Blaze + Odo
Blaze
An interface for data-centric computation
Expressions
+
Compute recipes

Blaze in the Ecosystem
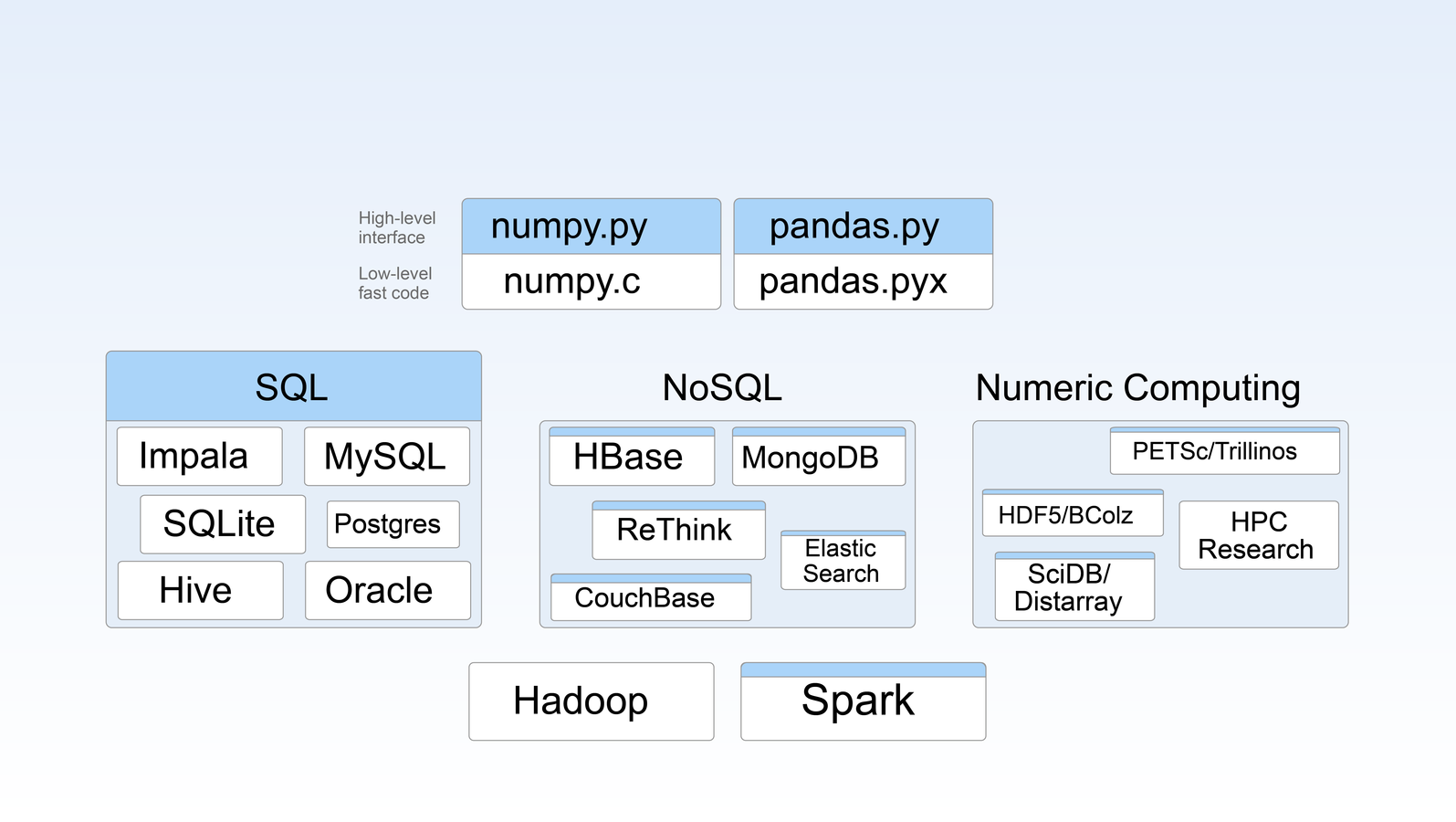
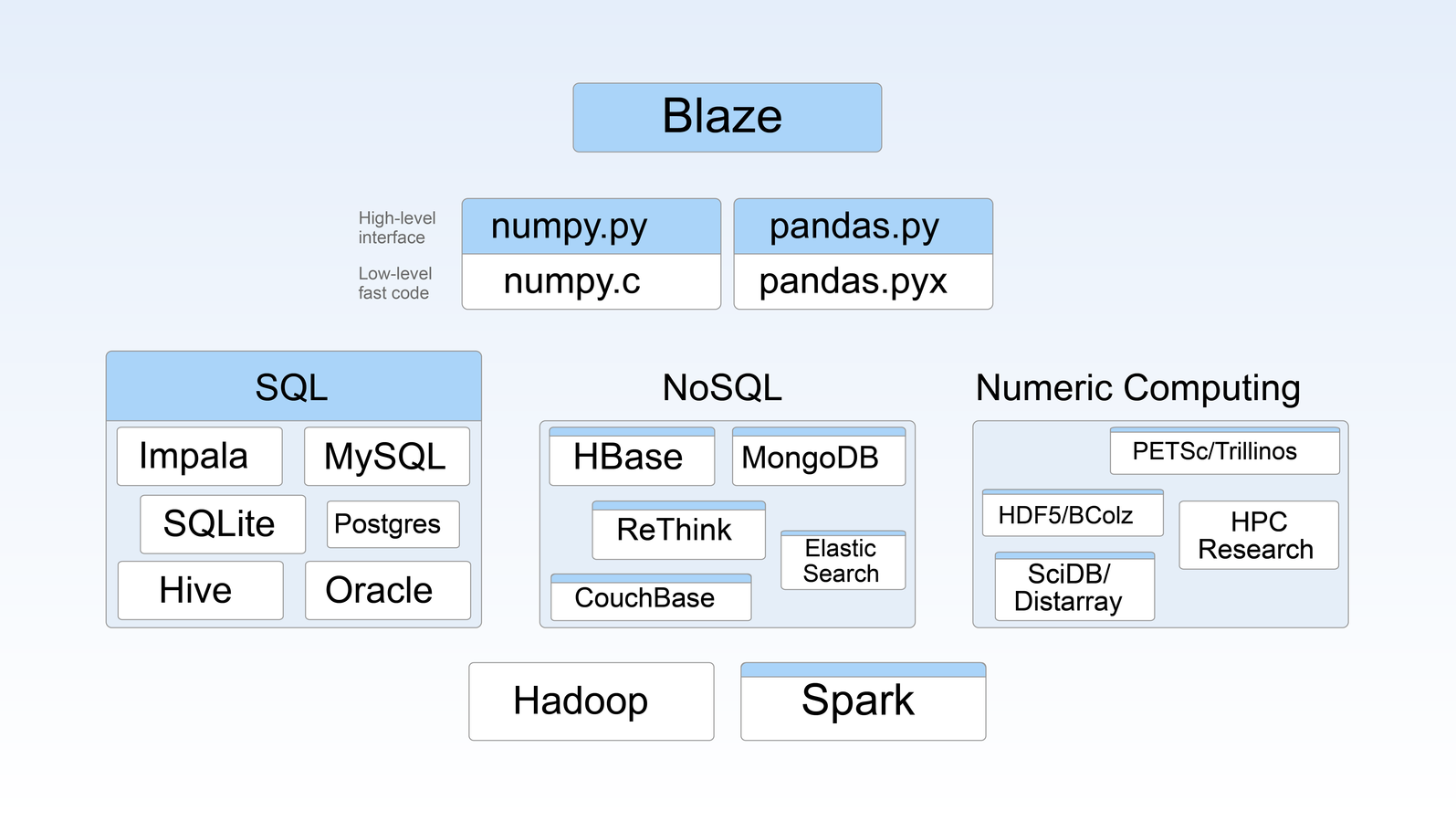
Prior Art
- PostgreSQL Foreign Data Wrappers
- Query a raw CSV file from psql
- dplyr / R
-
select(df, a, b) %>% group_by(b) %>% summarize(u=mean(a))
-
- SQLAlchemy
- Only for SQL
Expressions
"What do I want compute?"
Expressions
Blaze expressions describe data.
They consist of symbols and operations on those symbols
>>> from blaze import symbol
>>> t = symbol('t', '1000000 * {name: string, amount: float64}')name
shape
+
+
type information
Expressions
>>> by(t.name, avg=t.amount.mean(), sum=t.amount.sum())>>> join(s, t, on_left='name', on_right='alias')Group By
Join
Many more...
- Arithmetic (date and otherwise)
- Reductions (nunique, count, etc.)
- Column/Row stacking
- Many others
Compute Recipes
"How do I compute expression X on backend Y?"
Compute Recipes
@dispatch(Join, pd.DataFrame, pd.DataFrame)
def compute_up(expr, lhs, rhs):
# call pandas join implementation
return pd.merge(lhs, rhs, on=expr.on_left + expr.on_right)
@dispatch(Join, pyspark.sql.DataFrame, pyspark.sql.DataFrame)
def compute_up(expr, lhs, rhs):
# call sparksql join implementation
return lhs.join(rhs, expr.on_left == expr.on_right)Compute recipes work with existing libraries!
- python list
- numpy arrays
- pandas DataFrame
Demo time
ResultProxy -> list of RowProxy objects

Please, just give me a DataFrame
Odo
A library for turning things into other things
Factored out from the blaze project
"Oh, so it's a set of converters"
So is LLVM

Handles a huge variety of conversions
Let's name the containers in the PyData ecosystem
PyData Containers
- list
- ...
>>> odo([1, 2, 3], tuple)
(1, 2, 3)
list » tuple
Simple things ...
>>> odo('hive://hostname/default::users_csv',
... 'hive://hostname/default::users_parquet',
... stored_as='PARQUET', external=False)
<an eternity later ...
sqlalchemy.Table repr>Hive CSV » Hive Parquet
More complex things ...
odo is cp with types, for data
How do I go from X to Y in the most efficient way ...
... without explicitly writing down each conversion?
DataFrame » Hive
For example ...
I know how to do this:
DataFrame » CSV
df.to_csv('/path/to/file.csv')... and this:
CSV » Hive
load data
local infile '/path/to/file.csv'
into table mytable;Odo gives you this:
DataFrame » CSV » Hive
automatically
... and with uniform syntax
>>> odo(df,
... 'hive://hostname/default::tablename')How about something more involved?
JSON in S3 » postgres
How would we do this?
- JSON S3 » Local temp file
boto.get_bucket().get_contents_to_filename()
- Local temp file » DataFrame
pandas.read_json()
- DataFrame » CSV
DataFrame.to_csv()
- CSV » postgres
copy t from '/path/to/file.csv'
with
delimiter ','
header TRUE

The odo way
>>> odo('s3://mybucket/path/to/data.json',
... 'postgresql://user:passwd@localhost:port/db::data')Each step is usually easy
... but the whole thing

How does it work?
Through a network of conversions
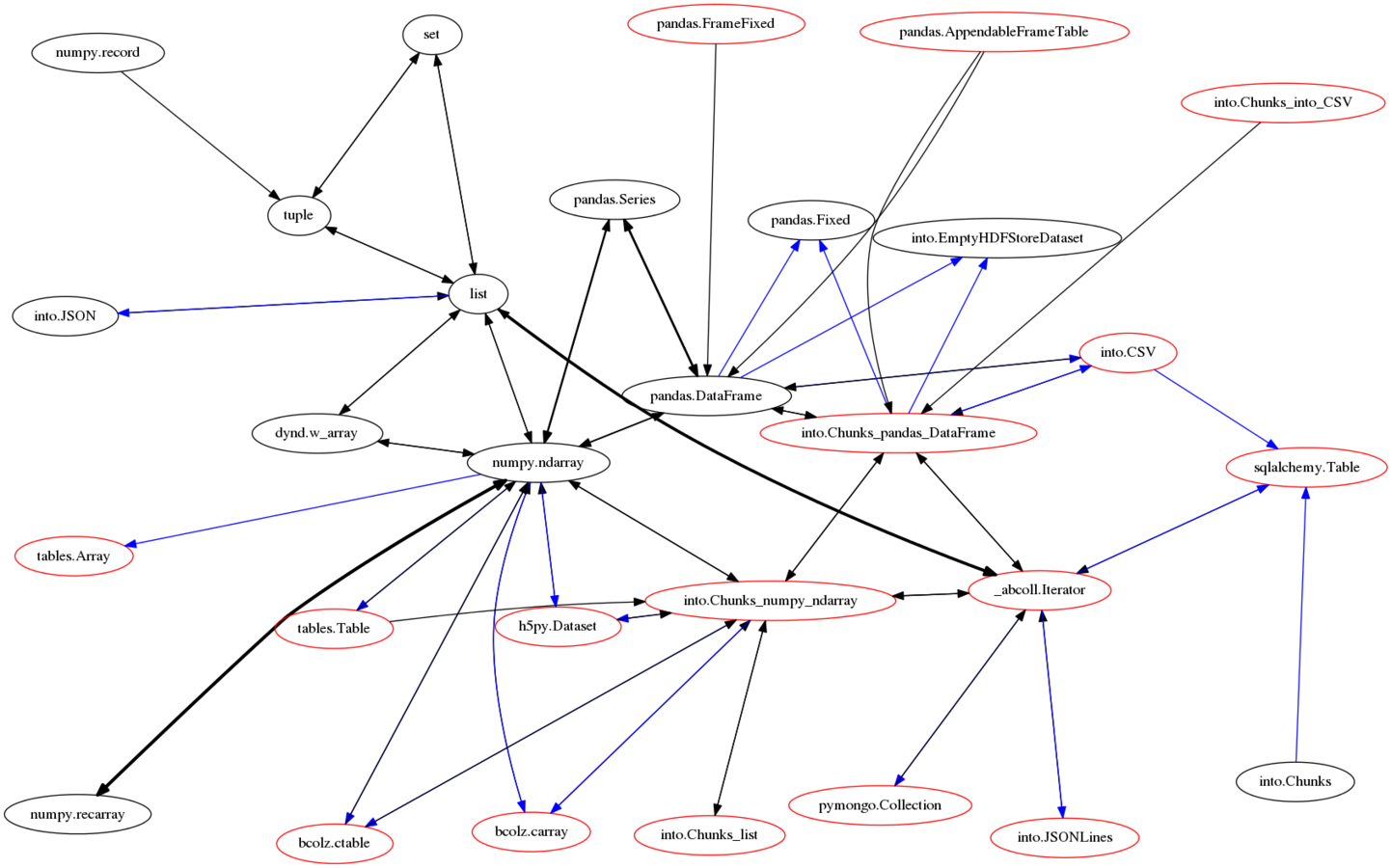
Each node is a type (DataFrame, list, sqlalchemy.Table, etc...)
Each edge is a conversion function
The full monty ...

It's extensible!
from odo import convert
from pyspark.sql import DataFrame as SparkDataFrame
@convert(pd.DataFrame, SparkDataFrame)
def frame_to_frame(spark_frame, **kwargs):
return spark_frame.toPandas()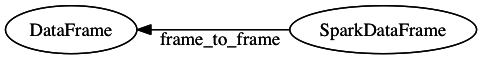
Docs
Thanks!
Source
Get it
-
conda install blaze odo -
pip install blaze odo