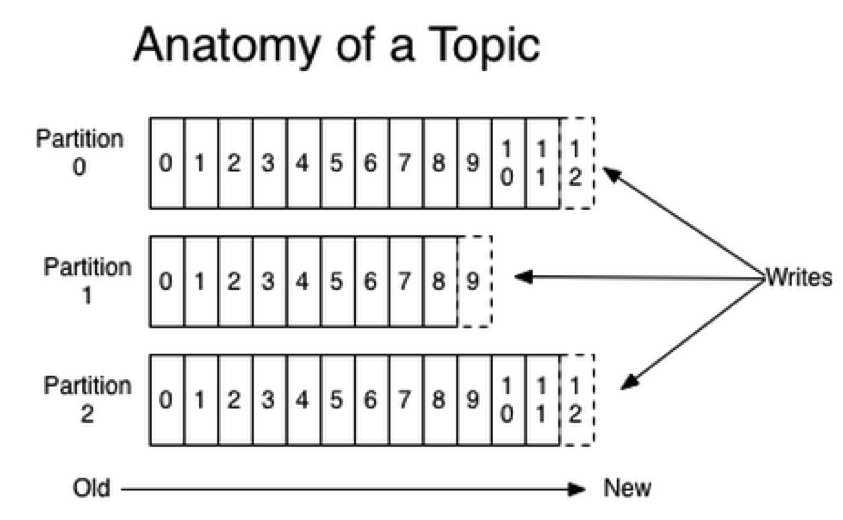
Kafka partition
- one topics can have multiple partitions
- one partition orders, but not orders across partitions
- A consumer instance sees messages in the order they are stored in the log
offset
Why partition
- Load balance, distributing one topic's messages to cluster avoids single machine IO bottleneck
- Each partition is replicated across a number of servers for fault tolerance
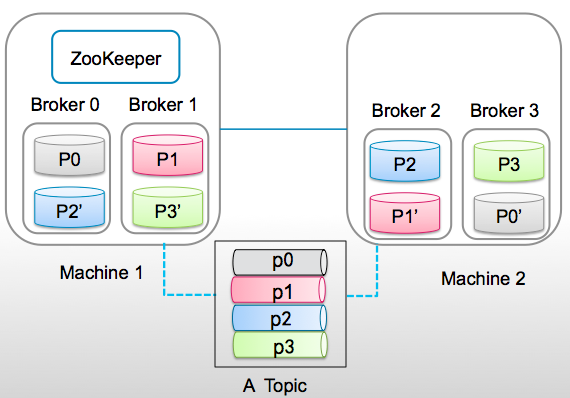
What is Zookeeper
- A high performance coordination service for distributed applications
- Centralized service for
- Configuration Management
- Naming service
- Group Membership
- Lock Synchronization
- Use case:
- Distributed Cluster Management
- Distributed Synchronization
- Leader election
- High reliable Registry
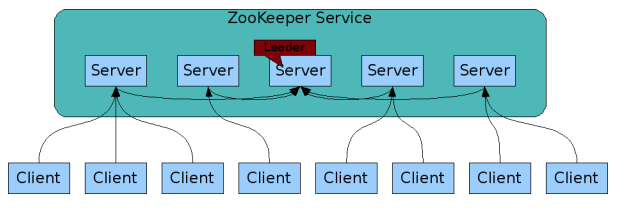
Zookeeper in Kafka
- Electing a controller. controller is a special broker to maintain the leader/follower relationship for all the partitions. when a node shuts down, controller tells other replicas to become partition leader.
- Cluster membership, which brokers are alive and part of the cluster.
- Topic configuration
- authentication, who is allowed to read and write which topic
In short: Zookeeper takes care of all Metadate about kafka.
Kafka good feature
- Fast
- Durable
- Flexible
- Scalable
Fast
- Write and read disk sequentially, O(1) time read and write. Don't fear the file system!
- Batching producing and consuming
- Gzip/snappy compression
- Zero-copy
Zero-Copy
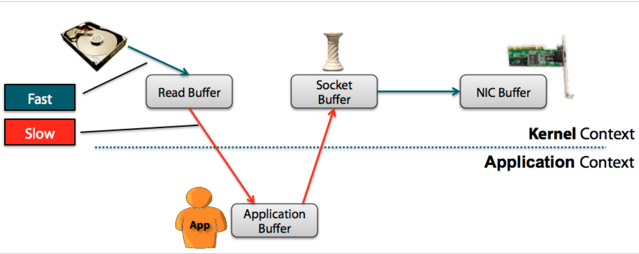
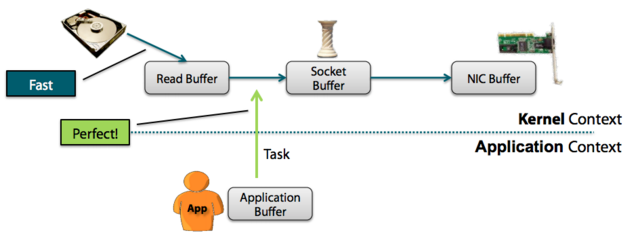
Traditional:
zero-copy:
- Kafka uses zero-copy when consuming
Kafka performance
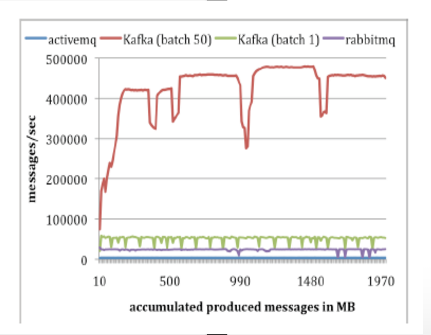
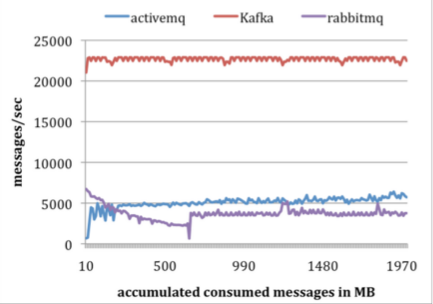
- Kafka VS Rabbitmq/activemq
Kafka@LinkedIn 2014
- data type is being transported through Kafka:
- Metrics: operational telemetry data
- Tracking: everything a LinkedIn.com user does
- Queuing: between LinkedIn apps, e.g for sending emails
- in total 200 billion events/day via Kafka:
- Tens of thousands of data produces, thousands of consumers
- 7 million events/sec write, 35 million events read
Durable
-
Message persisted on disk, offline and online unitized
-
Topic/Partiton replicate across brokers,N replicates tolerates N-1 failure
Flexible
-
Pull is better than Push, Consumer handle rate. for push model, end point can’t have lots of business logic in real-time, no further consumption
-
stateless, offset not maintained by the broker, consumer can deliberately rewind and re-consume data
- Prouder load balance (random, RoundRobin, hash(key))
Kafka Message Acking
- 0: producer never waits for an ack from the broker
-
1: producer gets an ack after the leader replica has received the data
-
-1: producer gets an ack after all replicas receiving the data
better durability
better
latency
Scalable
-
Can be elastically and transparently expanded without downtime.
Kafka VS RabbitMQ
- RabbitMQ is broker-centric, focused around delivery guarantees between producers and consumers, with transient preferred over durable messages
- Kafka is producer-centric, based around partitioning a large amount of event data into durable message brokers with cursors, supporting batch consumers offline or online consumers who wants a low latency
Kafka VS RabbitMQ: how to choose
- you have a fire hose of events (100k+/sec) need to delivered in partitioned order 'at least once' with a mix of online and batch consumers
- want to re-consume
- you have messages (20k+/sec) need to be routed in complex ways to consumes.
- want per-message delivery guarantees, don't care about ordered delivery
- need 24*7 paid support
Choose RabbitMQ:
Choose Kafka:
Kafka VS RedisMQ
- Redis needs as much memory as there are messages in flight, better to use when have short lived messages and wish more consumer capacity
- Kafka keeps messages much longer, for batch and real-time consuming
- quite different use case, Redis is only useful for online operational messaging while Kafka is best used in high volume data processing pipelines
RabbitMQ VS RedisMQ
- When enqueue, Redis has higher performance for small size messages, but quickly becomes untolerable slow when message size bigger than 10K
- When dequeue, Redis performs much better than RabbitMQ for whichever size data
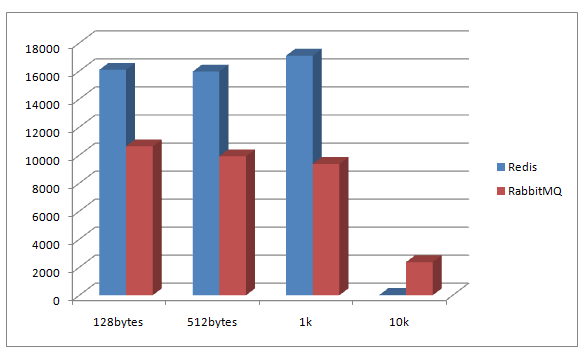
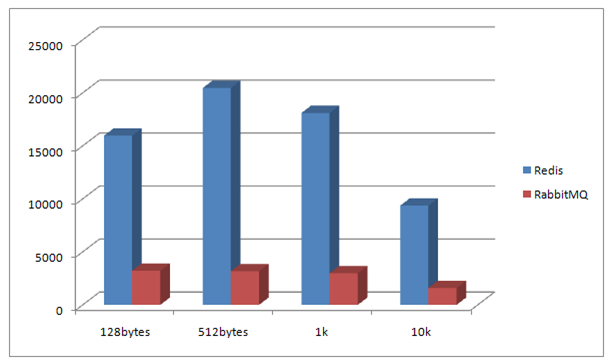
Kafka Client
- Kafka uses a binary protocol over TCP which defines all APIs as reqeust response message pairs.
- Kafka protocol is fairly simple,only six core client requests APIs.
Metadata, Send, Fetch, Offsets, Offset Commit, Offset Fetch
- A client is easily to implement , just follow the protocol defined.
Kafka Client
Kafka quick start
> wget http://www-us.apache.org/dist/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz > tar -xzf kafka_2.11-0.9.0.0.tgz
> cd kafka_2.11-0.9.0.0> bin/zookeeper-server-start.sh config/zookeeper.properties &> bin/kafka-server-start.sh config/server.propertiesfrom kafka import KafkaProducer
import time
def produce():
producer = KafkaProducer(bootstrap_servers='localhost:9092')
while True:
producer.send('my-topic', b"A test message")
time.sleep(1)
if __name__ =="__main__":
produce()pip install kafka-pythonKafka Python Client
producer usage:
from kafka import KafkaProducer
def consume():
consumer = KafkaConsumer(bootstrap_servers='localhost:9092',
auto_offset_reset='earliest')
consumer.subscribe(['my-topic'])
for message in consumer:
print message
if __name__ =="__main__":
consume()Kafka Python Client
consumer usage:
ConsumerRecord(topic=u'my-topic', partition=0, offset=230, key=None, value='A test message')
ConsumerRecord(topic=u'my-topic', partition=0, offset=231, key=None, value='A test message')
ConsumerRecord(topic=u'my-topic', partition=0, offset=232, key=None, value='A test message')terminal output:
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['broker1:1234'])
# Asynchronous by default
future = producer.send('my-topic', b'raw_bytes')
# Block for 'synchronous' sends
try:
record_metadata = future.get(timeout=10)
except KafkaError:
# Decide what to do if produce request failed...
log.exception()
pass
# Successful result returns assigned partition and offset
print (record_metadata.topic)
print (record_metadata.partition)
print (record_metadata.offset)
# produce keyed messages to enable hashed partitioning
producer.send('my-topic', key=b'foo', value=b'bar')
# encode objects via msgpack
producer = KafkaProducer(value_serializer=msgpack.dumps)
producer.send('msgpack-topic', {'key': 'value'})
# produce json messages
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('json-topic', {'key': 'value'})
# produce asynchronously
for _ in range(100):
producer.send('my-topic', b'msg')
# block until all async messages are sent
producer.flush()
# configure multiple retries
producer = KafkaProducer(retries=5)Producer More Usage
from kafka import KafkaConsumer
# To consume latest messages and auto-commit offsets
consumer = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers=['localhost:9092'])
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
# consume earliest available messages, dont commit offsets
KafkaConsumer(auto_offset_reset='earliest', enable_auto_commit=False)
# consume json messages
KafkaConsumer(value_deserializer=lambda m: json.loads(m.decode('ascii')))
# consume msgpack
KafkaConsumer(value_deserializer=msgpack.unpackb)
# StopIteration if no message after 1sec
KafkaConsumer(consumer_timeout_ms=1000)
# Subscribe to a regex topic pattern
consumer = KafkaConsumer()
consumer.subscribe(pattern='^awesome.*')
# Use multiple consumers in parallel w/ 0.9 kafka brokers
# typically you would run each on a different server / process / CPU
consumer1 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
consumer2 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')Consumer More Usage
set a cluster
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.propertiesconfig/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2> bin/kafka-server-start.sh config/server-1.properties &
> bin/kafka-server-start.sh config/server-2.properties &
A tool for managing Apache Kafka
Kafka use case

Kafka use case
- Messaging:
- replacement of RabbitMQ in some cases.
- Decouple module ,buffer unprocessed messages
- Log Aggregation:
- Collects physical log files across servers to a file server or HDFS.
- Abstract files as a stream of messages
- Comparing with Scribe/Flume, equally performance, stronger
durability, much lower latency
Kafka use case
- Website Activity Tracking:
- Rebuild a user activity tracking pipeline as a real-time pub-sub feeds.
- Publish site activity (page views, searches)
- Loading into Hadoop/warehouse for offline processing
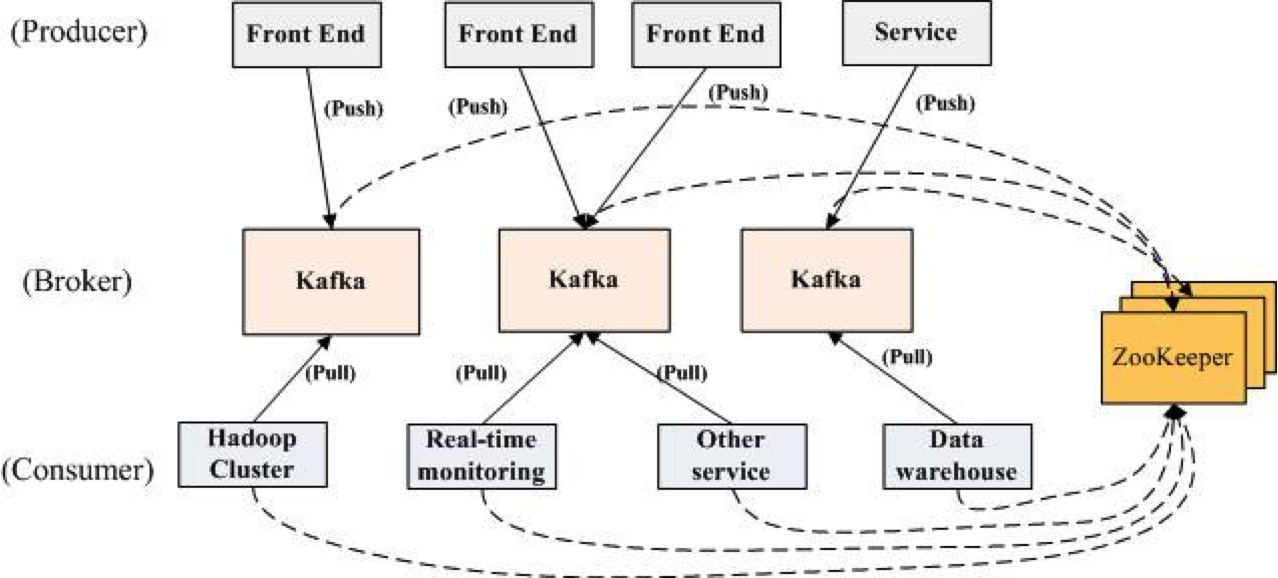
Kafka use case
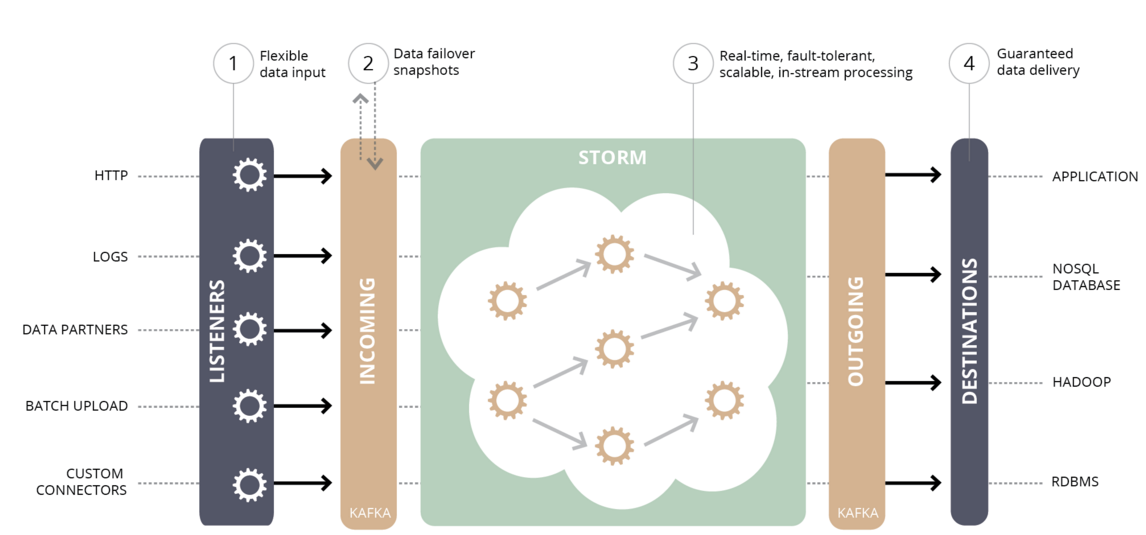
- Stream Processing:
- Many users end up doing stage-wise processing of data where data is consumed from topics of raw data and then aggregated, enriched, or otherwise transformed into new Kafka topics for further consumption.
- Stream Processing
- Hadoop Integration
- Search and Query
- Management Consoles
- AWS Integration
- Logging
- Flume - Kafka plugins
- Metrics
- Packing and Deployment
- Kafka Camel Integration
- Misc
Kafka Tips
- LinkedIn engineers who built Kafka have founded Confluent to build a data stream platform using Kafka

useful reference
