Attitude analysis and corpus analytics of 1M tweets about feminism
Zafarali Ahmed
Jerome Boisvert-Chouinard
Dave Gurnsey
Nancy Lin
Reda Lotfi
David Taylor

Big Data Week Montreal Hackathon
April 26, 2015
Attitude Analysis vs Sentiment Analysis
People use negative-sentiment words to support or oppose
"I hate feminism!"
vs.
"I hate it when people mock feminism!"
Ongoing problem: how do you read intentions?
Methodology summary
- retrieved last 100 tweets containing "feminism", "feminist" or "feminists" every 15 minutes for 5 months
- manually classified 500 tweets as pro-, anti-feminist or neither
- parsed without stopwords, with punctuation
- trained Naive Bayes classifier with 50-55% test set accuracy, predicted attitude of 391,000 original tweets
- calculated log-likelihood of each token (word, symbol, punctuation) appearing in the pro-feminist corpus or the anti-feminist corpus
Methodology 1:
Used Twitter Search API and a cron job to search most recent 100 tweets containing "feminism", "feminist" or "feminists" between Jan. 1, 2015 and Apr. 23, 2015
Total: 988,000 tweets
Removed retweets as unrepresentative low-effort instances; 391,000 remained.
Future project: see what gets retweeted
Methodology 2
Manually curate a small fraction (~500) tweets in three classes:
PRO
ANTI
NEITHER
Train a Naive Bayes classifier based on bag of words features
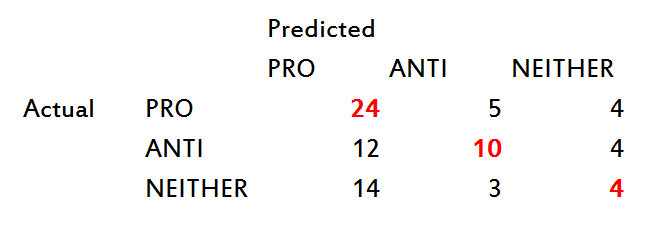
Confusion Matrix of Test Set
50-55% accuracy, compared to 33% for random selection. This seems low, but our use of log likelihood measures later on leverages that difference.
"Traditional" sentiment analysis with python modules TextBlob, NLTK, patterns based on IMDB movie reviews
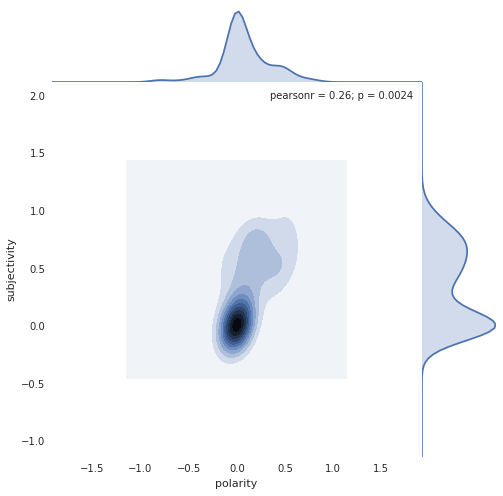
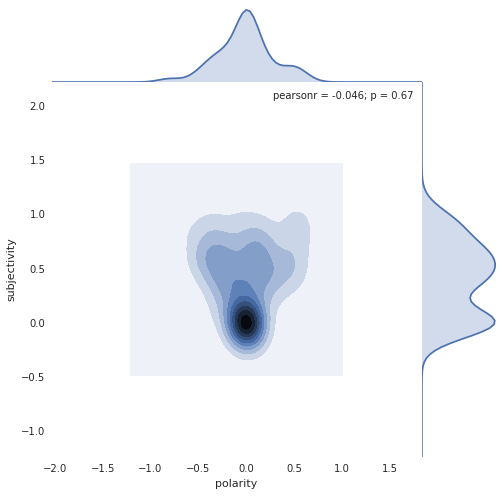
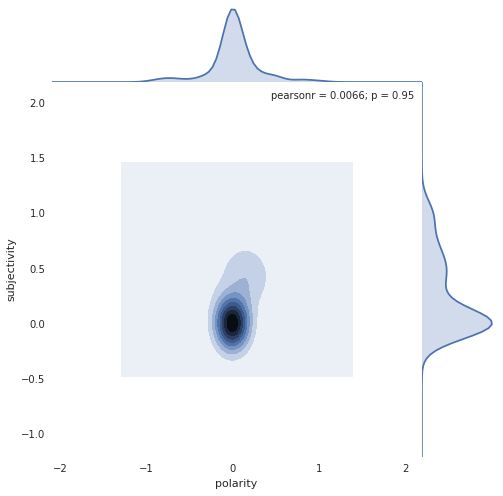
Pro Anti Neither
Random Forest classifier achieved 35.5% accuracy
Methodology 3
Parsed tokens according to whitespace, with NO STOP WORDS, removing only low-information punctuation (.,;:), keeping #hashtags and @atmentions intact
Why? Twitter is not like 'normal language'. In only 140 characters, every word has been chosen with care... or at least, with purpose.
Methodology 4
Calculate log likelihood of all terms that appeared at least 10 times in both the PRO and ANTI corpora.
(LL is an expensive operation, and it is highly unlikely that low-frequency words will have a high LL)
This gives us the "most characteristic" or "key" words used in tweets by pro-feminists and anti-feminist.
Log Likelihood
a measure of "keyness" in corpus analytics to determine what words are more likely to appear in one document than another
Uses absolute number of occurrences and absolute number of corpus size, not ratios
(e.g. LL of 100:1000 > LL of 10:100)
Measure of significance
Results
56% of pro-feminist tweets used "feminism" search term
88% of anti-feminist tweets used "feminists" search term.
The log-likelihood of these terms is heavily biases because these were selection criteria for the corpus,
but this difference is very instructive as to the attitudes and concerns of the two groups; one towards the movement, one towards the collection of people in the movement.

Plot.ly

Let's explore the keyness differences between the two corpora!
Anti Pro

Some initial patterns
Note: [joy] = emoji 'face with tears of joy'

Ascribing
&
Predictive
Describing
&
Defining
vs

Pronouns & gendered nouns

Emotionally
laden words
Current research and future work
We need a bigger training dataset!
- Mechanical Turk
- Volunteer crowdsourcing
- Active learning to make manual curation more efficient
- Using Doc2Vec
P.S. the HPC made this project possible!