Brief History of DL
http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/
Position of Deep Learning
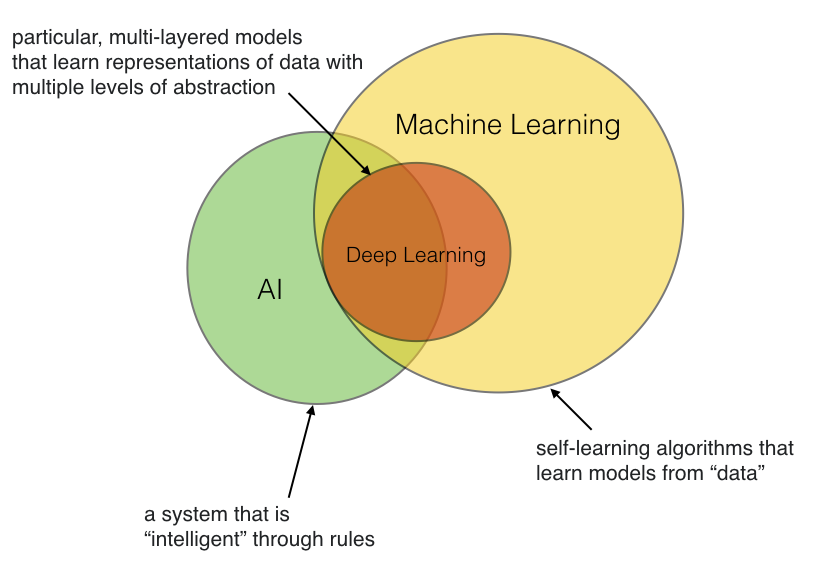
Machine Learning ???
Human Dream : Thinking Machine
The stuff promised in this video - still not really around.
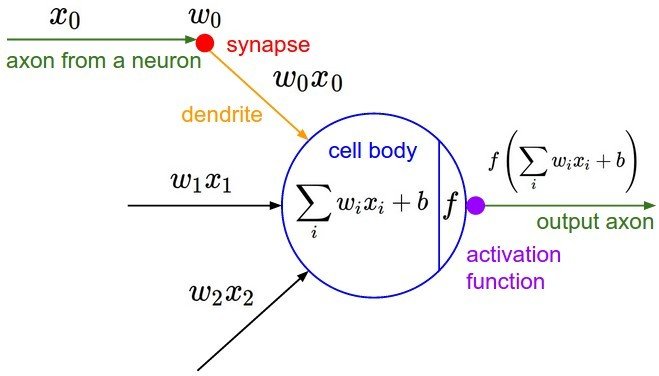
Hint from Neuron
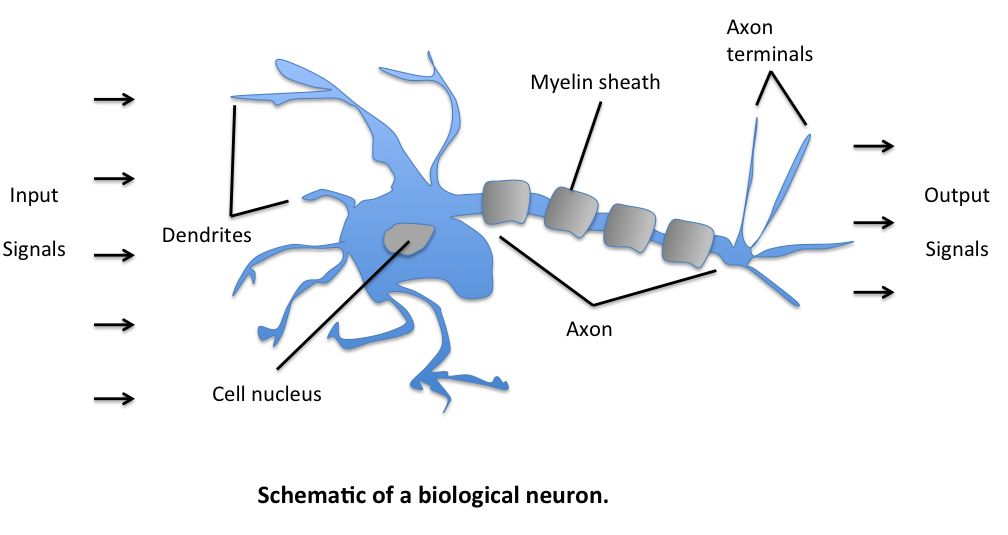
Biological Inspiration
Perceptron(1958)
http://psycnet.apa.org/index.cfm?fa=buy.optionToBuy&id=1959-09865-001
H/W of Perceptron

http://www-isl.stanford.edu/~widrow/papers/t1960anadaptive.pdf

Perceptron
by Frank Rosenblatt
1957
Adaline
by Bernard Widrow and Tedd Hoff
1960
People believe False Promises

http://www.nytimes.com/1958/07/08/archives/new-navy-device-learns-by-doing-psychologist-shows-embryo-of.html
“The Navy revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself an be conscious of its existence … Dr. Frank Rosenblatt, a research psychologist at the Cornell Aeronautical Laboratory, Buffalo, said Perceptrons might be fired to the planets as mechanical space explorers”
New York Times
July 08, 1958
XOR problem

linearly Separable?
Perceptrons(1969)

Perceptrons
by Marvin Minsky (founder of MIT AI lab)
1969
-
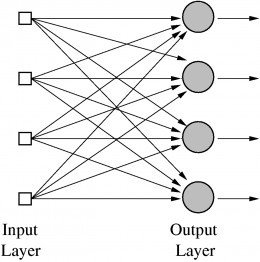
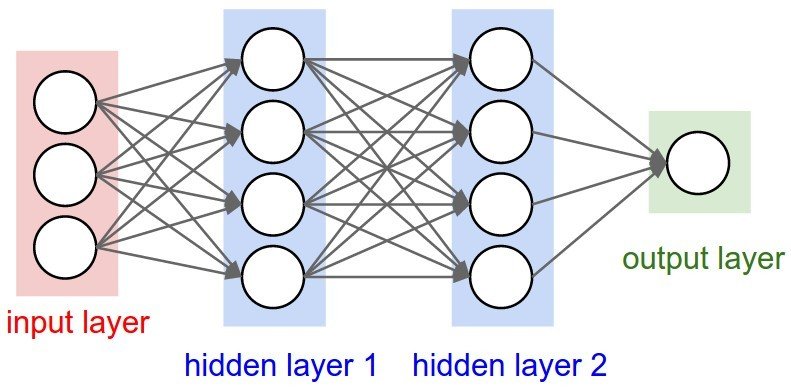
We need to use MLP, multilayer perceptrons
-
No on on earth had found a viable way to train MLPs good enough to learn such simple functions.
MLP can solve XOR problem
Text
1st Winter(1969)
"No on on earth had found a viable way to train..."

Marvin Minsky 1969
Backpropagation(1986)
(1974, 1982 by Paul Werbos, 1986 by Hinton)
https://devblogs.nvidia.com/parallelforall/inference-next-step-gpu-accelerated-deep-learning/
CNN
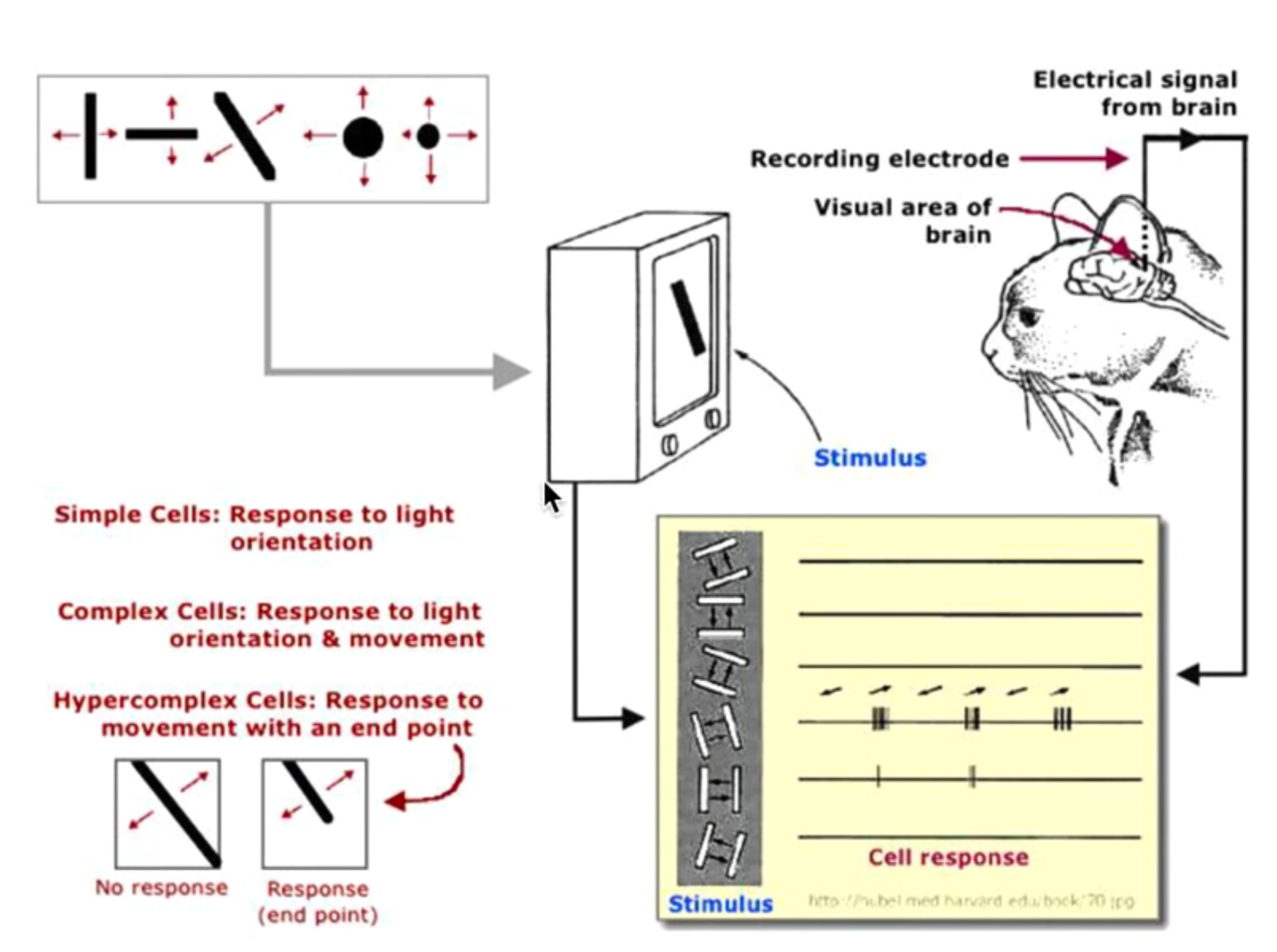
(by Hubel & Wiesel, 1959)
motivated by biological insights
CNN
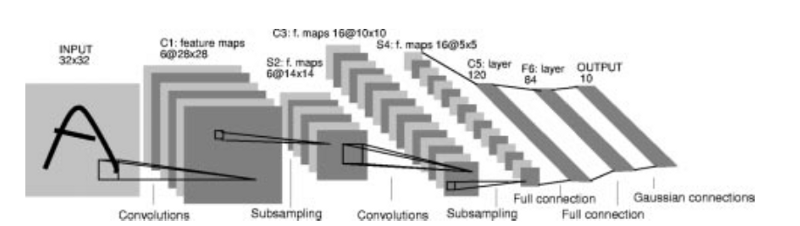
(LeNet-5, Yann LeCun 1980)
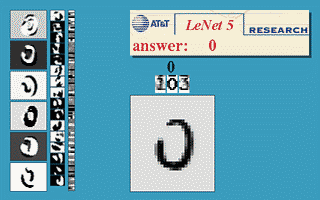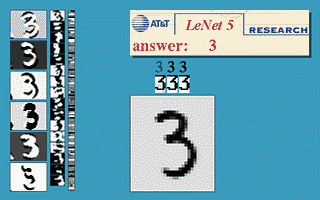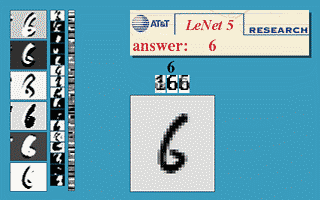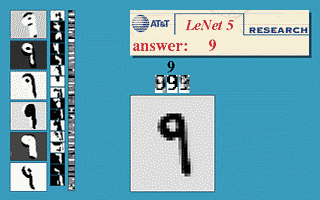
http://yann.lecun.com/exdb/publis/pdf/lecun-89e.pdf
CNN + Vision
"At some point in the late 1990s, one of these systems was reading 10 to 20% of all the checks in the US.”
CNN + Self Driving Car
"NavLab 1984 ~ 1994 : Alvinn”
Terminator 2 (1991)

http://pages.cs.wisc.edu/~jerryzhu/cs540/handouts/neural.pdf
BIG Problem
-
Backpropagation just did not work well for normal neural nets with many layers
-
Other rising machine learning algorithms : SVM, RandomForest, etc.
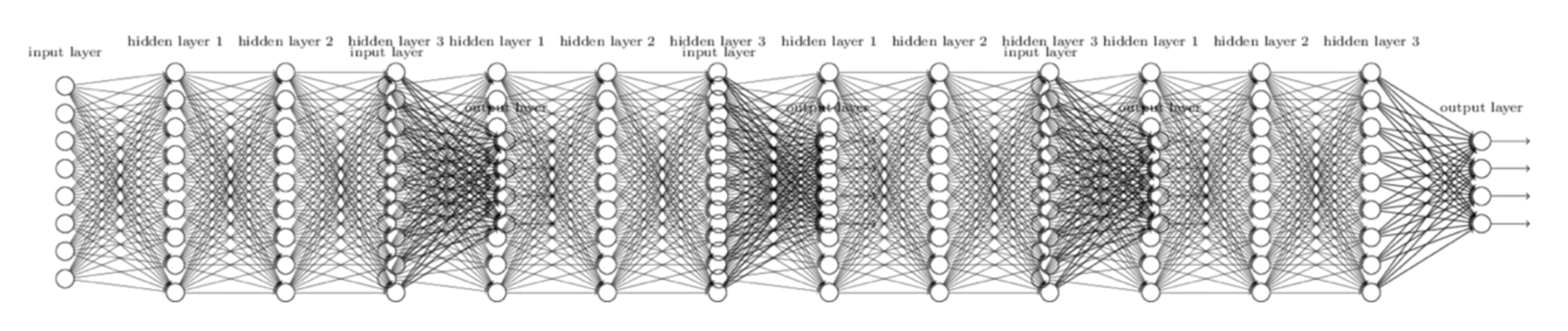
http://neuralnetworksanddeeplearning.com/chap6.html
2nd Winter(1995)

1995 Paper
"Comparison of Learning Algorithm For Handwritten Digit Recognition"
"New Machine Learning approach worked better"
Yann LeCun 1995
http://yann.lecun.com/exdb/publis/pdf/lecun-95b.pdf
CIFAR
-
Canadian Institute for Advanced Research -
which encourages basic research without direct application, was what motivated Hinton to move to Canada in 1987, and funded his work afterward.
http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning-part-4/
CIFAR
- “But in 2004, Hinton asked to lead a new program on neural computation. The mainstream machine learning community could not have been less interested in neural nets.
- “It was the worst possible time,” says Bengio, a professor at the Université de Montréal and co-director of the CIFAR program since it was renewed last year. “Everyone else was doing something different. Somehow, Geoff convinced them.”
- “We should give (CIFAR) a lot of credit for making that gamble.”
- CIFAR “had a huge impact in forming a community around deep learning,” adds LeCun, the CIFAR program’s other co-director. “We were outcast a little bit in the broader machine learning community: we couldn’t get our papers published. This gave us a place where we could exchange ideas.”
http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning-part-4/
Breakthrouth(2006,2007)

by Hinton and Bengio
https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf
http://papers.nips.cc/paper/3048-greedy-layer-wise-training-of-deep-networks.pdf

-
Neural networks with many layers really could be trained well, if the weights are initialized in a clever way rather than randomly. (By Hinton)
-
Deep machine learning methods (that is, methods with many processing steps, or equivalently with hierarchical feature representations of the data) are more efficient for difficult problems than shallow methods (which two-layer ANNs or support vector machines are examples of). (By Benzio)
Rebranding to Deep Learning
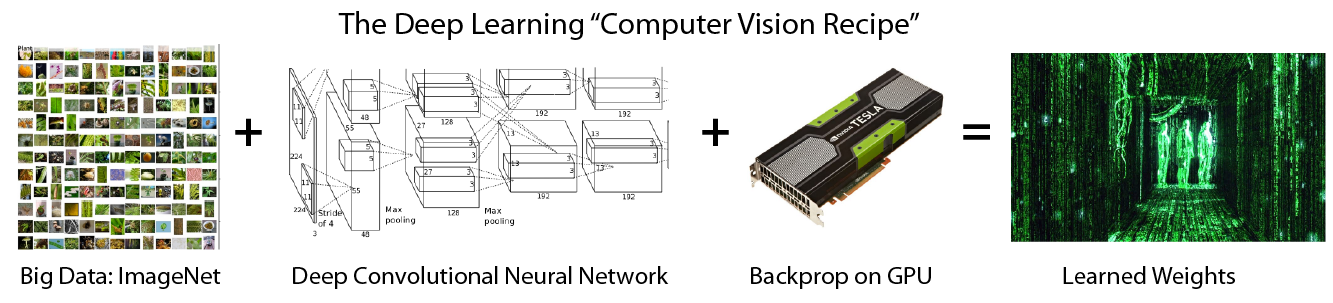
Imagenet

- Total number of non-empty synsets: 21841
- Total number of images: 14,197,122
- Number of images with bounding box annotations: 1,034,908
- Number of synsets with SIFT features: 1000
- Number of images with SIFT features: 1.2 million
- Object localization for 1000 categories.
- Object detection for 200 fully labeled categories.
- Object detection from video for 30 fully labeled categories.
- Scene classification for 365 scene categories on Places2 Database http://places2.csail.mit.edu.
- Scene parsing for 150 stuff and discrete object categories
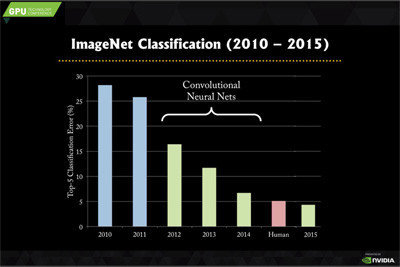
Short history of Imagenet
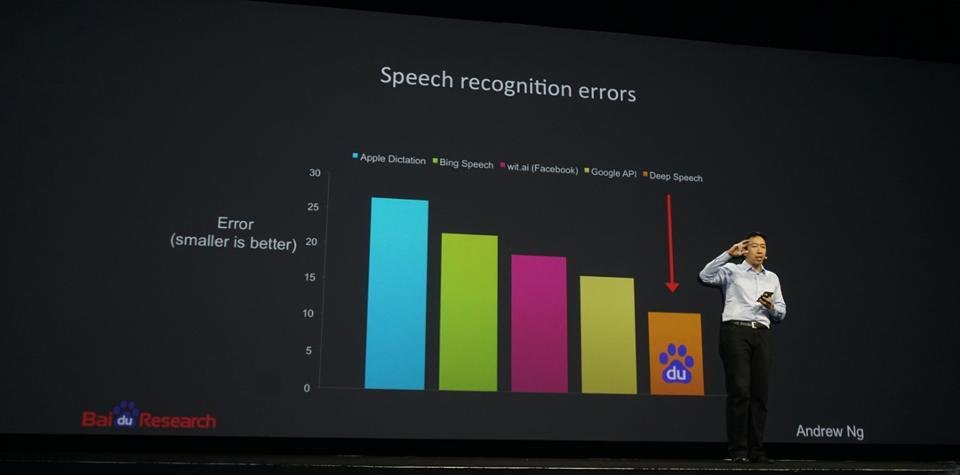
Speech Recognition
Geoffrey Hinton summarized the findings up to today
- Our labeled datasets were thousands of times too small.
- Our computers were millions of times too slow.
- We initialized the weights in a stupid way.
- We used the wrong type of non-linearity.
Deep Learning =
Lots of training data + Parallel Computation + Scalable, smart algorithms