Flink Operations
Flink Slots
- Task managers have "slots" a "slot" can be thought of as a worker
- Because of context shifts, flink recommends one slot per core: https://ci.apache.org/projects/flink/flink-docs-release-1.3/setup/config.html#configuring-taskmanager-processing-slots
- We can break this rule, but this means performance tuning, at first we had many slots per core, not much work was done because of hand offs between threads.
Job and Operator Parallelism
- We can set parallelism per job or per operator
- If we set it per job, all operators appear to get the same parallelism
- Tuning each operator is part of the flink production ready checklist and should always be done: https://ci.apache.org/projects/flink/flink-docs-release-1.2/ops/production_ready.html
Relationship between slots and Parallelism
- In order to properly tune an operator, you need to know how many slots will be consumed
- Understanding how to count this relies on understanding operator "chaining" vs "unchaining" (by default operators are "chained" but this is configurable via the streaming api)
- If you're "unchaining" an operator, the slots appear to equal parallelism, that means each operator instance gets it's own thread.
- For "chaining" flink notices that many times the same thread could continue executing the next operation without thread headoff/network traffic, so the operation is "chained".
Chaining vs Unchaining
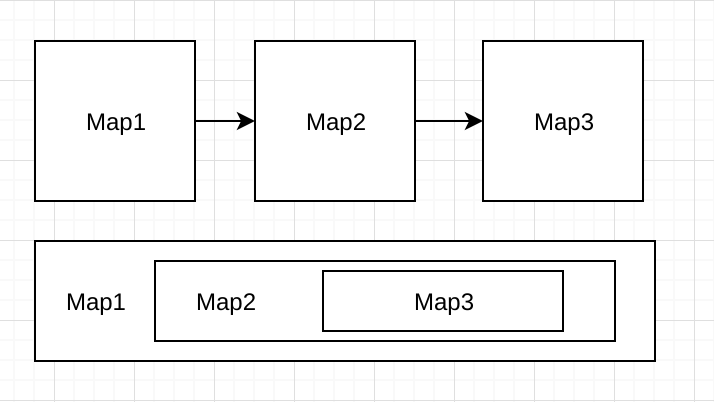
Chaining vs Unchaining
https://ci.apache.org/projects/flink/flink-docs-master/dev/stream/operators/#task-chaining-and-resource-groups
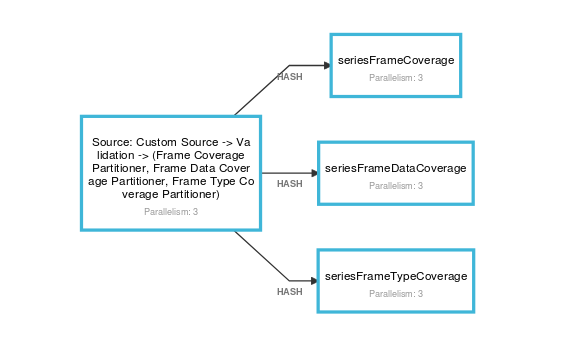
Chaining vs Unchaining
https://ci.apache.org/projects/flink/flink-docs-master/dev/stream/operators/#task-chaining-and-resource-groups
Summary
- Start with 1 slot per core per flink docs
- Slots are difficult to calculate due to chaining, and will intentionally apply a heavy load to each box to avoid copying/shuffling data
Snapshots

At least Once vs Exactly Once
If execution pauses from when the first barrier reaches an operator until the last barrier reaches an operator, we get exactly once processing, if we continue processing we get at least once.
(t1, B, t2) -> Op1
(t3, t4, B) ----^
https://ci.apache.org/projects/flink/flink-docs-master/internals/stream_checkpointing.html
Where to view Stats?
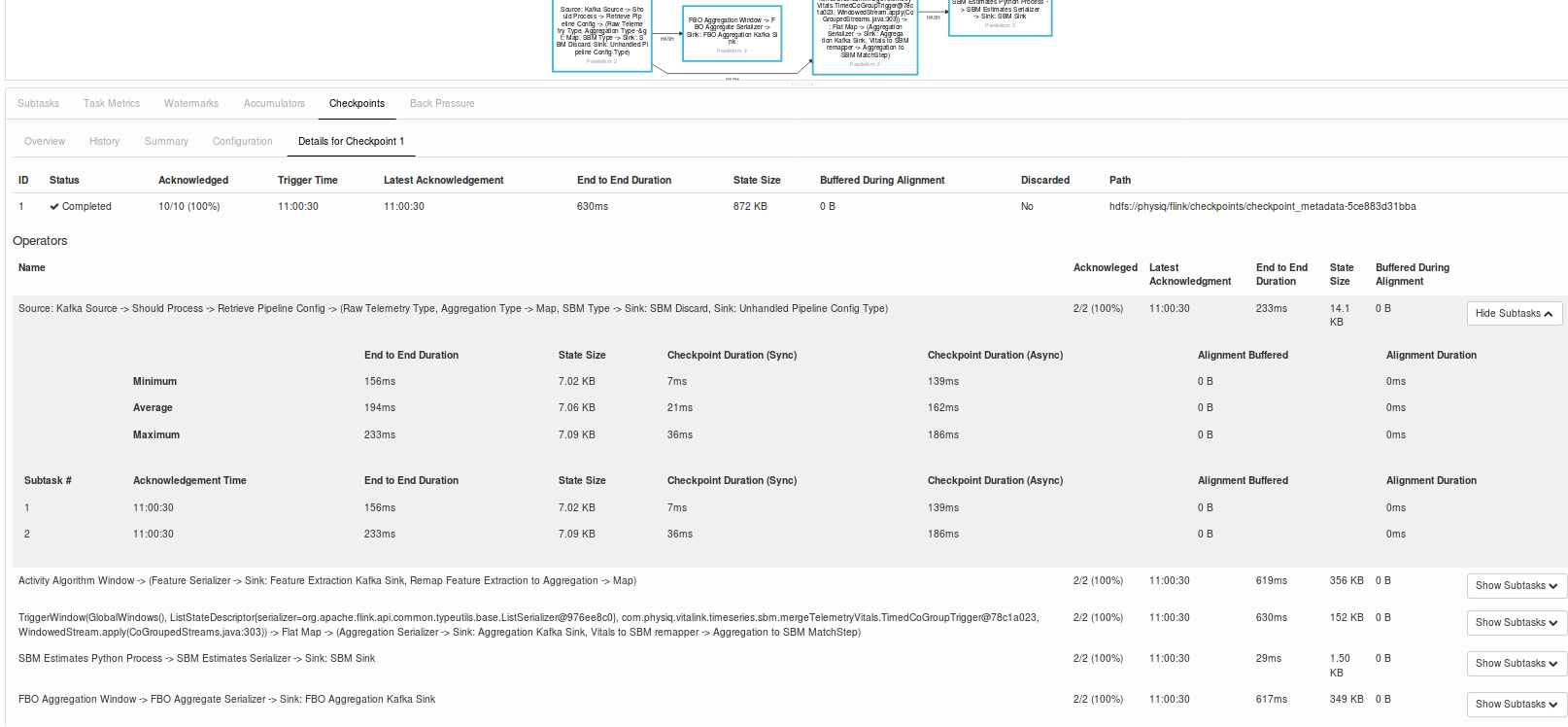
Summary
Snapshot time is a funny way to say "worst case stream latency".
Until we can make all streams flow more evenly, we need to use at least once processing.
The actual time we take snap shotting is just a second or two.
Async Operators
https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/stream/operators/asyncio.html
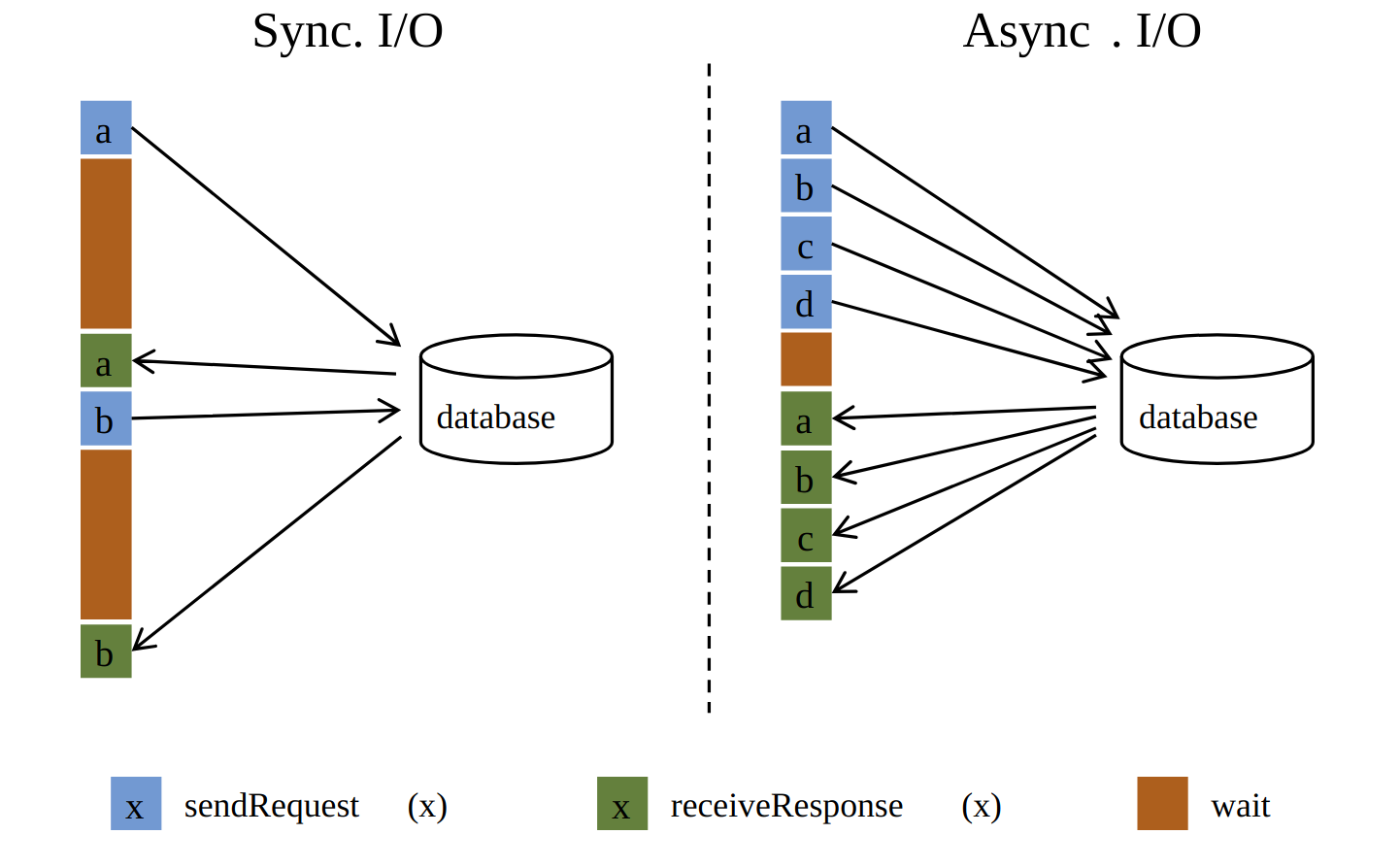
Summary
Async as much as we can
The flink docs around this topic are a mix of wrong and undocumented.