Ph.D. Thesis
Challenges in Speech Recognition Industry: Data Collection, Text Normalization and Punctuation Prediction
Author: mgr inż. Piotr Żelasko
Supervisor: dr hab. inż. Bartosz Ziółko
Reviewers: prof. dr hab. Zygmunt Vetulani
dr hab. inż. Artur Janicki
AGH University of Science and Technology, Kraków, 30.05.2019
Introduction
Motivation
- Build industry-adopted ASR
- What are the issues?
- Acoustic model training
- Language model training
- Transcript usability
- How to address them?
Main theses
- The proposed domain-specific recording acquisition process yields superior ASR training data (vs other available Polish data sets).
Main theses
- The proposed domain-specific recording acquisition process yields superior ASR training data (vs other available Polish data sets).
- Polish abbreviations can be correctly inflected with a context-aware LSTM model.
Main theses
- The proposed domain-specific recording acquisition process yields superior ASR training data (vs other available Polish data sets).
- Polish abbreviations can be correctly inflected with a context-aware LSTM model.
-
Deep neural networks and word embeddings are useful for punctuation restoration in conversational speech.
- Relative word timing information further improve their performance.
Data collection
Existing Polish speech corpora
With time aligned transcripts:
- CORPORA (Grocholewski, 1997)
- GlobalPhone (Schultz, 2002)
- Polish Speecon (Iskra et al., 2002)
- Jurisdic (Demenko et al., 2008)
- EASR (Hämäläinen et al., 2014)
Others:
- NKJP (Przepiórkowski et al., 2008)
- Europarliament recordings (Lööf et al., 2009)
- LUNA (Marciniak, 2010)
AGH Corpus of Polish Speech
- 25+h of recordings
- 166 speakers (1/3 of them female)
- Mostly young speakers (20-35 years old)
- ~14k unique words
Sub-corpora:
- Colloquial speech (PC + microphone, 10h)
- Students' projects (PC + microphone, 6.5h)
- TTS training corpus (anechoic chamber, 4.5h)
- Commands (VoIP, 3h)
- Others (various conditions, 2h)
ASR evaluation results
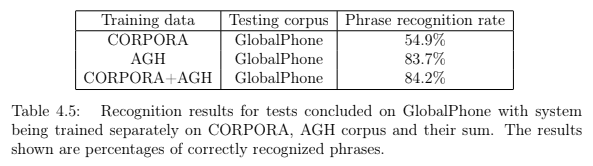
P. Żelasko, B. Ziółko, T. Jadczyk, D. Skurzok, AGH corpus of Polish speech, Language Resources and Evaluation (2016 IF = 0.922), vol. 50, issue 3, p. 585-601, Springer, 2016
Call recorder (v1)
- Simple words, numbers, named entities
- VoIP application with a phone number
- DTMF-based phrase set selection
- Only a single recording session at a time
Call recorder (v2)
- Phonetically balanced sentence set from NKJP and Wikipedia
- Web user interface
- Concurrent recording sessions
B. Ziółko, P. Żelasko, I. Gawlik, T. Pędzimąż, T. Jadczyk, An Application for Building a Polish Telephone Speech Corpus, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
Call recorder user interface

Results
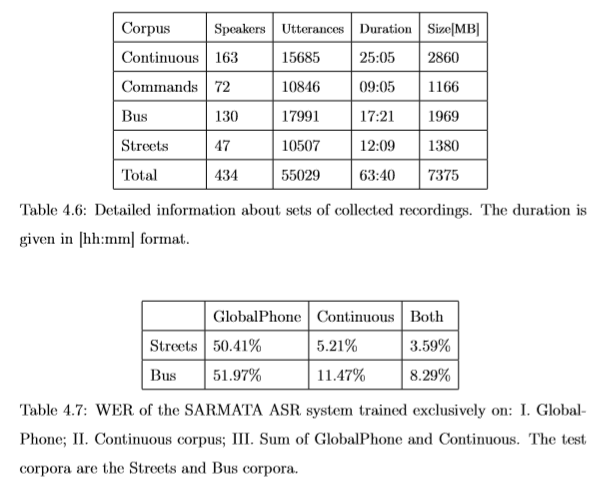
Text Normalization
What makes text normalization important?
- Vast amounts of text resources are available
- NKJP
- Polish Sejm Corpus
- Wikipedia
- Web-scraping
- Inconsistencies limit language modelling effectiveness
Sources of common text normalization issues
- Abbreviations
- Numerals
- Capitalization
- Typos
- Punctuation
Difficulties in strongly inflected languages
Hypothesis
- Humans can deduce the correct inflection.
- Can we model it?
- Is it enough to know the inflection of the context words?
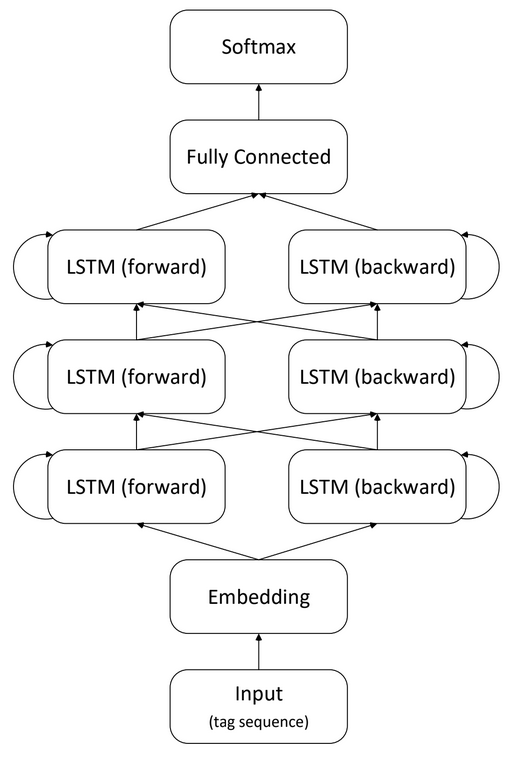
Method
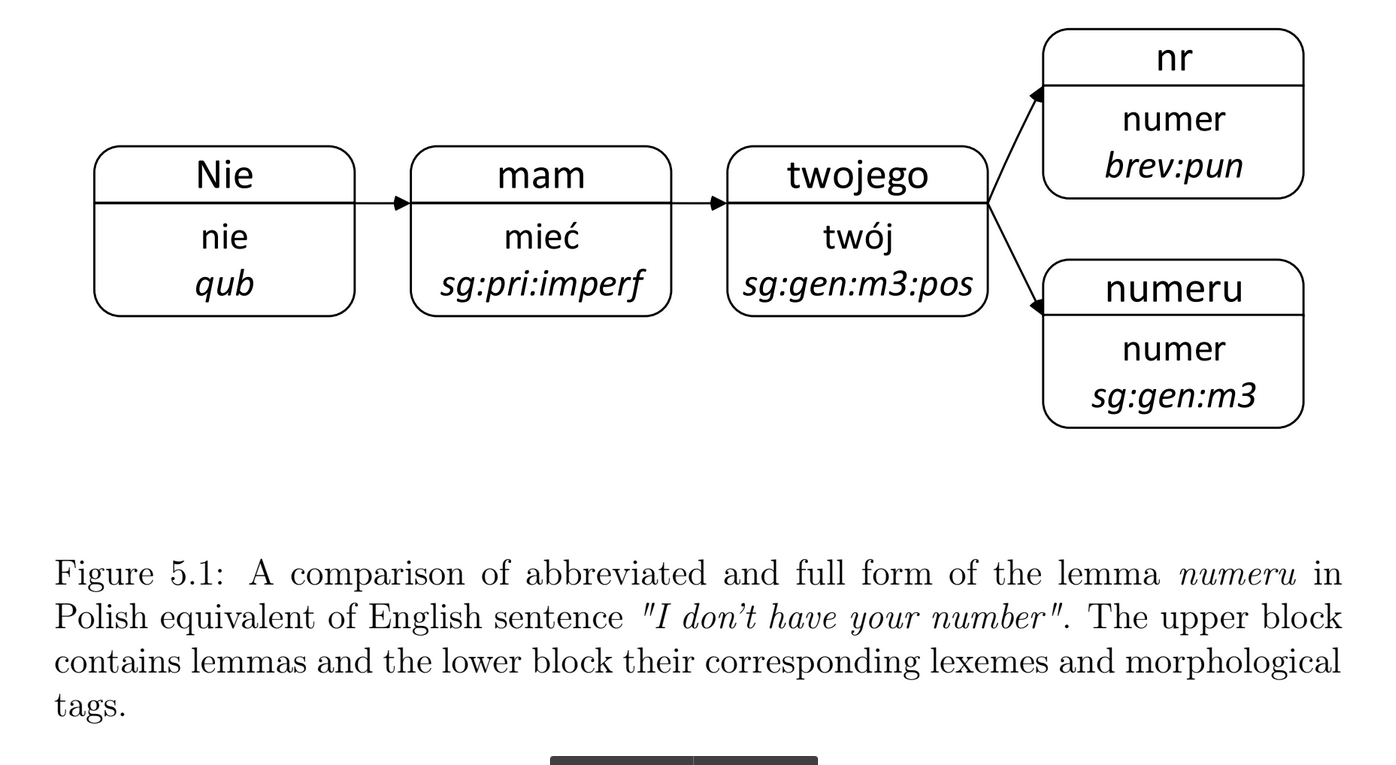
Train a BLSTM on morphosyntactic tag sequences to predict the masked tag.
- Word sequence:
- nie -> mam -> twojego -> nr
- Tag sequence (input):
- qub -> sg:pri:imperf -> sg:gen:m3:pos -> UNK
- Target label (output):
- sg:gen:m3
Results
| Dataset | Baseline | BLSTM |
|---|---|---|
| Train | 42.8% | 84.5% |
| Valid | 42.6% | 85.7% |
| Test | 40.3% | 74.2% |
Baseline: the most frequent tag for a given abbreviation
Error analysis
-
10 % accuracy lost by mistakes related to singular/plural grammatical number confusion.
-
Not all mistakes are severe, e.g.:
2.7 liter (pl. litra) <-> 2.7 liters (pl. litrów)
-
Not all mistakes are severe, e.g.:
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
Error analysis
-
10 % accuracy lost by mistakes related to singular/plural grammatical number confusion.
- Not all mistakes are severe, e.g.:
2.7 liter (pl. litra) <-> 2.7 liters (pl. litrów)
- Not all mistakes are severe, e.g.:
-
5 % accuracy lost by mistakes related to the “proc.” abbreviation.
-
Having no ability to learn about exceptions,
the network seems to have learned a rule:
5 cm -> 5 centimeters
5 % -> 5 “percents”
-
Having no ability to learn about exceptions,
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
Error analysis
-
10 % accuracy lost by mistakes related to singular/plural grammatical number confusion.
- Not all mistakes are severe, e.g.:
2.7 liter (pl. litra) <-> 2.7 liters (pl. litrów)
- Not all mistakes are severe, e.g.:
-
5 % accuracy lost by mistakes related to the “proc.” abbreviation.
-
Having no ability to learn about exceptions,
the network seems to have learned a rule:
5 cm -> 5 centimeters
5 % -> 5 “percents”
-
Having no ability to learn about exceptions,
-
Another 4 % are feminine/masculine confusions in grammatical gender (bias towards masculine forms).
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
Punctuation Prediction
What makes punctuation important?
- Readability/usability for the end-user
- NLP algorithms performance boost
- especially pre-trained ones
The concept
- Word embeddings (state-of-the-art at the time)
-
Prosody
- likely significant, but requires an additional component => less practical
-
Temporal information (word begin, end timestamps)
- available in ASR output
- Requires an aligned data set with transcripts, punctuation and word timings
P. Żelasko, P. Szymański, J. Mizgajski, A. Szymczak, Y. Carmiel, N. Dehak, Punctuation Prediction Model for Conversational Speech, Proceedings of Interspeech 2018, Hyderabad
Data preparation
Fisher (Cierci et al., 2004)

Results
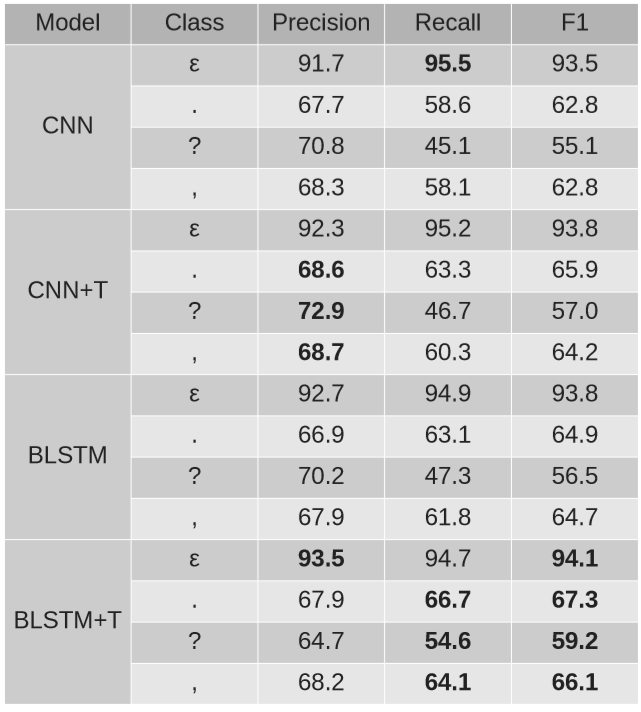
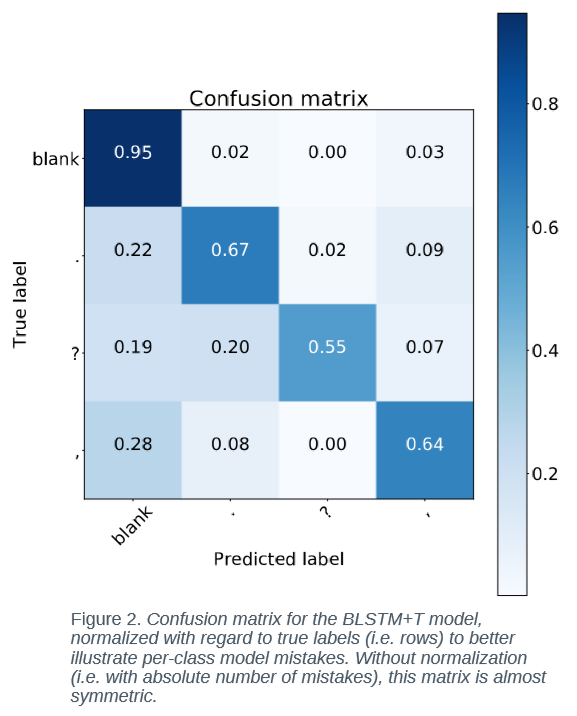
+T - uses temporal features
ε - blank (no symbol)
Conclusions
Main theses - recap
- The proposed domain-specific recording acquisition process yields superior ASR training data (vs other available Polish data sets).
- There is a major boost in ASR performance.
Main theses - recap
-
The proposed domain-specific recording acquisition process yields superior ASR training data (vs other available Polish data sets).
- There is a major boost in ASR performance.
- Yes, mostly with context's inflection
+ word information for exceptions.
Main theses - recap
-
The proposed domain-specific recording acquisition process yields superior ASR training data (vs other available Polish data sets).
- There is a major boost in ASR performance.
- Yes, mostly with context's inflection
+ word information for exceptions.
- Deep neural networks and word embeddings are useful for punctuation restoration in conversational speech.
- Yes, and temporal features further improve it.
Real-world applications
The presented research has been applied in (at least) two speech processing systems:
- Techmo Dictation (aka SARMATA)
- Avaya Conversational Intelligence
Thank you for your attention!
- B. Ziółko, T. Jadczyk, D. Skurzok, P. Żelasko, J. Gałka, T. Pędzimąż, I. Gawlik, S. Pałka, SARMATA 2.0 Automatic Polish Language Speech Recognition System, Proceedings of Interspeech 2015, Dresden, 2015
-
P. Żelasko, B. Ziółko, T. Jadczyk, D. Skurzok, AGH corpus of Polish speech, Language Resources and Evaluation (2016 IF = 0.922), vol. 50, issue 3, p. 585-601, Springer, 2016
-
B. Ziółko, P. Żelasko, I. Gawlik, T. Pędzimąż, T. Jadczyk, An Application for Building a Polish Telephone Speech Corpus, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
-
P. Żelasko, Expanding Abbreviations in a Strongly Inflected Language: Are Morphosyntactic Tags Sufficient?, Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, 2018
-
P. Żelasko, P. Szymański, J. Mizgajski, A. Szymczak, Y. Carmiel, N. Dehak, Punctuation Prediction Model for Conversational Speech, Proceedings of Interspeech 2018, Hyderabad
Extras
Speech recognition system industry requirements
- Accuracy
- Latency
- Scalability
Automatic Speech Recognition - recap
The inputs:
- X - acoustic features (parametrized recording)
The outputs:
- W* - the most likely word sequence
- W - a word sequence
The parameters:
- Θ - acoustic model parameters
- Ψ - language model parameters
Punctuation prediction example
