Deep Learning Papers
The economics of Housing & Homelessness
Zhang et al. (2017)
Point # 1
"Deep neural networks easily fit random labels."
- Notice how the neural networks loss converges fastest on the true labels
- But less easily than they fit the real data
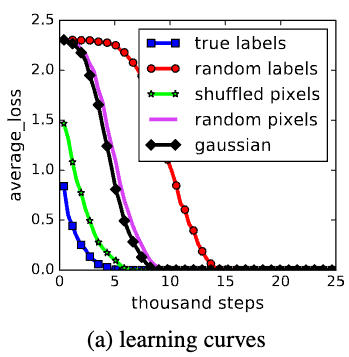
Point # 2
"The ability to augment the data using known symmetries is significantly more powerful than just tuning weight decay or preventing low training error"
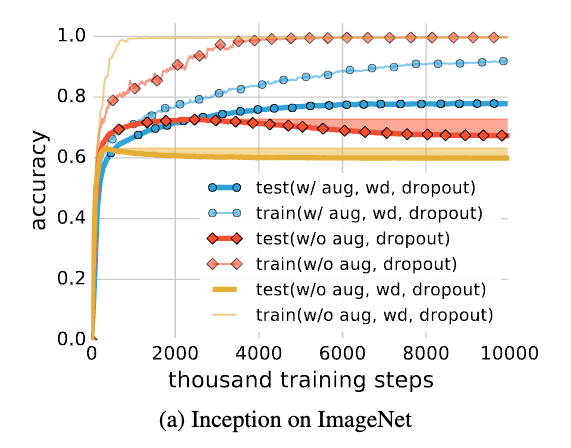
With Data Augmentation
Without Data Augmentation
Bengio et al. (2003)
The Abstract starts with the essentials of the estimation problem
"A goal of statistical language modeling is to learn the joint probability function of sequences of words in a language. This is intrinsically difficult because of the curse of dimensionality: a word sequence on which the model will be tested is likely to be different from all the word sequences seen during training"
The abstract highlights that every paper should state how it accounts for the curse of dimensionality
"We propose to fight the curse of dimensionality by learning a distributed representation for words which allows each training sentence to inform the model about an exponential number of semantically neighboring sentences."

The Essence of Learning from Data
To generalize is to transfer probability mass from the training data points
Learning in High Dimensions
In high dimensions, it is crucial to distribute probability mass where it matters rather than uniformly in all directions around each training point.
Bertsch et al. (2024)
In Context Learning
Retrieval
Fine-Tuning
Providing the model with a subset of the examples via the prompt
retrieving relevant data for each example at inference time
Adjusting the weights of the model to better fit the entire dataset
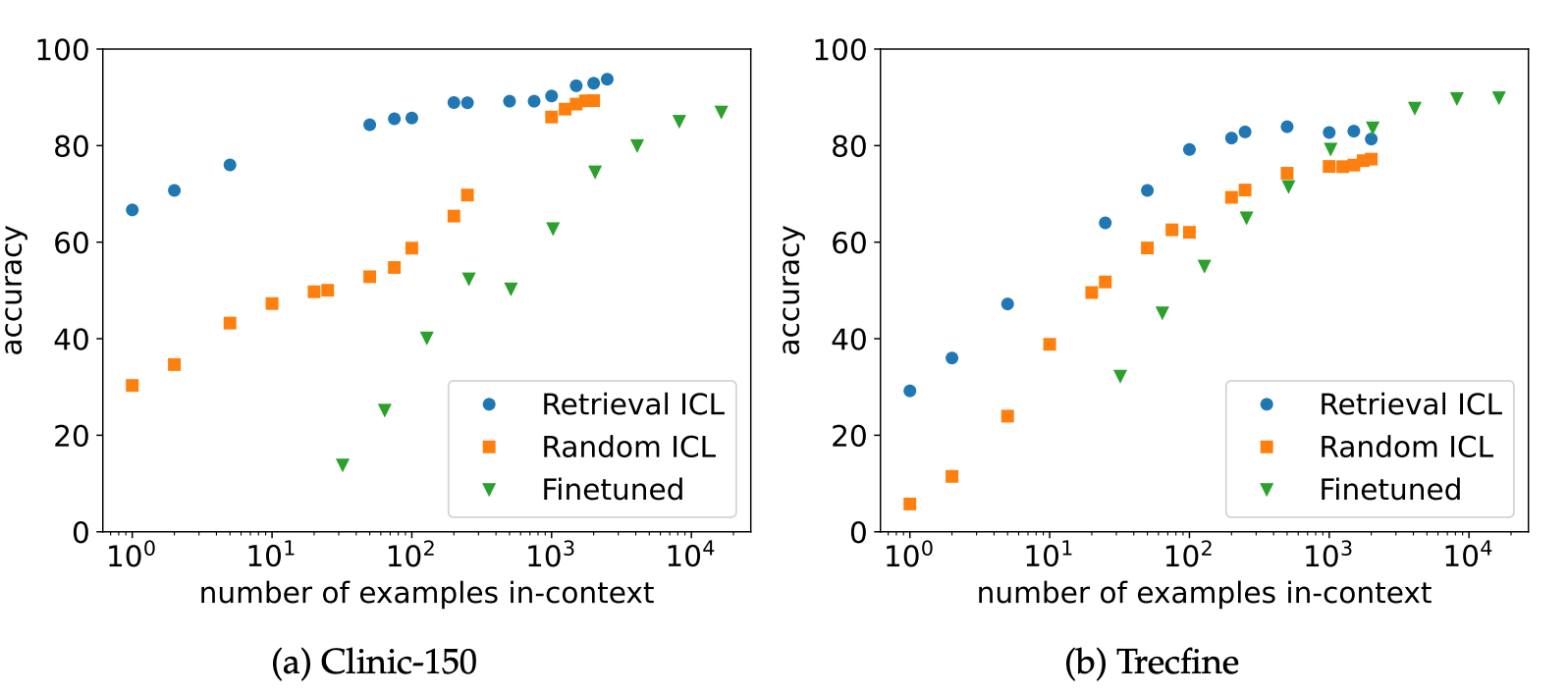
These figures suggest that fine-tuning is more effective when the number of data points exceeds the number of possible in context examples
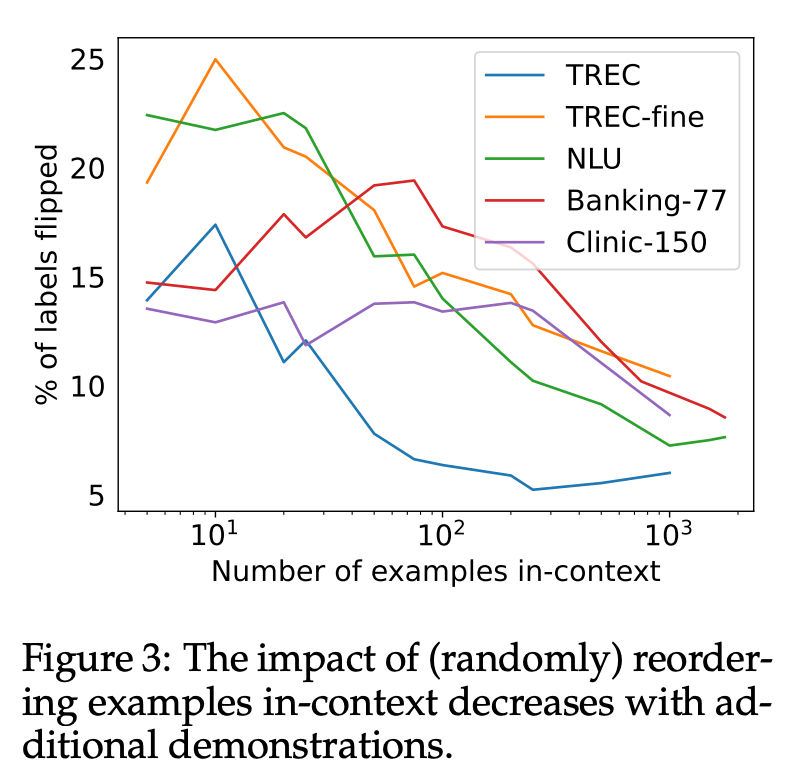
An important consideration is how sensitive LLMs are to the order in which they see the data