Flink 101:
How we got here, what we're doing
In the beginning, we had databases...
Early Software had a wide variety of DB types:
Relational:
* Tabular data
* Graph data
* heirarchical data such as directories (LDAP was 1988)
Non-relational:
* KV stores
* wide column
And then Tabular was everywhere
Key advantages:
* Easy to reason about
* Strong data promises (ACID)
* Easy to query SQL
* Don't need to know all code paths ahead of time
* Some modifications are "cheap" (add an index etc)
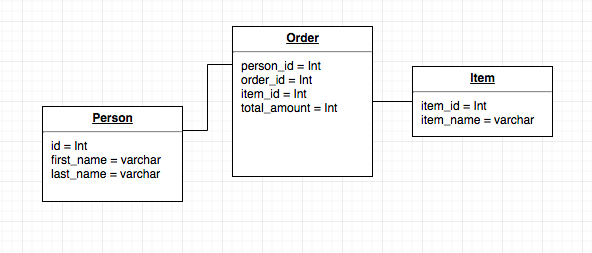
And then we had a problem
Large data sets (esp with heavy writes)
* Inserting into one table might require checking multiple other tables to satisfy FK dependencies
* This might require locking part or all of some tables for writes
* A write might also involve multiple index updates
* If there's multiple nodes, you might need to coordinate a lock over the network (SLOW).
DBAs began to recommend de-normalizing data, and this brought us back to our starting point.
Sharding
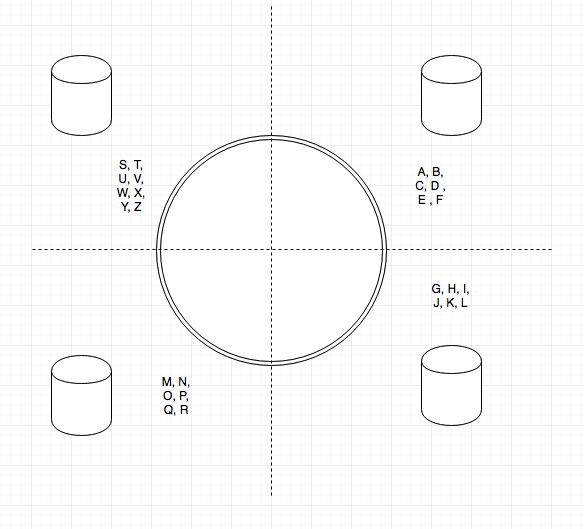
Sharding
We solved our network communication issue, our DBs don't need to talk much. Now we can scale out but...
* Re-sharding becomes painful if we need to grow/shrink the cluster
* The more machines we have the more likely we have a failure
* This really only works with denormalized data, so we're not leveraging relational as much as we used to
* Some problems like distributed state snapshots are hard.
Redundancy
Solves our uptime by creating more problems
* Now data is stored repeatedly on multiple machines, we can suffer a failure
* What do we do when we suffer a failure?!
* CAP Theorem
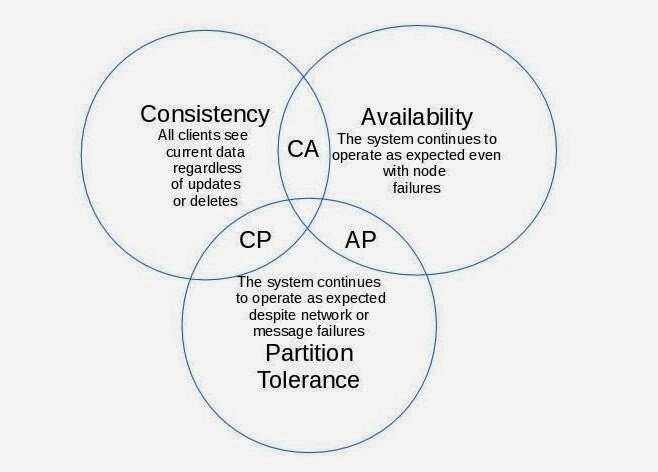
Key Take Away
Distributed Databases are a lot harder than a single machine relational database.
This is a decision you're pushed into by technical and business requirements, not something you seek out.
Data Analytics
What happens when we want to do something like sum all sales for our store? Or maybe all sales of a specific item?
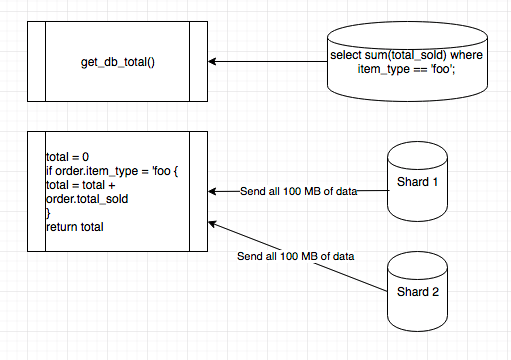
Data Analytics
Then we got fancy with map-reduce
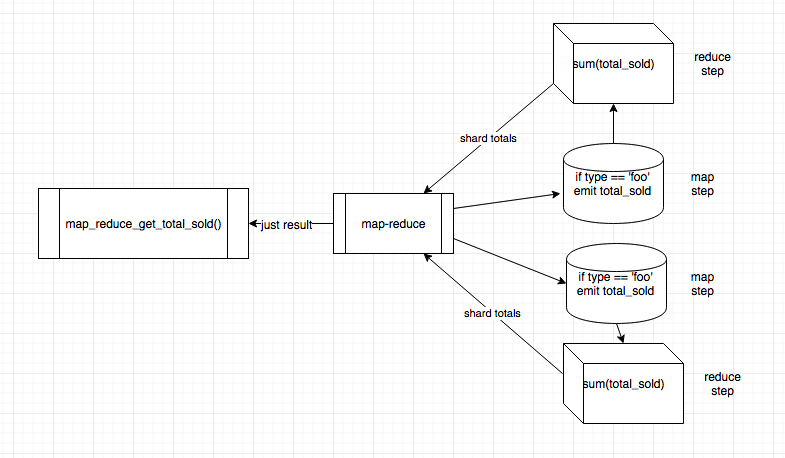
Take the code to the data
This is still slow (minutes)
Results aren't in real time, they can be old/stale, some domains don't care.
Fancier versions of the same idea arose.
Spark takes the intermediate steps and can persist them as an immutable dataset to help save time with re-queries and speculative inquiries.
A lot of people still do this today.
Streaming
For some things we can avoid doing batch analytics on data in the database. We can do computations on numbers as they arrive.
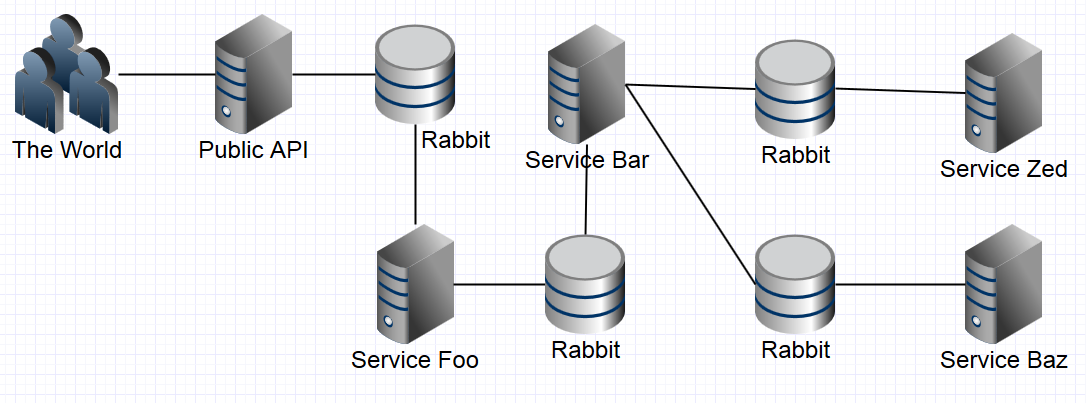
I spent my time...
- Standing up Message Queues and Services
- Fiddling with config between queues and services
- Writing endless monitors for queues and services
- Writing endless automated or manual recovery processes when queues/services failed
- Devising elaborate plans for message tracking through the system
- Building great integration environments to actually tests all of this in
- Creating deployment plans
- (sometimes writing the actual business logic I needed .....)
Let's think higher level
Some Code
Some Code
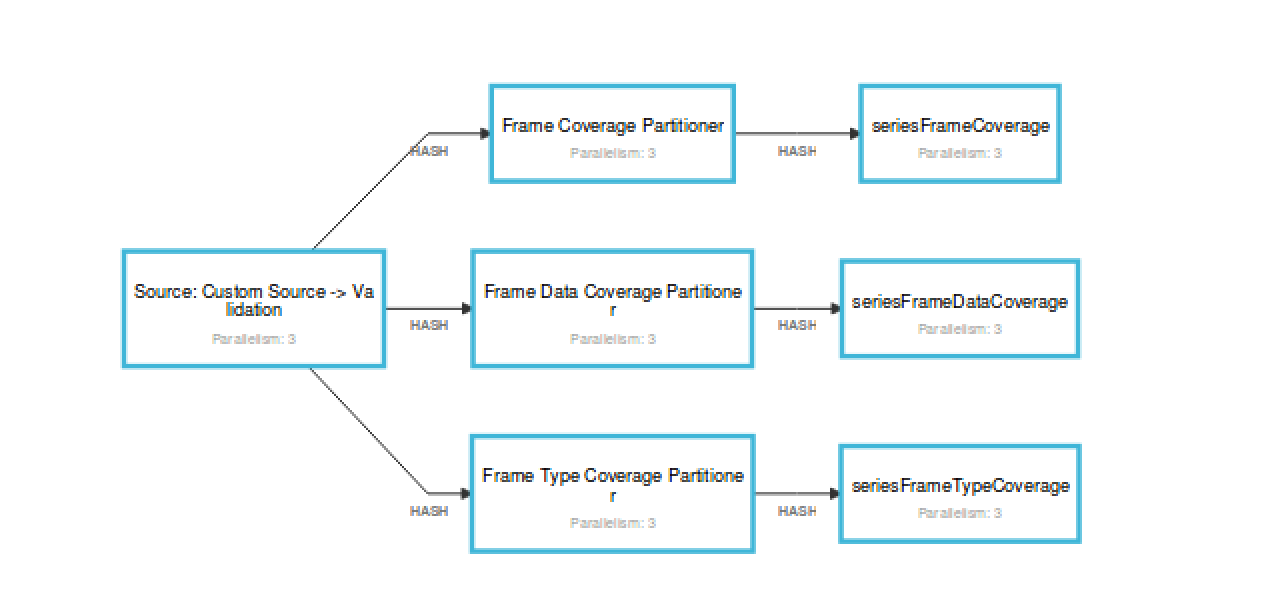
Flink will
- Manages messaging
- Manages health
- Manages deployments
- Tracks messages, can guarantee reliable processing
But wait, there's more!
- Windowing
- Water marking
- Expose state externally
And the problems!
- Distributed state is hard (QS carries all the problems of any distributed database from the start of this talk, and it's YOUNG)
- Disaster recovery is difficult
- Requires custom tools for testing
- Requires tooling for state CRUD ops (doesn't exist)
- Heavy weight dependencies (zookeeper, hdfs)